张传尧1,2, 司世景1, 王健宗1 , 肖京1
1 平安科技(深圳)有限公司
2 中国科学技术大学
张传尧, 司世景, 王健宗, 等. 联邦元学习综述[J]. 大数据, 2023, 9(2): 122-146.
[左上]欢迎引用[左上]
随着移动设备的普及,海量的数据在不断产生,合理有效地利用这些数据成为重点研究方向。由于隐私政策的保护,很多数据不能被轻易地获取,数据间相互隔离,形成了一个个数据“孤岛”。如何建立数据“孤岛”间沟通的桥梁,打破数据之间的界限,成为一个热点问题。 联邦学习 为解决该问题提供了一个新的方向。
联邦学习在满足数据隐私要求、保护数据安全、遵守政府法规的前提下,进行数据的使用和建模,即通过只在各节点间传递模型参数,而不分享节点间数据的方式训练一个共享的数据模型。许多早期的研究旨在在数据不公开的情况下分析和利用分布在不同所有者手中的数据。早在20世纪80年代,对加密数据进行计算的研究就已经展开,直到2016年,谷歌研究院正式提出联邦学习这一术语,对分布式数据的隐私保护研究才开始归于一类。 联邦学习成为解决数据隐私保护问题的一个有力工具。
在传统的机器学习中,通常需要大量的数据样本进行训练,才能获得一个较好的模型。例如在神经网络中,需要大量的标签数据进行模型训练,才能使模型具有良好的分类效果,并且一个训练好的神经网络模型往往只能解决某一类问题。在某些情况下,数据本身是稀缺的,大量的有标签数据是不容易获得的,往往只有少量的样本能够进行数据训练。人类可以通过少量的某一类动物的图片学习到这种动物的概念,再见到这种动物时能够很快地识别出来。这种通过少量样本图片快速学习到新概念的能力,对应机器学习中 元学习 的概念。元学习的训练目标是训练一个模型,这个模型只需要通过少量的数据和迭代训练就可以快速适应新的任务,即训练一个具有很强适应能力的模型。元学习能够很好地解决训练数据不足的问题。 元学习算法由两个部分构成 :基础学习者和元学习者。基础学习者在单个任务的水平上工作,其特征在于只有一小组标记的训练图像可用。元学习者从几个这样的情节中学习,目的是提高基础学习者在不同情节中的表现。一般认为元学习系统应当具有以下3个特征:拥有一个基础学习子系统;具有能够利用先前的经验获取知识的能力;能够动态地选择学习偏差。
元学习的早期研究工作主要集中在教育科学相关的领域 ,主要研究并控制自身的学习状态。随着机器学习的发展,元学习开始进入机器学习领域。元学习的第一个例子出现在20世纪80年代,参考文献提出了一个描述何时可以动态调整学习算法归纳偏差,从而隐式地改变其假设空间元素顺序的框架。参考文献提出具有两个“嵌套学习层”的元学习方法。元学习可以跨越多个问题进行经验的积累,以适应基础假设空间。
考虑联邦学习在解决异构数据训练方面的需求和元学习在多任务模型上的良好表现,利用元学习训练一个个性化的联邦学习算法成为一种选择。现有的联邦学习主要是利用不同的数据节点联合训练一个统一的全局模型,这种统一的全局模型不利于解决数据的非独立同分布问题。联邦元学习为不同的数据节点训练单独的数据模型,这种多模型的训练方式可以直接捕捉客户端间的数据不平衡关系,使它们很适合解决联邦学习的数据不平衡问题。
1 联邦学习简介
1.1 问题定义
