阿里巴巴集团董事局主席兼首席执行官张勇曾在云栖大会表示:“未来最核心的工作是完成数字化,在数据经济时代,大数据是石油,算力是引擎”。
大数据在商业活动中的重要价值不言而喻,对于互联网公司而言,大数据已成为绕不过去的必选项,但是,直接收集、产生大数据的公司毕竟是少数,大多数公司则选择使用“网络爬虫”等互联网技术来进行数据的收集与分析。
对于大多数程序员而言,职业生涯肯定写过若干爬虫程序。如今,做研究、写文章时为了整理数据方便,也离不开网络爬虫技术的应用,如火爆朋友圈的“python课程”。 网络爬虫这个字眼已从程序员的圈子进入了更多人的视线,前一段时间在程序员圈广为流传的顺口溜是“爬虫玩得好,监狱进的早。数据玩的溜,牢饭吃个够”,可见网络爬虫在爬取数据时若不注意合规管理,则有可能触犯法律规定甚至构成刑事犯罪。如今年年初简历大数据公司巧达科技因大量爬取个人信息被警方一锅端,近期则有大批警察上门调查51信用卡,祸起因素之一就是使用爬虫技术抓取大量数据。 因此,使用爬虫技术务必注意合法合规,本文主要探讨使用爬虫技术或将涉及的法律风险、合规建议。
一、爬虫不是虫,数据抓取无所不能
网络爬虫(web crawler),也叫网络蜘蛛(spider),一般定义为“一个在网络上检索文件且自动跟踪该文件的超文本结构并循环检索被参照的所有文件的软件”。
通俗来讲,是一种用来自动浏览万维网的网络机器人,可以自动化、高效率地浏览互联网并从互联网上获取数据。最早的爬虫程序是1994年休斯敦大学的Eichmann开发的RBSE。著名的谷歌公司使用的Google Crawler是当时还是斯坦福大学生Brin和Page在1998年用Python开发的。[1] 网络爬虫技术是搜索引擎架构中最为底层的基础技术,如百度的网络爬虫就叫做Baidu Spider,用来收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中能所搜到网页、图片、视频等内容。 Baidu Spider的基本工作流程[2]如下: (1)首先选取一部分精心挑选的种子URL[3];(2)将这些URL放入待抓取URL队列;(3)从待抓取URL队列中取出待抓取在URL,解析DNS[ DNS:域名系统(Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。],并且得到主机的IP,并将URL对应的网页*载下**下来,存储进已*载下**网页库中。此外,将这些URL放进已抓取URL队列。(4)分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。(5)在设置爬虫时,可以给定某些条件来启动或者关闭爬虫动作。 爬虫程序在访问网站时,可以通过极高的访问频率抓取数据,这将明显导致两个负面影响,一是被爬取的网站可能会被搜索引擎判定为为非正常网站流量来源或恶意破坏用户搜索规则,二是如果爬虫抓取数据产生的流量超过网站服务器流量承受上限,则有可能导致服务器崩溃。
二、道高一尺魔高一丈,爬与反爬相克相济
