数据中台建设方案
-基于大数据平台-
1数据中台建设方案
1.1 总体建设方案
1.2大数据集成平台
1.3大数据计算平台
1.3.1数据计算层建设
计算层技术含量最高,最为活跃,发展也最为迅速。计算层主要实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持。大数据基础平台技术能力的高低,主要依赖于该层组件的发展。
本建设方案满足甲方对于数据计算层建设的基本要求:
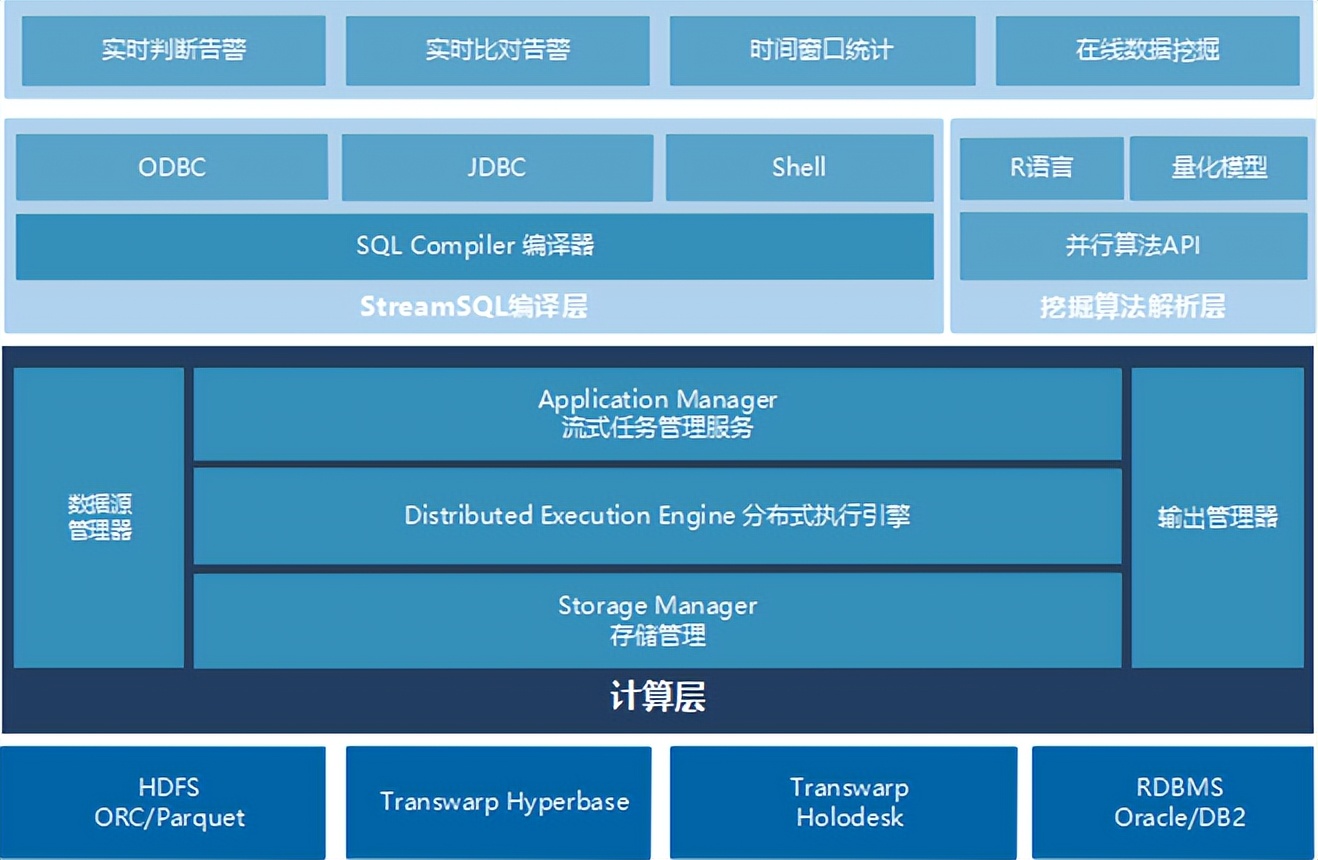
利用了MapReduce、Spark 、MPP 、Zookeeper、Yarn、HBase、Mahout 等开源组件和技术;实现了实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持;并且提供了更高效的列式数据库Hyperbase、跨内存/闪存/磁盘等介质的分布式混合列式存储Holodesk、一体化的机器学习平台Discover和拖拽式图形界面工具Midas。可以给甲方后续建设提供更丰富、更多样性的选择。
1.3.1.1分布式数据仓库
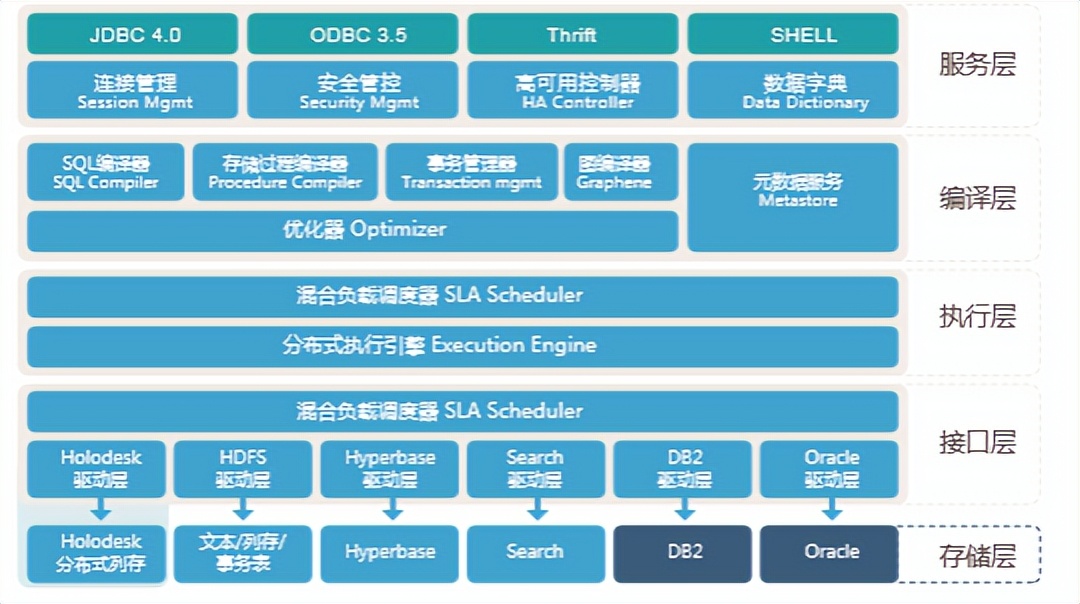
Transwarp Inceptor是一个企业级数据仓库,最下面是存储层接口层,Inceptor可将存储在分布式列存、文本/列存/事务表、Hyperbase、Search、DB2、Oracle中的数据,通过提供的对应驱动层,进入到执行层。在执行层中,Inceptor提供了混合负载调度器SLA Scheduler和分布式执行引擎。在编译层提供了各种编译器和优化器,以及元数据服务。最上层提供完整的交互访问接口和各类安全管控。
Spark是Map/Reduce计算模式的一个全新实现。Spark的创新之一是提出RDD(Resilient Distributed Dataset)的概念,所有的统计分析任务是由对RDD的若干基本操作组成。RDD可以被驻留在内存中,后续的任务可以直接读取内存中的数据,因此速度可以得到很大提升。Spark的创新之二是把一系列的分析任务编译成一个由RDD组成的有向无环图,根据数据之间的依赖性把相邻的任务合并,从而减少了大量的中间结果输出,极大减少了磁盘I/O,使得复杂数据分析任务更高效。从这个意义上来说,如果任务够复杂,迭代次数够多,Spark比Map/Reduce快100倍或1000倍都很容易。基于这两点创新,可在Spark基础上进行批处理、交互式分析、迭代式机器学习、流处理,因此Spark可以成为一个用途广泛的计算引擎,并在未来取代Map/Reduce的地位。
Inceptor可以分析存储在HDFS,HBase或者Holodesk分布式缓存中的数据,可以处理的数据量从GB到数十TB,即使数据源或者中间结果的大小远大于内存,也可高效处理。另外也通过改进Spark和YARN的组合,提高了Spark的可管理性。这些使得Inceptor成为目前真正适合企业生产环境7x24小时部署的Spark衍生产品。同时星环不仅仅是将Spark作为一个缺省计算引擎,也重写了SQL编译器,提供更加完整的SQL支持。
同时,星环通过改进Spark使之更好的与HBase融合。星环基于HBase的产品叫做Hyperbase,通过结合Inceptor,可以为HBase提供完整的SQL支持,包括批量SQL统计、OLAP分析以及高并发低延时的SQL查询能力,使得HBase的应用可以从简单的在线查询应用扩展到复杂分析和在线应用结合的混合应用中,大大拓展了HBase的应用范围。这两个产品的组合使得星环在市场上处于领先地位。
SQL语法支持
标准SQL语句支持
TDH提供ANSI SQL2003语法支持以及PL/SQL过程语言扩展,并且可以自动识别HiveQL、SQL2003和PL/SQL语法,在保持跟Hive兼容的同时提供更强大的SQL支持。减少系统迁移和新应用开发成本。支持SQL2003语法,支持TD SQL语法,支持Oracle PL/SQL和IBM DB2 SQL/PL存储过程。
由于现有的数据仓库应用大都基于标准SQL,对于客户,现有应用也大量使用了PL/SQL,要从现有数据库系统迁移到Hadoop,标准SQL以及PL/SQL的支持显得尤为重要。TDH可以支持标准SQL以及PL/SQL,支持复杂的数据仓库类分析应用,使得从原有数据库系统迁移到Hadoop更为容易,可以帮助企业建立高速可扩展的数据仓库和数据集市。
Inceptor支持以下SQL要求:
- 支持创建数据库、删除数据库、配置数据库的容量
- 支持创建表、删除表、增加表字段
- 支持创建、修改、删除视图CREATE/DROP/ALERT VIEW
- 支持表数据类型包括所有的结构化数据类型如整形、字符串、浮点型、布尔型、二进制、时间类型等,文档数据类型如XML,JSON,BSON,以及针对图片类文件的LOB类型;
- 支持创建索引、删除索引;
- 支持所有类型的表的连接,支持表的集合运算包括求并集、求交集、求差集,支持多层的SQL嵌套查询,支持 IN/Not IN/Exists/Not Exists 等复杂查询
- 支持字符串、日期等常用操作函数
- 支持最大值、最小值、平均值等聚合函数,支持常用Oracle函数,
- 支持select into、insert into、merge into 功能
- 支持完整的增删改语法,具体包括支持单条或者多条插入,支持单条更新和用子查询更新,支持从表中删除数据,支持Merge Into功能。
- 支持子查询 (sub-query factoring),包括非同步子查询(Non-correlated Sub-query)和同步子查询(Correlated Sub-query),支持子查询的多层嵌套。
- 支持在 where clause 子句使用同步和非同步subquery (包括IN 和 NOT IN)
- 支持在From clause子句中使用非同步subquery
- 支持 Having clause子句使用非同步subquery
- 支持 Select list里面使用同步和非同步 subquery
- 支持 WITH AS 语法,并可在系统运行中实时决定是否选择物理化 WITH AS来加速查询
- 支持 Inner JOIN, Outer JOIN (Left Outer JOIN, Right Outer JOIN, Full Outer JOIN), Implicit JOIN, Nature JOIN, Cross JOIN,SELF JOIN, Non-equi JOIN(JOIN条件可以是不等式),Map JOIN,left semi join 和 left anti semi join
- 支持 union, intersect, except操作,并且他们可以作为top level operator
- 支持 in 、between 以及运算符(+ - * )直接操作 subquery
- 具备较完整的事务处理支持(包括嵌套事务),支持BEGIN TRANSACTION, END TRANSACTION, COMMIT, ROLLBACK操作,支持自治事务
- 支持基于预定义维度的数据查询,支持简单查询、组合查询、模糊查询等。
- 支持标准DDL,DML,事务处理,支持SQL 2003 等,支持SQL子查询及窗口函数。
- 支持基本数据类型、复杂数据类型、with as 子句、同步子查询、相关子查询、嵌套子查询,窗口函数、聚合函数、类型转换、集合函数、操作符、Oracle PL/SQL过程扩展,HiveQL。
- 支持数据累加、统计、关联、比对、去重等各种常见的数据分析场景。
- 支持标准SQL的方式来访问Hadoop生态系统中的其他组件模块,如Hive、Hbase、hdfs中的文件,并能跨数据源做关联查询和分析。
- TDH平台全面支持HiveQL、SQL2003标准等,可以有效支持数据仓库中常用的数据立方统计(CUBE/ROLLUP)、窗口聚合统计、嵌套(nested)/同步(correlated)子查询、子表定义和操作,这些功能无法用HiveQL有效实现。
- TDH平台提供了对SQL2003标准最全面的支持,最大程度方便用户开发基于Hadoop平台的应用和现有应用的迁移。
Inceptor中对于SQL的相关支持可参见下表:
|
函数支持 |
|
|
聚合函数 |
count, sum, avg, min, max, variance, var_pop, var_samp, stddev_pop, stddev_samp, covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set, collect_list, ntile |
|
窗口函数 |
sum, avg, min, max, count |
|
dense_rank, group_max, group_min, group_sum, rank, row_number |
|
|
类型转换函数 |
binary, cast(expr as <type>) |
|
UDTF |
explode, inline, json_tuple, parse_url_tuple, posexplode, stack |
|
集合函数 |
size, map_keys, map_values, array_contains, sort_array |
|
其他功能函数 |
to_card_15_to_18(15位身份证号转18位) |
|
数据类型支持 |
|||
|
基本 数据类型 |
TINYINT, SMALLINT |
||
|
INT, INTEGER, BIGINT |
|||
|
BOOLEAN |
|||
|
FLOAT, DOUBLE |
|||
|
DATE, DATETIME, INTERVAL |
|||
|
TIMESTAMP |
|||
|
STRING |
|||
|
BINRAY |
|||
|
VARCHAR, VARCHAR2 |
|||
|
DECIMAL,DECIMAL(no.,no.), DEC(no., no.) |
|||
|
NUMERIC(no.,no.),NUMBER(no., no.) |
|||
|
复杂 数据类型 |
LIST |
||
|
MAP |
|||
|
STRUCT |
|||
|
UNION |
|||
|
WITH AS语句、嵌套查询支持 |
|||
|
WITH AS定义子表 |
SQL’92的WITH AS语句 |
WITH DEPT_COSTS AS --查询出部门的总工资 (SELECT D.DNAME,SUM(E.SAL)DEPT_TOTAL FROM DEPT D, EMP E WHERE E.DEPTNO = D.DEPTNO GROUP BY D.DNAME), AVE_COST AS --查询出部门的平均工资,在后一个WITH语句中可以引用前一个定义的WITH语句 (SELECT SUM(DEPT_TOTAL) / COUNT(*) AVG_SUM FROM DEPT_COSTS) SELECT * FROM DEPT_COSTS DC WHERE DC.DEPT_TOTAL > (SELECT AC.AVG_SUM FROM AVE_COST AC) --进行比较 |
|
|
嵌套 子查询 |
子查询在FROM子句中 |
SELECT employees.employee_number, employees.name FROM employees INNERJOIN (SELECT department, AVG(salary) AS department_average FROM employees GROUPBY department) AS temp ON employees.department = temp.department WHERE employees.salary > temp.department_average; |