联邦学习在满足数据隐私要求、保护数据安全、遵守政府法规的前提下,进行数据的使用和建模,即通过只在各节点间传递模型参数,而不分享节点间数据的方式训练一个共享的数据模型。联邦学习不需要交换各数据节点间的数据,各节点间仅交换共享数据模型的参数,以保护用户的隐私安全。
定义 n 个数据拥有者{ f 1 ,f 2 ,…,f n},不同数据拥有者 fi 的本地目标用 Fi(ω) 表示,它们各自拥有自己的数据{ D 1 ,D 2 ,…,D n},并希望利用这些数据训练机器学习模型。传统的机器学习方法是利用数据 D = D 1∪ D 2∪…∪ D n 训练一个机器学习模型 ω sum。在联邦学习中,服务器端使用聚合函数G(·)聚合来自不同数据拥有者的模型参数。数据拥有者在保护自身数据安全、互相不交换本地数据的情况下共同训练一个模型 ω fed。联邦学习的全局目标定义如式(1)所示:
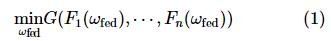
模型 ω fed的精度 v fed应当非常接近模型 ω sum的精度 v sum。如果存在非负实数δ使得式(2)成立:
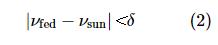
则称联邦学习算法具有δ精度损失。
1.2 联邦学习的训练过程
随着联邦学习研究的开展,各种各样的联邦学习框架被开发出来。例如微众银行的FATE已经覆盖了3种联邦学习: 横向联邦学习、纵向联邦学习、联邦迁移学习 。谷歌开源的Tensor/IO已经可以较好地支持横向联邦学习。尽管不同的算法框架(例如PySyft、FFL-ERL、CrypTen、LEAF、TFF)对联邦学习的支持不同,但是 联邦学习的主要训练过程均可以分为以下4步 。①中心服务器将最新的模型分发给各数据节点;②各数据节点利用本地数据更新模型;③各训练节点将更新的模型参数加密传送给中心服务器,中心服务器聚合各节点的参数,得到新的模型参数;④中心服务器将更新后的模型参数发送给各节点,节点更新本地模型参数,并进行下一轮训 练。联邦学习训练过程如图1所示。
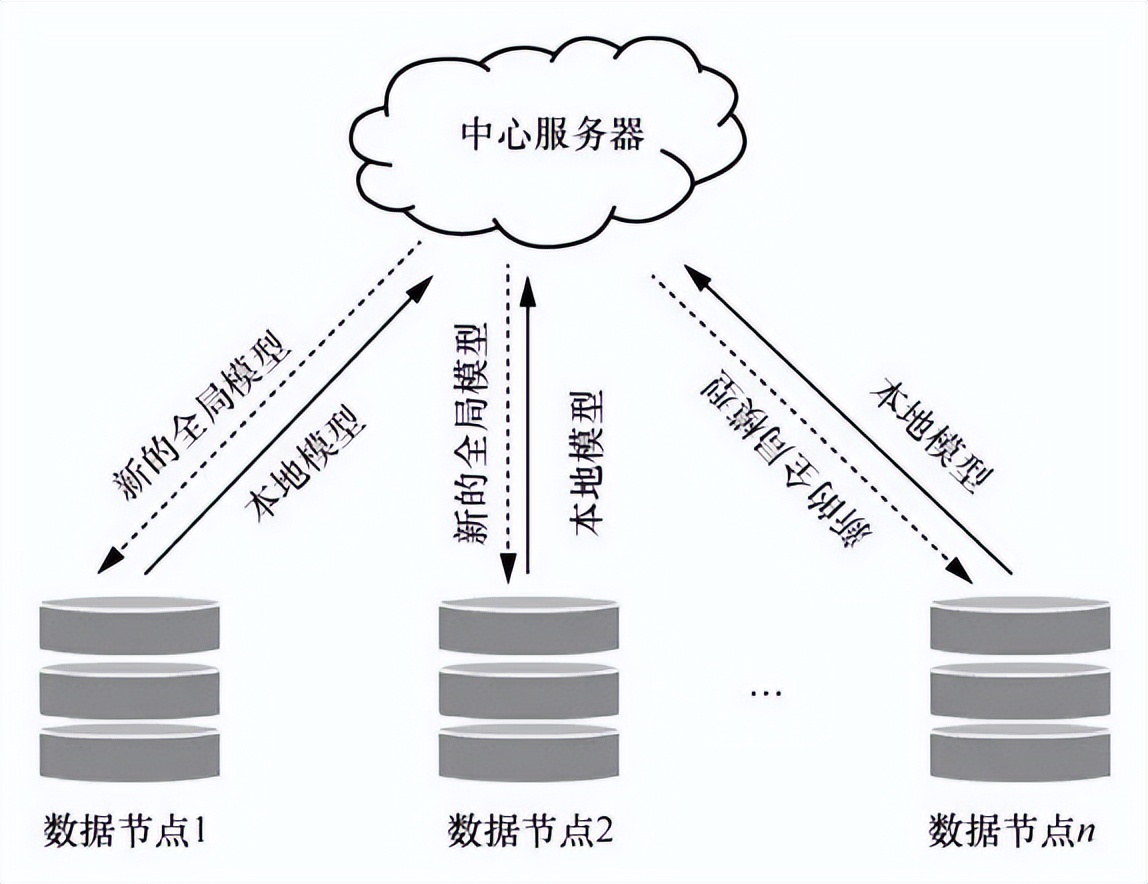
图1 联邦学习训练过程
1.3 联邦学习特点
联邦学习与传统机器学习存在很大不同,具体见表1。联邦学习的分布式环境设置导致不同数据节点的地理位置可能不同,用户的使用习惯存在差异,从而影响数据的分布。不同数据节点间是非独立同分布的,任何一个数据节点都不能代表整个数据集的分布。设备环境是否稳定也是影响联邦学习的一个重要因素,有限的网络通信速率要求找到一种合适的方式提高设备间的通信效率,同时还要避免因环境不稳定导致的设备随机加入与退出。 隐私保护是联邦学习最基本的属性要求 ,当中间结果与数据结构一起暴露时,可能造成数据的泄露。因此如何解决数据非独立同分布问题,提高通信效率,如何进行隐私保护成为联邦学习的关键。

1.3.1 数据隐私保护
隐私性是联邦学习的基本属性 ,如果不能做到对数据的隐私进行有效保护,联邦学习将失去可靠性,不同的数据“孤岛”也不会将自己的数据贡献出来用于数据训练。联邦学习在参数更新过程中,交换了工作的中间结果,因此不同数据方更容易受到推理攻击,敌对的参与方可以推断出训练数据子集的相关属性。在数据交换时,隐私保护的方式有很多种,例如在机器学习期间通过加密机制下的参数交换来保护用户数据隐私,或者使用差分隐私的方式保护数据。安全多方计算、安全聚合也是常用的隐私保护手段。其中,使用差分隐私方式保护数据隐私的方法通过向数据加入噪声的方式掩盖真实的数据,但是加入的噪声可能会影响最终结果的准确度。如何确定加入的噪声量是一个值得研究的问题,加入的噪声太多会导致计算结果失去准确性,加入的噪声不足则导致隐私保护效果不好。
