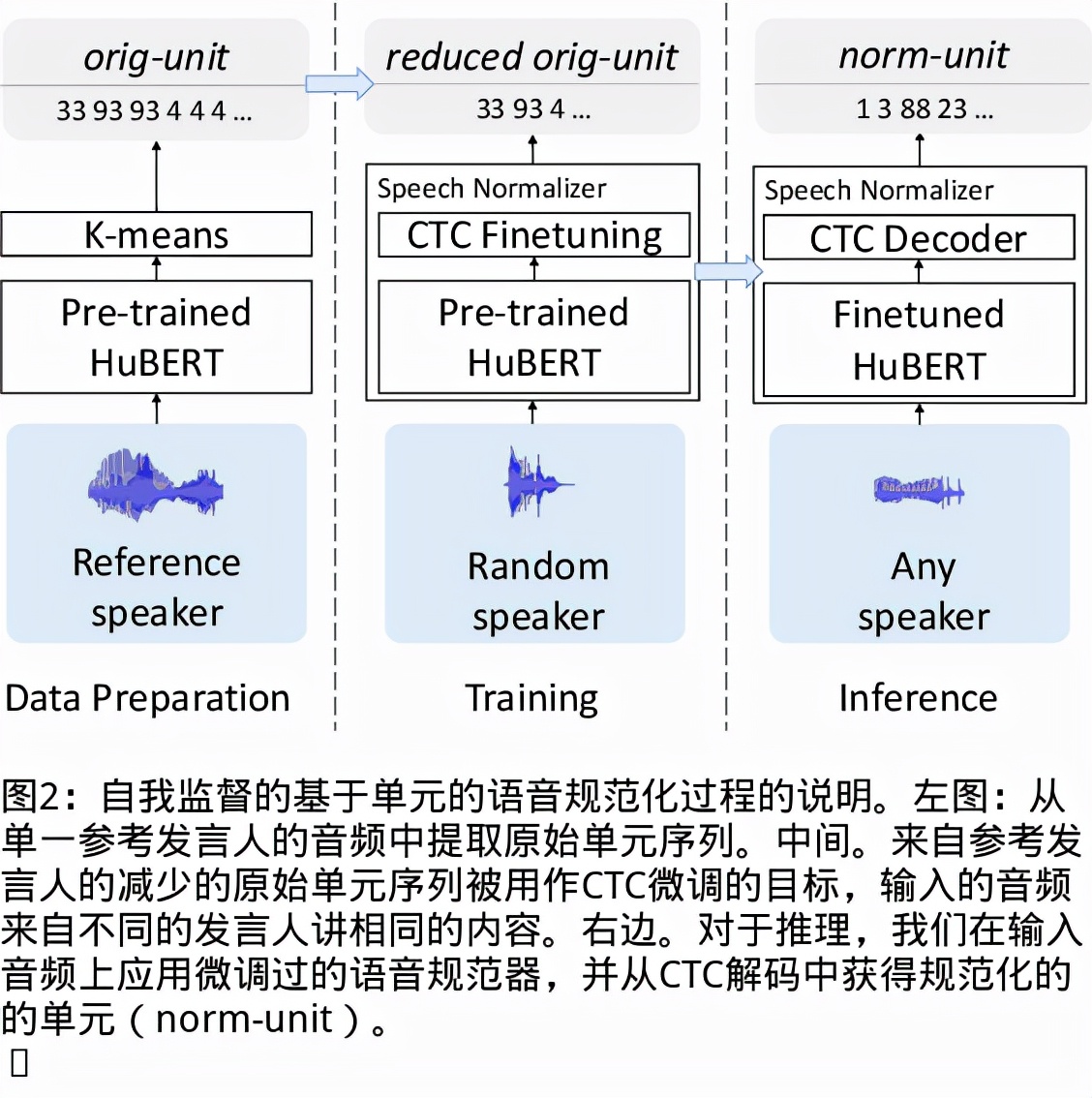
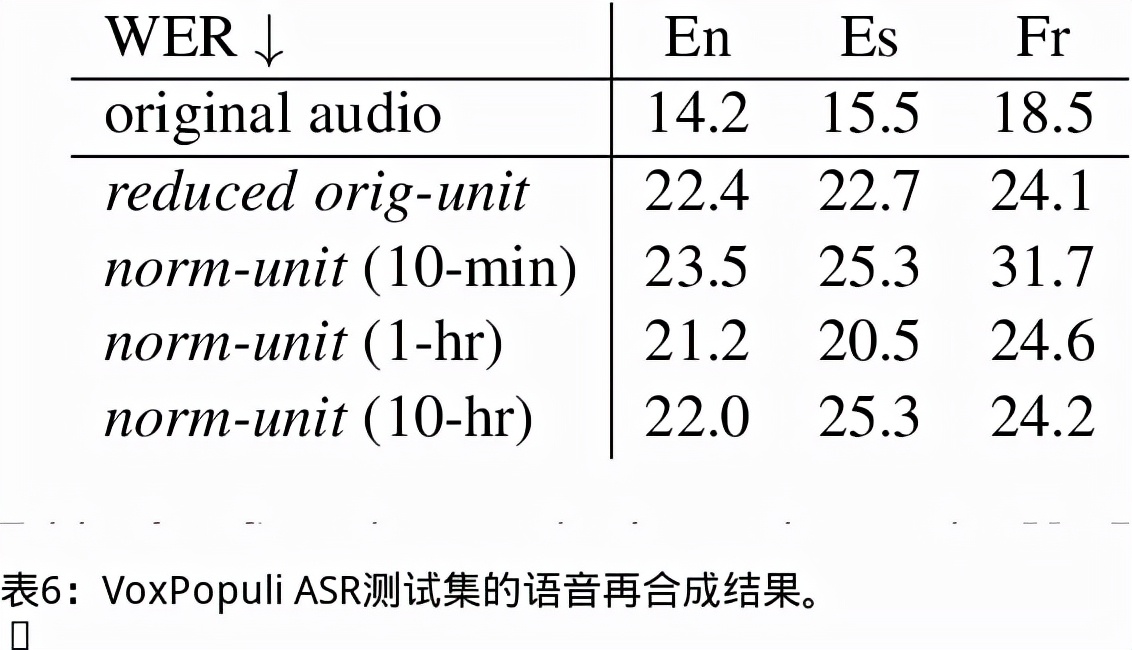
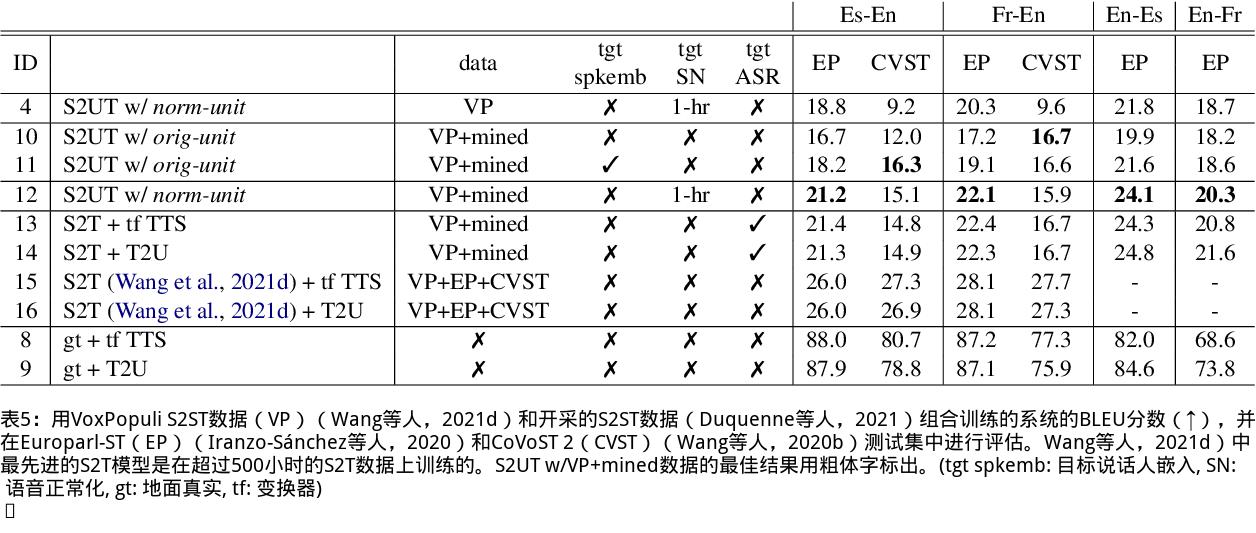
