- 1 数值型1.1 数值类型的创建1.2 数值类型转换1.3 python内置的数学相关函数
- 2 布尔型
- 3 字符型string
- 4 列表(list)
- 5 元组(tuple)
- 6 字典(dict)
- 7 集合(set)
- 作业
计算机是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种
1 数值型
数值型分为以下两种类型:
- 整型整型长整型(2**62)
- 浮点型
- 复数
|
2 是一个整数的例子。长整数 不过是大一些的整数。3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 ** 10-4。(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。 |
3.x已不区分整型与长整型,统统称为整型
1.1 数值类型的创建
In [ 1 ]: a = 10 In [ 2 ]: b = a In [ 3 ]: b = 666 In [ 4 ]: print(a) 10 In [ 5 ]: print(b) 666
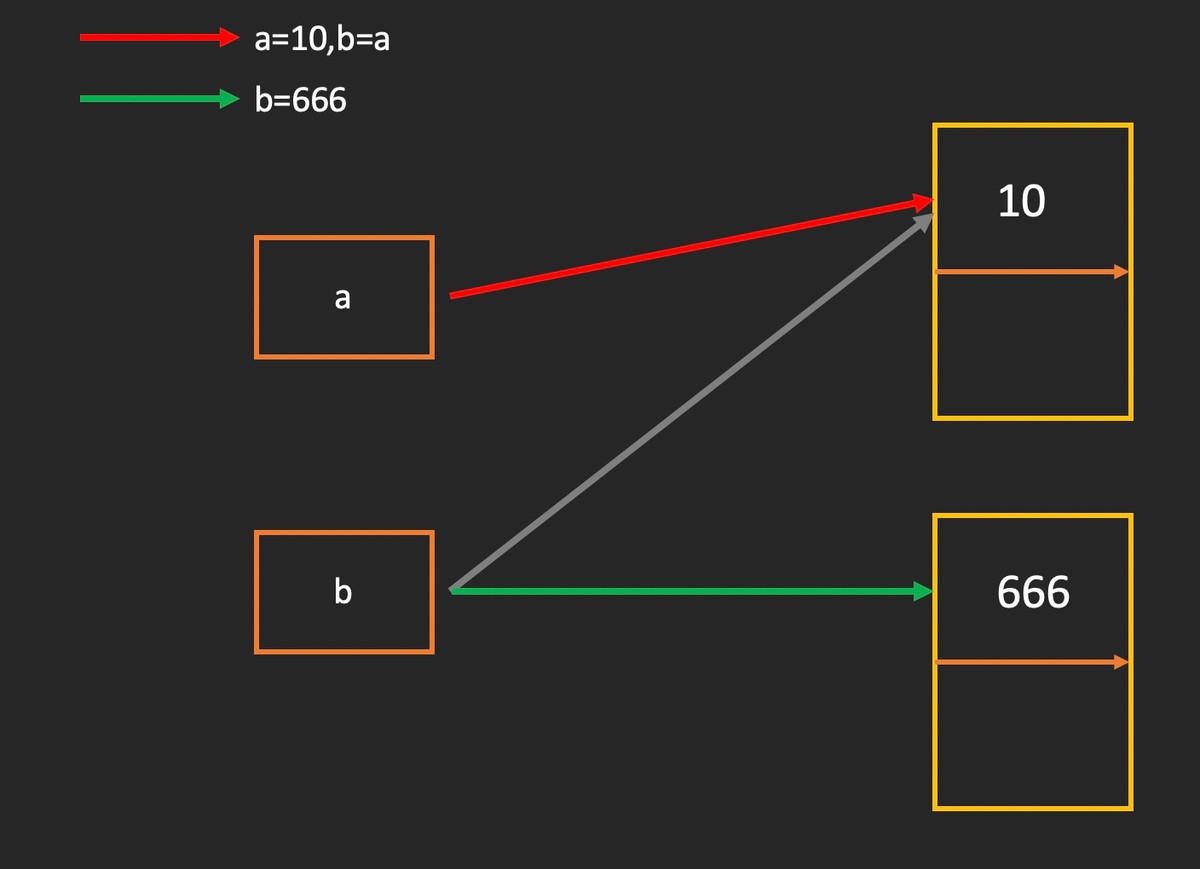
1.2 数值类型转换
In [ 1 ]: a = '3.14' In [ 2 ]: b = '100'
In [ 3 ]: type(a)
Out[ 3 ]: str In [ 4 ]: type(b)
Out[ 4 ]: str
In [ 5 ]: c = float(a) In [ 6 ]: d = int(b)
In [ 7 ]: type(c)
Out[ 7 ]: float In [ 8 ]: type(d)
Out[ 8 ]: int
1.3 python内置的数学相关函数
|
函数名 |
描述 |
|
abs(x) |
返回数字的绝对值,如abs(-10)结果返回10 |
|
ceil(x) |
返回数字的上入整数,如math.ceil(4.1)结果返回5 |
|
fabs(x) |
返回数字的绝对值,如math.fabs(-10)结果返回10.0 |
|
floor(x) |
返回数字的下舍整数,如math.floor(4.9)结果返回4 |
|
max(x1,x2,…) |
返回给定参数的最大值,参数可为序列类型 |
|
min(x1,x2,…) |
返回给定参数的最小值,参数可为序列类型 |
|
pow(x,y) |
计算x的y次幂,结果为x ** y运算后的值 |
|
round(x [,n]) |
返回浮点数x的四舍五入值,若给定n值,则代表保留n位小数 |
2 布尔型
布尔型只有两个值:
- True
- False
也可用1表示True,用0表示False,请注意首字母大写
In [1]: TrueOut [1]: True
In [2]: 4 > 2 Out [2]: True
In [3]: bool ([3,4]) Out [3]: True
In [4]: bool ([]) Out [4]: False
In [5]: True + 1 Out [5]: 2
与或非操作:
In [ 7 ]: bool( 1 and 0 )
Out[ 7 ]: False
In [ 8 ]: bool( 1 and 1 )
Out[ 8 ]: True
In [ 9 ]: bool( 1 or 0 )
Out[ 9 ]: True
In [ 10 ]: bool( not 0 )
Out[ 10 ]: True
布尔型经常用在条件判断中:
age= 18 if age> 18 : # bool(age>18)
print ( 'old' ) else :
print ( 'young' )
3 字符型string
字符串是以单引号'或双引号"或三引号'''括起来的任意文本,比如'abc',"123",'''456'''等等。
单引号与双引号的区别?
请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符
创建字符串
a = 'Hello world!'