1.3.2 数据非独立同分布
身份、性格、环境的差异导致由用户产生的数据集可能存在很大的差异,训练样本并不是均匀随机地分布在不同的数据节点间的。不平衡的数据分布可能导致模型在不同设备上的表现出现较大偏差。因此在进行联邦学习前,如何选取有效的数据集进行数据处理是一个重要的问题。 要解决联邦学习中的数据非独立同分布问题,主要的思路有两种 , 一种 是通过优化模型聚合的方法降低数据不平衡带来的影响, 另一种 是通过优化本地模型的更新过程解决联邦学习的统计挑战问题。参考文献提出了一种基于迭代模型平均的深层网络联合学习方法,该方法对于不平衡和非独立同分布是稳健的。参考文献提出通过每个设备上的类别分布和人口分布之间的地球移动者距离来量化数据集间的差异,并创建一个在所有边缘设备之间全局共享的数据子集来改进对非独立同分布数据的训练。
1.3.3 通信环境受限
在联邦学习中,中心服务器与计算节点间的物理距离很远,通信成本较高,且由于计算节点环境的不稳定性,可能随时存在计算节点加入和退出的情况,因此 联邦学习一般应选取网络环境稳定免费且计算节点空闲时进行 。通信成本成为制约联邦训练的主要因素,因此如何对设备间的通信进行压缩是一个值得研究的问题,可以通过减小客户端传送到服务器的对象的大小、减小从服务器向客户端广播的模型大小、客户端从全局模型开始培训本地模型等方法降低对通信链路的要求。参考文献中给出两种降低上行链路通信成本的方法:结构化更新和草图更新。结构化更新直接从使用较少数量的变量(如低秩或随机掩码)的受限空间中学习更新;草图更新先模型更新,然后在发送到服务器之前,使用量化、随机旋转和二次采样的组合对其进行压缩。
1.4 联邦学习算法
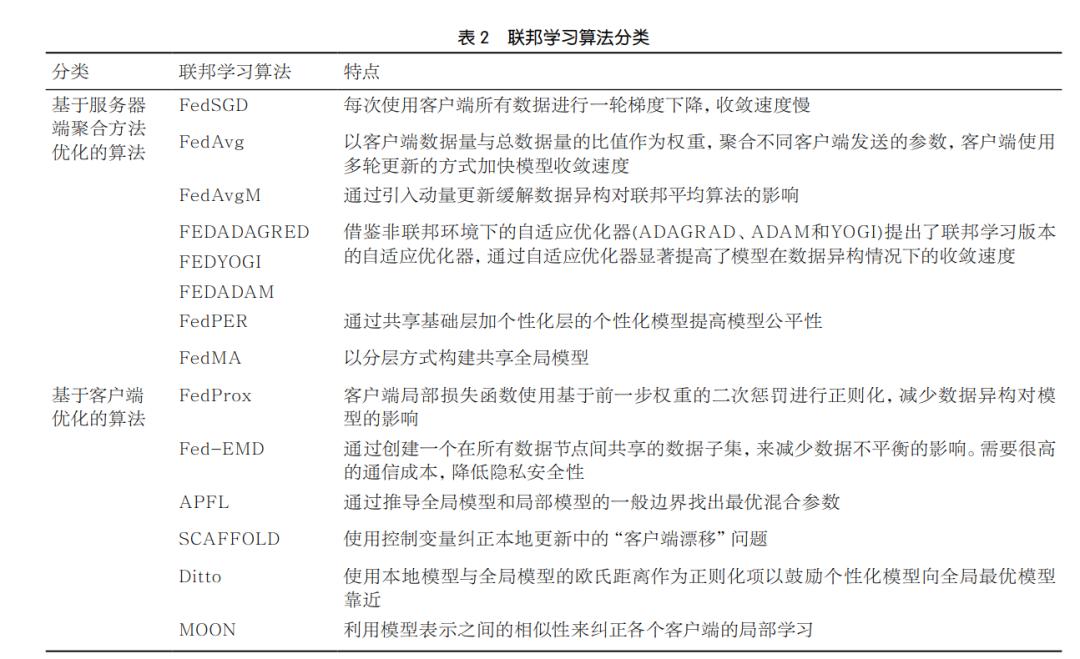
联邦学习的更新过程主要分为服务器端更新和客户端更新两部分,按照算法对联邦学习改进的阶段,可以将 联邦学习算法分为两类:基于服务器端聚合方法优化的算法和基于客户端优化的算法 。
联邦学习算法分类见表2。
2 元学习介绍
2.1 元学习定义
很难给出元学习的确切形式化定义。一般来说元学习就是学会去学习,希望训练一个通用的学习算法,该算法可以很好地适应新的任务,元学习研究系统如何通过经验提高效率,目标是了解学习本身如何根据学习领域灵活变动,元学习往往以小样本学习和对任务的快速适应作为切入点。
人类可以通过几张动物的照片快速地学习到该动物的概念,这对应元学习的少镜头学习(few-shot learning,FSL)情景。人类甚至可以在没有图像的情况下,仅仅凭借描述就能认识到新的类别,这对应元学习的零镜头学习情景。 元学习按照支持集每类样本的数量可以分为3类 :单镜头学习(one-shot)、k镜头学习(k-shot)、零镜头学习(zero-shot)。
元学习一般训练过程如图2所示。培养机器利用先前经验快速适应新任务的能力,就是让机器学会学习。
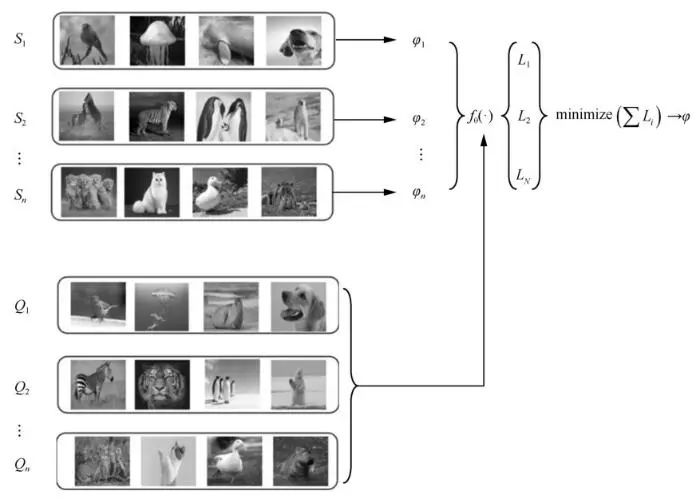