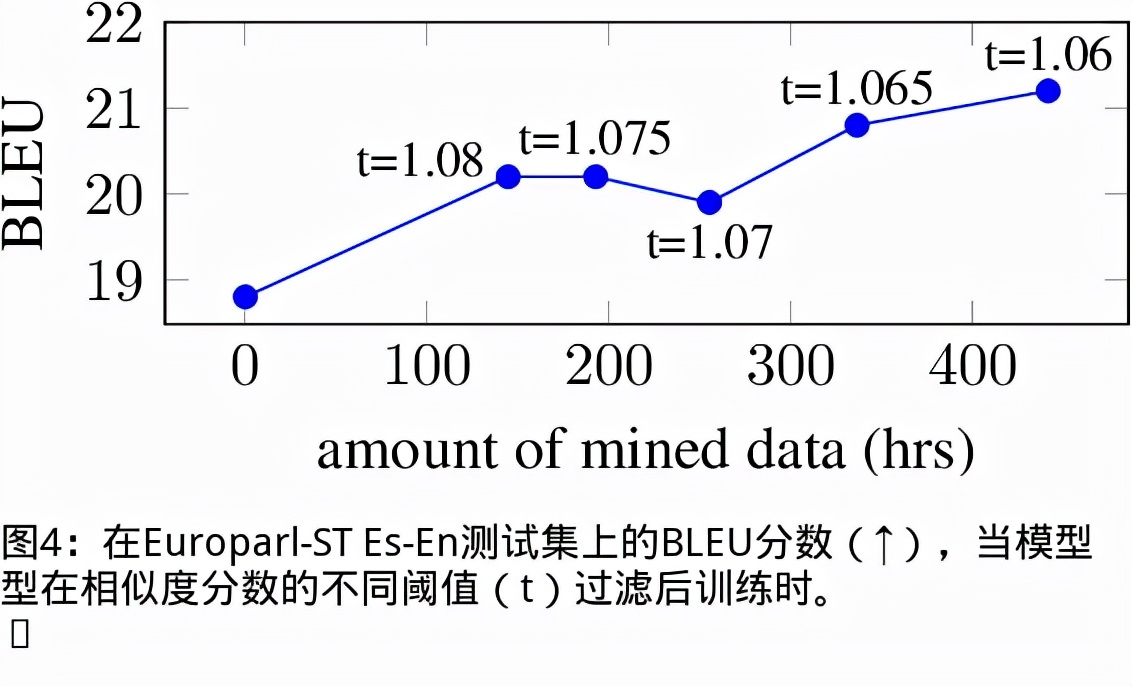
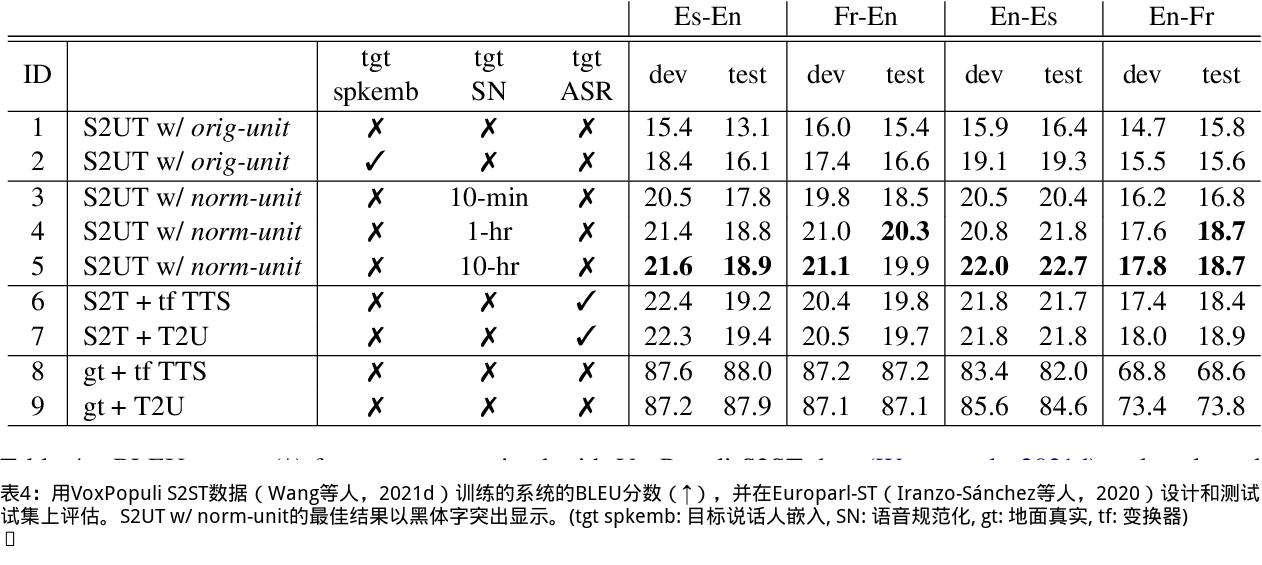
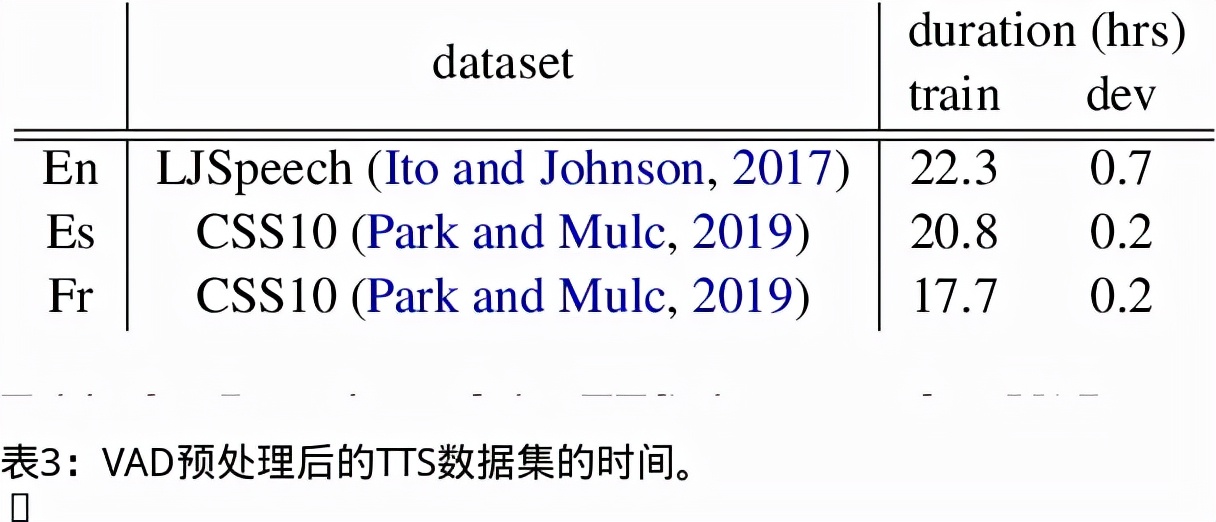
