1 概述
平常大家的业务如果受网络抖动影响到了而怪罪于运维哥的话,运维哥先给大家陪个不是
我们认了

并且也一直在想方案来改进网络质量和保障业务高可用。
不过,逢年过节的,心里也还是会偷偷在给网络君烧香祈祷:天冷了,别抖
然而,网络抽风问题为什么很困扰运维人员呢,我们从友好的“旁观者”角度来分析下。
有个概率问题,“0故障”基本是不可能的,一般机房都说可以达到99.99%的可用性,也就是常说的4个9,一年有52.6分钟的故障是可接受的。但是面对10个机房的4个9的SLA的时候,就是这子:

到了运维手上,就剩下只有3个9了也就是8.76个小时故障是“可接受”的。

怎么可能允许8个多小时故障,我们又不是gov网站,所以自然就是被发泄的对象了。
另外就是我们用户群体太大了,可以拿韩国做个很直观的对比。
韩国的国内网络是全球最快最厉害的,其国土面积大概为中国的一百分之一,大概是浙江省的大小,这相比于大中国的南北网络,这就是个大局域网呀。

数据包经过的网络设备节点比我们少太多,而且距离也短,比如才经过两个路由器,网络还没来得及抽风的时候数据已经传输完成了。
然而,从稍微专业点的角度又可以分析出来,网络抖动造成的业务影响,别甩,就是你的问题,虽然可大可小,但难道是行政或者财务部门的问题?
2 那些年我们曾经的网络故障
稍微客观总结下我们平常可能碰到的网络问题,可以看出来一些端倪来。
1. 人为故障
人为故障就是那种低级的操作失误导致网络卡顿,或者是网络架构不合理导致网络异常,或者是因为带宽限制不合理导致带宽跑满了,这些我们都可以归罪于人为的故障。罪过,不过经过以前的教训,这种概率变得很小了。
2. 硬件故障
硬件故障就是中锦鲤了,比如交换机莫名其妙地重启了,所以线上一般要用好一点的交换机,可以大大降低这个故障类型的可能性。
3. 第三方组件故障
用户上网严重依赖DNS服务一旦故障,区域性影响面会非常大,而且很容易也被认为是服务器网络问题。
4. 运营商网络故障
运营商网络故障现象就包罗万象了,是运维很冤很烦恼的问题,这虽不是运维能够掌握的,虽然谁也掌握不了,但这好像也可以说是运维部门的问题,你说机房是谁选的。。。

2.1 网络升级抖动
业务经过的网络设备众多和用户分布广泛会导致互联网公司受局部网络影响的机率非常大。
网络升级造成抖动的情况比我们想的多得多,我们能直接感受到的可能不多,如果运营商网络小割接或者升级之类的,影响可能是闪断或者期间延迟偶尔增大,对大部分客户来说可以说是在挠痒痒的痛,如果说要告知全部影响到的客户的话不太现实,全国各地的的线路可能都经过了这一跳。
单单从腾讯已发出的网络维护通知就可以看到平常一个公司经历过的网络维护是有多频繁了,几乎是每个礼拜好几次:
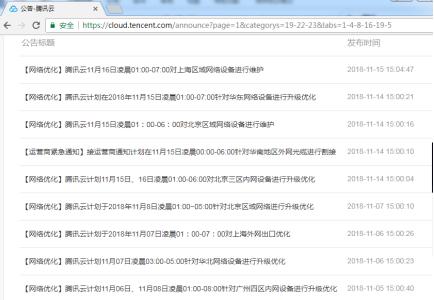
而且这个是公开在站点公告上面的,那些私下里通知客户的就更是数不胜数了。
不过各种各样的割接很多只是延迟丢包一下,或者只是可能会造成影响,先给用户一点心理提醒。
有些是网络闪断,虽然有些莫名奇妙的闪断对普通上网用户是无害无感知的,所以有些小运营商需要切换路由进行闪断的操作有时候也是懒得通知了,但是玩游戏的时候,或者ssh操作服务器更新的时候,这种伤害比丢包严重多了,这个时候网络丢包还可以接受的,忍一下就好了,但是如果闪断的话,就像在编辑文件没保存,遭遇突然断电的情况一样,满满的恨。
2.2 光纤被挖断
说起光纤被挖断,近年来支付宝的那次故障最闻名,影响约3个小时:
5月27日下午5点左右,支付宝出现全国范围的系统瘫痪。淘宝购物、第三方网站付款、支付宝钱包各项功能全部无法使用。