图2 元学习一般训练过程
2.2 元学习分类
传统的机器学习目的在于让机器学会理解事物的异同以区分不同的事物,而不是学会识别没见过的事物。元学习的目的是教会机器如何利用先验知识快速学习新知识,快速掌握识别新物体的能力。根据训练数据有无标签, 可以将元学习分为监督元学习和无监督元学习两种 ,如图3所示。

图3 元学习分类
2.2.1 无监督元学习方法
当训练数据没有标签时,无监督元学习常采用一种显式的方式自动构建数据集,通过构建虚标签的方式,将无监督学习转换为监督学习。参考文献[38]为了解决训练数据无标签问题,提出了一个分阶段训练集群自动构造任务(clustering to automatically construct tasks, CACTUs)算法,其先在无标签训练数据上使用无监督训练方法学习一个特征表示器,然后通过聚类的方式在无标签数据上进行聚类划分,并生成伪标签。其通过伪标签构建元学习任务,在元学习任务上训练常规的监督元学习模型,如模型不可知元学习算法(model-agnostic meta-learning,MAML)、原型网络算法(prototypical networks,ProtoNet)等。与CACTUs算法分阶段训练的过程不同,参考文献提出一种端到端的无监督元学习(unsupervised meta-learning with tasks constructed by random sampling and augmentation,UMTRA)算法,其通过数据增强的方式为每个图片生成一个增强数据,并将原数据作为支撑集,将增强图片作为查询集,构建N类单镜头(N-way-1-shot)任务。UMTRA在无标签数据上的分类准确度已经非常接近有标签数据集上MAML模型的分类准确度。
2.2.2 监督元学习方法
监督元学习旨在根据有限的数据信息,快速学习适应新任务的能力,根据算法分类,可以 将监督元学习的方法分为以下5种 :基于优化器的方法、基于记忆存储的方法、基于基础泛化模型的方法、基于度量学习的方法、基于数据增强的方法。
(1)基于优化器的方法
基于优化器的方法旨在通过学习一个更好的优化器加快学习过程 。参考文献中提出使用一个基于长短期记忆网络(long short term memory,LSTM)的元学习者来学习一个更新规则,这个更新规则可以被看成一种新的类似于但不同于梯度下降的优化算法。在参考文献中RL2 (fast reinforcement learning via slow reinforcement learning)利用一个慢速调整的强化学习方法去训练一个快速调整的强化学习,达到学会学习的目标,即用一个强化学习去学习一个强化学习算法。参考文献中提出了一种加快神经网络训练速度的方*L法**TL(learning t o learn by gradient descent by gradient descent)以实现快速学习,通过以往的神经网络学习的任务预测梯度,文章通过为梯度下降算法训练一个学习器以加快梯度下降算法的收敛速度。
(2)基于记忆存储的方法