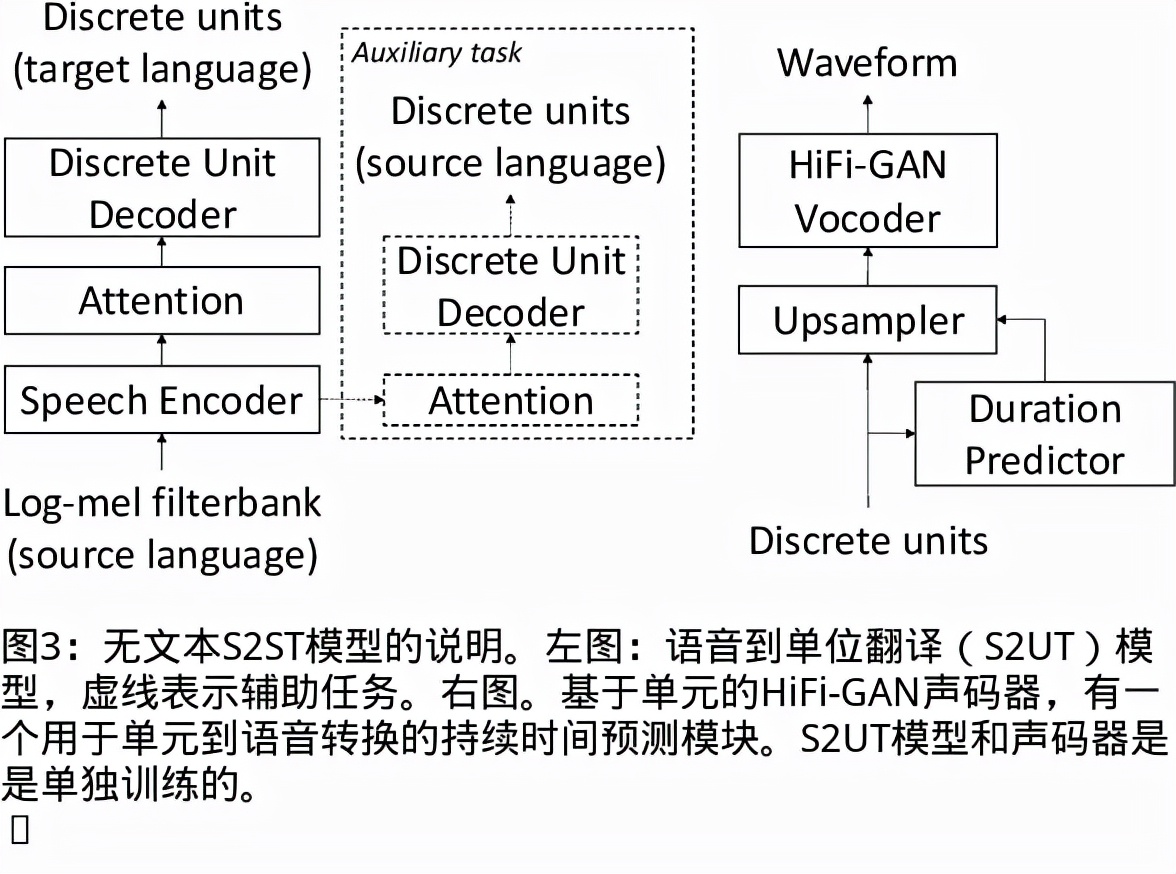
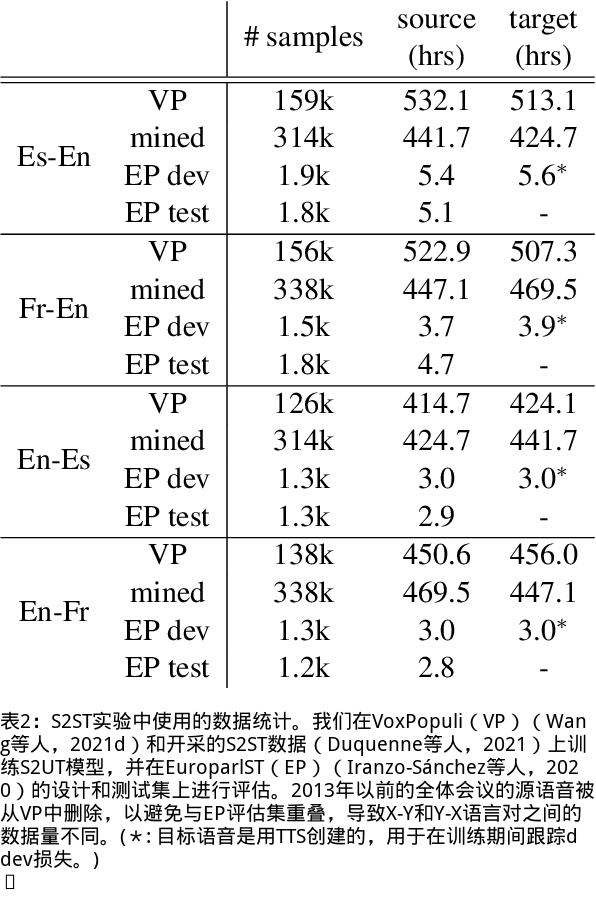
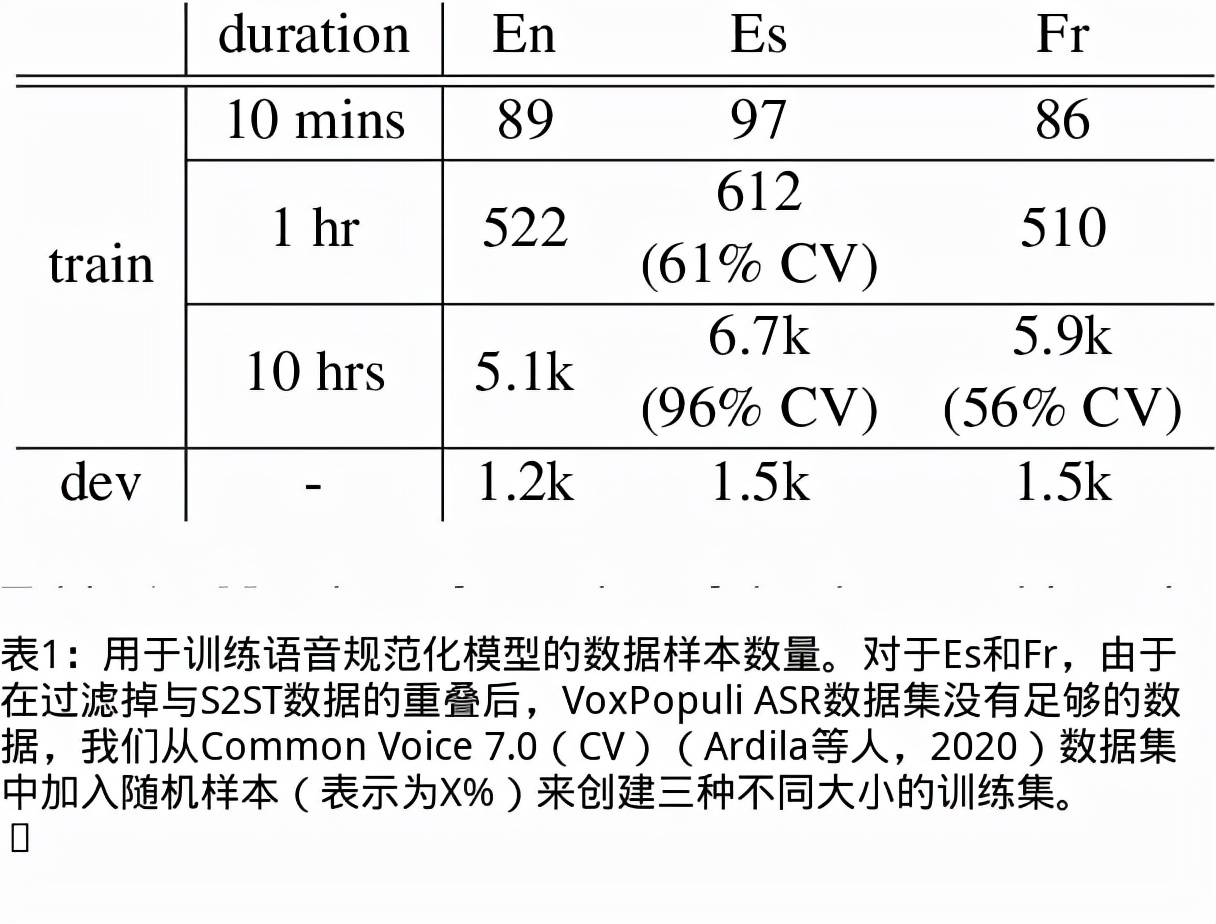