|
|
子查询在WHERE子句中 |
SELECT e.name, e.salary, e.department FROM employess e WHERE e.employee_id = (SELECT MIN(employee_id) FROM employess) |
||
|
子查询在SELECT子句中 |
SELECT employee_number, name, (SELECT AVG(salary) FROM employees) AS department_average FROM employees; |
||
|
子查询在HAVING子句中 |
SELECT department_id, manager_id FROM employees GROUP BY department_id, manager_id HAVING department_id = (SELECT max(department_id) FROM employees x ) ORDER BY department_id; |
||
|
子查询、窗口函数、Rollup扩展支持 |
|||
|
CORRELATED SUB-QUERY 相关/同步子查询 |
子查询在WHERE子句中 |
SELECT employee_number, name FROM employees AS Bob WHERE salary = ( SELECT AVG(salary) FROM employees WHERE department = Bob.department); |
|
|
子查询在SELECT子句中 |
SELECT employee_number, name, (SELECT AVG(salary) FROM employees WHERE department = Bob.department) AS department_average FROM employees AS Bob; |
||
|
子查询在HAVING子句中 |
SELECT department_id, manager_id FROM employees GROUP BY department_id, manager_id HAVING department_id = (SELECT department_id FROM employees x WHERE x.department_id = employees.department_id) ORDER BY department_id; |
||
|
窗口 聚合函数 |
OVER子句 |
SELECT SalesOrderID, CustomerID,OrderDate, TotalDue, SUM(TotalDue) OVER (PARTITION BY CustomerID) AS CustomerTotal, SUM(TotalDue) OVER() AS GrandTotal, AVG(TotalDue) OVER (PARTITION BY CustomerID) AS AvgCustSaleFROM Sales.SalesOrderHeader OuterQueryORDER BY CustomerID; |
|
|
Group By扩展 |
Rollup 生成简单的GROUP BY 聚合行以及小计行或超聚合行,还生成一个总计行 |
SELECT a, b, c, SUM ( <expression> ) FROM T GROUP BY ROLLUP (a,b,c); 会为 (a, b, c)、(a, b) 和 (a) 值的每个唯一组合生成一个带有小计的行。 还将计算一个总计行。 |
|
|
Cube生成简单的GROUP BY 聚合行、ROLLUP 超聚合行和交叉表格行 |
SELECT a, b, c, SUM (<expression>) FROM T GROUP BY CUBE (a,b,c); 会为 (a, b, c)、(a, b)、(a, c)、(b, c)、(a)、(b) 和 (c) 值的每个唯一组合生成一个带有小计的行,还会生成一个总计行。 |
||
多种数据访问形式支持
CLI命令行支持
大数据计算服务提供基于Beeline的命令行终端接口,通过JDBC连接大数据计算服务控制台,用户可以通过Beeline,使用SQL语言,对大数据计算服务中的数据进行检索、查询、关联等分析操作。
标准化API接口
平台对上层应用提供各种开发接口,包括JAVA API接口,REST接口,JDBC/ODBC接口以及R语言等接口。通过这些接口,平台上层应用可以通过平台开放的JAVA API进行二次开发,可以完全支持常见的应用开发框架,如Hibernate, mybatis。平台开放的API完全兼容Hadoop生态圈的所有组件的API,同时提供额外并行算法库的Java API给上层应用调用;平台上层应用开发人员可以通过平台开放的REST API接口,对接平台作业调度工具或HUE图形化界面等,进行作业创建和管理;平台上层应用开发人员可以通过平台开放的标准JDBC/ODBC接口,使用SQL语言交互式查询和分析数据平台的海量数据;平台上层应用开发人员可以使用R语言接口进行交互式数据挖掘探索。
平台提供的主要开发接口描述如下:
|
数据接口 |
接口描述 |
接口使用对象 |
|
JDBC/ODBC接口 |
TDH支持标准的SQL形式访问数据,提供ANSI SQL2003语法支持以及存储过程语言支持。使得复杂的数据仓库、数据集市应用可以快速落地到TDH平台。 |
上层应用开发人员 |
|
REST接口 |
TDH支持通过REST接口对接Transwarp Manager、HDFS、YARN、Hyperbase、Inceptor、OOZIE、HUE等服务。 |
上层应用开发人员 |
|
Java API接口 |
TDH支持通过JAVA API编程接口对接HDFS、YARN、Kafka、、flume、sqoop、Hyperbase、Inceptor等服务。 |
上层应用开发人员 |
|
R接口 |
提供RStudio Web图形化开发界面,通过R语言调用并行算法库,并可通过并行化算子二次开发并行化算法。 |
上层应用开发人员 |
SQL开发辅助工具
Waterdrop是为开发人员和数据库管理人员提供的数据库管理工具,它可进行跨平台管理,可作为Inceptor SQL客户端,除了Inceptor还支持并兼容其余多种数据库。它具有有四个功能模块:DatabaseNavigator、SQL Editor、SQL Executor、Data Viewer/Eidtor,分别用来帮助用户实现数据库管理、SQL编辑、SQL执行、数据操作这四项功能。
Waterdrop提供一个类似Eclipse的环境,用户可以通过Waterdrop连接Inceptor并在之上做数据库开发。
Waterdrop的开发环境如下:
操作系统/数据库支持度
- Waterdrop支持的操作系统有:Windows(32/64位),Linux(32/64位),Mac OS X(64位),Solaris(32位)
- Waterdrop支持连接的数据库有:
|
Inceptor |
|
Apache Drill |
|
Apache Hive |
|
Apache Phonix |
|
Cache |
|
Firebird (Interbase) |
|
Gemfire XD |
|
H2 |
|
HSQLDB |
|
IBM DB2 |
|
IBM Informix |
|
Ingres |
|
Java DB (Derby) |
|
Linter |
|
MariaDB |
|
MySQL |
|
Microsoft SQL Server |
|
Microsoft Access |
|
Mimer |
|
Netezza |
|
NuoDB |
|
Oracle |
|
ODBC |
|
PostgreSQL |
|
Redshift |
|
Sybase |
|
SQLite |
|
SAP MAX DB |
|
Teradata |
|
Vertica |
|
WMI |
功能实现
Waterdrop提供数据库导航栏,提供查看当前存在的连接,以及各个Connection所提供的内容、包括了哪些元数据对象,如数据库、表、列、分区、桶、视图、存储过程、Packages等,并通过层级反映元信息结构。可以轻松实现:
- 查看元数据信息
- 创建元数据
- 指定默认数据库
- 刷新元数据对象
- 对比元数据对象
- 对象重命名
- 添加书签
SQL Editor主要用于SQL语句的编辑,具有高亮和报错功能。
SQL Executor是用于执行SQL语句的功能模块。它不仅可以执行各种语句,将结果和错误分别显示在结果窗口和Problems窗口,还可以查看以往执行过的所有SQL语句,以及执行的时间。
对数据的操作是使用数据库时频繁发生的行为,为了提升对用户的友好性,Waterdrop提供了许多数据管理接口,以方便用户对数据进行查看和编辑。
Waterdrop可以根据用户选择的数据,生成对应的SQL语句,以方便用户对SQL的构造与编写。数据对象可以来自表整体或者仅是表数据页内的部分值(不允许来自语句结果窗口),二者允许的语句自动生成方式和类型有所不同。
1.3.1.1.2方言选择支持
TDH支持完整的完整的SQL 99标准和SQL 2003核心扩展,支持Oracle PL/SQL 和IBM DB2 SQL/PL存储过程,SQL与存储过程支持Oracle、DB2、Teradata、HiveSQL等多种数据库方言。各个厂家的SQL语法都与标准SQL语法有一些差异,具有自己的方言。TDH的SQL和存储过程支持多种方言,可以根据需要,选择Oracle、DB2以及Teradata方言。只要设置相应的方言开关,就可使用该方言进行开发。
1.3.1.1.3存储过程支持
TDH平台兼容Oracle PL/SQL、IBM DB2 SQL PL、Teradata宏,包括数据类型、函数、流程控制、Package、游标、异常处理以及动态SQL等语法。
PL/SQL基本语句支持
TDH平台对基本语句的支持包括:赋值语句、匿名块执行、函数定义和调用、存储过程定义调用、UDF/UDAF调用。
- 赋值语句
支持赋值语句,并有完整的作用域机制和可见性。变量的作用域为变量申明开始到当前语句块结束。当外部过程和内嵌过程定义了相同名字的变量的时候,在内嵌过程中如果直接写这个变量名是没有办法访问外部过程的变量的,可以通
过给外部过程定义一个名字outername,通过outername变量名来访问外部过程的变量。
- 匿名块执行
PL/SQL 匿名块语句是可以包含 PL/SQL 控制语句和 SQL 语句的可执行语句。它可以用来在脚本语言中实现过程逻辑。匿名块中可以有一个可选的DECLARE段用以声明本块所使用的变量,直接写在最外层的匿名块会立即执行(区别于写在函数或者包内部的匿名块),也是PL/SQL程序的唯一入口。
- 存储过程调用
支持存储过程的调用。PL/SQL 过程引用由过程名以及随后的参数(如果有的话)组成。
PL/SQL数据类型支持
TDH平台对PL/SQL数据类型的支持包括,标量类型、集合类型及其方法(COUNT()/LIMIT()/etc.)、RECORD类型、隐/显式类型转换。
- 标量类型
标量类型的含义是存放单个值。Inceptor中支持的标量类型为int/double/string等Inceptor中所有支持的类型。