b = "Hello tom"
c = '''hehe'''
字符串相关操作:
# 1 * 重复输出字符串 In [ 18 ]: 'hello' * 2
Out[ 18 ]: 'hellohello'
# 2 [] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表 In [ 19 ]: 'helloworld'[2:]
Out[ 19 ]: 'lloworld'
# 3 in 成员运算符 - 如果字符串中包含给定的字符返回 True In [ 20 ]: 'el' in 'hello'
Out[ 20 ]: True
# 4 % 格式字符串 In [ 21 ]: name = 'wangqing'
In [ 22 ]: print( 'wangqing is a good teacher')
wangqing is a good teacher
In [ 23 ]: print( '%s is a good teacher' % name)
wangqing is a good teacher
万恶的字符串拼接: python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
# 5 + 字符串拼接 In [ 11 ]: a= '123' In [ 12 ]: b= 'abc' In [ 13 ]: c= '789'
In [ 14 ]: d1=a+b+c In [ 15 ]: print(d1) 123 abc789
# + 效率低,该用join In [ 16 ]: d2= ''.join([a,b,c])
In [ 17 ]: print(d2) 123 abc789
python内置的字符串相关函数方法: 统计次数 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数string.count(str, beg=0, end=len(string))
In [ 1 ]: a = 'hello world'
In [ 2 ]: a.count( 'l')
Out[ 2 ]: 3
In [ 3 ]: a.count( 'l',3)
Out[ 3 ]: 2
首字母大写
In [ 1 ]: a = 'hello world'
In [ 2 ]: a.capitalize()
Out[ 2 ]: 'Hello world'
内容居中 string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
In [ 1 ]: a = 'hello world'
In [ 2 ]: a.center( 50 )
Out[ 2 ]: ' hello world '
In [ 3 ]: a.center( 50 , '-')
Out[ 3 ]: '-------------------hello world--------------------'
内容左对齐 string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
In [1]: a = 'hello world'
In [2]: a.ljust(50)
Out[2]: 'hello world '
In [3]: a.ljust(50,'*')
Out[3]: 'hello world***************************************'
内容右对齐 string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
a = 'hello world'
a.rjust(50) # ' hello world'
a.rjust(50,'*') # '***************************************hello world'
以指定内容结束 string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False.
