
作者/赵一晗
存储流向
本地存储
本地存储的目录如下所示:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ │ └── 000002
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD.tmp
└── wal
├── 00000002
└── checkpoint.000001
└── 00000000
└── checkpoint.000001.tmp
Prometheus的存储大致可以分为两类:一类是block块,就是01开头的那些文件夹;另一类是wal(预写日志),就是wal文件夹的部分。
block块
在Prometheus中每两个小时为一个时间窗口,即将2小时产生的数据存储在一个块里面,这样的块会有很多,监控数据会以时间段的形式被拆分成不同的block。
block会压缩、合并历史数据块,以及删除过期的块。随着压缩、合并,block的数量会减少,在压缩过程中会发生三件事:定期执行压缩、合并小的block到大的block、清理过期的块。
block的大小不固定,根据设定的步长成倍数增长,默认最小的block保存两小时的监控数据,如果步长为4,那么block对应的时间依次为2h、8h、24h、72h。
块内部结构
block内部格式如下:
```
├── 01EM6Q6A1YPX4G9TEB20J22B2R # block
│ ├── chunks # 样本数据 每个大小为512MB超过会被截断成多个
│ │ └── 000001 # 存储的时序数据
│ │ └── 000002 # 存储的时序数据
│ ├── tombstones # 逻辑数据,主要记载删除记录,和标记要删除的内容,删除标记,可在查询块时排除样本。
│ ├── index # 索引文件,记录存储的数据的索引信息,通过文件内的几个表来查找时序数据
│ └── meta.json # block元数据信息,包含了样本数,最大时间和最小时间,压缩级别
```
一个块由4个部分组成。
以01EM6Q6A1YPX4G9TEB20J22B2R块ID为例,以上是文件在磁盘上的外观。
block的命名原理ULID
ULID:全局字典可排序ID。
持久化的块
块具有一个有趣的属性——其中的样本不可变。如果要添加更多样本,或删除一些样本,或更新一些样本,必须使用所需的修改来重写整个块,并且新块具有新的ID。这两个块之间没有关系。我们通过墓碑对块进行了删除,而没有触及样本,因为在每个删除请求上重写一个块听起来并不健全。