(一)Robots协议 Robots协议((Robots Exclusion Protocol,robots.txt))是国际互联网界通行的道德规范,基于以下原则建立:(1)搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权;(2)网站有义务保护其使用者的个人信息和隐私不被侵犯。 Robots协议是一种存放于网站根目录下的文本文件,是爬虫程序第一个要访问的文件,该文件告知爬虫程序,哪些是可以爬取的内容,哪些是不允许爬取的内容。若该文件没有规定特定的不允许访问的范围,则视为该网站内容对于爬虫程序是开放的。
Robots协议作为一种技术规范而非技术手段,其作用只在于标示该网站是否准许搜索引擎爬虫程序访问、准许哪些搜索引擎爬虫程序访问,但爬虫程序识别该Robots协议的内容后,若爬虫程序不遵守Robots协议,该协议并不会起到强制禁止访问这一技术手段的作用 Robots协议毕竟仅仅是一个“君子协定”,爬虫程序不遵守该协议的情形很常见,就是通俗称之为“恶意爬虫”。对于恶意爬虫的限制,需要采取技术手段——反爬虫技术。 (二)反爬虫技术 如前所述,爬虫程序尤其是恶意爬虫,有可能导致访问频率过高而导致服务器崩溃,或者不遵守Robots协议而爬取目标网站不同意被抓取的内容。
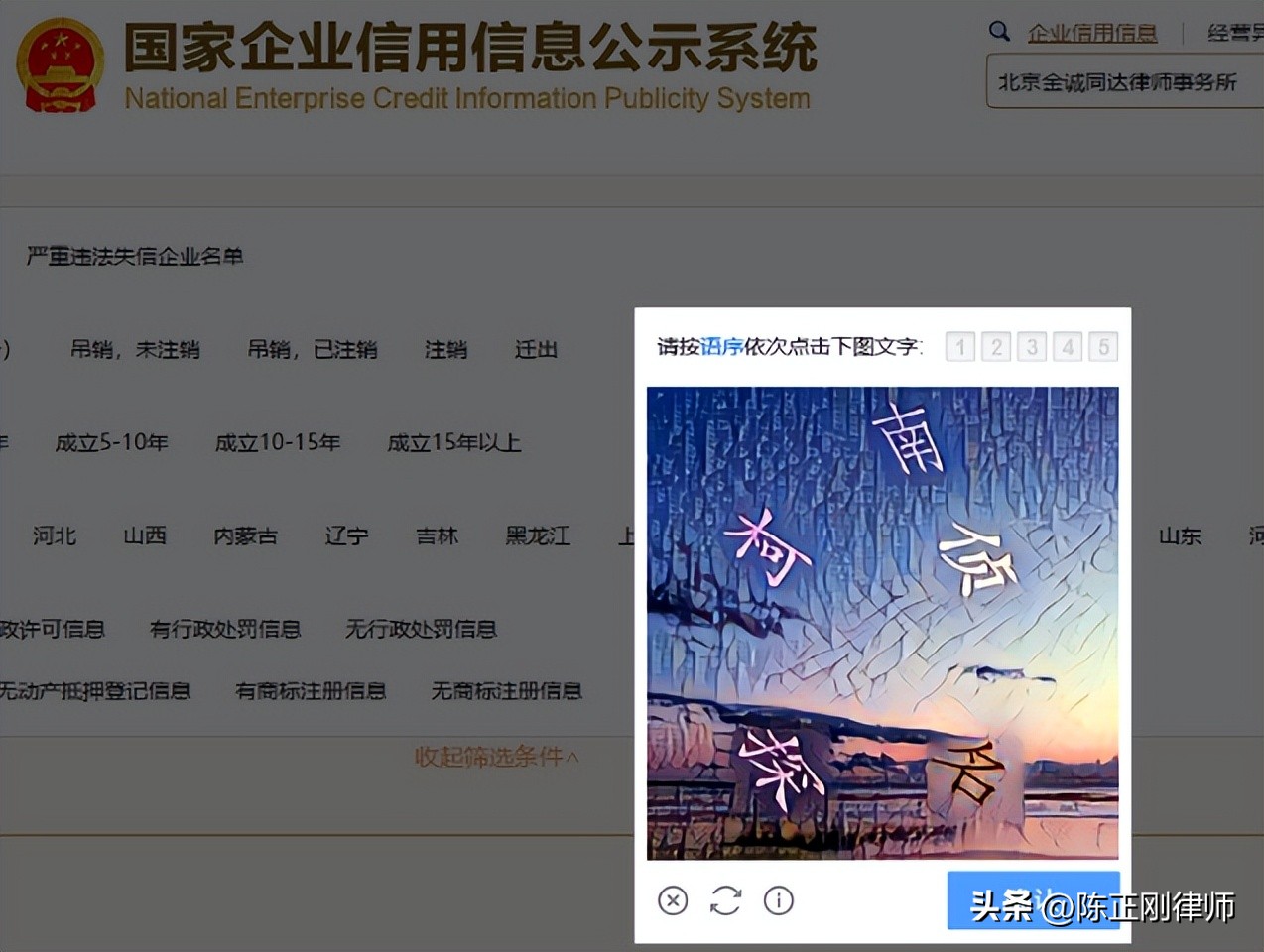
因此,网站将会从技术上采取反爬措施,反爬虫技术主要有以下几种: 1.IP访问频率、流量限制 如果同一个IP地址短时间内较高频率地访问,则会被识别为是爬虫程序,进而可以将其列入黑名单拒绝访问,但是该技术手段容易对用户造成大面积、无差别的误伤。 2.通过验证页面识别人、机行为 如我们在访问网站时经常会要求输入验证符号,该步骤就是为了提高爬虫程序访问该网站的难度。如国家企业信用信息公示系统就设置了“拖动滑块验证”,以及按语序点击某词组等方式。
但是,随着OCR技术的发展以及机器学习等智能化技术的进步,识别验证符号的难度已大大降低了,甚至已经远远超过了人类的认知水平。如图所示,如果一个网民不知道“名侦探柯南”,那么只好选择更换验证页面,但是机器学习却可以瞬时识别出“名侦探柯南”这一语义顺序。
3.建立白名单机制,通过User-Agent限制 User Agent中文名为用户代理,简称UA。无论是人为操作还是爬虫程序在访问网络时,都会与被访问网站交流头文件“headers”用以向服务器“表明身份”,如操作系统及版本、CPU类型、浏览器及版本、浏览器插件等。通过对UA设置参数范围,只有符合范围的UA才可以范围网站。但是,爬虫程序的反制手段是通过技术手段随机生成符合访问范围UA。 通过以上几种情形来看,爬虫与反爬虫技术的发展历程就是矛与盾的对弈,都在不停地衍生与进化,目前暂未有哪一方可以一劳永逸地处于不败之地。在“快播”一案中,创始人王欣主张“技术中立”,*今条头日**创始人张一鸣也以技术中立为*今条头日**抓取网页信息的行为做辩护,但是对于技术使用的限制要以法律法规为边界。
三、使用爬虫不合规,法律风险常相随
如前所述,若爬虫程序导致干扰了目标网站的正常运营、爬取了特定类型的数据或信息等情形,将会面临法律风险。