a = 'hello world'
a.endswith( 'd' ) # True
a.endswith( 'o' , 0 , 5 ) # True
以指定内容开头 string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查
a = 'hello world'
a.startswith( 'h' ) # True
a.startswith( 'w' , 5 ) # False
通过制表符(\t)设置字符间的间隔 string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8
a = 'hello\tworld'
a.expandtabs(tabsize= 8 )
a.expandtabs(tabsize= 10 )
查找到第一个指定元素的位置,返回其索引值 string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是,返回开始的索引值,否则返回-1
a = 'hello world'
a.find( 'w' ) # 6
a.find( 'p' ) # -1
从右往左查找到第一个指定元素的位置,返回其索引值 从右往左找第一个指定元素的位置,返回其索引值,该索引值的位置是从左到右数的string.rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找
a = 'hello world'
a.rfind( 'w' ) # 6 虽然是从右往左找,但是顺序是从左数到右的
a.rfind( 'p' ) # -1
b = 'hello worldworld'
b.rfind( 'w' ) # 11 虽然是从右往左找,但是顺序是从左数到右的
查找到第一个指定元素的位置,返回其索引值 string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常
a = 'hello world'
a. index ( 'w' ) # 6
a. index ( 'p' ) # ValueError: substring not found
从右往左查找到第一个指定元素的位置,返回其索引值 string.rindex(str,beg=0,end=len(string)) 类似于 index(),不过是从右边开始
a = 'hello world'
a. rindex ( 'w' ) # 6
a. rindex ( 'p' ) # ValueError: substring not found
b = 'hello worldworld'
b. rindex ( 'w' ) # 11
format格式化字符串 将format方法中指定的变量的值替换到字符串中
a = 'My name is {name},I am {age} years old.'
a.format(name='tom',age= 20 ) # 'My name is tom,I am 20 years old.'
format_map格式化字符串 将format_map方法中指定的变量的值替换到字符串中
a = 'My name is {name},I am {age} years old.'
a.format_map({ 'name' : 'tom' , 'age' : 20 }) # 'My name is tom,I am 20 years old.'
判断字符串中是否全为数字 string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False
a = 'abc12cde'
a.isnumeric() # False
b = '123'
b.isnumeric() # True
判断字符串中是否全为字母 string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
a = 'abc12cde'
a.isalpha() # False
b = 'abcdef'
b.isalpha() # True
判断是否只包含字母或数字
a = 'abc12cde'
a.isalnum() # True
b = '123'
b.isalnum() # True
c = 'abc123!@#'
c.isalnum() # False
判断是否为十进制 string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False
a = '1234'
a.isdecimal() # True
判断是否为整数 string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False
a = '1234'
a.isdigit() # True
b = '10.4'
b.isdigit() # False
判断是否为小写字母 string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
a = 'abcDEF'
a.islower() # False
b = 'abc'
b.islower() # True
判断是否为大写字母 string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
a = 'abcDEF'
a.isupper() # False
b = 'ABC'
b.isupper() # True
判断是否为空格 string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False
a = ' '
a.isspace() # True
b = ' abc'
b.isspace() # False
判断是否为标题 每个单词的首字母大写视为标题string.istitle() 如果 string 是标题化的(见 title())则返回 True,否则返回 False
a = 'Hello World'
a.istitle() # True
b = 'Hello world'
b.istitle() # False
将大写字母变成小写 string.lower() 转换 string 中所有大写字符为小写
a = 'ABCdef'
b = a.lower() print (b) # abcdef
将小写字母变成大写 string.upper() 转换 string 中的小写字母为大写
a = 'ABCdef'
b = a.upper() print (b) # ABCDEF
将小写字母变成大写同时将大写字母变成小写 string.swapcase() 翻转 string 中的大小写
a = 'ABCdef'
b = a.swapcase() print (b) # abcDEF
把字符串左边、右边的空格或换行符去掉
a = ' haha xixi '
a.strip() # haha xixi
把字符串左边的空格或换行符去掉
a = ' haha xixi '
a.lstrip() # 'haha xixi '
把字符串右边的空格或换行符去掉
a = ' haha xixi '
a.rstrip() # ' haha xixi'
替换内容 string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次
a = 'hello world world'
b = a.replace( 'l' , 'p' ) print (b) # 'heppo worpd worpd'
c = a.replace( 'l' , 'p' , 2 ) # 'heppo world world'
以指定字符作为分隔符将字符串中的元素分别取出来存入一个列表中 string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串
a = 'a:b:c:d:e'
b = a.split( ':' ) print (b) # [ 'a' , 'b' , 'c' , 'd' , 'e' ]
c = a.split( ':' , 2 ) print (c) # [ 'a' , 'b' , 'c:d:e' ]
以行为分隔符将字符串中的元素分别取出来存入一个列表中 string.splitlines(num=string.count('\n')) 按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行
a = 'hello world\nhello haha\nxixi\nhehe'
b = a.splitlines() print (b) # [ 'hello world' , 'hello haha' , 'xixi' , 'hehe' ]
c = a.splitlines( 2 ) print (c) # [ 'hello world\n' , 'hello haha\n' , 'xixi\n' , 'hehe' ]
把字符串变成标题格式 string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写
a = 'hello world'
b = a.title() print (b) # 'Hello World'
返回字符串 str 中最大的字母
a = 'abcGhijZ'
max(a) # j
返回字符串 str 中最小的字母
a = 'abcGhijZ'
min(a) # G
从指定位置将字符串分豁成三部分 string.partition(str)有点像 find()和 split()的结合体从 str 出现的第一个位置起,把字符串string分成一个3元素的元组( string_pre_str,str,string_post_str )如果 string 中不包含str 则 string_pre_str == string
a = 'abcGhijZ'
b = a.partition( 'G' ) print (b) # ( 'abc' , 'G' , 'hijZ' )
rpartition string.rpartition(str) 类似于 partition()函数,不过是从右边开始查找
a = 'abcGhiGjZ'
b = a.rpartition( 'G' ) print (b) # ( 'abcGhi' , 'G' , 'jZ' )
4 列表(list)
需求:把班上所有人的名字存起来
有同学说,不是学变量存储了吗,我就用变量存储呗,呵呵,不嫌累吗,同学,如果班里有一百个人,你就得创建一百个变量啊,消耗大,效率低。
又有同学说,我用个大字符串不可以吗,没问题,你的确存起来了,但是,你对这个数据的操作(增删改查)将变得非常艰难,不是吗,我想知道张三的位置,你怎么办?