上面的目录结构展示了一个块文件内部的结构。如下图所示,灰色部分就是持久化在本地硬盘中的不可变的块,block在硬盘和内存两个位置都有。
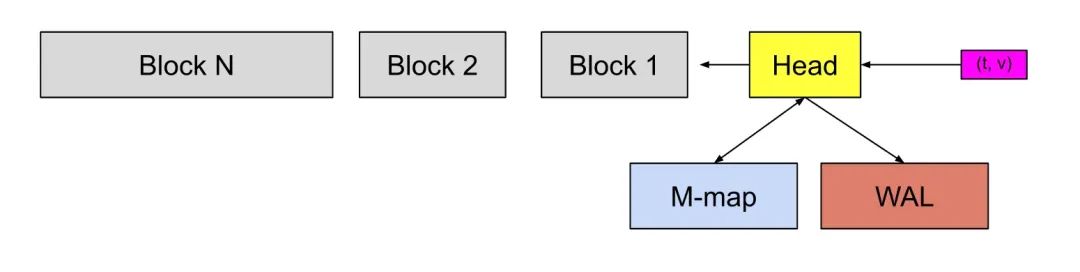
图中黄色的部分叫做head block,保存在内存里面,用来存储最新的数据,每个block初始都被设定为保留两个小时的数据,包括head block,不同的是,其他block是存储在硬盘上且不可变的,而head block存在内存里,可以被修改不断增长,(t,v)代表着Prometheus刮擦的数据,数据会先放在内存里面的head block,当head block的数据存储量达到2h的1.5倍即3h的数据时,他将被重新分配为2h和1h的部分,2h数据的部分,会落盘,固定为不可变的block 1存储在硬盘里。剩下的1h数据部分的继续在内存里作为head_block继续被添加上新的数据,直到下个循环。
在数据写到head block的同时也会将该操作以及数据记录到wal里面,以防止Prometheus停止时,保存在内存中的数据丢失。当数据写入head block时,也会写入wal,当head block写满被截断落盘时,wal内部的有关落盘数据的记录部分会被同时删除,但是他们的操作不是原子性的。
Head块
如上述所讲,Head block位于数据库的内存部分,灰色块是磁盘上不可更改的持久块,还有一个蓝色的部分叫做M-map,在Prometheus 2.19的版本中,增加了head block的内存映射M-map的数据格式,减少了内存的使用量。
如下图所示,将head_block的部分进一步细化,即将内存中的head_block进一步分为多个chunk,更细颗粒度地将数据落盘。
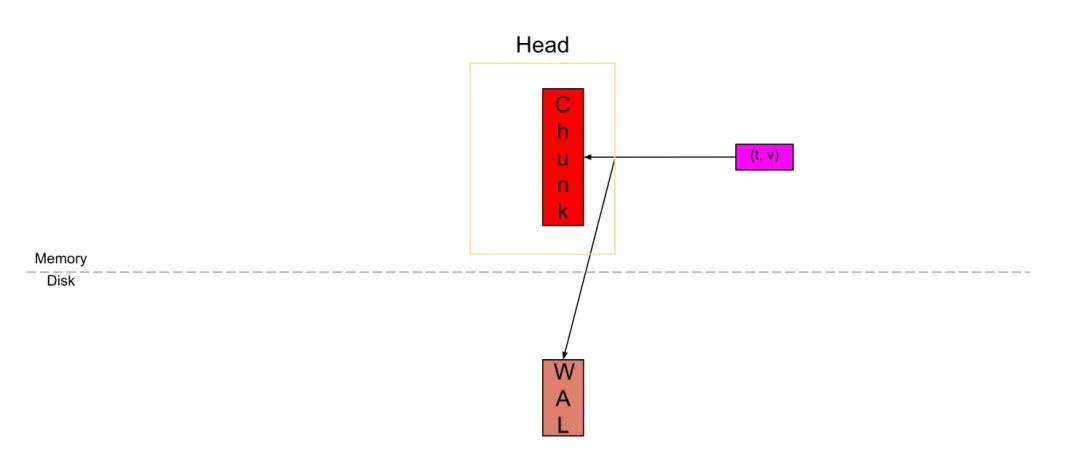
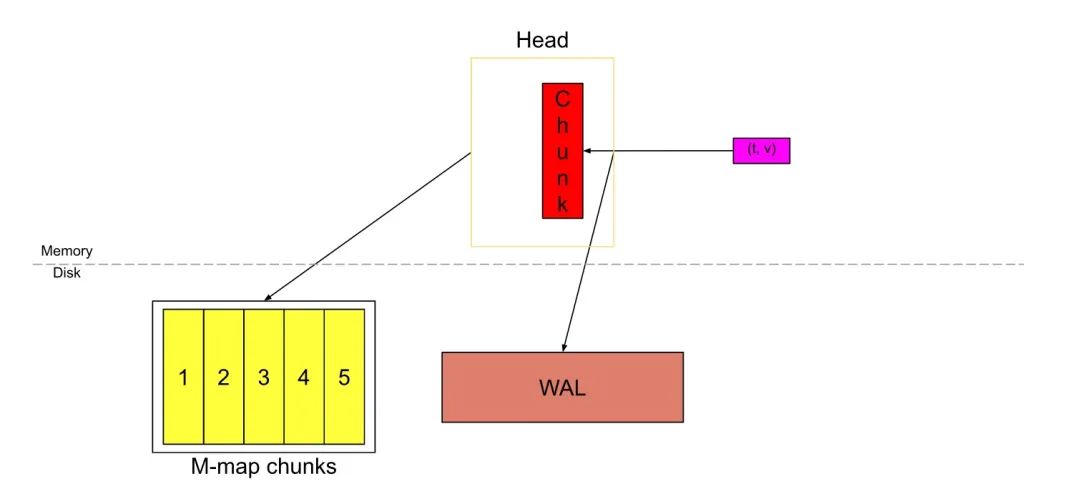
Prometheus刮擦的数据首先会被存储在位于内存中的head_block的"active chunk",这个active chunk是唯一可以主动写入数据的单元。
在数据写入active chunk的同时,也会将其记录到位于磁盘的预写日志wal中,以确保持久性,当Prometheus意外停止后,可以从wal中恢复数据,不至于造成数据丢失。
