
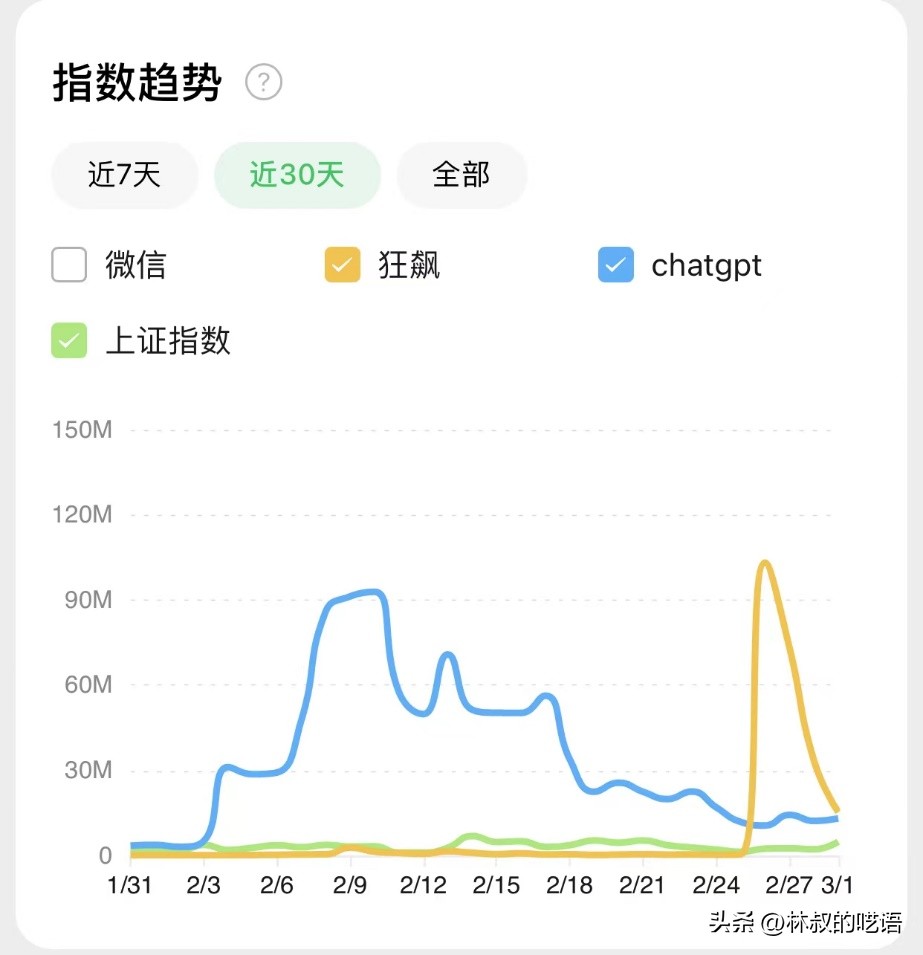
刚刚过去的2月,是最近三年来科技互联网最热闹的时光。从月初到月末,ChatGPT的热度覆盖整月,不但全面碾压了十年如一日的上证指数,遇到《狂飙》这种热播剧也能一较高下。
有人还在质疑用途时,国内商业化早就开始:
动作快的人,卖账号卖方案挣了第一桶金;
稍慢些的人,依然在小程序上添加应用场景,拉群推广;
再晚些的人,还在摸索新的变现途径(对,在下也是其中之一);
就算完全没用过的人,大概率在刷短视频时看到各路博主神情夸张的介绍,替代就业岗位的预期,能让人或多或少的产生焦虑。
直到现在,坦率的说,部署机器人依然是提高群活跃度和催化群裂变最简单直接的方式。如果不是亲自试过,我是不会相信一个群,能在短短几小时里增加至几百人,况且其中大多数都互不相识,还能有着极高的群聊天频率与活跃度。