在这种需求下,Python有了一个重要的数据类型----列表(list)
什么是列表: 列表(list)是Python以及其他语言中最常用到的数据结构之一。Python使用使用中括号 [ ] 来解析列表。列表是可变的(mutable)——可以改变列表的内容。
列表是一种容器类型:
- 可以包含任意对象的有序集合,通过索引进行访问其中的元素,是一种可变对象,其长度可变
- 支持异构和任意嵌套
- 支持在原处修改
对应操作: 1.定义列表( [] )
names = [ 'tom' , 'jerry' , 'zhangshan' , 'lisi' ]
2.查( [] )
names = [ 'tom' , 'jerry' , 'zhangshan' , 'lisi' ]
# print(names[2])# print(names[0:3])# print(names[0:7])# print(names[-1])# print(names[2:3])# print(names[0:3:1])# print(names[3:0:-1])# print(names[:])
3.增(append,insert) insert 方法用于将对象插入到列表中,而append方法则用于在列表末尾追加新的对象
names. append ( 'wangqing' )
names.insert( 2 , 'runtime' ) print (names)
4.改(重新赋值)
names=[ 'zhangshan' , 'lisi' , 'tom' , 'jerry' ]
names[ 3 ]= 'wangwu'
names[ 0 : 2 ]=[ 'hehe' , 'xixi' ] print (names)
5.删(remove,del,pop)
names.remove( 'xixi' ) del names[ 0 ] del names
names.pop() #注意,pop是有一个返回值的
6.其他操作 6.1 count count 方法统计某个元素在列表中出现的次数
In [ 1 ]: [ 'to' , 'be' , 'or' , 'not' , 'to' , 'be' ].count( 'to' )
Out[ 1 ]: 2
In [ 2 ]: x = [[1,2], 1, 1, [2, 1, [1, 2]] ]
In [ 3 ]: x.count( 1 )
Out[ 3 ]: 2
In [ 4 ]: x.count([ 1 , 2 ])