- 集合类型
Inceptor支持的集合类型主要分为3大类:Associative array,Nested table,Variable-size array。
- RECORD类型
Inceptor支持RECORD类型。类似C语言struct类型的临时记录对象类型,其变现形式为“单行多列”,也可能是“单列”。在PL/SQL当中表的schema对应到一个RECORD类型的,用户也可以定义自己的RECORD类型而不和表schema发生任何关系。
- cursor类型
Inceptor支持cursor类型。cursor用于提取多行数据,定义后不会有数据,使用后才会有数据。
- 隐/显式类型转换
Inceptor支持的显式类型转换:
to_number(value) 一般为字符类型转换为数值类型
to_date(value, 'yyyymmdd') 字符类型转换为日期类型
to_char(value) 数值类型转换为字符类型
Inceptor支持的隐式类型转换:
连接时(||),数值类型一般转为字符类型;赋值调用函数时,以定义的变量类型为准。
Pl/SQL其它复杂支持
- Inceptor支持流程控制语句:IF/ELSE IF/ELSE语句,GOTO语句、LOOP循环、FOR循环、FORALL循环、WHILE循环、CONTINUE(WHEN)语句、EXIT(WHEN)语句
- Inceptor支持游标:显式CURSOR及其基本操作:OPEN/FETCH(BULK COLLECT)/NOTFOUND/etc.;支持SELECT (BULK COLLECT) INTO语句
- Inceptor支持Package包,包括包内全局变量、包内类型、包内函数。包内全局变量定义在包头部分。包内类型在包头定义,用户可以直接使用定义好的type。包内函数在包头处声明,在包体实现。
PL/SQl异常支持
Inceptor支持用户自定义异常和系统预定义异常;支持RAISE语句;支持WHEN (OR) THEN (OTHERS)异常处理;支持存储过程内部和存储过程之间的异常传播;部分系统预定义异常抛出点;部分编译时刻错误检测。
- 系统预定义异常
ACCESS_INTO_NULL 未定义对象
CASE_NOT_FOUND CASE 中若未包含相应的 WHEN ,并且没有设置 ELSE 时
COLLECTION_IS_NULL 集合元素未初始化
CURSER_ALREADY_OPEN 游标已经打开
DUP_VAL_ON_INDEX 唯一索引对应的列上有重复的值
INVALID_CURSOR 在不合法的游标上进行操作
INVALID_NUMBER 内嵌的 SQL 语句不能将字符转换为数字
NO_DATA_FOUND 使用 select into 未返回行,或应用索引表未初始化的元素时
TOO_MANY_ROWS 执行 select into 时,结果集超过一行
ZERO_DIVIDE 除数为 0
SUBSCRIPT_BEYOND_COUNT 元素下标超过嵌套表或 VARRAY 的最大值
SUBSCRIPT_OUTSIDE_LIMIT 使用嵌套表或 VARRAY 时,将下标指定为负数
VALUE_ERROR 赋值时,变量长度不足以容纳实际数据
LOGIN_DENIED PL/SQL 应用程序连接到数据库时,提供了不正确的用户名或密码
NOT_LOGGED_ON PL/SQL 应用程序在没有连接数据库的情况下访问数据
异常
PROGRAM_ERROR PL/SQL 内部问题,可能需要重装数据字典& pl./SQL 系统包
ROWTYPE_MISMATCH 宿主游标变量与 PL/SQL 游标变量的返回类型不兼容
SELF_IS_NULL 使用对象类型时,在 null 对象上调用对象方法
STORAGE_ERROR 运行 PL/SQL 时,超出内存空间
SYS_INVALID_ID 无效的 ROWID 字符串
TIMEOUT_ON_RESOURCE 在等待资源时超时
- 支持存储过程内部和存储过程之间的异常传播
- 支持部分系统预定义异常抛出点
1.3.1.1.4分布式事务处理
事务处理(transaction)是数据库保证原子性(atomicity)的方法。原子性是指一系列任务在系统中只会有完成和未完成两种状态,不会有只完成了一半的情况。事务处理的任务都是对表本身有修改的语句,包括增删改,也就是SQL中的DML语句:LOAD/INSERT/UPDATE/DELETE。TDH支持通过Inceptor Shell和JDBC/ODBC接口进行事务处理。
Inceptor SQL的事务处理指令为COMMIT TRANSACTION (提交事务)或者ROLLBACK TRANSACTION(回滚事务,撤回事务)。在Inceptor中对事务表的映射处理时,系统会默认任何active session都包含在一个事务中,所以无需像在一些其他数据库中专门通过BEGIN TRANSACTION开始事务。在Inceptor中COMMIT TRANSACTION或者ROLLBACK TRANSACTION后,一个事务即结束,系统会默认接着自动开始另一个事务。
1.3.1.1.5查询优化服务
CBO(CostBased Opimization)
CBO全称是Cost Based Optimization(基于代价的优化方式),是SQL执行计划重要的优化手段。Inceptor对大数据平台原有的CBO功能进行了增强和扩展,进一步提升了SQL兼容性和执行性能。
性能提升方面,在测试TPC-DS标准测试集时,开源Hive在开启CBO优化以后,平均有2.5倍的性能提升。Inceptor基于原有的功能进行了扩展和增强,在开启内置CBO后,约10%的测试场景性能提升3~4倍,接近20%的场景性能提升40%,约有80%的执行计划等于或接近最优计划。实际海量数仓业务中,预计CBO能够提供较好的性能优化提升。
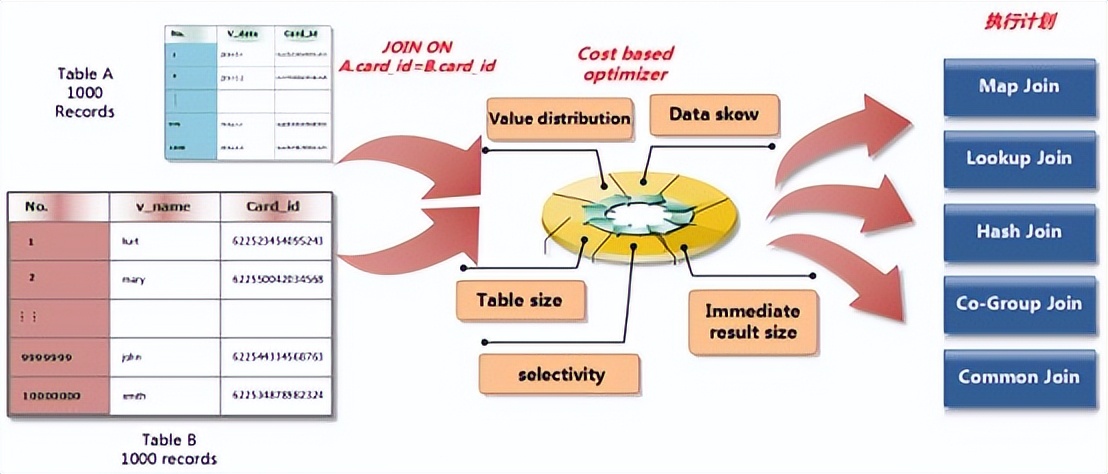
RBO(Rule Based Optimization)
RBO全称是Rule Based Optimization(基于规则的优化方式),应用静态优化规则生成一个优化的逻辑执行计划,通过一组简单的启发式规则和打分原则来确定语句的执行过程和访问方式的,其中排名越靠前,被认为效率越高。
MBO(Materialized view Based Optimizer)
MBO全称是Materialized view Based Optimizer(基于物化视图的优化器),它可以基于物化的OLAP Cube或者视图来优化输入的SQL查询,根据对执行成本的计算,决定是否执行读取物化对象的存储计划。
智能索引
大数据平台中部分数据存储上可以建立索引,达到查询加速的效果。Inceptor内置智能索引功能,可以识别出底层存储具备的索引,并在查询时优先使用存储上的索引。
智能索引技术具有以下特点:
- 查询计划智能使用最快速的索引
- 无需用户在SQL中指定索引
- 对指定查询,根据该表有的多个索引创建不同的执行计划
- 根据成本计算性能最佳的执行计划和索引
- 支持精确查询和模糊查询
- 查询延时百毫秒级
比如Hyperbase支持多种索引,包括全局索引(Global Index)、局部索引(Local Index)、高维索引(High-dimensional Index)以及全文索引(Full-text Index)等;结合Inceptor支持通过SQL进行复杂条件毫秒级高并发查询,同时查询计划智能使用最快速的索引,无需用户在SQL中指定索引。对指定查询,根据该表有的多个索引创建不同的执行计划,根据成本计算性能最佳的执行计划和索引,与此同时,支持精确查询和模糊查询。相对于普通索引技术,智能索引技术基于代价的执行优化,准确率高,性能更好,能满足各类复杂场景需求,包括基于条件的多表关联即席查询与统计,可以满足高速的OLAP数据分析应用需求。
相对于普通索引技术,CBI准确率高,性能更好,满足复杂场景需求。
1.3.1.2 实时计算平台
Transwarp Slipstream是星环专为企业级用户打造的流计算引擎,主要应用于流数据加工,具体特点如下:
- Transwarp Slipstream具有高性能、稳定性好等特征;并且根据在测试和实际部署应用中遇到的问题和需求,丰富Transwarp Slipstream的功能、简化流计算应用的开发以及管理成本;另外Kafka作为生产环境中常用的数据源,Transwarp Slipstream也做了对应的性能优化和功能开发。
- 准实时处理: Transwarp Slipstream同时兼具批处理和事件两种处理模式,其数据处理的延迟在100毫秒到2秒之间,因此Transwarp Slipstream可以满足绝大部分的准实时处理数据的场景。
- 高吞吐量:Transwarp Slipstream具有高吞吐量的特点,与Storm相比,Transwarp Slipstream的吞吐量要高2~5倍。
- 灵活扩展及高容错:Transwarp Slipstream集群支持灵活的进行线性扩展。
- 简单丰富的编程接口:Transwarp Slipstream提供高级语言和SQL的编程接口,降低用户的编程难度,让用户可以通过简单的接口完成复杂的业务处理逻辑。
- 支持多种数据源:Transwarp Slipstream内置支持多种数据源,简单的如文件系统、 Socket连接,复杂的如Kafka、Flume等;还支持用户自定义数据源。
- 丰富的结果处理:用户可以将流计算的处理结果进行多种处理,可以持久化到关系数据库、HDFS、Hyperbase等;也可以通过接口服务将结果推送到其他系统,进行分析统计展现等。
高性能:Transwarp Slipstream支持将接收到的数据持久化到Off-Heap和SSD,可以有效防止GC的影响,消除流计算的性能波动;支持多Receiver模型,这样可以提高数据接收的并行度;Transwarp Slipstream创建的Receiver能够自动识别Kafka集群数据的Locality,避免Receiver接收数据时占用不必要的网络带宽。
高可用:Transwarp Slipstream能够保证用户的流计算应用运行过程中不丢失数据。Transwarp Slipstream通过WAL(Write Ahead Log)以及Spark框架中RDD的重算机制,可以保证在计算节点发生故障时,数据也能被正常的处理;通过Checkpoint机制,当流计算应用的Driver从故障恢复之后,能够将发生故障时还未处理的数据处理,保证数据的不丢失。
安全:Kafka作为生产环境中最常用的数据源之一,用户对其安全性的需求非常迫切。星环科技为Kafka实现了一套访问控制管理策略,只有授权的用户才可以对Kafka集群进行读写操作,避免发生数据泄露或者其他用户发生误写操作。
交互式探索分析:Transwarp Slipstream支持将实时数据流转成列式存储存放到Holodesk上,可以利用 Transwarp Inceptor使用SQL对准实时的数据进行Ad-hoc分析以及利用R进行数据挖掘等。
流式机器学习:Transwarp Slipstream支持用户在实时计算过程进行统计学习和机器学习,如聚类算法,可以实时调整聚类中心;分类算法可以实时更新分类模型,并对流数据进行类比判断。
易开发:Transwarp Slipstream相比于Storm提供了一套简单的编程接口,但在开发一些复杂统计分析的业务时还是过于复杂,Transwarp Slipstream支持用户在开发流计算应用时使用SQL进行数据转换与统计分析,让用户更轻松的实现复杂的操作,将主要的精力放在业务本身而不是流计算框架。