先验知识对于后续任务具有重要作用, 合理利用先验知识可以帮助模型快速适应新的任务 。参考文献[44]提出了一种带有记忆增强神经网络的元学习(memoryaugmented neural network,MANN)算法,该算法利用外部存储器进行样本特征的保存,使用元学习算法改进单元的读取和写入方式,并采用错位匹配的方式避免在训练过程中记住样本的相应位置。权重的缓慢更新实现了网络的长期记忆功能,并利用外部存储实现短期记忆,最终实现元学习的快速训练。在参考文献中,作者引入时间卷积网络访问之前的特征信息提出了一种元学习模型简单神经注意力学习器(simple neural attentive learning, SNAIL),使其可以在某个固定的时间内使用更加灵活的计算。通过时间卷积网络和注意力机制的结合,网络可以更加准确地在先前的信息中进行选择。
(3)基于基础泛化模型的方法
基于基础泛化模型的方法旨在学习一个可以快速适应新任务的基础模型,当面对新任务时,仅仅通过简单的几步梯度下降就能获得快速适应新任务的模型 。参考文献提出一种模型无关(MAML)的算法。MAML算法的关键在于训练一个良好的模型初始化参数,当遇到一个新的任务时,只需要使用很少的样本,进行几次简单的梯度下降,就能获得一个能适应新的任务的模型,MAML算法训练过程如图4所示。原始的MAML算法包含二阶求导,这就需要对内循环的高阶导数进行计算和保存。隐式模型不可知元学习算法(implicit model-agnostic meta-learning, iMAML)通过推导出外循环的梯度解析式,解决了MAML算法多步梯度消失、内循环存储和高阶求导的问题。参考文献将进化策略(evolutionary strategies,ES)应用于MAML算法,从而避免内层循环的二阶导数计算。基于评估策略的模型不可知元学习(evolutionary strategies model-agnostic metalearning,ES-MAML)算法使用确定性的策略避免了很多在随机策略情况下反向传播引起的问题。Reptile算法将MAML算法的两次求导过程简化为一次,直接使用参数差值方向决定外循环更新方向。潜在的嵌入优化算法(latent embedding optimization,LEO)利用编码器和关系网络将样本数据投影到一个低维空间,在内循环中对低维特征向量直接更新,并将特征向量通过解码器获得一个条件概率分布,通过随机采样获得参数。
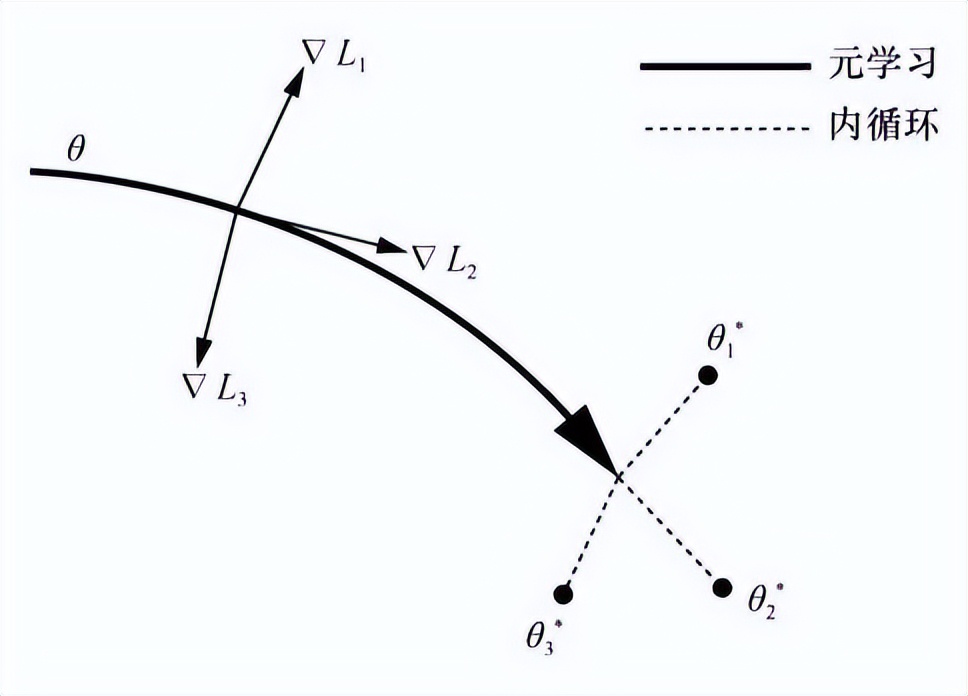
图4 MAML算法训练过程
(4)基于度量学习的方法
基于度量学习的方法旨在获得一个强大的特征提取器,通过在特征空间中不同样本间的距离进行分类 。参考文献设计了一个元评价(meta-critic)网络,该网络由核心价值网络(meta value network)和任务行为编码器(task-actor encoder)组成。使用任务编码通过批评网络驱动对目标网络的监督,而不是合成其权重。匹配网络通过对比数据间的相似度来判断数据类别。原型网络示意如图5所示,对每个数据进行提取特征,并将每个类别的特征均值作为该类别的原型,通过判断样本特征到不同类别的原型的距离来判断样本的类别。匹配网络、原型网络、孪生网络都是通过计算特征向量间的距离判断样本类别的。而关系网络提出使用神经网络计算样本间的匹配程度,首先对查询集与支持集中的样本进行特征提取,然后进行拼接,将拼接后的特征输入神经网络计算出关系得分。