Out[ 4 ]: 1
6.2 extend extend 方法可以在列表的末尾一次性追加另一个序列中的多个值
In [ 5 ]: a = [ 1 , 2 , 3 ]
In [ 6 ]: b = [ 4 , 5 , 6 ]
In [ 7 ]: a.extend(b)
In [ 8 ]: a
Out[ 8 ]: [ 1 , 2 , 3 , 4 , 5 , 6 ]
In [ 9 ]: b
Out[ 9 ]: [ 4 , 5 , 6 ]
extend 方法修改了被扩展的列表,而原始的连接操作(+)则不然,它会返回一个全新的列表
In [10]: a = [1, 2, 3]
In [11]: b = [4, 5, 6]
In [12]: a + b
Out[12]: [1, 2, 3, 4, 5, 6]
In [13]: a
Out[13]: [1, 2, 3]
In [14]: b
Out[14]: [4, 5, 6]
6.3 index index 方法用于从列表中找出某个值第一个匹配项的索引位置
names. index ( 'xixi' )
6.4 reverse reverse 方法将列表中的元素反向存放
names. reverse () print (names_class2)
6.5 sort sort 方法用于在原位置对列表进行排序
x = [ 4 , 6 , 2 , 1 , 7 , 9 ]
x. sort () #x. sort ( reverse = True )
6.6 sorted sorted 方法会对对象进行排序并生成一个新的对象
In [1]: a = [1,3,5,2,10,8] In [2]: sorted(a)
Out[2]: [1, 2, 3, 5, 8, 10] In [3]: a
Out[3]: [1, 3, 5, 2, 10, 8]
6.7 深浅拷贝 对于一个列表,我想复制一份怎么办呢? 办法一:重新赋值
a = [[ 1 , 2 ], 3 , 4 ]b = [[ 1 , 2 ], 3 , 4 ]
这是两块独立的内存空间
这也没问题,如果列表内容做够大,你真的可以要每一个元素都重新写一遍吗?100个元素?1000个元素? 办法二:浅拷贝 浅拷贝时,拷贝者与被拷贝者在内存中实际上是同一个对象引用
In [1]: a = [[1,2],3,4]
In [2]: b = a
In [3]: id(a)
Out[3]: 4485742792
In [4]: id(b)