作为一个辅助工具,ChatGPT有着许多使用场景可以进一步探索。
但显然,过于好用的工具出现,一定会影响到某些利益。
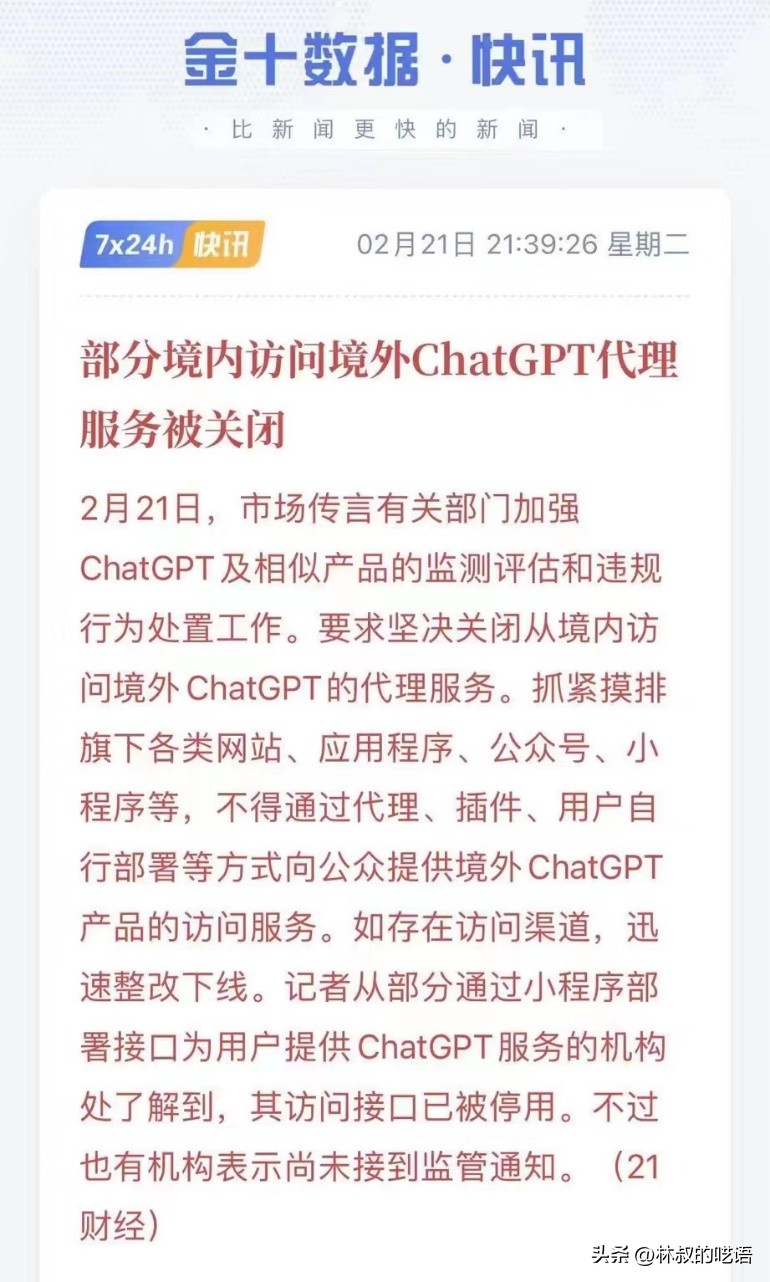
先是有传言监管要求关闭访问OpenAI的服务,国内服务商整改下线。消息传的神乎其神,一度各大财经媒体都在转发。然而几天之后并没有更进一步的信息出现,腾讯对GPT机器人的封禁也是以“使用第三方插件,外挂”的理由判定违规。
同一时间,还发生了些有意思的事。
一些媒体在英语环境下,向ChatGPT提问有关敏感地区的问题。然后用回答结果质疑人工智能表面先进,实则特洛伊木马另有所图。
这些问题确实存在,我不想过多解读,单单只想提一个问题:为什么要在英语环境下提问,这跟打着灯笼进厕所,然后说厕所里有屎有何区别?为了博眼球明知故问,意义何在?