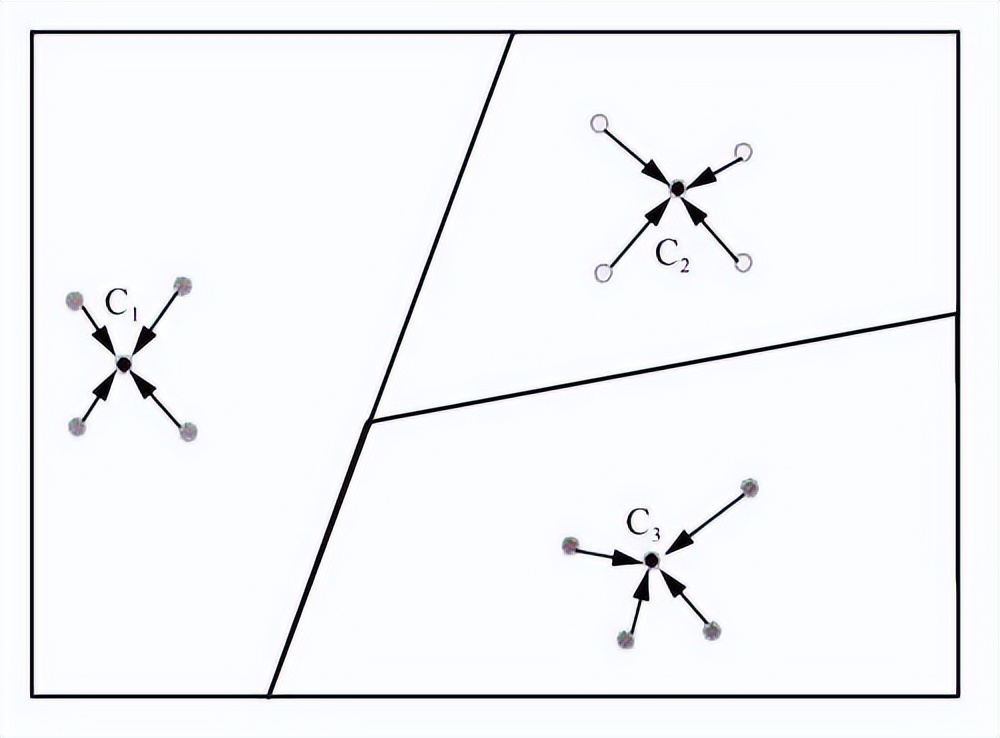
图5 原型网络示意图
(5)基于数据增强的方法
元学习在解决小样本分类问题时, 面临的最大挑战来源于训练数据不足 ,通过不同的数据增强方式扩展训练数据集成为一种选择。参考文献提出了一种分离光照网络(separating-illumination network,Sill-Net),该网络可以针对图片分离光照特征,并通过在特征空间使用该网络分离光线的影响来增强训练样本。参考文献提出了一个统一的元数据增强框架并在此框架下解释了现有的增强策略。参考文献通过将样本数据增强策略作为样本重加权问题来学习一个具有样本感知能力的元数据增强策略(sample aware data augmentation policy, MetaAugment),该策略网络通过捕捉样本间的不同性来评估不同样本增强策略的有效性。参考文献为少镜头学习提出了一个简单通用的算法——基于对抗性方法的少镜头学习(anadversarial approach to few-shot learning,MetaGAN)算法,其引入了一个以任务为条件的对抗生成器,其目标是生成与从特定任务中采集的真实数据无法区分的样本。参考文献结合小样本文本分类问题介绍了一种新的框架——数据增强元学习(meta-learning with data augmentation,MEDA),该框架引入一个球生成器用于生成新的数据样本,首先通过生成器计算支持集样本的最小球形封闭边界,然后在边界内合成新的数据样本。
3 联邦元学习介绍
3.1 联邦元学习定义
在联邦学习中,通过元学习算法,为每个客户端训练个性化的模型,降低模型在不同客户端上表现的差异,提高模型公平性,就称为联邦元学习算法 。元学习旨在学习和提取先前任务内部可转移的知识,训练一个良好的初始化模型,以快速适应新的任务。其防止过拟合并快速适应新任务的能力特别适合解决联邦学习中不同客户端数据分布不一致的问题,联邦元学习将每个客户端视作一个任务,训练一个良好的初始化模型,其可以在客户端上通过几步简单的梯度下降快速适应新的任务。元学习因其快速适应新任务的能力,表现出在解决联邦设置的系统和统计挑战问题的巨大潜力。联邦元学习算法与元学习方法不同,联邦元学习算法运行在分布式数据集上,数据不再是集中分布的,同时不同客户端与服务器的连接并不稳定,客户端的本地更新通过简单的平均聚合可能会导致元模型产生梯度偏差。
3.2 联邦元学习算法分类
联邦学习旨在利用不同客户端的数据联合训练一个全局模型,同时保护各个客户端隐私 。相较于只使用本地数据进行模型训练,联合利用多个客户端的数据可以提高模型的表现,但是在联邦学习环境中,由于不同客户端所处地理位置不同,个人用户可能受到不同的地域环境、风俗文化的影响,导致其本地数据间存在很大差异,数据是非独立同分布的。因此一个单一的全局模型无法满足所有用户的需求,具体问题如下。
①如何为不同用户提供不同的个性化模型是一个重要问题。在联邦学习中对客户端隐私进行保护,服务器不能随意检查客户端发送的数据,这使得联邦学习更加容易受到恶意攻击的影响。②如何提高联邦学习面对恶意攻击时的鲁棒性,加强联邦学习对于隐私数据的保护同样是一个重要问题。不同于集中式中心化训练,联邦学习中不同客户端距离分散,设备间性能差异巨大,服务器与客户端间的通信信道带宽有限,客户端的计算资源、设备电量、参与计算时间都十分有限。③如何为联邦学习制订一套合理的资源分配策略,以提高设备公平性、提高通信效率、加快收敛速度也是一个重要问题。联邦元学习算法分类如图6所示。