Out[4]: 4485742792
In [5]: a[2] = 10
In [6]: a
Out[6]: [[1, 2], 3, 10]
In [7]: b
Out[7]: [[1, 2], 3, 10]
In [8]: a[0][0] = 3
In [9]: a
Out[9]: [[3, 2], 3, 10]
In [10]: b
Out[10]: [[3, 2], 3, 10]
办法三:深拷贝 深拷贝时,拷贝者与被拷贝者在内存中是两个不同的对象引用 通过分片赋值实现深拷贝
In [1]: a = [[1,2],3,4]
In [2]: b = a[:]
In [3]: id(a)
Out[3]: 4370272328
In [4]: id(b)
Out[4]: 4369162312
In [5]: a[1] = 10
In [6]: a
Out[6]: [[1, 2], 10, 4]
In [7]: b
Out[7]: [[1, 2], 3, 4]
In [8]: a[0][0] = 5
In [9]: a
Out[9]: [[5, 2], 10, 4]
In [10]: b
Out[10]: [[5, 2], 3, 4]
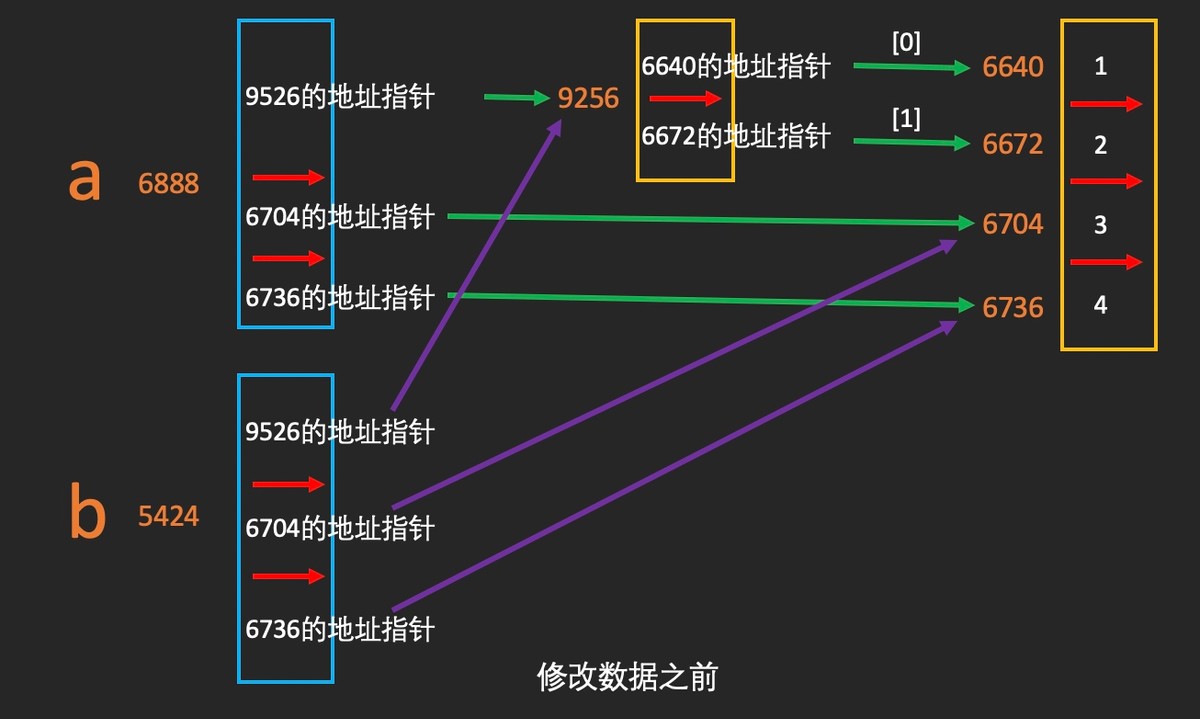
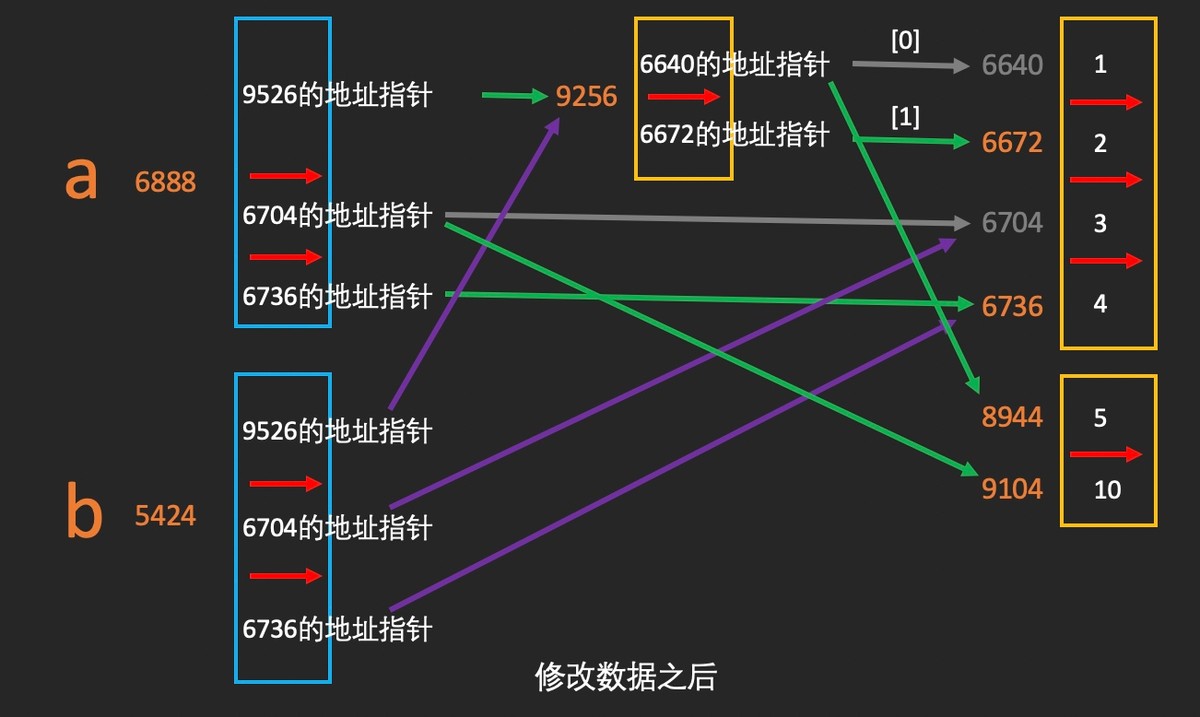
通过copy模块的deepcopy方法来实现深复制
In [1]: import copy
In [2]: a = [[1,2],3,4]
In [3]: b = copy.deepcopy(a)
In [4]: id(a)
Out[4]: 4362280328
In [5]: id(b)
Out[5]: 4362553224
In [6]: a[1] = 100
In [7]: a
Out[7]: [[1, 2], 100, 4]
In [8]: b
Out[8]: [[1, 2], 3, 4]
In [9]: a[0][1] = 10
In [10]: a
Out[10]: [[1, 10], 100, 4]
In [11]: b
Out[11]: [[1, 2], 3, 4]
6.8 变量分解
In [ 1 ]: b,c = [ 1 , 2 ]
In [ 2 ]: b
Out[ 2 ]: 1
In [ 3 ]: c
Out[ 3 ]: 2
想一想:
- 左边变量比右边多行吗?
- 右边值比左边多行吗?