易管理:Stream JobServer是Transwarp Slipstream提供的一套流计算应用的管理服务。通过Stream JobServer,用户可以使用管理界面提交运行、监控、停止流计算任务,让流计算任务更易管理,降低流计算应用的管理运维成本。另外通过Transwarp JobServer,可以让多个流计算应用共享一组计算资源,从而提高资源的利用率。
SQL支持
Transwarp Slipstream实时流式计算系统同时具备分布式、水平扩展、高容错和低延迟特性。系统通过在软件层面通过冗余、重放、借助外部存储等方式实现容错,可以避免数台服务器故障、网络突发阻塞等问题造成的数据丢失的问题。
Transwarp Slipstream支持SQL,使得用户可以通过SQL的方式实现业务逻辑,大大降低了流应用开发的门槛。SQL几乎可以应用于所有业务场景,包括ETL工具,规则报警工具等简单业务场景。对于更复杂的业务逻辑,用户可以选择使用PLSQL,属于高级功能。
Transwarp Slipstream可以针对不同的数据源、不同的数据接入方式、不同的处理时效性要求,组合实现技术方案,具有灵活度高、针对性强等特点,完全满足客户在流式计算方面的任何需求。
Transwarp Slipstream在语法上对SQL和存储过程语法的完美支持,在处理机制上支持按时间切片后进行批量处理,也支持基于事件触发,这使得其在功能上和性能上都能满足几乎所有的流数据的处理场景:
功能上,Transwarp Slipstream是使用StreamSQL,实时从数据源获取一个mini-batch的数据,之后的这批数据参与计算和分析处理的原理完全等用于一张物理表。
数据输入与输出
Transwarp Slipstream可以接受来自文件系统、Kafka、Flume、TCP Socket,本来文件系统的数据源或者用户自己定义的输入源。Transwarp Slipstream支持Flume日志处理数据流、各类企业消息总线或ZeroMQ等消息通讯库、Kafka等分布式消息系统也支持各种生产系统应用日志、渠道与交易系统的WebSocket信息流、外部系统的XML或JSON字节流。
用StreamSQL编写流应用的用户可以通过CREATE STREAM创建流的语法,对各种数据源的数据进行模型创建。按照源数据的格式可以通过标准sql语法中substr、replace等函数对结构化数据和半结构化数据完成解析,复杂的数据格式也可以通过编写UDF程序实现对源数据的解析。
Transwarp Slipstream中流数据实时处理完成的数据支持多种输出方式,基于数据源连接Stargate技术,通过SQL支持结果输出到分布式K-V数据库Hyperbase进行在线检索查询;支持输出到分布式文件系统HDFS,并支持输出格式为Textfile、ORC等格式;支持输出到分布式内存列式存储Holodesk中;支持输出到分布式消息队列Kafka中,使用Kafka作为消息总线,业务系统从Kafka中消费数据进行实时展现处理等。
流处理模式
Transwarp Slipstream提供同时支持事件驱动和微批处理的混合计算引擎,基于事件驱动模型,逐条读取数据流中的数据,使得实时处理延时达到毫秒级别,并具备单节点百万级别的吞吐。基于微批处理模型,支持将一批任务对应一个分布式弹性数据集,通过微批处理,提高吞吐量。
事件驱动模式满足低至5ms的低延时需求,而微批处理模式则满足高吞吐的需要。
复杂逻辑处理CEP
Transwarp Slipstream支持复杂逻辑处理CEP(Complex Event Processing),满足对流数据进行事件模式的过滤,模式包含逻辑控制、事件顺序操作以及生命周期等。支持指定复杂事件模式定义在某个时间范围内多种操作组合在一起的一系列有序事件,通过复杂逻辑事件处理在实时数据流中找到满足这种模式的事件的组合。
复杂事件处理由事件和操作两部分组成:事件就是数据流中的数据,通常会在上面加上一些过滤条件,操作可以逻辑控制、事件顺序操作以及生命周期等,将这种通过操作组合在一起的一系列事件成为复杂事件模式。而实时复杂事件处理复杂事件处理由事件和操作两部分组成:则是在实时数据流中找到满足这种模式的事件的组合。
Slipstream所支持的就是在实时数据流中找到满足这种模式事件的组合,当前市面上流行的Spark Streaming及Storm目前还不支持CEP的处理,而Flink虽然可以支持CEP的操作,但是无法在模式中体现事件的关系,用户需要编写自己的逻辑代码来完成这部分的判断操作,因此带来额外的使用上的代价以及性能上的损失。Slipstream提供的SQL使用PATTERN关键字表示定义一个CEP模式,使用逗号来分割不同之间之间的顺序,WITHIN关键字定义了事件生命周期。这样通过一条简单的SQL就实现了过去可能需要上百行逻辑代码才能完成的功能。
关联对比
Transwarp SlipStream具有很强的可用性,包括复杂时间处理 CEP 引擎,全面的ANSI SQL支持,支持多种时间窗口并能容忍数据的乱序到达,允许多流的聚合分析,以及流上数据和历史数据关联,此外Slipstream还支持用户在流上运行一些数据挖掘的模型。
支持Top-K和排序操作
Transwarp SlipStream中支持时间窗口内数据的自动时间保序,支持对于时间窗口内数据通过SlipStreamSQL中Order by语法进行排序操作,支持降序以及升序,并通过limit K语法实现Top-K数据的提取。
支持与静态表之间的关联
这是实际业务中流上数据分析的必要功能,一些复杂的实时流处理场景,需要支持流上数据与静态表的关联,在Transwarp SlipStream中,Stream SQL支持流数据表和静态表的Join操作,并针对数据量以及不同数据源的静态表通过Lookup Join、MapJoin等方式进行性能优化。
支持多个数据流的关联处理
Transwarp SlipStream中支持流数据表与流数据表的Join操作,实现多个数据流的关联分析。
支持类SQL接口
支持SQL 2003标准语法,支持where子句,GroupBy和Join,支持窗口函数,UDF函数等。使用StreamSQL,用户只需要有编写普通SQL的经验,就可以写出高效、安全、稳定的流处理应用。
这种交互方式实现流处理应用在易用性、产品化程度和迁移成本等诸多方面都表现的很出色,它给编写流应用的用户带来的体验也是颠覆性的。
实时机器学习
Transwarp Slipstream支持实时机器学习,通过星环的Transwarp Sophon产品可以做到离线训练,实时流数据经过Slipstream处理之后保存到分布式存储系统中,Sophon可以对保存在分布式存储中的流数据进行分布式训练并同步更新在线预测模块中的模型,通过各种分类聚类算法对实时流数据进行在线的预测。
实时的机器学习可由离线训练和在线预测两部分组成。实时数据基于PL/SQL进行数据转换清洗后入库,经过离线训练后,同步更新在线预测模块的中的模型,并通过各种分类、聚类算法进行在线预测。算法模型支持特征工程、聚类、分类、推荐、异常检测、时序预测等。
时间窗口统计
Transwarp Slipstream支持时间窗口统计,满足对一定的时间窗口区间做多表关联、聚合或者统计。
Slipstream里的窗口(STREAMWINDOW)跟SQL标准的窗口不同,在Slipstream中 STREAMWINDOW 主要作为时间分割的单位。用户的流应用一般会对一定的时间区间做多表关联、聚合或者统计。
流处理的窗口有两种:
- 滑动窗口
滑动窗口需要由两个量来定义:窗口长度(LENGTH)和滑动间隔(SLIDE)。滑动窗口是指按照一定的 SLIDE 向未来滑动的长度为 LENGTH 的窗口。相邻两个窗口之间可能会有重叠的部分。
滑动窗口中有一个特例是无限滑动窗口——它的窗口长度为无限长(INFINITE)。它的意思是,窗口每滑动一个间隔会触发一次计算,但是每次触发计算的窗口都会包含所有之前的窗口覆盖的区间。一个典型的无限滑动窗口的应用是对网页访问次数进行统计,每隔一段时间输出从开始到当前时间的累积值。
- 跳动窗口
当窗口间隔和滑动间隔相同,滑动窗口就退化为跳动窗口。跳动窗口就是滑动窗口 LENGTH = SLIDE 的特例。所以跳动窗口只需要一个时间长度(INTERVAL)即可定义,它既是窗口长度也是滑动间隔。
一些网页流量统计、基于规则的业务,会频繁需要在一定的窗口上进行统计分析,如对时间窗口内统计指标进行规则判断是否触发告警。
低延时高吞吐量
在吞吐方面,包括Storm在内的大部分分布式流处理框架都以单条记录为粒度来进行处理和容错,单条记录的处理代价较高,而Transwarp Slipstream不仅支持类似Storm的处理模式,同时支持微批处理模式,微批模式的吞吐量显著高于Storm,用户可以根据业务需求自主选择流数据处理模式。
Transwarp Slipstream微批处理模式具有高吞吐量的特点,与Storm相比,Transwarp Slipstream的吞吐量要高2~5倍。
1.3.1.3数据检索平台
Hyperbase实时在线数据处理引擎以开源Apache HBase为基础,具备与传统数据库相近的接口以及开发方式,以减少系统迁移和新应用开发成本,支持SQL2003以及PL/SQL,星环的Hyperbase集OLTP、OLAP、批处理和搜索引擎于一体,满足企业高并发的在线业务需求。
在OLTP方面,Hyperbase支持高并发毫秒级数据插入/修改/查询/删除(CRUD),结合InceptorSQL引擎,可以支持通过SQL进行高并发的CRUD;支持常见数据类型,可更高效的存取数据。在OLAP方面,Hyperbase支持多种索引,包括全局索引(Global Index)、辅助索引、局部索引(LocalIndex)以及高维索引(high-dimensionalindex);结合Inceptor,可进行行列存储转换,进行秒级高效分析;同时支持复杂查询条件,自动利用索引加速数据检索,无需指定索引;与Inceptor引擎相结合后,充分利用Hyperbase的内部数据结构以及全局/辅助索引进行SQL执行加速,可以满足高速的OLAP数据分析应用需求。
在批处理方面,Hyperbase通过为Inceptor引擎提供高效数据扫描接口,通Inceptor的扩展SQL语法,使得Inceptor能在Hyperbase之上做全量数据的高速统计,性能会比Hive/MapReduce跑在HBase上快5~10倍。此外,Hyperbase还支持全文索引,通过建立增量全文索引,对于全文关键字搜索达到秒级的返回。
Transwarp Hyperbase支持多数据,包括结构化数据、半结构化(JSON/BSON,XML形式存储)、非结构化数据,例如纯文本、图片或者视频大对象的高效存储以及读取。通过Inceptor对Hyperbase上的数据进行SQL统计分析,完整支持SQL2003和大部分PL/SQL,支持使用大表交互等一系列复杂的SQL分析语法操作。
Transwarp Hyperbase支持多种索引,包括全局索引(Global Index)、局部索引(Local Index)、高维索引(High-DimensionalIndex)以及全文索引(Full-TextIndex)等;结合Inceptor支持通过SQL进行复杂条件毫秒级高并发查询,满足在线存储和在线业务分析系统(OLAP)的低延时需求,实现高并发低延时的OLAP查询。
Transwarp Search用于在企业内部构建大数据搜索引擎。它能够在PB数据量级上实现秒级延迟的搜索功能;在开发接口方面,Search提供了完整的SQL语法支持并提供了搜索语法SQL扩展,通过和Inceptor优化器有效结合,使开发者无需了解底层架构就可以开发出高效的搜索引擎。Search创新的使用了堆外内存管理技术来提高系统的健壮性,避免了GC问题对系统的影响;此外,Search还支持混合存储,通过将热数据存储在SSD上来提升查询速度。
