由于爬虫的出现,导致很多网页都设置了反爬虫机制:
常见的反爬虫机制就是在客户端发出请求的时候,在请求的内容中新增一些内容,而这些内容都是经过“加密的”,每次请求都是不同的,这样就导致了很多传统的爬虫失效。

python
这里小编今天就给大家发一个最新的破解有道翻译反爬虫机制的python代码,你也可以百度,但百度上目前的所有有道翻译的爬虫代码都已经不能用,大家可以自测!
话不多说,我们先看结果,代码在第三幅图
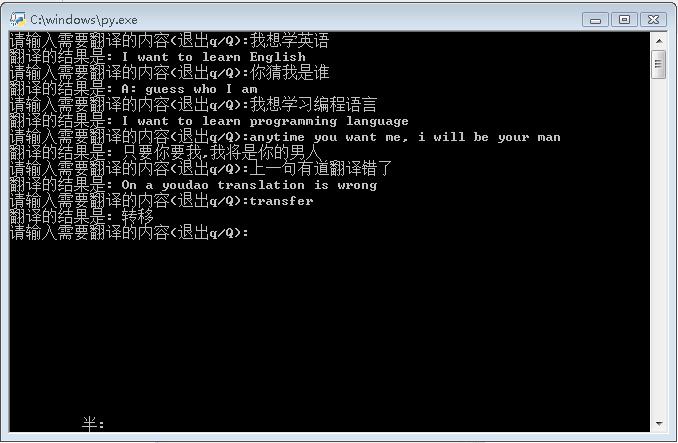
爬虫运行结果
由于头条屏蔽了空格,导致所有代码缩进无法正常显示,所有附带截图帮大家区分代码段

代码段截图
话不多数直接上代:由于有道翻译采用了反爬虫机制,所有破解需要一定时间,不赘述破解过程
from urllib import request,response,parse
from requests import Request
import json
import time
import random
import hashlib
import operator
while True:
content = input(’请输入需要翻译的内容(退出q/Q):’)
if(content != ’Q’ and content != ’q’) :
url = ’http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule’
head = {}
head[’User-Agent’]=’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36]’
data = {}
S = ’fanyideskweb’ #反爬虫机制1
n = content #反爬虫机制2
r = str(int(time.time() * 1000) + random.randint(1, 10)) #反爬虫机制3
D = ’ebSeFb%=XZ%T[KZ)c(sy!’ #反爬虫机制4
sign = hashlib.md5((S + n + r + D).encode(’utf-8’)).hexdigest() #反爬虫机制5
data[’i’] = content
data[’from’] = ’AUTO’
data[’to’] = ’AUTO’
data[’smartresult’] = ’dict’
data[’client’] = ’fanyideskweb’
data[’salt’] = r
data[’sign’] = sign
data[’doctype’] = ’json’
data[’version’] = ’2.1’
data[’keyfrom’] = ’fanyi.web’
data[’action’] = ’FY_BY_CLICKBUTTION’
data[’typoResult’] = ’false’
data = parse.urlencode(data).encode(’utf-8’)
request1 = request.Request(url=url, data=data, method=’POST’)
response1 = request.urlopen(request1)
html=response1.read().decode(’utf-8’)
target = json.loads(html)
result = target[’translateResult’][0][0][’tgt’]
print (’翻译的结果是:’,result)
else:
print(’退出翻译器’)
break
每日更新python经典练习,您的关注是小编最大的动力
