一种使用NLTK的简单而有效的文本清理方法

1. 文本清理及其重要性
一旦获取了数据,就需要对其进行清理。
大多数情况下,数据将包含重复的条目、错误或不一致。在应用任何机器学习模型之前,数据预处理是重要的一步。与文本数据相同,在对文本数据应用任何机器学习模型之前,它需要进行数据预处理。
文本的预处理意味着清除噪音,例如: 删除停止词,标点符号,在文本上下文中没有太大权重的术语等。
在本文中,我们详细描述了如何使用Python(NLTK) 对机器学习算法的文本数据进行预处理。
事不宜迟,让我们深入研究代码
2. 库导入
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
nltk.download('stopwords')
nltk.download('wordnet')
Copy
3. 使用For循环一次性实现所有文本清理技术
corpus = []
text_data = ""
for i in range(0, 1732): # (Number of rows)
text_data = re.sub(
'[^a-zA-Z]',
' ',
Raw_Data['Column_With_Text'][i]
)
text_data = text_data.lower()
text_data = text_data.split()
wl = WordNetLemmatizer()
text_data = [wl.lemmatize(word) for word in text_data if not word in set(stopwords.words('english'))]
text_data = ' '.join(text_data)
corpus.append(text_data)
Copy
4. 现在让我们看看for循环到底做了什么
4.1 第一步,它将删除除英文单词以外的所有术语。
这一步至关重要,因为文本数据中的其他术语,如特殊字符和数字,会给数据增加噪音,从而对机器学习模型的性能产生负面影响。在这一步中,使用正则表达式来删除所有非英语词汇。
4.2 在第二步中,它将对文本数据进行规范化处理。
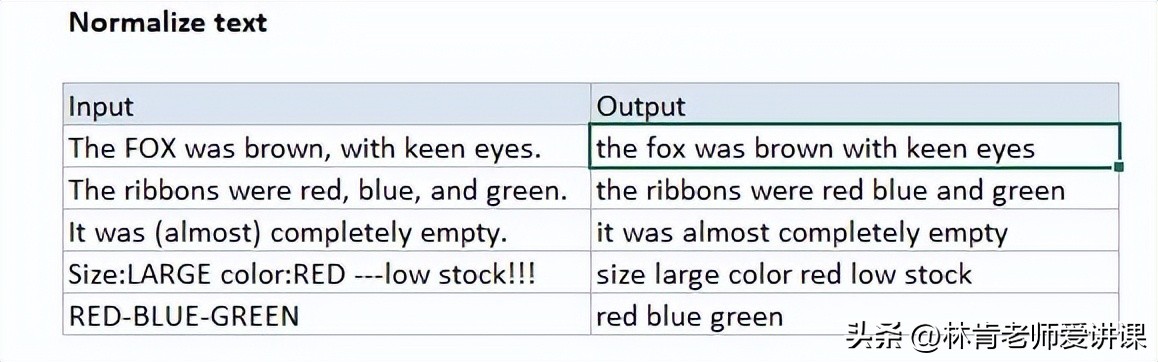
对文本进行规范化处理是一个重要步骤,因为这可以减少模型中的维度问题。如果文本没有被规范化,就会导致数据重复的问题。为了使文本规范化,使用了Python中的Lower()函数。这个函数将所有的单词转换成小写字母,从而解决了这个问题。
4.3 在第三步,它将对单词进行词法处理。
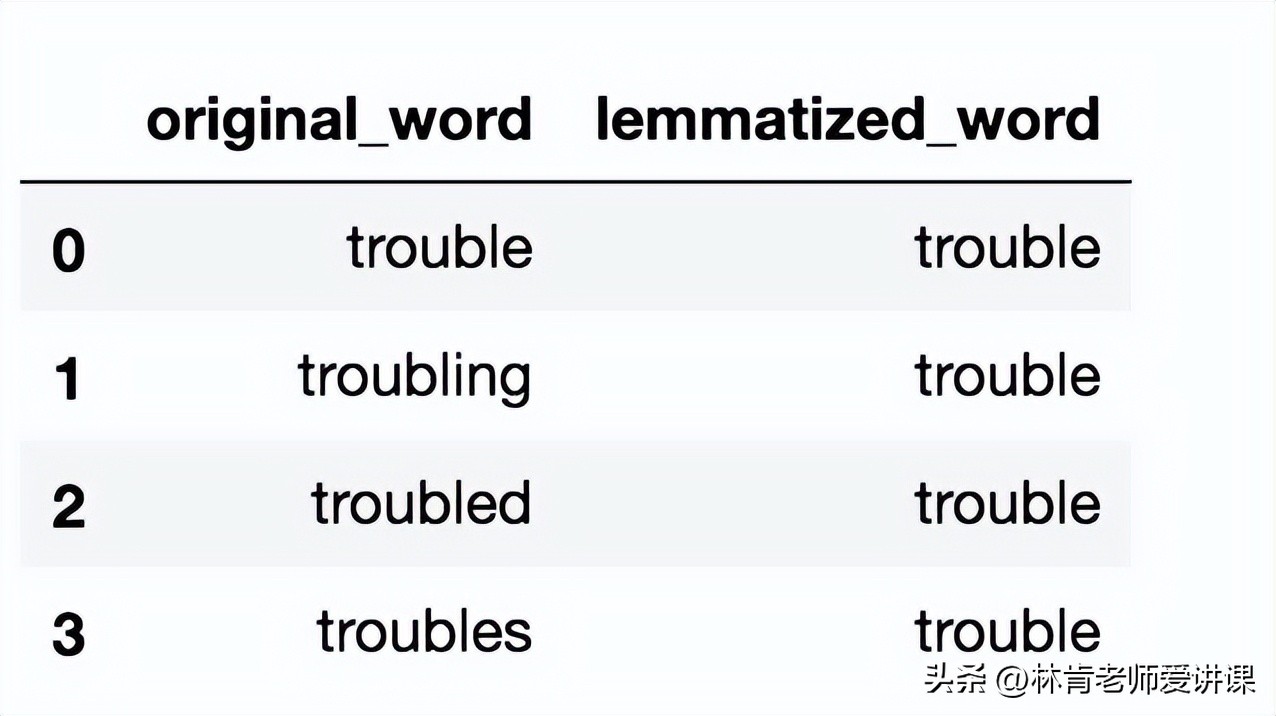
词法处理是一个重要的步骤,因为它消除了数据重复的问题。意思相近的词如work、working和worked具有相同的意思,但在创建词包模型时,这将被视为三个不同的词。NLTK库的WordNetLemmatizer包被用来解决这个问题。这个包将任何给定的词还原成其原始形式。
4.4 在第四步中,它将删除所有的停用词。
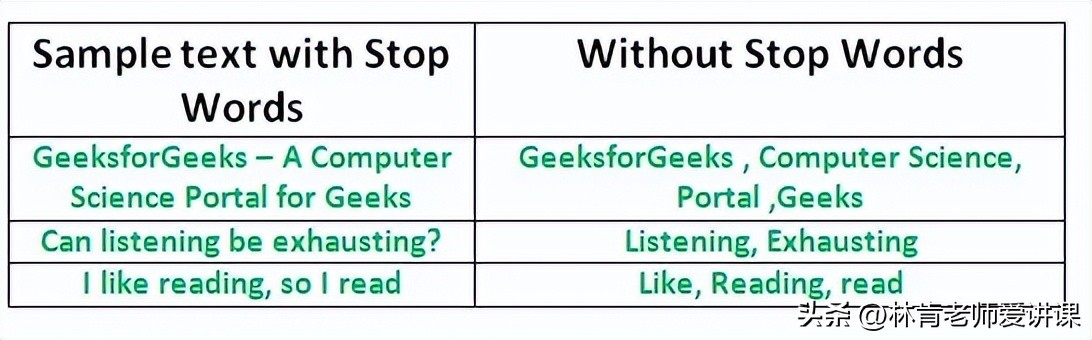
删除停用词是一个重要的步骤,因为停用词会给模型增加维度;这种额外的维度会影响模型的性能。
NLTK库中的Stopword包被用来去除停止词。语料库中的所有文本都要与停止词列表进行比较,如果有任何单词与停止词列表相匹配,就会被删除。
这篇文章是为那些刚开始接触NLP并被文本清理困扰的人准备的。在大多数情况下,文本清理可能是令人头痛的。这段代码可以帮助你掌握最基本的文本清理技术,并且可以直接使用。