Transwarp Search基于开源的Elasticsearch进行开发,在其基础架构的基础上进行了多种功能优化,并通过Esdrive实现了SQL交互方式。Transwarp Search是一个可扩展的分布式全文搜索和分析引擎。在Transwarp Data Hub中,Transwarp Search扮演两个角色:
- 作为Transwarp Hyperbase全文索引的底层实现。
- 作为一个单独的服务,它是:分布式文件存储(Distributed Document Store);强大的搜索引擎。常见应用场景有海量数据的存储和搜索、日志分析等。
分布式列式数据库
Hyperbase是星环基于HBase开发的分布式NoSQL数据库,它有效的解决了HBase中存在的问题。
SQL语法支持
Hyperbase在语法上对SQL和存储过程完美支持,Hyperbase通过星环自研的交互式分析引擎Inceptor支持SQL,用户可以通过编写SQL在Hyperbase上实现复杂的业务逻辑,极大的降低了使用成本。
索引技术
Transwarp Hyperbase实时分布式数据库融合了多种索引技术,使用索引的时候,支持数据在已创建索引的情况下导入数据,避免数据导入完毕后再创建索引的时间窗口。
目前Hyperbase主要应用在结构化和半结构化的大数据存储上,在逻辑上,Hyperbase的表数据按RowKey进行字典排序, RowKey实际上是数据表的一级索引(Primary Index),由于Hyperbase本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到RowKey中,这是HBase开发中极为常见的做法,但是无论怎样设计,单一RowKey固有的局限性决定了它不可能有效地支持多条件查询。受限于单一RowKey在复杂查询上的局限性,基于二级索引(Secondary Index)的解决方案成为最受关注的研究方向。
为解决这一问题,Hyperbase在索引支持上做了重大的完善和加强。Hyperbase支持多种方式的索引,如:COMBINE_INDEX和 STRUCT_INDEX。COMBINE_INDEX使用一列或者多列组合生成索引,而STRUCT_INDEX对STRUCT类型中的一个或多个字段生成索引。 Hyperbase中的索引还可根据存储方式分为全局索引(Global Index)和局部索引(Local Index)。全局索引的索引存储与原表独立,索引本身是以一张表的形式存在(索引表)。局部索引在原表中创建一个新的列族(索引列)。Hyperbase在使用索引的时候,能智能化选择性能更高的索引支持数据查询,智能化选择索引使得用户在使用索引时更加透明和方便。
全文检索
TDH支持半结构化(JSON/BSON形式存储)和非结构化数据的高效存取,其中半结构化数据支持字段内部建立索引。提供全文索引功能,支撑内容管理,实现文字等非结构化数据的提取和处理;提供增量创建全文索引的能力,可以实时搜索到新增的数据。
智能索引
大数据平台中部分数据存储上可以建立索引,达到查询加速的效果。TDH内置智能索引功能,可以识别出底层存储具备的索引,并在查询时优先使用存储上的索引。
智能索引技术具有以下特点:
- 查询计划智能使用最快速的索引
- 无需用户在SQL中指定索引
- 对指定查询,根据该表有的多个索引创建不同的执行计划
- 根据成本计算性能最佳的执行计划和索引
- 支持精确查询和模糊查询
- 查询延时百毫秒级
比如Hyperbase支持多种索引,包括全局索引(Global Index)、局部索引(Local Index)、高维索引(High-dimensional Index)以及全文索引(Full-text Index)等;结合Inceptor支持通过SQL进行复杂条件毫秒级高并发查询,同时查询计划智能使用最快速的索引,无需用户在SQL中指定索引。对指定查询,根据该表有的多个索引创建不同的执行计划,根据成本计算性能最佳的执行计划和索引,与此同时,支持精确查询和模糊查询。相对于普通索引技术,智能索引技术基于代价的执行优化,准确率高,性能更好,能满足各类复杂场景需求,包括基于条件的多表关联即席查询与统计,可以满足高速的OLAP数据分析应用需求。
相对于普通索引技术,CBI准确率高,性能更好,满足复杂场景需求。
小文件的高效存储
Hyperbase上支持ObjectStore对象存储,针对大量小文件(一般小于等于10M)在HDFS上存储的方式进行优化,将数据文件封装为ObjectStore对象进行存储,支持高效率读写ObjectStore对象。
大对象数据存储检索
Hyperbase支持海量影像数据或文件数据等大对象数据的存储和检索,提供稳定高效的入库和检索能力。
综合搜索
Transwarp S earch基于开源的Elasticsearch并对其进行了优化。Transwarp Search是一个可扩展的分布式大规模搜索引擎,它能够提供大规模搜索的引擎,以及海量数据上的统计分析能力。Search和Inceptor SQL Engine配合使用,提供标准的SQL接口,以及兼容Oracle扩展标准的全文检索的SQL扩展。
在系统可用性方面,Search也做了大量的工作,包括采用对外的内存管理技术让系统更加可靠和稳定,支持混合存储模型,以更好的利用SSD等快速存储从而加速系统性能。
根据星环的某次测试,用10台机器构建的Search集群,可以在几百毫秒内完成对100TB的数据的模糊检索。
SQL支持
综合搜索平台支持标准SQL接口,兼容Oracle扩展标准的全文检索的SQL扩展,通过SQL对文本数据进行关键词搜索,并按照匹配程度排序输出。
TDH平台上Inceptor组件通过一层抽象的数据源连接器Stargate对外提供统一SQL服务。从而让用户可以使用SQL语法对存放在Hyperbae和Search数据进行全文检索,可以将全文检索作为SQL的一种过滤条件,接口满足数据中心接口标准。功能上可以做到:
- 支持简单的统计功能,如计算命中结果数量,将检索后的结果按分组统计等。可以通过在select语句中对分组字段进行group by后再使用count、sum等函数实现分组统计。
- 支持按照相关度排序,可以按照搜索内容的匹配相关程度排序返回结果;支持按照某一字段排序,可以在查询语句中使用order by语法实现按照某一字段排序。
- 支持词组检索的方式,即一个词组需要完全匹配,支持精确完全匹配。
- 支持权重检索,即不同关键词权重不同,包含权重较高的关键词的条目优先返回。可以通过在select语句中加上where matches字句实现权重条件匹配过滤。
- 支持模糊检索,可以是前模糊、后模糊、前后模糊,不必满足所有关键词,返回满足部分关键词的结果。可以通过在select语句中加上where contains子句配合模糊匹配通配符%实现条件过滤。
- 支持字符距离限定,只匹配各个关键词在一定文本中一段距离出现的情况。可以简单的通过在查询语句中使用substr函数截取文本中的一段再进行where matches匹配实现。
- 支持部分结果返回,即结果量较大时,先返回部分结果。
- 支持结果导出,将检索返回的结果导出成文件。支持检索结果对接到数据统计和数据分析模块中进行进一步的处理和分析。用户也可以通过Inceptor的Stargate能力,用SQL语句输出到多种存储介质中,可以是本地或者HDFS文件系统、Inceptor orc表、分布式内存数据库Holodesk等等,进一步的处理和分析。
聚合算子下推
TranswarpSearch支持聚合算子下推,提升搜索聚合分析性能。将过滤聚合操作下推到各分布式服务节点中做本地的数据预处理计算,避免大量网络数据传输(shuffle)带来的性能损耗。将本地计算后的结果汇合后再进行运算,提供亚秒级在线分析性能。
任意条件搜索
平台支持通过SQL进行综合搜索,任意条件组合灵活查询,秒级返回。
TDH平台全文检索能力由Search提供,分布式实时数据库Hyperbase作为补充,在Hyperbae和TranswarpSearch服务之上,星环的交互式分析引擎Inceptor通过一层抽象的数据源连接器Stargate(实现Hyperbae与TranswarpSearch对应的驱动Hyperbase driver和TranswarpSearch driver)对外提供统一SQL服务,这样就构成了TDH平台上全文索引能力的技术架构。
TDH平台上Inceptor组件通过一层抽象的数据源连接器Stargate对外提供统一SQL服务。从而让用户可以使用SQL语法对存放在Hyperbae和 Search数据进行全文检索,可以将全文检索作为SQL的一种过滤条件,接口满足数据中心接口标准。功能上可以做到:
- 支持简单的统计功能,如计算命中结果数量,将检索后的结果按分组统计等。可以通过在select语句中对分组字段进行group by后再使用count、sum等函数实现分组统计。
- 支持按照相关度排序,可以按照搜索内容的匹配相关程度排序返回结果;支持按照某一字段排序,可以在查询语句中使用order by语法实现按照某一字段排序。
- 支持词组检索的方式,即一个词组需要完全匹配,支持精确完全匹配。
- 支持权重检索,即不同关键词权重不同,包含权重较高的关键词的条目优先返回。可以通过在select语句中加上where matches字句实现权重条件匹配过滤。
- 支持模糊检索,可以是前模糊、后模糊、前后模糊,不必满足所有关键词,返回满足部分关键词的结果。可以通过在select语句中加上where contains子句配合模糊匹配通配符%实现条件过滤。
- 支持字符距离限定,只匹配各个关键词在一定文本中一段距离出现的情况。可以简单的通过在查询语句中使用substr函数截取文本中的一段再进行where matches匹配实现。
- 支持结果导出,将检索返回的结果导出成文件。支持检索结果对接到数据统计和数据分析模块中进行进一步的处理和分析。用户也可以通过Inceptor的Stargate能力,用SQL语句输出到多种存储介质中,可以是本地或者HDFS文件系统、Inceptor orc表、分布式内存数据库Holodesk等等,进一步的处理和分析。
自定义扩展
平台支持分词器和词库的自定义扩展,支持第三方或者自定义分词器,满足个性化全文检索需求。
Search为用户提供了几款常用的中文、英文分词器,可选的英文分词器有两种:一是standard分词器,二是english分词器;可选的中文分词器有两种:ik分词器和mmseg分词器。当平台提供的分词器不能满足用户需求时,可以选择第三方或自定义分词器,并且可以支持词库的自定义扩展,只需将自定义分词器或词库的文件放入相应的目录下。
关键词搜索
基于SQL接口的支持,用户在TDH上进行关键字搜索的门槛变得很低,整个关键字搜索的实现过程是:
- 用户可以根据业务场景选择将全量数据存入TranswarpSearch,还是将原始数据存入Hyperbase索引数据存入TranswarpSearch,两种方式对应不同的建表操作。如果是选择使用第二种方式,需要在建立Hyperbase表时定义Fulltext Index、是否启用分析和对分词建立索引。
- 用户可以利用非常简便的使用insert语法插入数据,在数据入库过程中建立索引,也可以使用build index语法对已经入库的数据创建索引,该过程均是利用集群所有计算节点的资源分布式完成。每分钟可以处理几十GB的数据。
- 数据在入TranswarpSearch时会进行分词操作,TDH支持常见的中英文分词器,如IKAnalyzer,根据应用需求可以扩展分词器。目前平台支持的语言包括英文,简体/繁体中文。