相比硬件故障,网络故障没那么大的影响,最起码支付宝里面的钱还在的,不用那么慌。
这种网络故障其实很常态,但是这次闹得比较大,估计大家都在趁着机会发泄、调侃发泄一下“支付宝干不过蓝翔”吧。
关于异地双活、灾备,大公司一般有,但是真的用起来的话很可能有后遗症和未知的问题,最怕数据紊乱,所以如果忍一下就恢复了,大家就先忍忍吧。

我们基建大国,何止挖断光纤,还有电缆。
特别是广东这里,经常各种新闻,深圳供电局怒怼地铁公司:地铁野蛮施工,三天两起挖断7根,还有建筑工地直接上凿穿地铁的,各种施工故障都屡见不鲜了,不过我们这种民用的光纤被挖断在他们面前是大巫见小巫了,不过有点神秘的是“国防光缆被挖断”会怎么样,听说是巨额罚款然后蹲监狱,震慑性非常大,牛。
还有就是光纤被人为剪断,这种在城中村网络的竞争中比较常见,如果说在大型的网络中也出现这个情况,可能比较丢脸,一般网络故障不会出现这个解释,但是私下了解的话是存在的。
我们办公网也经历够光纤被挖断的情况,而且很悲催,就在办公楼不远,主备两条光纤线路还没正式分开就被挖断了,两根同时断,认为可能性很低的糟糕情况就直接发生在身边。
2.3 同机房被DDOS
机房一般都有一些硬防,可以抵抗一些攻击流量,再大一点的话就需要依赖上层运营商进行IP封禁,这个过程中其他客户也容易受到一些连累,所以我们选机房一定需要选优质机房,不能和那种*服私**的客户做邻居。
而且不要以为每个机房都是独立出口给你,成本很大。最多就是一些优质客户独立开来一个额外的出口。
2.4 运营商网络互联
我们的公告中经常会出现“大网”两个字,大网故障就是说的骨干网有问题,故障一般是某个运营商故障、某个省份故障、运营商之间互联故障,一般不是完全不通,而是拥塞导致延迟大和丢包的情况。
大家都知道我们大陆网络运营商一般是电信、联通、移动三家,另外还有教育网和一些小众的地域性运营商。但应该很少听过“跨网结算”这个词,他们不是一家人,他们有很大的利益竞争关系,比如我的用户主要是移动用户,移动运营商就希望你能在他们这里放置一个CDN节点(移动免费提供)来进行缓存和资源直接提供,而不是任由你的移动用户每次都去电信*载下**资源,否则他们需要给电信一大笔带宽使用费。

可以猜到南方电信网络到北方联通网络其实可以很快的,协作也可以很顺畅的,但是直接很快的话会影响到自己的市场份额,跟自己的钱很相关了。
2.5 第三方组件
我们上网严重依赖DNS服务,如果DNS不稳定了,其实网络是通的,但是我们打不开网页,也就非常影响到业务了,是很严重的故障。