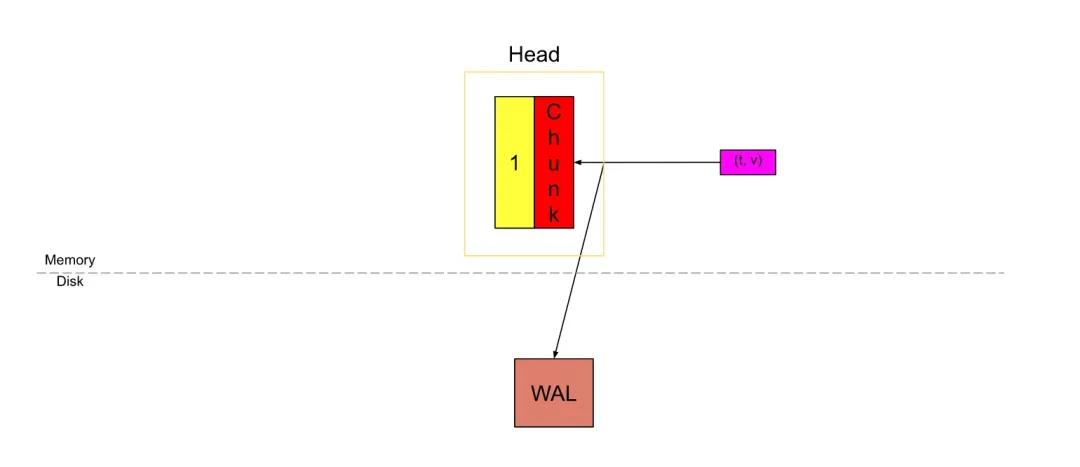
一旦chunk填满,默认120个sample(一次刮擦的数据),或是到了chunk/block范围,默认为chunkRange(每个块保存数据的大小,默认情况下为2h),则将剪切一个新chunk,并称旧块为“full”。如果将scrape间隔为15秒,因此120个sample(完整块)将跨越30m。
黄色数字为1的块是已填充的完整chunk,红色块是已创建的新chunk。
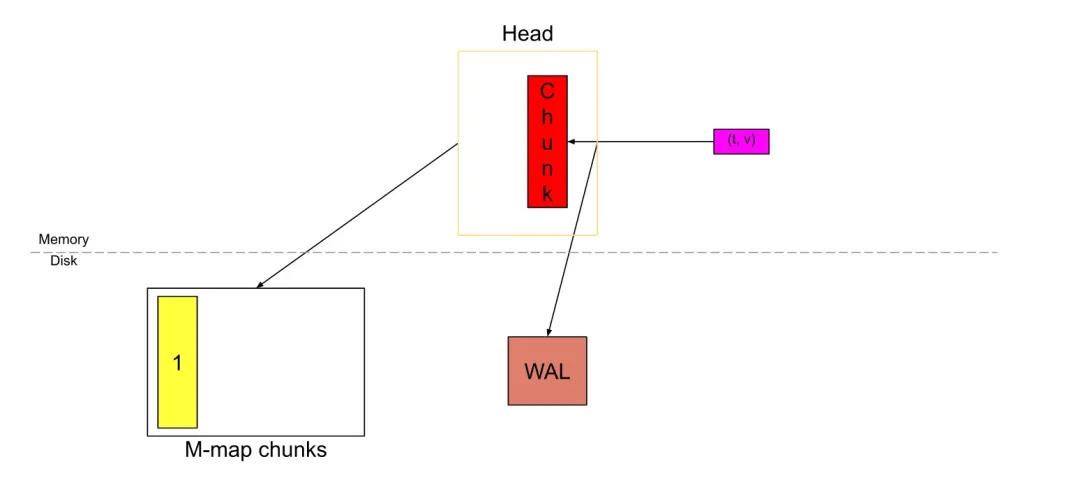
从Prometheus v2.19.0开始,Prometheus引入了内存映射,将head_block中已填充的完整的chunk,刷新到磁盘并从磁盘进行内存映射,同时仅将引用存储在内存中。通过内存映射,可以在需要时使用该引用将chunk动态加载到内存中。这是操作系统提供的功能。通过引入内存映射,减少了Prometheus的内存消耗,虽然填充完毕的chunk会被刷到磁盘上,但是对于该部分的操作预写入日志不会被删除,直到该chunk所属的block完整落盘。
以此类推,同样,随着新sample的不断涌入,新的chunk也被切割,然后将它们刷新到磁盘并映射到内存。
一段时间后,“ Head”块将如下所示。如果我们认为红色chunk几乎已满,则Head中有3h的数据(6个chunk,每个块跨越30m)。也就是chunkRange * 3/2。
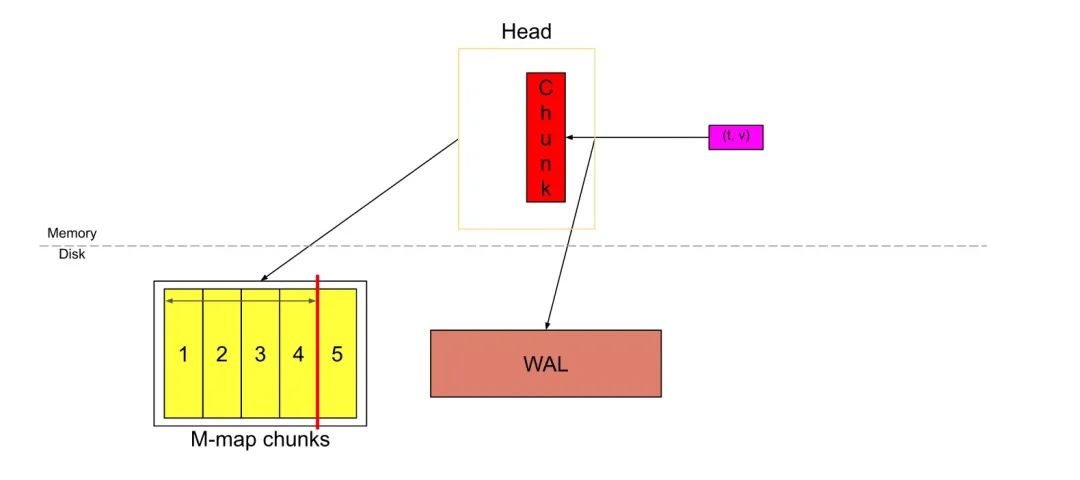
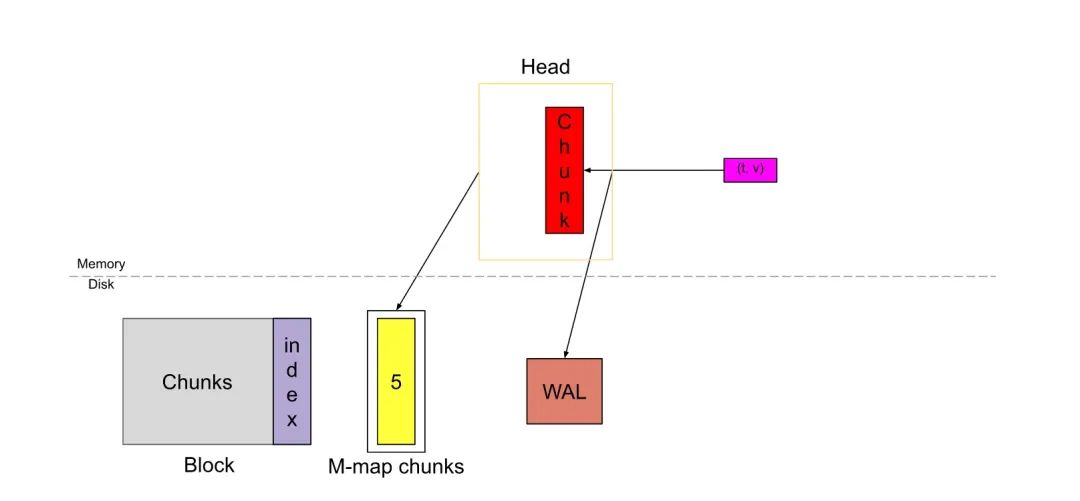
当Head中的数据跨过chunkRange * 3/2时,数据的第一个chunkRange(此处为2h)被压缩为一个持久块。如果你在上面注意到,wal此时将被截断并创建一个“检查点”(图中未显示)。此时head_block就会被切割成两部分,一部分是2h的数据,此部分会被压缩成一个不可变的block存储在硬盘里,同时此部分位于wal文件夹下的的操作事件日志会被删除,以及此部分的内存映射也会被删除,另一部分数据会继续重复之前在head_block发生过的事情,一部分被刷新到硬盘中,一部分存储在内存中等待数据被添加。
Sample的scrape,内存映射,压缩以形成持久性块的这一循环继续进行。这就形成了Head块的基本功能。