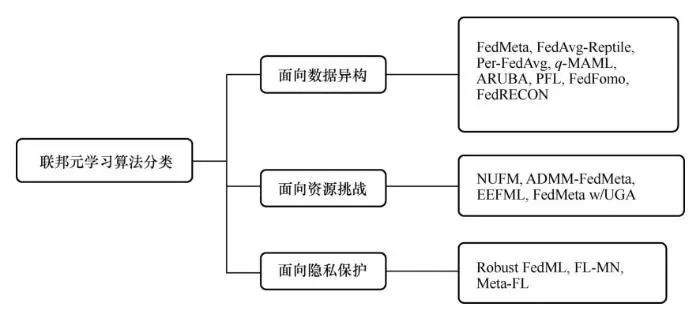
图6 联邦元学习算法分类
本节我们从以下3个问题出发,介绍近年来联邦元学习为解决这些问题所做的工作:①如何通过联邦元学习为不同用户提供个性化模型,解决联邦学习中的数据异构问题;②如何利用联邦元学习进行合理资源分配,提高联邦学习的通信效率,加快收敛速度;③如何利用元学习算法增强联邦学习面对恶意攻击的鲁棒性,保护数据隐私。
联邦元学习算法分类见表4。
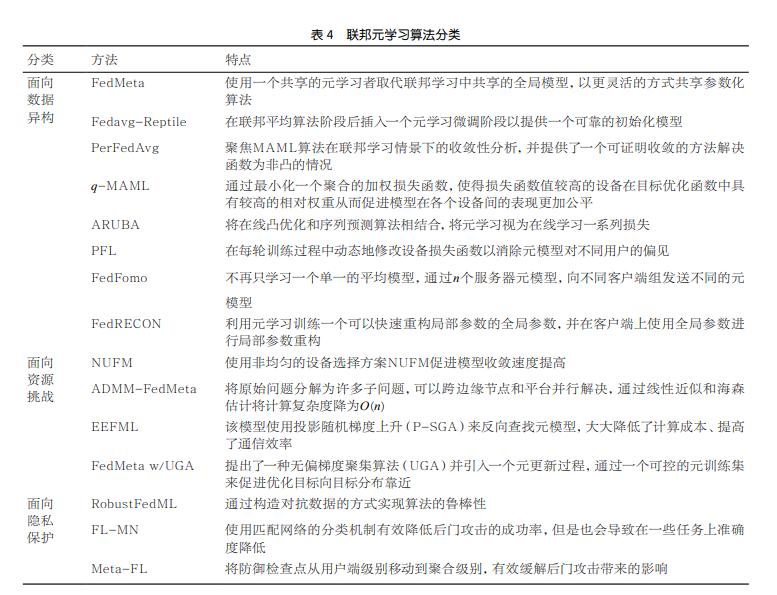
3.3 联邦元学习应用
相较于传统的联邦学习算法,联邦元学习因为其收敛快速、个性化能力强等优点被广泛应用到不同的领域,以下为现有的工作中联邦元学习算法的一些应用。
(1)信用卡欺诈检测
信用卡诈骗每年给银行带来数十亿美元的损失。然而由于对用户数据安全和隐私保护的需求,各个银行间无法共享数据集。面对不同银行间数据流动的限制,传统的利用集中数据训练的模型很难检测到信用欺诈的存在。因为仅约2%的交易活动存在欺诈可能,所以数据集往往是不平衡的。人类可以利用以往的经验很快地识别出信用卡欺诈行为(对应元学习的快速学习能力)。参考文献利用联邦元学习技术进行信用卡欺诈检测,该方法可以在不共享数据的情况下,通过使用联邦元学习算法聚合不同银行的信用卡欺诈检测模型的参数,构建一个共享的全局模型,从而保护不同用户的隐私信息,同时,文中提出了一种新的基于元学习的分类器以改进 三重态度量学习(triplet-like metric learning),该分类器可以同时与K个负样本进行比较。相比于其他最先进的信用卡欺诈检测模型FlowScope、新型信用卡欺诈检测策略(a realistic modeling and a novel learning strategy,RMNLS),该方法在检测准确度方面得了明显的提升。
(2)分布式通信设备数据处理
第6代通信技术旨在实现全球互联,通信需求也从太空扩展到大气、地面和海洋。水下通信的要求也越来越高,水下声音通信是最有效的水下信息传输方式。深度学习在解决水下声音信号恢复问题上取得了很好的效果,然而依然存在两个问题:设备是分布式的;在单个节点上的数据可能不足。参考文献提出一种基于声学无线电合作增强的联邦元学习算法以解决数据水下通信设备分布式连接和数据不足的问题,其只需要在本地数据集上通过几步梯度下降进行简单微调就能快速适应新任务的特性。ARC/FML算法可以从边缘节点快速更新网络,传递网络参数而不是发送节点数据的方式大大提高了分布式节点间的通信效率,并通过元学习算法提高机器学习在通信领域的鲁棒性。
(3)个性化联邦元学习推荐系统
相较于数据集中的传统推荐系统而言,联邦推荐系统在保护数据隐私、整合利用数据方面具有很大优势。然而以往的联邦推荐系统没有考虑到设备在计算资源、通信带宽方面的限制,提出的推荐模型过于庞大,很难在移动设备上运行。同时,一个统一的全局推荐模型很难利用用户间的协同过滤信息。为了解决上述问题,参考文献引入一个联邦矩阵分解算法元矩阵分解(meta matrix factorization, MetaMF),该方法在服务器上使用元推荐模型生成私用项嵌入和评级预测模型以更好地利用联邦推荐系统中的协同过滤信息,同时该方法可以在不损失性能的情况下减少模型参数。