常见的DNS方面的故障是DNS服务商故障和省DNS服务器故障。
DNS服务商故障,最出名的是2009年DNSPOD故障导致全国大面积站点提供不了解析,后续也经常会碰到这个故障,不过dnspod的防护能力强大了几个量级,让用户受到的影响小了些。
然后就是用户的dns服务故障,大多数用户直接用到的DNS是运营商直接分配的dns,可能是他们自己搭建的DNS加了些缓存功能之类的,这种自建的不怎么稳定。也可能是省DNS,故障率稍微低一点,还有就是各种公共DNS比如114.114.114.114这些一般比较稳定。
dns服务器故障对办公网的影响就小了很多,因为办公网可以随时针对上层dns做灵活调整。对游戏小白用户来说也是个麻烦事,特别是手机端用户更是麻烦。
还有可能是第三方云的故障,第三方云说的很强大,但是如果大家纯依赖他的话,那是不那么靠谱的,因为他也是肉做的,也有各种机率导致各种问题,而且有把鸡蛋放一个篮子的风险。
2.6 对症下药
虽然上面故障看起来是很难避免,但是还是有些办法可以减小业务负面影响的,比如机房选型可以在预算充足下,选硬件资源好一点的,网络质量、带宽预警功能要做好,在有影响征兆的时候就及时做出处理。
然后也要敦促机房不要把出口网络放在容易被攻击的公司一起,做到独立出口,或者“优质公司出口”。
至于别的优化就从业务高可用方面来着手了,高可用做的好,可以做到影响最小、业务最快恢复,比如BGP中转,Anycast IP,关键业务机房互备等,别看以前电信联通双线IP比较山寨,但是也是个很重要的线路互备,放在现在专线的情况下双BGP IP仍然可行。
另外就是根据业务情况,可以依赖公有云做出一些紧急的备用方案了。
3 网络公告分析
至于出故障了要怎么发公告来告知外部的业务方呢?
我们来分析一下腾讯的一则运维方面的公告,我们会发现这称得上是教科书式地网络故障公告,虽然有点虚,但比较到位,值得大家参考。
7月24日,我们监测到腾讯云广州区域部分用户出现资源访问失败、控制台登录异常等情况。经排查,确定该故障是因腾讯云广州一区的主备两条运营商网络链路同时中断所导致。我们随即与运营商紧急进行联合修复,该故障已于当天上午11:06得到解决,所有业务恢复正常。
虽然此次故障是因运营商不可抗中断所致,但我们深知故障在客观上给相应区域的用户业务带来了不良影响,这在一定程度上也辜负了这些用户对我们的长期信任。我们对此表示最诚恳的歉意。
从技术角度分析,双线网络同时故障属于小概率事件,但遗憾的是这次我们的主备线路却遭遇了同时中断的情况。用户业务无小事,我们正在重新梳理网络架构,引入更多维度的容灾机制,力争将故障隐患降到最低。
第一段, 首先强调我们监控到了网络故障,运维人员一定要监控到故障,否则你的过错就很明显了。然后定位到了网络故障是主备同时中断导致,网络已经做了主备容灾,已经做的比较到位了。然后就是出故障当然是赶快解决,现在所有业务已经恢复正常,顺利恢复。
第二段, 这次其实不是我们的问题,问题点是运营商那里,但是确实造成了影响,我们还是需要背锅的,我们道歉。
第三段, 其实客观上来说,这次不属于常规的故障,大家真的要多多包涵,不过我们也有专业精神,会继续做好更厉害的容灾机制,为你们造福。
字里行间透露着一种苦衷,这锅我们背,但是客户你们真的需要理解我们,我们做的很到位了,碰到这种小概率事件是倒了八辈子霉的。

还有就是支付宝因光纤被挖断而断网事件道歉
支付宝官方发布声明,对支付宝因光纤被挖断而断网事件道歉。支付宝表示,光缆被挖断可能并不能完全杜绝,但对于支付宝而言,会继续推进技术的升级改造,继续完善异地多活的系统架构。未来,即使再次出现光缆被挖断等意外情况,进行异地切换时,也尽量做到让用户最小感知甚至无感知。
歉意肯定是有的,这个需要大度一些,然后就是谦虚一点地表示会继续进行架构升级,“尽量”做到让用户最小感知甚至无感知。这也是运维方架构师们需要学习的。
4 结语
扯了那么多,网络出问题了业务方肯定是找运维,这个是共识,必须的,但这个找不应该停留在单纯地找麻烦,而是找运维沟通解决或者缓解网络问题导致的影响,如果单纯的来找运维骂人那就估计有点不合适了,除非运维还不知道网络出问题了。
作为运维方,如果没监控到网络故障或者认为造成的,那就是活该欠揍了,如果是客观原因造成的,也不能逃避,应该大度负起责任来,监督敦促把问题解决好的同时需要想办法在成本允许和研发人员配合的情况下进行架构升级,用技术的力量来让用户最小化感知。