对于head_block的index文件,它在内存中并存储为倒排索引。当Head块的压缩发生时,创建了一个持久性块,Head块被截断以删除旧的块,并且对该索引进行了垃圾回收,以删除Head中不再存在的任何系列条目。
如果TSDB必须重新启动(优雅地或突然地),它将使用磁盘上内存映射的块和wal重播数据和事件,并重新构建内存中的索引和块。
wal和checkpoint
介绍
在head block中,提到为了持久性,我们首先将传入的sample写到预写日志(wal)中,并且当该wal被截断时,将创建一个检查点。
wal基础
wal是数据库中发生的事件的顺序日志。在写入/修改/删除数据库中的数据之前,首先将事件记录(附加)到wal中,然后在数据库中执行必要的操作。
不论出于何种原因,即使是机器或程序崩溃,也都会在此wal中记录事件,您可以按照相同的顺序重播这些事件以恢复数据。这对于内存数据库尤其有用,在内存数据库中,如果数据库崩溃,则如果不是wal,则内存中的所有数据都会丢失。
预读写日志的机制在关系型数据库中被广泛使用,为数据库提供持久性。同样,Prometheus通过wal,为其Head block提供可用性。Prometheus还使用wal进行正常重启以恢复内存中状态。
在Prometheus中,wal仅用于记录事件并在启动时恢复内存中状态,它不以任何其他方式涉及读取或写入操作。
在Prometheus TSDB中写入wal
在磁盘上的格式
默认情况下,wal存储为带有128MiB的编号文件序列。这里的wal文件称为“segment”。
```text
data
└── wal
├── 000000
├── 000001
└── 000002
```
文件的大小必然会使旧文件的垃圾回收更加简单。可以猜到,序列号总是增加的。
wal截断和检查点
我们需要定期删除旧的wal段,否则,磁盘最终将填满,TSDB的启动将花费大量时间,因为它必须重播此wal中的所有事件(其中大部分会被丢弃,因为已经过期了)。
wal截断
wal截断在Head块被截断之后立即完成(有关Head截断的信息,请参见head block部分),无法随意删除文件,并且删除操作会针对前N个文件进行,而不会在序列中造成间隔。
由于写请求可以是随机的,因此在不遍历所有记录的情况下确定wal段中样本的时间范围既不容易也不高效。因此,我们删除了片段的前2/3。
```text
data
└── wal