在解释语言环境的问题之前,我们先简单了解一下语言模型的训练方式。
但凡认真了解过ChatGPT的人,都知道它是语言模型训练出来的。GPT3使用了1750亿个参数的语言模型,原理就像它自己说的一样,获取语料来源,拆解成最小可识别单元,然后用预测模仿人类语言。
为了方便各位理解,我画了一张平面图来解释训练原理。恕我代码能力有限,不一定完全正确:
先把语料切分,成最短的字词句组合。从二维平面看,形成了横向是篇幅,纵向是字词句可选项的二维坐标系,语料等待算法拟合。
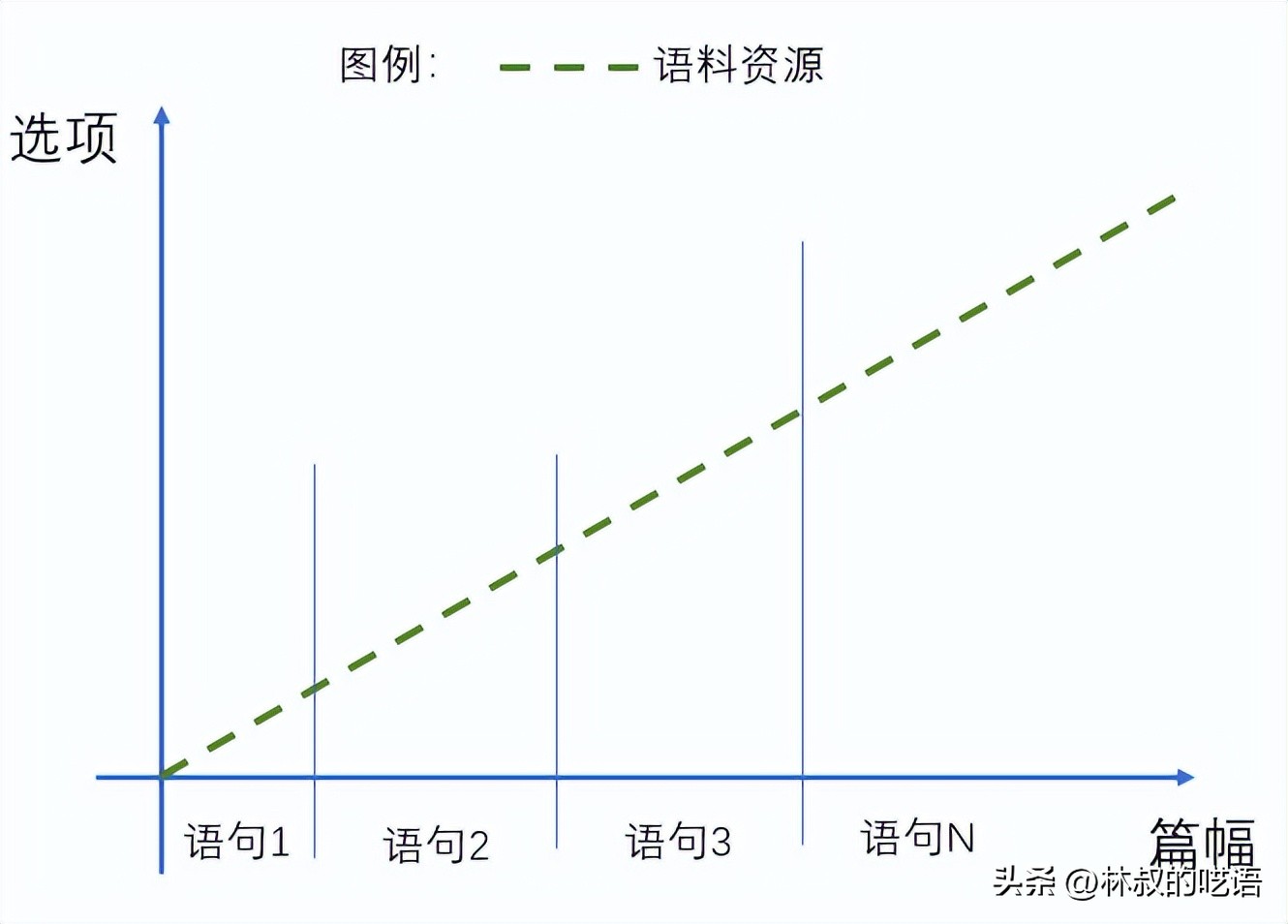
初始状态
开始拟合时,算法的目标很明确,就是找出那个能近乎一字不差复写出语料的算法分支。为此,从给定起始词开始,在字库中穷举所有已知的文字选项,直到拟合原文,然后进入下一段语句拟合。
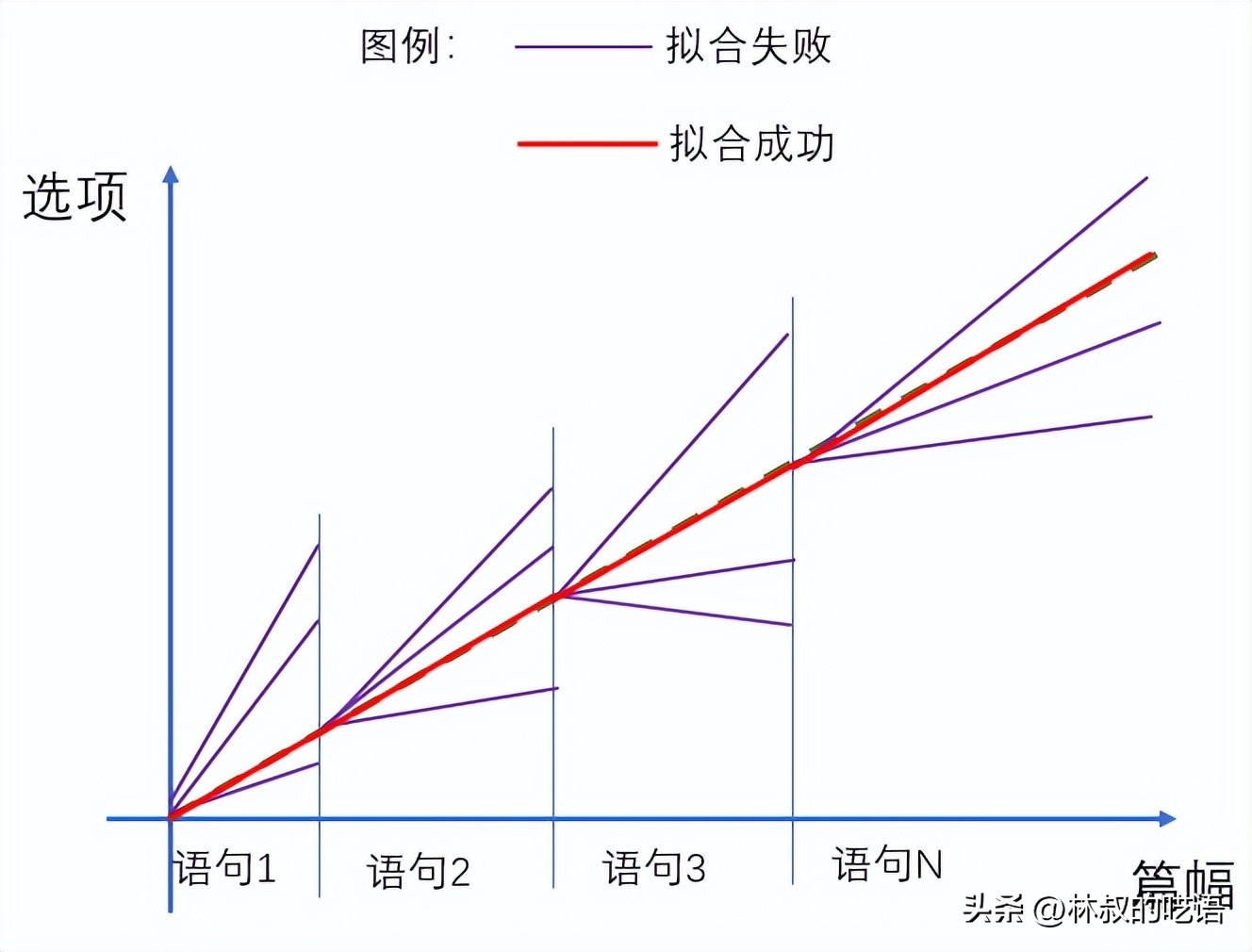
拟合算法
这过程用一个词可以形容,就是“大力飞砖”。
每一段拟合,像极了支撑人类百万年进化的优胜劣汰法则,成功拟合的算法得以保留,失败的被无情抛弃,周而复始。
只不过机器不用登上几百万年,只要钱足够,几年就能完成这段光荣进化。
如果从三维来看,拟合可选项会更多,情况更复杂,但多轮拟合完成之后,剩下的算法选项大大减少(相对算力而言),如果再加上人工标注的加持,训练速度会几何级增长。
也就是说,以后的GPT语言模型会更智能,更接近于人的交流和问答方式。
回到前面的话题,你用什么语言和GPT模型交流,它自然会用相应的数据库回复你(当然你也可以指定回复语言或者要求翻译)。换句话说,中文问答用中文语料训练的数据库,英文问答同样如此。
文字解释可能比较长,这段不如看下OpenAI Fine-tuning API微调GPT-3模型的代码示例,代码的目标是训练一个能够回答关于美国总统的问题的模型。代码如下:
```python
# 导入OpenAI库
import openai
# 设置API密钥
openai.api_key = "sk-xxxxxxxxxxxxxxxxxxxxxxx"