- 用户可以利用SQL语法进行任意模糊的关键字搜索。
- 用户可以自由选择将检索结果导出文件,或者是保存到其他存储介质,或者是参与其他数据统计和数据分析。
性能指标
TranswarpSearch支持PB级数据存储搜索能力,并提供毫秒级响应。TDH平台上Hyperbase和Search都支持分区表,支持的最大数据规模不低于千亿级。
1.3.1.4 交互式分析平台
交互式分析是指用户期待秒级的分析响应。为支持在线事务处理、交互式分析、近实时挖掘,或针对操作型数据直接进行复杂、即席的分析性应用需求,传统数据集市、数据仓库等均针对预先定义的分析服务类型进行预先计算。将原始数据做抽取、转换、加载,最后生成物化视图,实现相关分析;同时周期性检查数据存储中的增量数据,优化分析结果,因而无法满足实时、即席的复杂分析要求。此外,数据存储模式的变化,数据量激增之后,传统的在线分析的局限性越来越明显,如数据存取性能下降,连接处理复杂化等。
为了加速交互式分析的速度,Inceptor推出了基于内存或者SSD的列式存储引擎Holodesk。Holodesk将数据在内存或者SSD中做列式存储,辅以基于内存的执行引擎,可以完全避免IO带来的延时,极大的提高数据扫描速度。除了列式存储加快统计分析速度,Holodesk支持为数据字段构建分布式索引。通过智能索引技术为查询构建最佳查询方案,Inceptor可以将SQL查询延时降低到秒级。
Inceptor中Holodesk支持跨内存/闪存介质的分布式混合列式存储,可用于缓存数据供Spark高速访问。Holodesk利用SSD的高IOPS特性进行针对性的存储结构优化,通过列式存储,内置索引等技术,使得在SSD上分析性能比纯内存缓存相差在10%~20%范围左右,提供性能接近的交互式SQL分析能力。由于内存的价格是SSD的近10倍,因此可以采用SSD来替代内存作为缓存,一方面可以增大分布式内存数据库Holodesk存储容量,另一方面可以降低成本,同时性能没有明显损失。
Inceptor可以通过SQL将数据从Hyperbase/HBase以及HDFS上装载入Inceptor分布式内存列式存储Holodesk,星环的Inceptor支持对海量数据的交互式数据分析,具备在秒级扫描分析数十亿条数据的能力。未来可以对不同业务部门开放交互式分析能力,提供现有数据仓库不能满足的交互式内存分析能力。
Holodesk允许用户对多字段组合构建OLAP-Cube,并将cube直接存储于内存或者SSD上,无需额外的BI工具来构建Cube,因此对于一些复杂的统计分析和报表交互查询,Holodesk能够实现秒级的反应。除了性能优势,Holodesk在可用性方面也表现出色。Holodesk的元数据和存储都原生支持高可用性,通过一致性协议和多版本来支持异常处理和灾难恢复。在异常情况下,Holodesk能够自动恢复重建所有的表信息和数据,无需手工恢复,从而减少开发与运维的成本,保证系统的稳定性。
列式存储
平台支持基于内存或者固态硬盘高IO特性优化的列式存储,避免IO带来的延时以提高数据扫描速度。
Holodesk星环自主研发用于应对海量数据OLAP高性能分析查询难题的一款产品,它是跨内存/闪存/磁盘等介质的分布式混合列式存储,常用于缓存数据供Inceptor高速访问。Holodesk内建索引,结合Inceptor计算引擎可提供比开源Spark更高的交互式统计性能,可以达到秒级灵活分析数亿条记录的性能;结合使用低成本的内存/闪存混合存储方案,可接近全内存存储的分析性能。
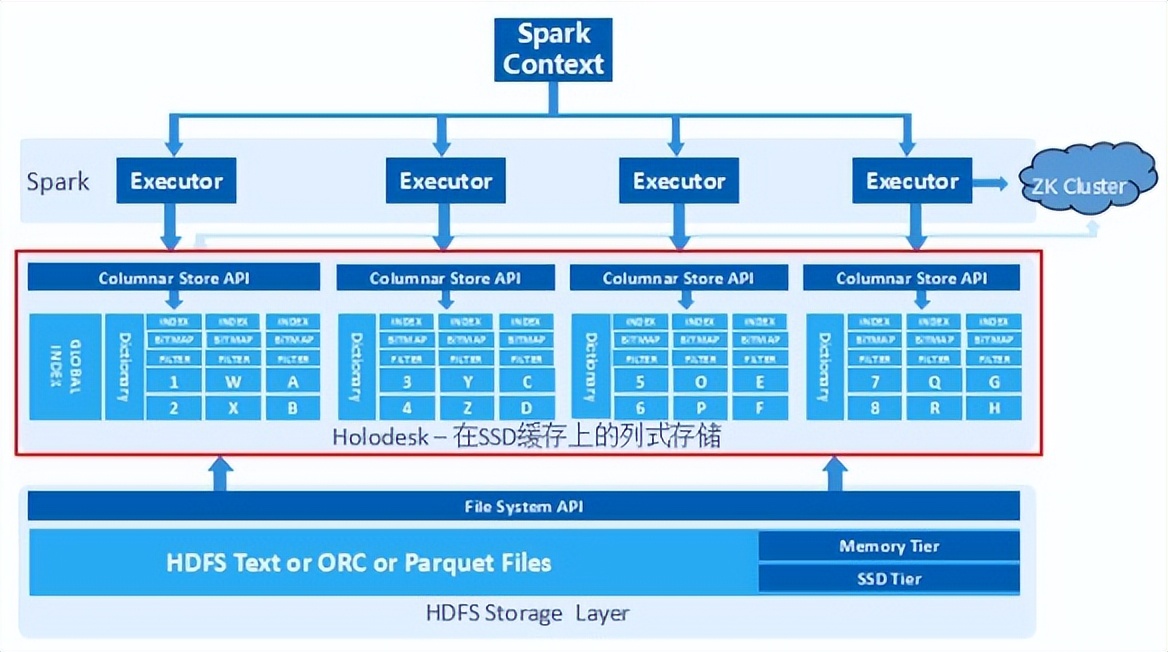
它着力于交互式分析中即时查询效率的提高且能够保证扩展性与稳定性。Transwarp Holodesk 通过 Zookeeper 来管理元数据,从而避免因为单点故障而导致的数据丢失,数据checkpoint 在 HDFS 中。服务在故障恢复之后,Holodesk 能够通过Zookeeper 中的信息自动重建数据与索引,因此有很高的可靠性。
SQL访问
平台支持通过SQL直接访问,提供海量数据任意维度的交互式分析能力。Inceptor可以通过SQL将数据从Hyperbase/HBase以及HDFS上装载入Inceptor分布式内存列式存储Holodesk,星环的Inceptor支持对海量数据的交互式数据分析,具备在秒级扫描分析数十亿条数据的能力。Inceptor未来可以对不同业务部门开放交互式分析能力,提供现有数据仓库不能满足的交互式内存分析能力。
TDH提供ANSI SQL2003语法支持以及PL/SQL过程语言扩展,并且可以自动识别HiveQL、SQL2003和PL/SQL语法,在保持跟Hive兼容的同时提供更强大的SQL支持。支持标准的SQL形式访问数据。由于现有的数据仓库应用大都基于标准SQL,现有应用也大量使用了PL/SQL,要从现有数据库系统迁移到Hadoop,标准SQL以及PL/SQL的支持显得尤为重要。TDH可以支持标准SQL以及PL/SQL,支持复杂的数据仓库类分析应用,使得从原有数据库系统迁移到Hadoop更为容易,可以帮助企业建立高速可扩展的数据仓库和数据集市。
局部索引
平台支持在分布式内存列式存储上建立局部索引,提供OLAP能力,为大表创建索引,支持多维数据灵活分析,无需预先物化计算。
索引和Cube的建立会提升在高过滤和高聚合率的情况下的查询速率和效率,并且使得以更直观地方式从多维度多层面研究数据。Holodesk的索引是将列式存储的每个单元看作整体建立的。索引的创建采用了字典编码技术(Dictionary Encoding)。相对于通过遍历每一条记录进行条件过滤的手段,使用索引大幅度缩短了过滤时间。可以根据需求,选择对一个字段或多个字段创建索引,Holodesk的索引支持所有数据类型。
全局索引
平台可以采用全局索引,快速找到精确查询的记录,索引采用分桶技术,加快寻找索引速度,快速精确定位数据。
Holodesk通过创建全局索引,优化底层存储,对于过滤率较高的情况有很好的优化效应。Holodesk提供了表组织成桶的优化方式,通过分桶技术可以做到:
- 有助于取样
取样是从所有数据随机的抽取一部分样本。当数据极多时,不方便使用全部的数据验证系统功能,这时需要使用样本数据进行测试。表若被分桶,每个桶的内容是对数据的离散后的结果,满足对于样本的要求,所以取样时可以直接抽取任意一桶的全部数据作为样本。
- 减少操作量,提高查询速率
条件过滤时,如果过滤字段和分桶字段一致,可根据哈希结果直接知道该记录所在的相关分桶编号,只在这些分桶查找满足条件的记录,而不用搜索所有的文件,有很高的查询效率。
- 减少Shuffle数据量
分桶操作使得如GROUP BY以及特定场景下的JOIN(多个JOIN表分桶个数相同)能够在一个Stage中完成,避免了Shuffle过程。例如,有两张表对Join Key的列分桶,现对这两张表做JOIN,由于两个表相同列值的记录都在对应表的同一个编号bucket中,因为Inceptor实现了同一个编号的bucket在同一个节点上的co-location的特性,所以可以直接在一个Stage实现JOIN,而不用Shuffle。
物化视图
平台支持物化视图技术,在查询分析时通过MBO进行执行计划优化,提升交互式分析性能与并发度。TDH提供了MBO查询优化服务,MBO全称是Materialized view Based Optimizer(基于物化视图的优化器),它可以基于物化的OLAP Cube或者视图来优化输入的SQL查询,根据对执行成本的计算,决定是否执行读取物化对象的存储计划。
OLAP函数支持
星环TDH支持多个OLAP函数,支持超大数据立方,支持雪花、星型等复杂分析模型。目前支持的函数如下:
表5-2 函数列表
|
序号 |
函数类型 |
TDH |
|
1 |
lead |
支持 |
|
2 |
lag |
支持 |
|
3 |
row_number |
支持 |
|
4 |
rank |
支持 |
|
5 |
dense_rank |
支持 |
|
6 |
percent_rank |
支持 |
|
7 |
cume_dist |
支持 |
|
8 |
ntile |
支持 |
|
9 |
first_value |
支持 |
|
10 |
last_value |
支持 |
|
11 |
min |
支持 |
|
12 |
max |
支持 |
|
13 |
count |
支持 |
|
14 |
avg |
支持 |
分布式 Cube
Transwarp Inceptor将数据缓存在Holodesk中,通过高效的内存计算达到快速扫描海量数据的目的,支持在Holodesk建立索引,提高数据扫描效率,支持在Holodesk建立Cube,使得数据仓库、数据集市类应用的性能进一步提升,灵活、快速的进行模型旋转、钻取等操作。
独立的分布式内存列式存储Holodesk,解决开源Spark的稳定性问题以及进一步提供交互式分析能力,同时为了降低平台建设成本与提高平台内存分析数据量,分布式内存存储可建在内存或者固态硬盘SSD上。
通过创建数据源对应的数据表的元信息,在内存中对数据源创建数据表的结构,根据元信息把当前的数据行生成为一个列式数据块并存储到硬盘,能够更加有效的使用内存,实现后续在硬盘上查询数据的性能达到与在内存上查询数据相近的性能,能够进一步支持后续以高速的查询效率为基础的强大的数据分析能力。进一步的,所述列为索引列时,通过对每个索引列建立一个倒排索引,并采用RadixTree结构将索引列存储到固态硬盘的对应位置的文件中,能够提高后续数据查询的效率。
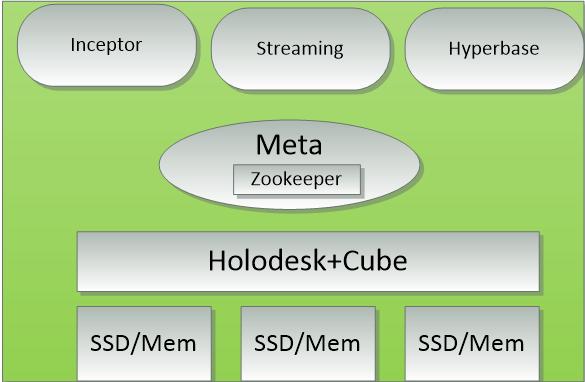
图 Holodesk框架
优势如下:
- 数百亿数据行的查询延迟保持在次秒级别(cube加速)。能够为使用SQL兼容性工具的用户提供ANSI SQL。完整的OLAP方案以实现各类高级功能。拥有对高基数与超大规模业务体系的支持能力。面向成千上万用户的高并发性处理能力。能够处理TB乃至PB级别分析任务的分布式低成本横向扩展架构(列式数据存储放SSD上)。
目前在Holodesk上建立Cube支持的函数如下:
表 函数列表
|
序号 |
函数类型 |
分布式Cube |
|
1 |
And |
支持 |
|
2 |
Or |
支持 |
|
3 |
Add |
支持 |
|
4 |
Sub |
支持 |
|
5 |
Mul |
支持 |
|
6 |
Div |
支持 |
|
7 |
Mod |
支持 |
|
8 |
Abs |
支持 |
|
9 |
Sqrt |
支持 |
|
10 |
Floor |
支持 |
|
11 |
LessThan |
支持 |
|
12 |
EqualOrLessThan |
支持 |
|
13 |
GreaterThan |
支持 |
|
14 |
EqualOrGreaterThan |
支持 |
|
15 |
Equal, |
支持 |
|
16 |
When, |
支持 |
|
17 |
Case |
支持 |
|
18 |
Decode, |
支持 |
|
19 |
Negative |
支持 |
|
20 |
Sum |
支持 |
|
21 |
Avg |
支持 |
|
22 |
Min |
支持 |
|
23 |
Max |
支持 |
|
24 |
Count |
支持 |
1.3.1.5图计算平台
图数据也是结构化数据的一种,它是一种存储信息的结构,每一条记录对应图中的一条边,在这条记录中包含了点与点之间的关系以及这条边的属性信息,这种数据结构存储在二维表中。Transwarp Graphene是一款专门用于大规模图数据计算的产品。图数据分析分为图检索与图计算两类:
- 图检索是从复杂的大规模图中快速找出匹配指定模式节点或边;
- 图计算是指大规模复杂图数据处理和特征提取。
图算法
Transwarp Graphene通过Inceptor引擎完成分布式计算,目前可在海量数据中执行十几种图算法,可满足大多数的应用场景。
目前支持了十几种常见的图分析算法,具体列表如下:
|
算法编号 |
算法名称 |
算法简介 |
|
1 |
PageRank |
PageRank算法计算网络中节点的相关性和重要性,由Google公司发明,常见用途是网页排名。 |
|
2 |
FastUnfolding |
FastUnfolding算法是社区发现算法中的一种,用于快速分类网络节点,将图划分为多个社区。 |
|
3 |
Shortest Path |
Shortest Path算法用于计算网络中两点间的最短距离。 |
|
4 |
Connected Components |
Connected Component用于求解图中的所有连通子图。 |
|
5 |
Strongly Connected Components |
Strongly Connected Components用于求解图中的所有强连通子图。 |
|
6 |
Triangle Counting |
Triangle Counting用于计算图中三角形数量,常用于社交网络结构分析,垃圾邮件分析和欺诈检测。 |
|
7 |
Global Cluster Coefficient |
Global Cluster Coefficient是一种衡量图整体紧密程度的标准,常用于社交网络分析。 |
|
8 |
Local Cluster Coefficient |
Local Cluster Coefficient是一种衡量节点和其邻居的紧密程度的标准。 |
|
9 |
Average Cluster Coefficient |
Average Cluster Coefficient是一种衡量图节点间平均紧密程度的标准 |
|
10 |
Diameter |
Diameter用于计算图的直径。 |
|
11 |
Radius |
Radius用于计算图的半径。 |
|
12 |
Eccentricity |
Eccentricity用于计算图中节点与其他节点距离的极大值。 |
|
13 |
Degree |
Degree用于计算图中节点的度,包括:出度、入度和出入度。 |
SQL支持
用户可以使用统一的编程接口处理普通业务数据与图数据,将图计算、检索场景与传统应用场景紧密结合。以图的边数据作为输入, 通过Inceptor可以使用基于SQL的扩展语法调用图算法。输入和输出数据支持多种数据类型, 与Inceptor平台紧密结合。
数据源支持
Transwarp Graphene兼容分布式文件系统HDFS中文本以及ORC格式作为图分析的数据源。
性能指标
图作为常见的数据表达方式, 被广泛应用于社交网络分析、网页搜寻、推荐系统和安全事件分析等场景。分布式图计算解决了传统图算法受制于物理资源限制的问题,使大规模图挖掘分析成为可能。然而多次迭代下,会造成不稳定的状态。Transwarp Graphene是基于Spark的图计算引擎,将复杂图算法分解为RDD操作。相比Giraph和GraphX,Graphene优化了数据存储和数据传输过程,从而拥有更低的内存负载和更好的稳定性。在对6千5百万顶点、18亿边的数据集的测试中,Graphene成功完成了10轮PageRank运算。而Giraph和GraphX都因内存问题无法成功运行。
Transwarp Graphene通过Inceptor引擎完成分布式计算,目前可在海量数据中执行十几种图算法,可满足大多数的应用场景。性能方面,Transwarp Graphene支持上亿条边的复杂图处理,实际案例中,对一张含有200多万节点、十多亿条边的复杂图进行社区发现分析,在1个小时内完成了一百多个社区发现。
1.3.1.6数据挖掘平台
Transwarp Discover是针对海量数据平台提供的分布式机器学习引擎,主要由开源R语言、Spark分布式内存计算框架以及MapReduce分布式计算框架构成。Discover支持R语言引擎,用户可以通过R访问HDFS或者Inceptor分布式内存中的数据。在Discover中,用户既可以通过R命令行,也可以使用图形化的RStudio执行R语言程序来对TDH中的数据进行分析挖掘,易用性极高。Discover内置了大量常用的并行化机器学习算法和统计算法,同时兼容数千个开源的R包,配合TDH内置的高度优化的专有算法,可高速分析关联关系网络等图数据。此外,Discover还支持用户直接将R语言代码处理逻辑作用于分布式数据集中,使用户的操作更加灵活方便。
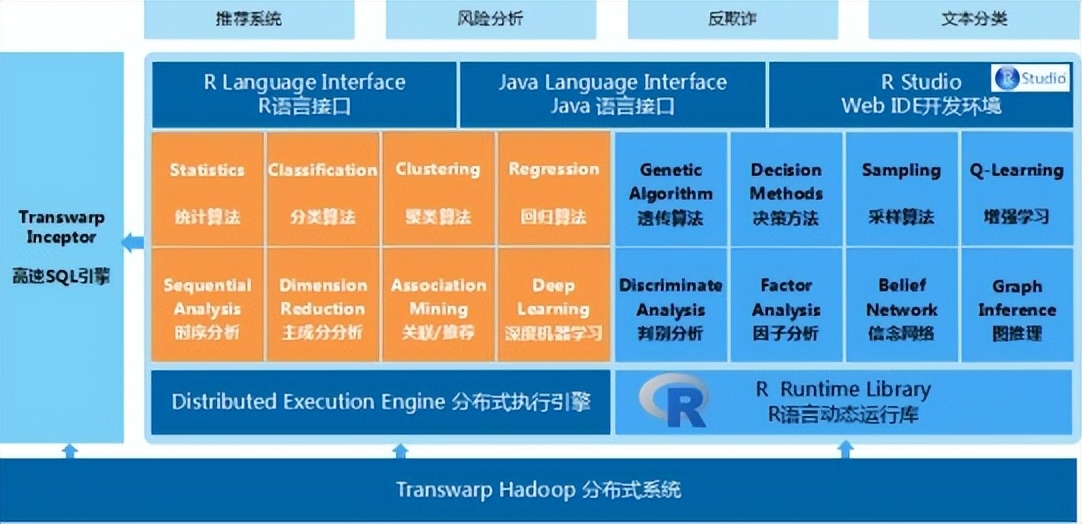
星环Discover的并行化算法库主要包含机器学习算法库与统计算法库,利用Spark在迭代计算和内存计算上的优势,将并行的机器学习算法与统计算法运行在Spark上,可以有效提高大数据量上算法的执行效率。例如:机器学习算法库包括逻辑回归、朴素贝叶斯、支持向量机、随机森林、聚类、线性回归、推荐算法等,统计算法库包括均值、方差、中位数、直方图、箱线图等。可以支持后期在平台上搭建多种分析型应用,例如用户行为分析、精准营销,将对用户贴标签、进行分类,此类应用都会用到平台的数据挖掘功能。
Discover集成了RStudioServer,RStudio是R的一种强大而便捷的IDE,提供基于web的开发环境,支持多人同时在线。同时平台提供的RStudio预加载好了并行化后台以及并行化执行引擎的连接模块,并将R脚本的编写、编译、跟踪执行以及中间变量查看和绘图集于一体,为用户提供了一个强大的R的操作环境。用户除了可以自行编写R的程序脚本、调用开源版本R提供了数千个R的包和函数之外,还可以直接调用Discover实现的并行化机器学习算法库。Discover目前实现的并行化机器学习算法已经提供了常用的分类、聚类、回归、推荐等功能。还会根据进一步的具体需求在平台开发的中进一步实现更多的并行化算法。此外,Discover中还包含了完整的并行化算子库,用户可以通过并行化算子进行并行化算法二次开发。
Sophon是除Discover之外的另一个机器学习产品,是一款深度学习交互式探索引擎。
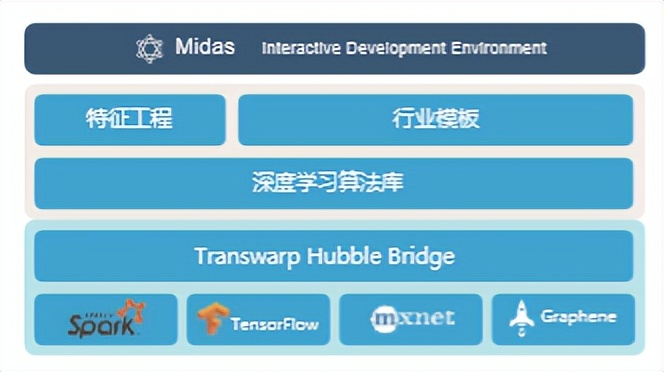
它和Discover之间有三点差异:第一,Sophon包含一个交互式的开发IDE——Midas,用户可以在Midas中通过拖拽算子的方式来实现复杂的数据分析工作流程;第二,它内置了100+个挖掘算子,基本涵盖了常用的挖掘算法;第三,它很好的整合了深度学习的框架TensorFlow和MxNet,方便用户在图形化平台上构建神经网络模型并灵活调参。
分布式数据挖掘框架
机器学习算法库
在传统的数据分析应用场景中,数据分析师会使用多种编程语言进行数据的分析。大数据平台可以支持数据分析与挖掘使用到主流编程语言接口,支持R语言进行统计分析与挖掘,并运行在分布式计算框架中,利用R丰富的统计分析库和丰富的图形可视化方法来分析Hadoop中存储的数据;也支持Python等主流数据挖掘语言,能够满足用户多编程语言进行建模分析的需求。
TranswarpR目前实现的并行化机器学习算法已经提供了常用的分类、聚类、回归等功能。还会根据进一步的具体需求在平台开发的中进一步实现更多的并行化算法。此外,Transwarp Inceptor中还包含了完整的并行化算子库,用户可以通过并行化算子进行并行化算法二次开发。
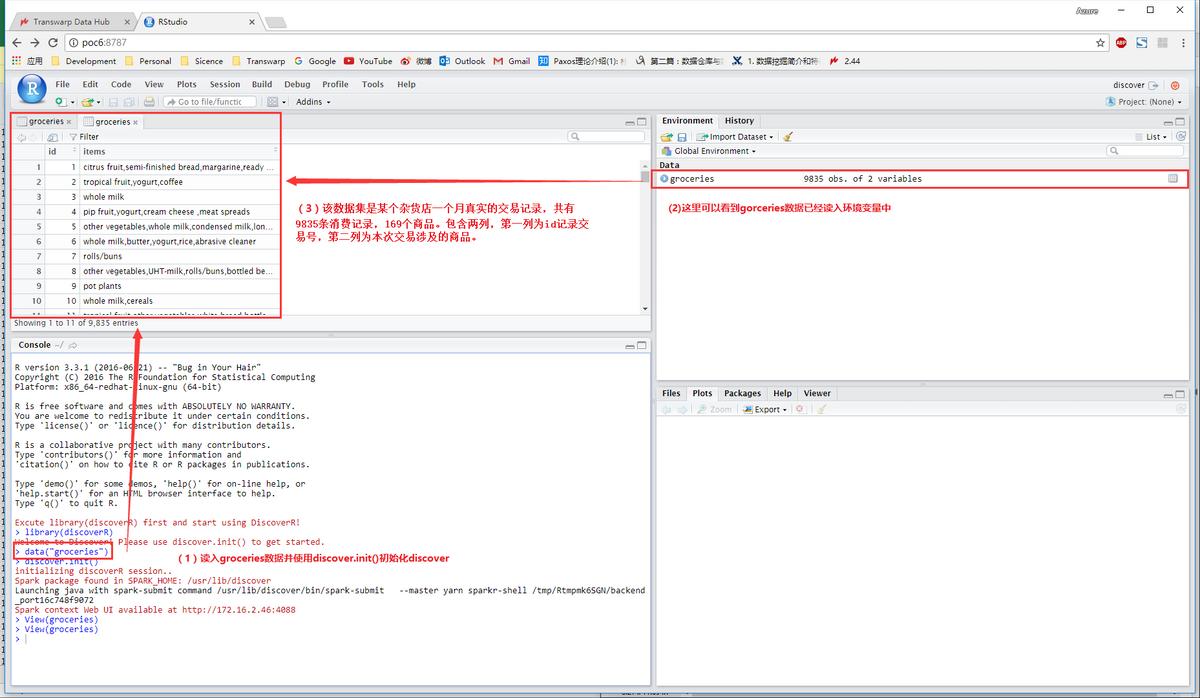
图:Discover-初始化服务
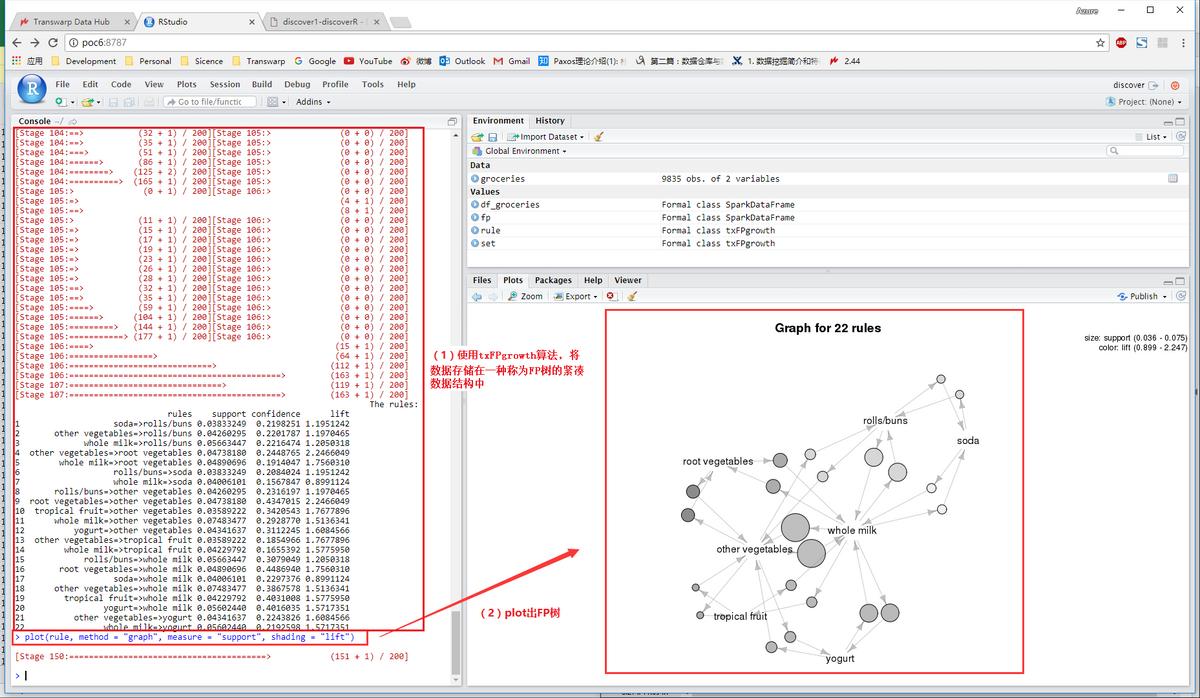
图:Discover-训练模型并制图
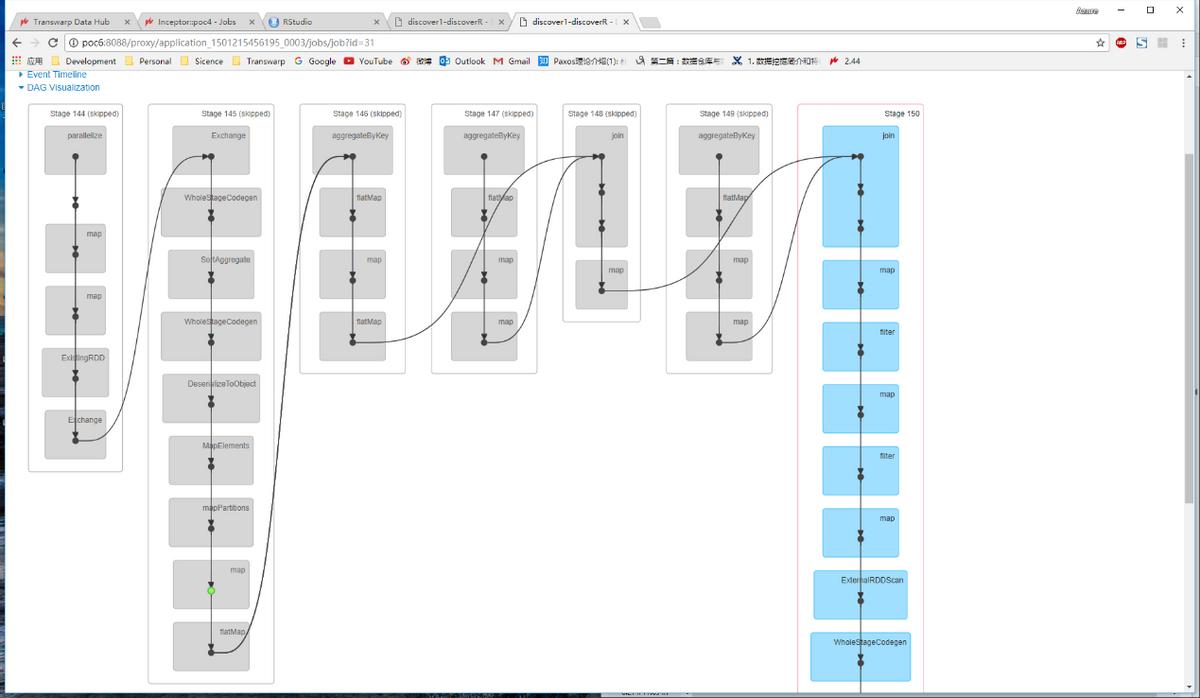
图:Discover-DAG可视化
现有机器学习并行算法列表:
|
算法 |
描述 |
|
Logistic Regression 逻辑回归 |
当前业界比较常用的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等,常用于做分类。 |
|
Naïve Bayes 贝叶斯 |
ML中的一个分类算法,常用于做文本分类。该分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。该模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单实用。 |
|
SVM 支持向量机 |
支持向量机(Support Vector Machine)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析,具有较高的鲁棒性。 |
|
HMM 时间序列算法 |
隐马尔可夫模型(Hidden Markov Model,HMM)作为一种统计分析模型,已经被广泛应用于时间序列分析的不同领域,如语音识别,行为识别,文字识别以及故障诊断等。 |
|
K-Means 聚类算法 |
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。 |
|
Linear Regression 线性回归 |
线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。 |
|
Collaborative Filtering 协同过滤 |
基于用户的协同过滤算法: 基于一个这样的假设“跟你喜好相似的人喜欢的东西你也很有可能喜欢。”所以基于用户的协同过滤主要的任务就是找出用户的最近邻居,从而根据最近邻居的喜好做出未知项的评分预测。 |
|
Generalized Linear Models 广义线性模型 |
GLM是一般线性模型的直接推广,使因变量的总体均值通过一个非线性的连接函数(link function)而依赖于线性预测值,许多应用广泛的统计模型均属于广义线性模型。 |
|
Decision Tree 决策树(随机森林决策树) |
决策树是一个树形结构的预测模型,代表的是对象属性与对象值之间的一种映射关系。 |
现有的并行化统计算法列表:
|
算法 |
描述 |
|
Min |
计算某列数据的最小值. |
|
Max |
计算某列数据的最大值. |
|
Mean |
计算某列数据的平均值 |
|
Variance |
计算某列数据的方差 |
|
MinMax Normalization |
归一化方法是一种简化计算的方式,通过将原始数据转换到某个范围内如(0,1),可以避免不同指标因取值范围的不同,对结果造成的偏差。 |
|
ZNormalization |
将输入数据按照Z-Score进行归一化. |
|
Median |
计算某列数据的中位数 |
|
Percentile |
用来计算处于某个分位数上的值,如给定参数0.5,则返回中位数 |
|
Boxplot |
箱线图是一种描述数据分布的统计图,利用它可以从视觉的角度来观察变量值的分布情况。箱线图主要表示变量值的中位数、四分之一位数、四分之三位数等统计量。 |
|
Cardinality |
统计某列数据中每个值的频数 |
|
Histogram |
直方图(Histogram)又称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 |
|
Binning |
通过指定区间数,可以返回对数据进行均匀分布后的每个区间的取值。 |