4 总结和展望
元学习由于其快速适应新任务的能力,可以为联邦学习数据异构问题提供很好的解决方案,通过为每个客户端训练一个个性化模型解决联邦学习数据异构问题。同时联邦学习由于其分布式、重隐私的特性,很容易受到恶意攻击。联邦学习环境下,通信带宽有限、客户端上计算资源的限制等都是制约其发展的重要因素,通过引入元学习增强联邦学习面对恶意攻击的鲁棒性、合理分配资源都已经得到了广泛的研究。
随着人们对数据隐私保护重视程度的提高,机器学习中数据使用的安全性要求将越来越高。联邦学习作为数据隐私保护的重要方式,必将受到更多的重视。现有的关于联邦学习的研究只能应用于个别的机器学习模型,虽然对某个特定模型设计单独的算法可以使模型效果更好,但是一个通用、高效的联邦学习框架更加被需要,如何为不同节点训练不同模型成为一个重要课题。现有联邦学习算法的研究主要针对集中式的联邦学习架构,需要一个中心服务器,对于分布式联邦学习算法的研究还有待深入。
未来的研究难点在于如何解决联邦学习所面临的数据异构、隐私保护、通信环境不稳定的问题。 元学习在联邦学习数据异构方面将起到更加重要的作用。如何将元学习与联邦学习更好地结合,使元学习适应联邦学习面临的复杂环境仍然是一个重要的课题。现有的联邦元学习主要研究如何为不同客户端训练一个良好的初始化模型,但是这种从不同客户端学习可转移知识的方法在面临恶意客户端攻击时,相较于传统联邦学习算法可能会受到更大的影响,同时客户端的本地更新可能会使聚合的元模型产生梯度偏移。在隐私保护方面,利用基于度量的元学习算法增强元学习面对恶意攻击时的鲁棒性是一个引人注目的方向,但是向服务器发送度量模型参数可能会产生用户敏感信息的泄露。目前一些元学习算法受益于特定的模型结构,如何将元学习中与模型耦合度较高的元学习算法与模型解耦以更好地应用于联邦学习中仍然值得研究。元学习算法是参数敏感的,在联邦学习环境中,客户端的突然加入与退出、通信的突然中断都可能会对元模型造成不利影响。如何提高联邦元学习算法面对通信受限环境的鲁棒性也是一个重要的研究方向。同时元学习本身也有很多研究难点,如何使基础模型更好更快地适应新的学习任务,甚至适应跨领域的任务,以及在元学习的进化性、可解释性、连续性、可扩展性方面都还有很多工作需要进行。
--------END-------
联系我们:
Tel: 010-81055490
010-81055448
E-mail: bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
转载、合作:010-81055307
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中国科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,以及信息通信领域高质量科技期刊分级目录、计算领域高质量科技期刊分级目录,并多次被评为国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。