# 准备训练数据集,这里只用了一小部分数据作为示例
train_data = [
{
"input": "Who is the president of the United States?",
"output": "Joe Biden"
},
{
"input": "Who was the president before Joe Biden?",
"output": "Donald Trump"
},
{
"input": "How many presidents have there been in total?",
"output": "46"
}
]
# 训练一个新的微调模型,指定模型名称、训练数据、基础模型和训练参数
fine_tune_result = openai.FineTune.create(
model="davinci",
train_data=train_data,
fine_tune_id="president-qa",
max_examples=10,
n_epochs=3,
)
# 使用新的微调模型进行预测,输入一个问题并获取输出
response = openai.Completion.create(
model="president-qa:1",
prompt="Who was the first president of the United States?",
)
# 打印输出结果
print(response["choices"][0]["text"])
```
是的,这也是新必应自己给出的代码示例。
重点就在数据集input和output那里。模型训练时数据库输入了什么,大概率被调用时就会输出什么,直到数据库更新,或者被新的语言模型替代,再或者遇到它也不知道的问题张冠李戴胡乱作答。
英语环境最近几年对敏感地区什么态度,各位媒体大人难道不清楚,你们不去英语环境下为国发帖呐喊,最起码多增加些被训练模型抓取的权重,拿着小学生都知道的结果在国内危言耸听,吓唬谁呢?