从已有法规及裁判案例来看,若不当使用爬虫技术将涉及民事责任、刑事责任、行政责任等法律风险。 (一)民事责任风险 1.不正当竞争责任 未经许可利用爬虫技术爬取经营者的信息数据,将构成不正当竞争,给被侵害的经营者造成损害的,应当承担损害赔偿责任。 在“北京百度网讯科技有限公司、百度在线网络技术(北京)有限公司与北京奇虎科技有限公司不正当竞争纠纷案”[4]中基本事实是:百度Robots协议不允许360爬虫机器人抓取产品内容;360爬虫机器人抓取了百度网站的内容,并作为搜索结果向网络用户提供;360在强行抓取百度内容后,百度进行了强制跳转到百度首页的技术措施,360也进行了向网络用户直接提供网页快照的反制技术措施。
基于以上事实,法院认为:提供内容的网站经营者的两原告与作为搜索引擎服务商的被告构成《反不正当竞争法》意义上的经营者,被告未遵守Robots协议的行为构成不正当竞争。 2.著作权侵权责任 网络上的文章、评论、图片等内容在具备独创性的前提下即构成著作权法上受保护的作品,作品财产权利主要有复制权、发行权、出租权、展览权、表演权、放映权、广播权、信息网络传播权、摄制权、改编权、翻译权、汇编权等,而一般情况下网络运营者会在用户协议中写明部分可转让的著作权权利将转给运营者。
因此,若爬虫程序不遵守Robots协议或者突破了反爬虫技术爬取了网站数据,则爬取本身即侵犯了复制权,若进一步投入网络使用将涉嫌侵犯信息网络传播权等其他权利。 (二)刑事责任风险 1.非法获取计算机信息系统数据罪 违反国家规定,侵入国家事务、国防建设、尖端科学技术领域的计算机信息系统的以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。 若通过爬虫程序强行绕开网站反爬虫技术措施爬取数据,侵入了计算机系统,情节严重时将构成前述罪名。如上海晟品网络科技有限公司、侯明强等非法获取计算机信息系统数据罪一案中,[6]法院认为被告人使用的“tt_spider”文件中包含通过*今条头日**号视频列表、分类视频列表、相关视频及评论3个接口对*今条头日**服务器进行数据抓取,并将结果存入到数据库中。
在数据抓取的过程中使用伪造device_id绕过服务器的身份校验,使用伪造UA及IP绕过服务器的访问频率限制。采用技术手段获取计算机信息系统中存储的数据,情节严重,其行为已构成非法获取计算机信息系统数据罪。 2.侵犯商业秘密罪 商业秘密,是指不为公众所知悉,能为权利人带来经济利益,具有实用性并经权利人采取保密措施的技术信息和经营信息。使用爬虫程序获取他人商业秘密的行为符合以不正当手段获取他人商业秘密,构成侵犯商业秘密。
若后续的使用行为导致商业秘密的权利人重大损失的,将面临处三年以下有期徒刑或者拘役,并处或者单处罚金;造成特别严重后果的,处三年以上七年以下有期徒刑,并处罚金等刑事责任。 3.侵犯著作权罪 侵犯著作权罪是指以营利为目的,违反著作权管理法规,未经著作权人或与著作权有关的权益人许可,复制发行其作品,出版他人享有专有处版权的图书,复制发行其制作的音像制品,或者制作、出售假冒他人署名的美术作品,违法所得数额较大或者有其他严重情节的行为。 在郑某等侵犯著作权罪一案中,[7]被告人在其网站上收录其利用“爬虫”软件自动搜索的网络小说数量达上千部,被法院认定为侵犯著作权罪。