5 元组(tuple)
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,列表的切片操作同样适用于元组。
元组写在小括号(())里,元素之间用逗号隔开。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
t1 = () # 空元组
t2 = ( 10 ,) # 一个元素,需要在元素后添加逗号
作用:
- 对于一些数据我们不想被修改,可以使用元组;
- 元组可以在映射(和集合的成员)中当作键使用,而列表则不行
- 元组作为很多内建函数和方法的返回值存在
练习:购物车程序 思路:
- 产品列表用什么存
- 商品应该有编号,选择编号就购买相应产品
- 用户的银行卡上钱应比商品价格高才能买
- 买完后应打印一个清单告知用户购买了什么,花了多少钱
6 字典(dict)
字典是Python中唯一的映射类型,采用键值对(key-value)的形式存储数据。Python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。
可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
对应操作: 1.创建字典{}
In [ 1 ]: dic1 = { 'name' : 'wangqing' , 'age' : 30 , 'sex' : 'male' }
In [ 2 ]: dic2 = dict((( 'name' , 'wangqing' ),))
In [ 3 ]: dic3 = {}.fromkeys([ 'name' , 'age' , 'salary' ], 'tom' )
In [ 4 ]: dic1
Out[ 4 ]: { 'name' : 'wangqing' , 'age' : 30 , 'sex' : 'male' }
In [ 5 ]: dic2
Out[ 5 ]: { 'name' : 'wangqing' }
In [ 6 ]: dic3
Out[ 6 ]: { 'name' : 'tom' , 'age' : 'tom' , 'salary' : 'tom' }
2.增
In [ 1 ]: dic1 = {}
In [ 2 ]: dic1[ 'name' ] = 'tom'
In [ 3 ]: dic1[ 'age' ] = 20
In [ 4 ]: dic1
Out[ 4 ]: { 'name' : 'tom' , 'age' : 20 }
In [ 5 ]: a = dic1.setdefault( 'name' , 'wangqing' )
In [ 6 ]: b = dic1.setdefault( 'ages' , 25 )
In [ 7 ]: a
Out[ 7 ]: 'tom'
In [ 8 ]: b
Out[ 8 ]: 25
In [ 9 ]: dic1
Out[ 9 ]: { 'name' : 'tom' , 'age' : 20 , 'ages' : 25 }
执行setdefault函数时当键已在字典中存在时用字典中原元素的值,当键在字典中不存在时,将新增该元素至字典中
3.查
dic1 = { 'name' : 'tom' , 'age' : 20 }
# print (dic1[ 'name' ])
# print (dic1[ 'names' ])
#
# print (dic1.get( 'age' ,False))
# print (dic1.get( 'ages' ,False))
print (dic1.items()) print (dic1.keys()) print (dic1.values())
print ( 'name' in dic3) # py2: dic3.has_key( 'name' ) print (list(dic3.values()))
4.改
dic1 = { 'name' : 'tom' , 'age' : 20 }
dic1[ 'name' ]= 'jerry'
dic2={ 'sex' : 'male' , 'hobby' : 'book' , 'age' : 23 }
dic1.update(dic2) print (dic1)
5.删
dic1={ 'name' : 'tom' , 'age' : 18 , 'class' : 1 }
# dic1.clear()# print(dic1) del dic1[ 'name' ]
print(dic1)
a=dic1.popitem()
print(a,dic1)
# print(dic1.pop('age'))# print(dic1)
# del dic1# print(dic1)
6.字典方法 6.1 dict.fromkeys
d1 = dict.fromkeys([ 'host1' , 'host2' , 'host3' ], 'Mac' ) print (d1)
d1[ 'host1' ] = 'xiaomi' print (d1) #######
d2 = dict.fromkeys([ 'host1' , 'host2' , 'host3' ],[ 'Mac' , 'huawei' ]) print (d2)
d2[ 'host1' ][ 0 ] = 'xiaomi' print (d2)
6.2 dict.copy 对字典进行浅复制,返回一个有相同键值的新字典
In [ 1 ]: a = { 'name' : 'tom' , 'age' : 23 }
In [ 2 ]: d = a. copy ()
In [ 3 ]: a
Out[ 3 ]: { 'name' : 'tom' , 'age' : 23 }
In [ 4 ]: d
Out[ 4 ]: { 'name' : 'tom' , 'age' : 23 }
In [ 5 ]: id(a)
Out[ 5 ]: 4378229208
In [ 6 ]: id(d)
Out[ 6 ]: 4382880464
6.3 字典的嵌套 还用我们上面的例子,存取某班学生的信息,我们如果通过字典来完成,效果更佳
dic = {
'zhangshan' : {
'age' : 23 ,
'sex' : 'male'
},
'lisi' : {
'age' : 20 ,
'sex' : 'male'
},
'wangwu' : {
'age' : 27 ,
'sex' : 'Female'
}
}
6.4 字典的排序 sorted(dict)对字典进行排序,返回一个有序的包含字典所有key的列表
dic = { 5 : '555' , 2 : '222' , 4 : '444' } print (sorted(dic))
6.5 字典的遍历
dic1={ 'name' : 'tom' , 'age' : 20 }
for i in dic1:
print (i,dic1[i])
for items in dic1.items():
print (items)
for keys , values in dic1.items():