TDH平台集成了R语言,支持通过R语言进行统计分析、数据挖掘、机器学习,并运行在分布式计算框架中,利用R丰富的统计分析库和丰富的图形可视化方法来分析Hadoop中存储的数据。用户通过R可以分析从HDFS中读出的数据,以及SQL查询返回结果数据。下面是可视化分析结果的示例:
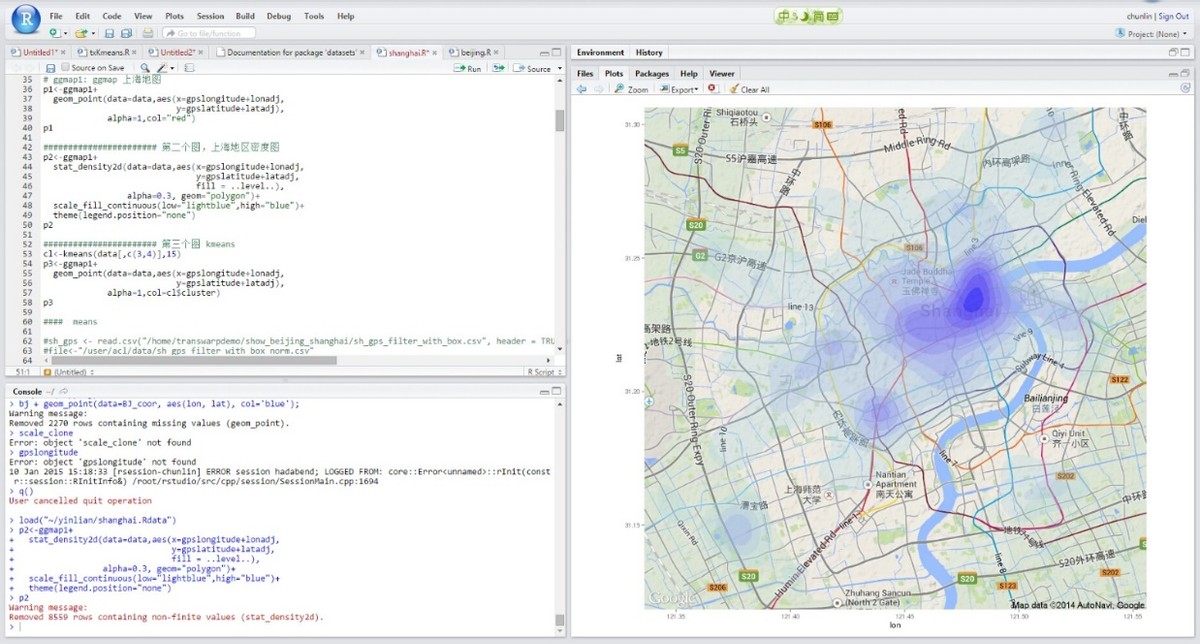
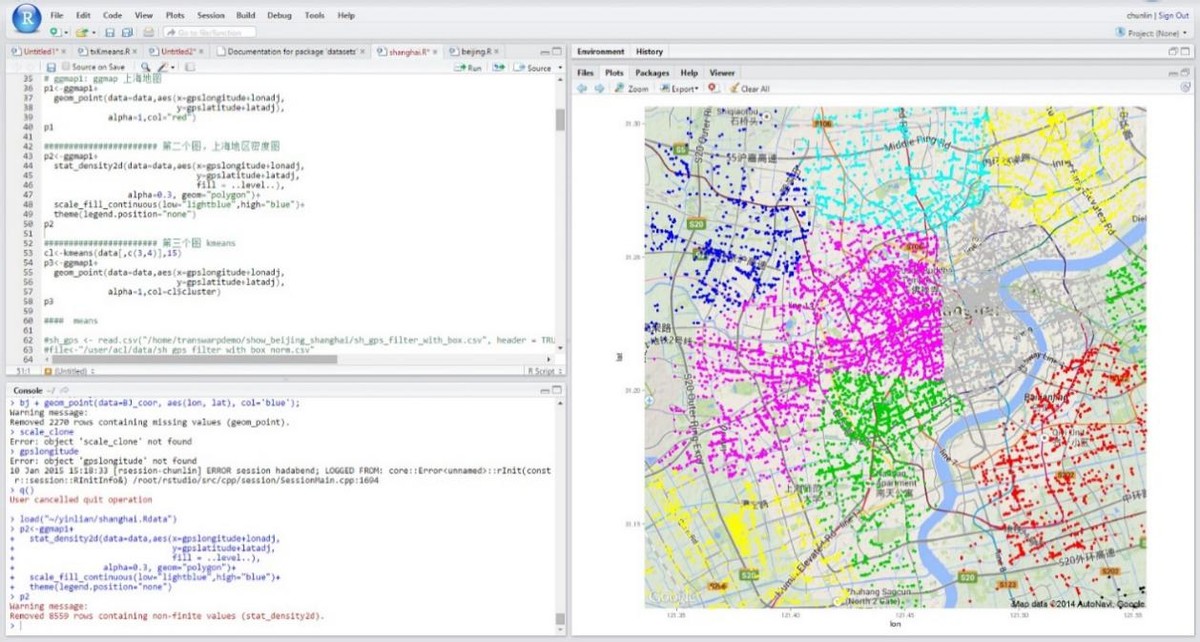
上图是用kmeans算法对商户根据地理位置进行聚类,并绘制聚类效果图。
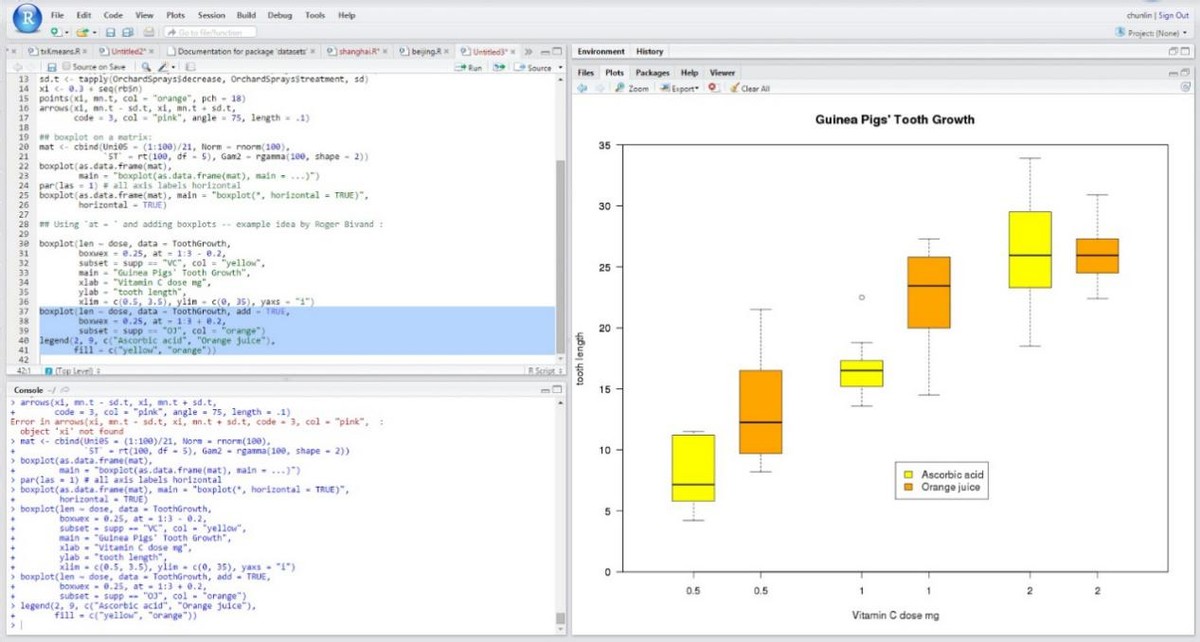
Rstudio中绘制箱线图,展示数据的分布信息。
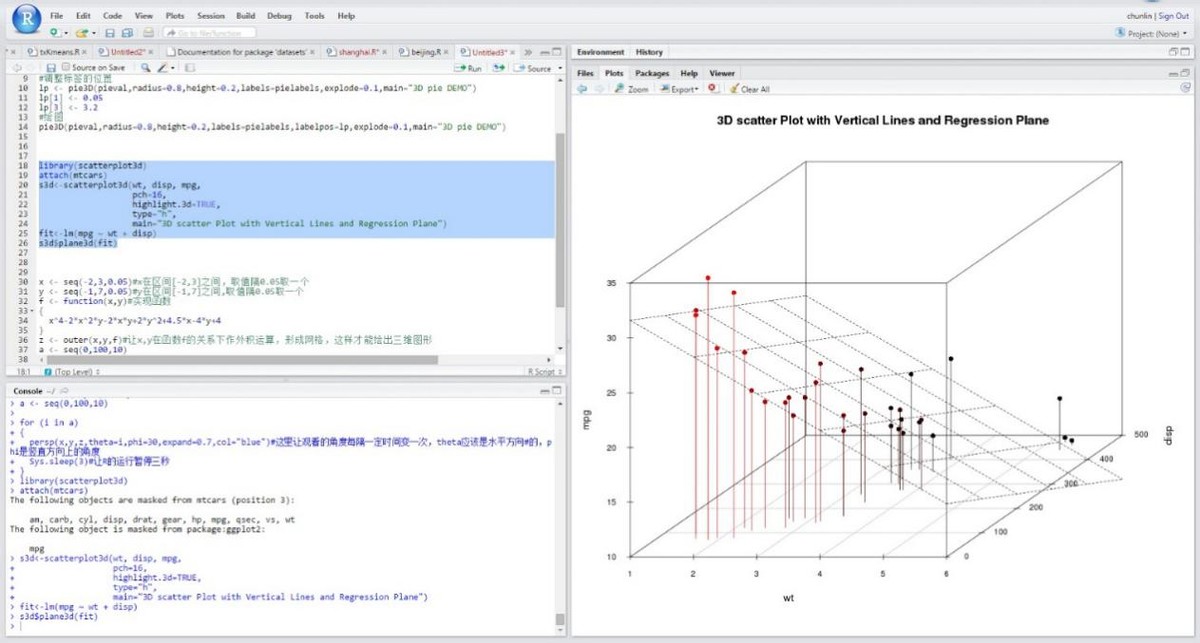
Rstudio 3D绘制散点,并拟合回归平面。
流式机器学习
TDH平台中把Discover组件与Slipstream组件进行很好的融合,支持把离线挖掘好的算法模型用于实时的数据流中,当实时的数据流经过已嵌入的算法模型可以实时的把符合算法逻辑的结果过滤出来,以实现准实时的数据挖掘和流式机器学习任务,输出结果支持写入目标结果表、下游消息队列等灵活方式。
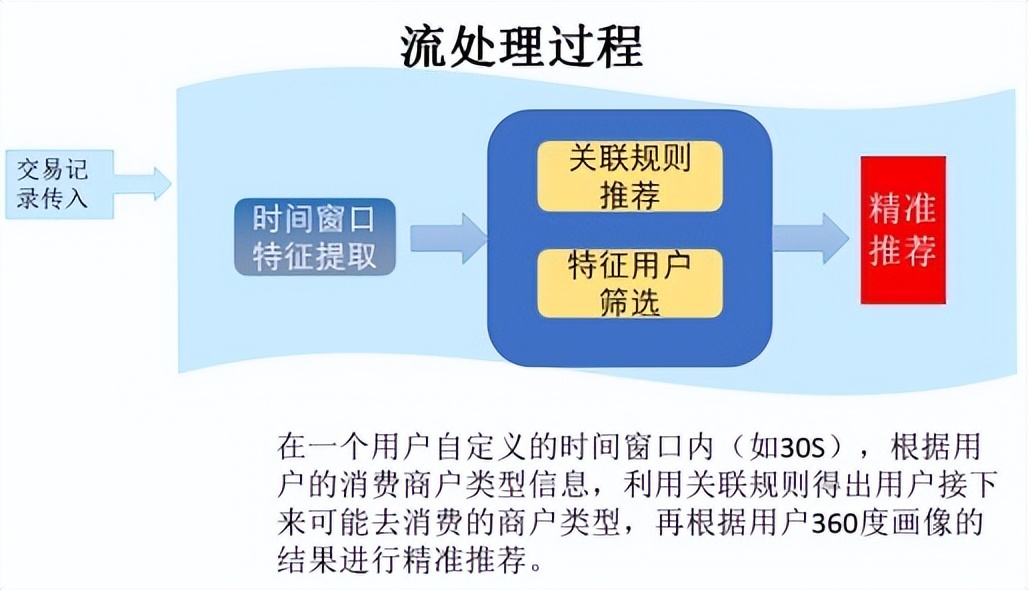
Transwarp Slipstream支持从高速产生数据的物联网介入流计算引擎,在实时计算过程中进行数据挖掘,包括统计和机器学习等多种算法,从中挖掘出有价值的信息及时报警或者进一步分析。在进一步分析过程中,Transwarp Slipstream支持将实时数据流转成列式存储存放到Holodesk上,可以利用Transwarp Inceptor使用SQL对准实时的数据进行Ad-hoc分析以及利用R进行数据挖掘等。
自定义数据挖掘算法
当系统自带的库函数、库算法无法满足开发需求时,开发人员可以自主开发算法并加载到Discover中使用。
目前,RStudio支持以rJava的形式,在RStudio中调用由用户自主开发的Java类和方法,用户需要执行下面几步基于rJava的自主开发流程:
1) 首先使用Intellij IDEA建立工程编写用户需要的scala或JAVA代码;
2) 将编译调试通过的代码编译打包成 .jar 文件;
3) 通过Discover Rstudio平台上的“upload”交互方式将JAR包上传至集群;
4) 基于Discover R函数txAddJar和txGrant实现对Jar包中用户自主开发的类和方法进行调用及共享。
自主开发主要依赖rJava工具,Discover RStudio包含该包中的所有函数。rJava实现了在R环境中创建Java对象,调用Java方法等功能。
交互接口
数据挖掘平台提供R语言、Python、API交互接口,方便开发人员选用不同方式进行数据挖掘。
Transwarp Discover同时支持使用R语言、Java语言和图形化接口进行数据挖掘开发,同时在产品中内嵌了一个R Studio的R语言开发环境,数据分析师可以使用R语言或者Java语言调用内置的算法进行分析,Transwarp Discover集成了大量分布式算法,包括分类、聚类、回归、时序分析、主成分分析、关联、推荐、深度学习等,这些算法都是基于spark分布式计算引擎,算法的效率和精度在大数据量都具有明显的优势,可以达到亿级数据分类、聚类分析小时级的性能。
Discover可以被R语言和Python语言调用。
分布式深度学习框架
TDH提供了深度学习与交互式探索平台Sophon,它是除了Discover之外的另一个机器学习产品。
Sophon的主要特点有:第一,Sophon包含一个交互式的开发IDE——Midas,用户可以在Midas中通过拖拽算子的方式来实现复杂的数据分析工作流程;第二,它内置了100+个挖掘算子,基本涵盖了常用的挖掘算法;第三,它很好的整合了深度学习的框架TensorFlow和MxNet,方便用户在图形化平台上构建神经网络模型并灵活调参。
深度学习框架
Sophon的框架算层中拥有TensorFlow和MXNet两个开源深度学习框架。这些为平台的深度学习提供了坚实基础。TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。MXNet是一款设计为效率和灵活性的深度学习框架。它允许你混合符号编程和命令式编程,从而最大限度提高效率和生产力。在其核心是一个动态的依赖调度,它能够自动并行符号和命令的操作。
2015年11月9日谷歌开源了人工智能学习系统TensorFlow,同时成为2015年最受关注的开源项目之一。其命名来源于本身的运行原理。TensorFlow是一个使用数据流图(data flow graphs)技术来进行数值计算的开源软件库。数据流图中的节点,代表数值运算;节点节点之间的边,代表多维数据(tensors)之间的某种联系。你可以在多种设备(含有CPU或GPU)上通过简单的API调用来使用该系统的功能。
数据流图是描述有向图中的数值计算过程。有向图中的节点通常代表数*运学**算,但也可以表示数据的输入、输出和读写等操作;有向图中的边表示节点之间的某种联系,它负责传输多维数据(Tensors)。图中这些tensors的flow也就是TensorFlow的命名来源。
节点可以被分配到多个计算设备上,可以异步和并行地执行操作。因为是有向图,所以只有等到之前的入度节点们的计算状态完成后,当前节点才能执行操作。
TensorFlow的特性有:
- 灵活性
TensorFlow不是一个严格的神经网络工具包,只要你可以使用数据流图来描述你的计算过程,你可以使用TensorFlow做任何事情。你还可以方便地根据需要来构建数据流图,用简单的Python语言来实现高层次的功能。
- 可移植性
TensorFlow可以在任意具备CPU或者GPU的设备上运行,你可以专注于实现你的想法,而不用去考虑硬件环境问题,你甚至可以利用Docker技术来实现相关的云服务。
- 提高开发效率
TensorFlow可以提升你所研究的东西产品化的效率,并且可以方便与同行们共享代码。
- 支持语言选项
目前TensorFlow支持Python和C++语言。(但是你可以自己编写喜爱语言的SWIG接口)
常用的深度学习训练模型为数据并行化,即TensorFlow任务采用相同的训练模型在不同的小批量数据集上进行训练,然后在参数服务器上更新模型的共享参数。TensorFlow支持同步训练和异步训练两种模型训练方式。
异步训练即TensorFlow上每个节点上的任务为独立训练方式,不需要执行协调操作,同步训练为TensorFlow上每个节点上的任务需要读入共享参数,执行并行化的梯度计算,然后将所有共享参数进行合并。
MXNet是一款设计为效率和灵活性的深度学习框架。它允许你混合符号编程和命令式编程,从而最大限度提高效率和生产力。在其核心是一个动态的依赖调度,它能够自动并行符号和命令的操作。MXNet的系统架构如下图:
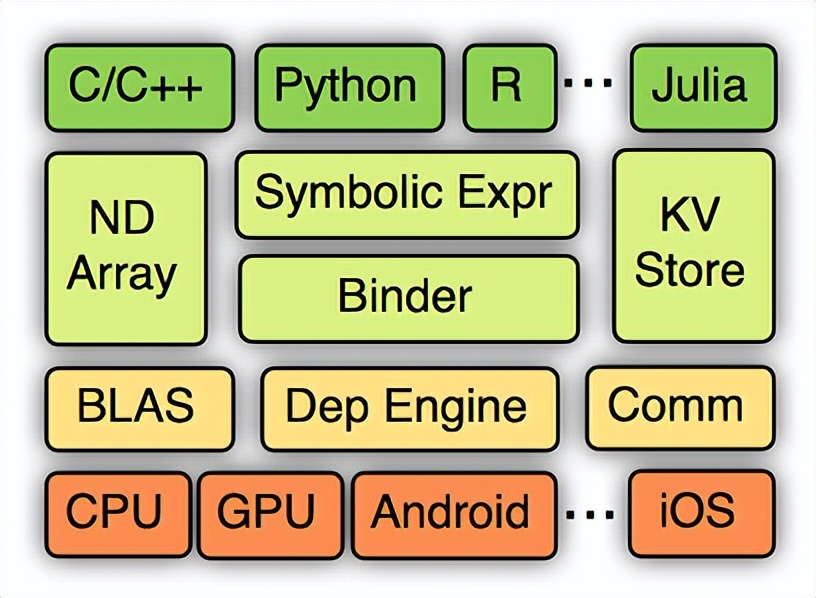
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。
MXNet的设计细节包括:符号执行和自动求导;运行依赖引擎;内存节省。
目前主流的深度学习系统一般采用命令式编程(imperative programming,比如 Torch)或声明式编程(declarative programming,比如 Caffe,theano 和 TensorFlow)两种编程模式中的一种,而 MXNet 尝试将两种模式结合起来,在命令式编程上 MXNet 提供张量运算,而声明式编程中 MXNet 支持符号表达式。用户可以根据需要自由选择,同时,MXNet 支持多种语言的 API 接口,包括 Python、C++(并支持在 Android 和 iOS 上编译)、R、Scala、Julia、Matlab 和 JavaScript。
丰富挖掘算子
TDH提供了深度学习与交互式探索平台Sophon内置了100+个挖掘算子,基本涵盖了常用的挖掘算法。
狭义的算子实际上是指从一个函数空间到另一个函数空间(或它自身)的映射。广义的算子的定义只要把上面的空间推广到一般空间,可以是向量空间。赋范向量空间,内积空间,或更进一步,Banach空间,Hilbert空间都可以。算子还可分为有界的与*界无**的,线性的与非线性的等等类别。
Midas中提供了本地算子和远程算子,用户可以选择进行本地算法体验,也可以选择远程连接进行分布式算法的体验。上百种统计算子和机器学习算子,可以在算子视图的搜索框中搜索所需要的算子名称,快速定位所需算子,然后只需双击该算子或者左键拖拽该算子,就可将需要的算子添加到流程视图中,极大的方便了用户的操作。
自定义算子
Midas支持自定义算子来打通平台内部,用户只需在Midas中添加自定义算子,就可以轻松使用通过Python、Scala在平台中所编写的算法或模型。
支持深广模型
深广模型是一个广度线性模型和深度前馈神经网络模型的联合模型,它结合了两个模型的记忆性和泛化性的特点,对于高维稀疏特征下的大规模回归和分类问题具有非常好的学习记忆和泛化能力。
Sophon中的TensorFlow架构支持深广模型的建立,在使用Sophon建立深广模型时只需要三个步骤:
- 为广度模型部分选择特征:选择要使用的稀疏特征(离散变量one-hot)以及交叉稀疏特征(crossed one-hot);
- 为深度模型部分选择特征:选择连续特征(连续特征需要进行一定的处理,例如标准化和归一化),以及每一个离散变量的Embedding的维度,并设定隐藏层的数量的大小;
- 将上述特征放入深广模型中进行联合训练。
图形化深度神经网络拖拽
神经网络(也称之为人工神经网络,ANN)算法是80年代机器学习界非常流行的算法,神经网络的诞生起源于对大脑工作机理的研究,学习机理是分解与整合,在神经网络中,每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。
近来,机器学习的发展产生了一个新的方向,即“深度学习”,其理念就是传统的神经网络发展到了多隐藏层的情况。多隐层的神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类。
Sophon提供了一款拖拽式图形化界面工具Midas,支持图形化深度神经网络拖拽。
数据挖掘IDE开发工具
RStudio
Discover集成了RStudio Server。Rstudio是R的一种强大而便捷的IDE,提供基于Web的开发环境。同时平台提供的RStudio预加载好了并行化后台以及并行化执行引擎的连接模块,并将R脚本的编写、编译、跟踪执行以及中间变量查看和绘图集于一体,为用户提供了一个强大的R的操作环境。用户除了可以自行编写R的程序脚本、调用开源版本R提供了数千个R的包和函数之外,还可以直接调用TranswarpR实现的并行化机器学习算法库。
Zeppelin
平台支持网页编程工具Zeppelin。用户可以通过R访问HDFS或者Hyperbase中的数据,还支持访问存储在Inceptor分布式内存中的数据,Zeppelin提供了Web版的编程工具,用于做数据分析和可视化,可支持R、Python、Scala和SQL,实现数据采集、数据发现、数据分析、数据可视化和协作,一些基本的图表已经包含在Zeppelin中,任何输出都可以被识别并可视化,Zeppelin具有可视化强、代码量少、模块清晰等优点。对于非开发人员,用户可以通过Midas,以拖拉拽的方式通过DAG图,对相应的数据挖掘算子调整相关参数,即可快速开发出数据挖掘和机器学习应用。在平台中,用户既可以通过R命令行,也可以使用图形化的R Studio、Zeppelin执行R语言程序来访问TDH中的数据,易用性极高。