在段某某侵犯著作权一案中,[8]被告人在互联网上设立视频网站,利用搜索爬虫技术,针对其他视频网站的影视作品设置加框链接,并设置目录、索引、内容简介、排行榜等,吸引用户点击*放播**,屏蔽所链影视作品的片头广告,在所设网站网页内发布广告后从网络“广告联盟”处收取费用牟利。该行为被认定为“通过信息网络向公众传播他人作品”构成侵犯著作权罪。 4.侵犯公民个人信息罪 公民个人信息,是指以电子或者其他方式记录的,能够单独或者与其他信息结合识别特定自然人身份,或者反映特定自然人活动情况的各种信息,包括姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等。 《刑法》明确规定违反国家有关规定,向他人出售或者提供公民个人信息,情节严重的,构成犯罪;在未经用户许可的情况下,非法获取用户的个人信息,情节严重的将构成“侵犯公民个人信息罪”。
《最高人民法院 最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释对“情节严重”的认定标准:(1)非法获取、出售或者提供行踪轨迹信息、通信内容、征信信息、财产信息五十条以上的;(2)非法获取、出售或者提供住宿信息、通信记录、健康生理信息、交易信息等其他可能影响人身、财产安全的公民个人信息五百条以上的;(3)非法获取、出售或者提供第三项、第四项规定以外的公民个人信息五千条以上的便构成“侵犯公民个人信息罪”所要求的“情节严重”。 (三)行政责任风险 根据《网络安全法》规定,侵害个人信息依法得到保护的权利的,由有关主管部门责令改正,可以根据情节单处或者并处警告、没收违法所得、处以罚款,对直接负责的主管人员和其他直接责任人员处罚款;情节严重的,并可以责令暂停相关业务、停业整顿、关闭网站、吊销相关业务许可证或者吊销营业执照。
从事危害网络安全的活动,或者提供专门用于从事危害网络安全活动的程序、工具,或者为他人从事危害网络安全的活动提供技术支持,尚不构成犯罪的,由公安机关没收违法所得,处拘留、罚款,并对直接负责的主管人员和其他直接责任人员处罚。 国家互联网信息办公室于2019年5月28日发布《数据安全管理办法(征求意见稿)》第十六条:网络运营者采取自动化手段访问收集网站数据,不得妨碍网站正常运行;此类行为严重影响网站运行,如自动化访问收集流量超过网站日均流量三分之一,网站要求停止自动化访问收集时,应当停止。“自动化手段访问收集网站数据”即包括爬虫程序爬取网站数据。该办法若正式生效后,爬虫技术若妨碍网站正常运行时,或将受到相关处罚。
四、爬虫技术虽好用,如何才能不踩雷
如今数据的价值越来越高,而数据的垄断效应亦日渐明显,大数据的源头已被行业龙头所牢牢把握。
在此背景下,中小型互联网公司为了业务发展只好使用爬虫程序获取信息数据,但在使用爬虫技术时务必注意合规,无论是公司管理者亦或程序员,请注意以下合规建议。 (一)爬虫技术勿滥用,robots协议要遵循 如前所述,技术虽然中立,但是使用中立技术的人要是“不正经”,技术就会成为违法作恶的工具,因此对于技术的使用要注意合法合规。虽然技术派称“没有爬不到的数据”,但并不是所有数据都能爬。