print ( keys , values )
7 集合(set)
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set) :把 不同的元素 组成一起形成集合,是Python基本的数据类型之一
集合元素(set elements):组成集合的成员( 不可重复 )
l1 = [ 1 , 2 , 'a' , 'b' ]
s = set (l1) print (s) # {1, 2, 'a', 'b'}
l2=[ 1 , 2 , 1 , 'a' , 'a' ]
s = set (l2) print (s) # {1, 2, 'a'}
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
l1 = [[ 1 , 2 ], 'a' , 'b' ]
s = set (l1) # TypeError: unhashable type: 'list' print (s)
集合分类 :可变集合、不可变集合
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反
l1 = [ 1 , 'a' , 'b' ]
s = set (l1)
dic = {s: '123' } #TypeError: unhashable type: 'set'
集合的相关操作 1.创建集合 由于集合没有自己的语法格式,只能通过集合的工厂方法set()和frozenset()创建
s1 = set( 'wangqing' )
s2= frozenset( 'tom' )
print (s1, type (s1)) # { 'a' , 'g' , 'q' , 'i' , 'n' , 'w' } <class 'set' > print (s2, type (s2)) # frozenset({ 'm' , 'o' , 't' }) <class 'frozenset' > 'frozenset' >
2.访问集合 由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素
s1 = set ( 'wang' ) print ( 'a' in s1) # True print ( 'b' in s1) # False# s1[1] # TypeError: 'set' object does not support indexing
for i in s1:
print (i)
3.集合添加元素
s1 = frozenset( 'wang' )
s1.add( 0 ) # AttributeError: 'frozenset' object has no attribute 'add' 'add'
s2 = set( 'wang' )
s2.add( 'mm' ) # 添加的元素被当成一个整体添加 print (s2) # { 'a' , 'mm' , 'g' , 'n' , 'w' }
s2.update( 'HO' ) # 添加的元素被当成一个序列一个个添加进集合,\
# 当被添加的元素中有重复时只会保留一个 print (s2) # { 'a' , 'mm' , 'g' , 'H' , 'O' , 'n' , 'w' }
4.集合删除 4.1 删除集合元素
s1 = set ( 'wangqing' )
s1.remove( 'w' ) # 删除指定元素 print (s1) # {'a', 'g', 'i', 'n', 'q'}
s1.pop() # 随机删除元素
s1.clear() # 清空元素
4.2 删除集合本身
s1 = set ( 'wangqing' )
del s1 # NameError: name 's1' is not defined
5.等价(==)与不等价(!=)
s1 = set ( 'wangqing' )
s2 = set ( 'wangqi' )
s1 == s2 # True
6.关系测试 6.1 子集(<) s2是否完全被s1包含
s1 = set ( 'wangqing' )
s2 = set ( 'wang' ) print ( 'w' in s1) # True print (s2 < s1) # True
print (s2.issubset(s1)) # True
6.2 超集(父集)(>) s1是否完全包含s2
s1 = set ( 'wangqing' )
s2 = set ( 'wang' ) print (s1 > s2) # True
print (s1.issuperset(s2)) # True
6.3 交集(&) 与集合and等价,交集符号的等价方法是intersection()取出的内容是两组数据间都有的
s1 = set ([ 1 , 2 , 3 , 4 , 5 ])
s2 = set ([ 4 , 5 , 6 , 7 , 8 ])
s3 = s1 & s2 print (s3) # {4, 5}
s1.intersection(s2) # {4, 5}
6.4 并集(|) 联合(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union()把两组数据中所有数据合并,重复的只保留1个
s1 = set ([ 1 , 2 , 3 , 4 , 5 ])
s2 = set ([ 4 , 5 , 6 , 7 , 8 ])
s3 = s1 | s2 print (s3) # {1, 2, 3, 4, 5, 6, 7, 8}
s1.union(s2) # {1, 2, 3, 4, 5, 6, 7, 8}
6.5 差集(-) 等价方法是difference()s1中有而s2中没有的元素
s1 = set ([ 1 , 2 , 3 , 4 , 5 ])
s2 = set ([ 4 , 5 , 6 , 7 , 8 ])
s3 = s1 - s2 print (s3) # {1, 2, 3}
s1.difference(s2) # {1, 2, 3}
6.6 对称差集(反向交集)(^) 对称差分是集合的(‘异或’),取得的元素属于s1、s2但不同时属于s1和s2.其等价方法symmetric_difference()取两组数据中都有的元素之外的元素
s1 = set ([ 1 , 2 , 3 , 4 , 5 ])
s2 = set ([ 4 , 5 , 6 , 7 , 8 ])
s3 = s1 ^ s2 print (s3) # {1, 2, 3, 6, 7, 8}
s1.symmetric_difference(s2) # {1, 2, 3, 6, 7, 8}
7.利用集合去重
l1 = [ 1 , 2 , 3 , 4 , 1 , 2 , 3 , 4 ] print (list( set (l1))) #[1, 2, 3, 4]
作业
写一个三级菜单,要求如下:
- 打印省、市、县三级菜单
- 可依次选择进入各子菜单以及返回上一级
- 可随时退出程序
所需知识点:
- 列表
- 字典