├── 000000
├── 000001
├── 000002
├── 000003
├── 000004
└── 000005
```
在上面的示例中,文件000000 000001 000002 000003将被删除。
这里有一个陷阱:series记录仅写入一次,因此,如果盲目删除wal段,则会丢失这些记录,因此无法在启动时恢复这些series。另外,在前2/3段中可能还没有从头上截断一些sample,因此您也会丢失它们。
检查点
在截断wal之前,我们从那些要删除的wal段中创建一个“检查点”。您可以将检查点视为经过过滤的wal。考虑时间T之前的数据是否发生Head截断,以上述wal布局为例,检查点操作将按顺序遍历000000 000001 000002 000003中的所有记录,并且:
- 删除不再在Head中的series的所有series记录。
- 删除时间T之前的所有sample。
- 删除T之前时间范围内的所有逻辑删除记录。
- 保留与在wal中找到的series,sample和墓碑记录相同的方式(以它们在wal中出现的顺序)。
删除操作也可以是重写操作,同时从记录中删除不必要的项目(因为单个记录可以包含多个series,sample或逻辑删除)。
这样,您就不会丢失仍在Head的series,sample和墓碑。该检查点名为checkpoint.X,其中X是在其上创建检查点的最后一个段号。
在wal截断和检查点之后,磁盘上的文件看起来像这样(检查点看起来又是另一个wal):
```text
data
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005
```
在新的版本里,如果有任何较旧的检查点,则此时将其删除。
wal重播
我们首先从最后一个检查点开始依次遍历记录(与它关联的最大数字的检查点是最后一个检查点)。对于checkpoint.X,X告诉我们需要从哪个WAL段继续重放,即X + 1。因此,在上面的示例中,在重播checkpoint.000003之后,我们从WAL段000004继续重播。
可能会想为什么在删除wal段之前,为什么我们需要在检查点中跟踪段号。关键是,创建检查点和删除wal段不是原子的。在两者之间可能发生任何事情,并防止wal段删除。因此,我们将不得不重播将被删除的wal片段的另外2/3,从而使重播速度变慢。
在谈论单个记录时,将对它们执行以下操作:
- `Series`:使用与记录中提到的相同的引用在Head中创建series(以便我们以后可以匹配sample)。普罗米修斯可以通过映射参考来处理同一series的多个series记录。
- `Sample`:将此记录中的sample添加到Head。记录中的引用指示要添加的series。如果找不到引用series,则跳过该sample。
- `Tombstones`:通过使用引用来标识series,将这些Tombstones存储回Head。
读写wal的底层细节
当大量写入请求时,您要避免随机写入磁盘,以避免写入放大。此外,在读取记录时,您要确保它没有损坏(在突然关闭或磁盘故障时很容易发生)。
Prometheus具有wal的实现,其中一条记录只是一个字节切片,而调用者必须负责对记录进行编码。为了解决以上两个问题,wal软件包执行以下操作:
- 数据一次一页地写入磁盘。一页长32KiB。如果记录大于32KiB,则将其分解成较小的块,每块接收一个wal记录头,以便进行簿记,以了解该块是记录的结尾,开始还是在中间。
- 记录的校验和将附加在末尾,以检测读取时的任何损坏。
wal软件包负责无缝地连接记录片段,并在遍历记录以进行重放时检查记录的校验和。
默认情况下,wal记录不进行重压缩(或完全压缩)。因此,wal软件包提供了使用Snappy(现在默认启用)压缩记录的选项。此信息存储在wal记录头中,因此,如果计划启用或禁用压缩,则压缩和未压缩的记录可以一起存在。
临时性文件
在最上面的存储中可以看到有很多个临时性文件,在我们的实际使用和参考相关社区问题,发现会有两种,一个是检查点会产生临时文件,还有一种是持久化的block会有临时性文件产生。
可以分析出以下几点:
1. wal的检查点会在head block截断时产生,用来遍历过滤要被删除的wal文件。
2. 保存在本地磁盘block是不可变的,如果需要修改删除或者改变数据只能通过生成新block的方式进行。
3. 在Prometheus中如果操作失败,会产生tmp的临时文件,后续且不会删除,新版本会删除掉。
4. 检查点的tmp文件夹,就是因为检查点的操作失败,将checkpoint改了个名加上了.tmp后缀。
5. block后缀类似,只不过是发生在块压缩的时候,在将小块合并成更大的块的时候失败了,就会产生tmp文件。
6. 新版本的Prometheus在重启的时候会删除掉之前因为错误留下的tmp文件夹,从而减少磁盘占用。
-End-