对此,上海交通大学数据法律研究中心执行主任何渊教授总结为“三全一稳定,两秘密一隐私”。所谓“三全”是指国家安全、公共安全、经济安全。“一稳定”指社会稳定。“两秘密一隐私”是指国家秘密、商业秘密和个人隐私。因此不应滥用爬虫技术,应避免爬取以上数据。 Robots协议虽然并非作为法律意义上的协议或者合同,但爬虫程序应当遵守该协议中关于可以访问和禁止访问的范围。
如百度与奇虎360不正当竞争纠纷案中,法官认为Robots协议应当被认定为行业内的通行规则及商业道德,不遵守Robots协议应当承担不利后果。 (二)反爬技术不突破,善意爬取别作恶 按授权情况,可以分为合法爬虫和恶意爬虫。遵循Robots协议的属于合法爬虫。恶意爬虫是指通过分析并自行构造参数对非公开接口进行数据爬取,获取对方本不愿意被大量获取的数据,并有可能给对方服务器性能造成极大损耗。此处通常存在爬虫和反爬虫的激烈交锋。[9]随着爬虫技术的进步,反爬虫技术也在不断迭代更新。
若目标网站已通过反爬虫技术手段禁止访问服务器,此时应当避免通过技术突破的手段强行访问受保护的计算机信息系统进行数据爬取。 (三)爬取内容常审查,授权许可要获得 爬虫会按照既定规则不知疲倦地自动抓取数据,在运行爬虫程序前要分析拟爬取内容,应避免抓取个人信息、隐私或者涉嫌商业秘密以及他人具有较高商业价值的数据信息。
爬虫程序在抓取数据后,要对于数据做相应的审查,若涉及前述不应当爬取的内容,应及时修改爬虫规则或停止运行,并删除数据。对于爬虫经常光顾的社交、电商、在线旅游等网络,要遵循“三重授权原则”,即“用户授权平台方+平台方/第三方授权+用户授权第三方”。 (四)避免侵犯著作权,数据灰产莫沾染 对于爬取的数据,若本身具有独创性则会落入著作权保护的范围。爬虫程序运行时即是一种复制行为,有可能会侵犯著作权人的“复制权”;若抓取后经过网络的二次传播,则可能侵犯著作权人的“网络信息传播权”等。
因此,在爬取数据时,要注意判断拟爬取的数据是否受著作权保护,应当尽力避免侵犯著作权。 近年来,大数据灰色产业已形成了收集数据、交换数据、洗白数据、数据补全等全产业链模式,爬虫程序在大数据行业中最受欢迎,已成为数据行业的“底层技术”。
在获取、使用数据时务必要注意数据的合法来源以及合法去向,使用过程中也应当及时评估合规性,否则稍有不慎极有可能涉嫌刑事犯罪。 [1]罗刚:《网络爬虫全解析:技术、原理与实践》[2]wawlian:网络爬虫基本原理[3]URL:统一资源定位符(Uniform Resource Locator,缩写:URL),在WWW上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL,它是WWW的统一资源定位标志,就是指网络地址。[4]DNS:域名系统(Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。[5]北京市第一中级人民法院 (2013)一中民初字第2668号 [6]北京市海淀区人民法院 (2017)京0108刑初2384号 [7]北京市海淀区人民法院 (2013)海刑初字第2725号 [8]上海市徐汇区人民法院 (2017)沪0104刑初325号 [9]云鼎实验室 《2018上半年互联网恶意爬虫分析:从全景视角看爬虫与反爬虫》