难不成又想复制一遍游戏的精神*片鸦**指控吗?

昨天精神*片鸦**,今日科技行业
你看,怎么我用中文提问,新必应的回答就很合情合理啊,完全没有任何瑕疵,甚至都不会做出主观评价。
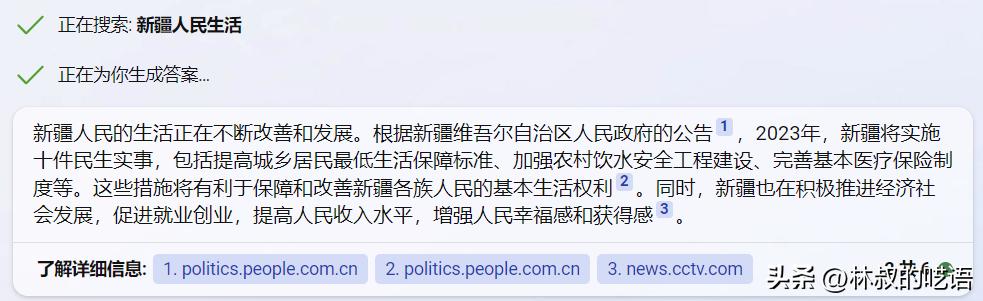
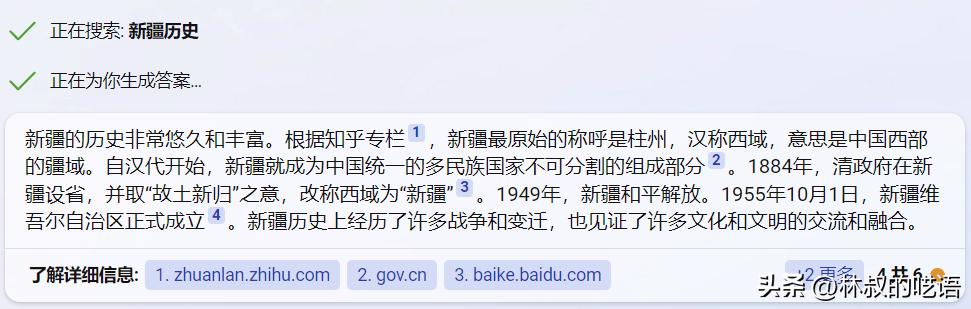

这回答比百度靠谱多了。
原本这篇文章到此就差不多了,就在结尾时突然看到两条消息。
第一条是国内的,知乎创始人周源建议ChatGPT设定年龄限制。

好家伙,真的好家伙,您是真的要复制游戏行业的未成年人防沉迷?问题是国内游戏容易管,OpenAI你能让他网站接入防沉迷系统,每次登陆时校验一下吗?
再说了,你自家app一没有防沉迷提示,二每天晚上八点半都在直播讨论ChatGPT引流,首页大屏展示生怕人不知道。
做人能不能不要太双标啊,难不成你也怕人工智能抢了你家饭碗?(貌似有这可能)

知乎热榜醒目
第二条是OpenAI的,又有大动作。
就是放在最前面的那张图,简单来说OpenAI开放了应用嵌入API接口,一个账号能开更多授权key,更便宜的流量价格,以及一个有可能威胁到科大讯飞的语音助手。
这些内容展开来都很有意思,咱们暂且留下话题,下一篇展开来,细细讲。
这大概是今年可能性最多的创业机会,宛如新一*大轮**航海时代降临一样,令人激动不已。
弱小和无知不是生存的障碍,傲慢才是。当一些人还拿着GPT3的愚笨说事,更快更智能的GPT3.5已经来了。
你当然可以选择捂住耳朵,用那些堂而皇之的合规,堂而皇之的流程做借口熟视无睹,当有一天时代抛弃你时,根本不会征求你的意见。
没人可以挡住OpenAI,也没人可以禁的掉ChatGPT。