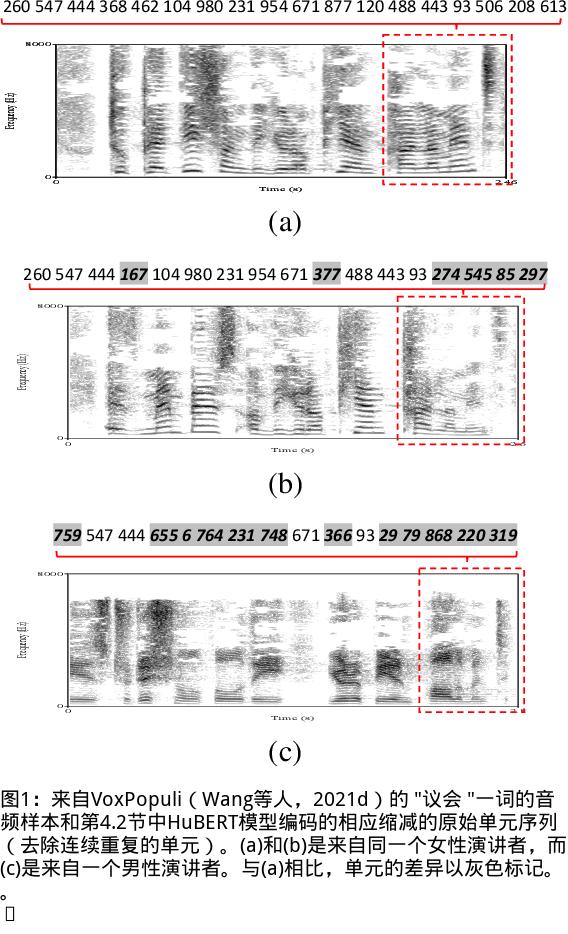
我们提出了一个无文本语音翻译(S2ST)系统,它可以将一种语言的语音翻译成另一种语言,并且可以在不需要任何文本数据的情况下建立。与文献中的现有工作不同,我们解决了对多发言人目标语音进行建模的挑战,并利用真实世界的S2ST数据对系统进行训练。我们的方法的关键是基于单元的自我监督的语音规范化技术,该技术通过来自多个说话人和单一参考说话人的配对音频来微调经过训练的语音编码器,以减少由于口音造成的变化,同时保留词汇内容。仅用10分钟的配对数据进行语音规范化,与在未规范化的语音目标上训练的基线相比,我们在S2ST模型上训练S2ST模型时平均获得了3.2个BLEU增益。我们还纳入了自动挖掘的S2ST数据,并显示出额外的2.0 BLEU增益。据我们所知,我们首次建立了一种无文本的S2ST技术,该技术可以用真实世界的数据进行训练,并适用于多种语言对。
《Textless Speech-to-Speech Translation on Real Data》
论文地址:http://arxiv.org/abs/2112.08352v1