这是一个新的产研团队、新研发员工加入我们的技术体系所应遵循的技术流程规范、工具、原则合集,也是我们花费了昂贵学费换来的……经验教训。
1.前言
这是一个雄心勃勃、拥有强大技术传承和宝贵技术财富的宝藏团队,我们曾经:
- 2011年组建团队,当年成为中国团购市场和本地团购市场双料第一
- 2012年推行 RCA 注1 报告制度
- 2013年从 JobCenter 注2 、 NotifyServer 注3 和 IDCenter 注4 开始起步,量身定制自己的通用中间件
- 2014年开始开发自己的大数据技术体系
- 2015年所有商业应用迁入 Docker 容器集群
- 2016年研发协作三剑客 CloudEngine 注5 + iDB 注6 + SimpleWay 注7 横空出世,至此我们完成了“云原生= DevOps 注8 + 持续交付 + 微服务 +容器化”的改造
- 2018年社餐和团餐业务均已接入 异地双活 注9 体系
- 2017年至2019年历经整整三年久久为功的不懈努力,大数据平台“数芯”日臻完善,已经基本覆盖了大数据六大体系:数据采集迁移,开发协作调度,数据可视化,数据开放共享,平台运维管控和数据资产管理
- 2019年 大中台 注10 技术体系如期收官
与业务铁军一路并肩走来,秉持着“平凡人可为非凡事”的信念,我们创造了无数辉煌:
- 带领团队从千团大战中成功突围,行业内唯一一个在正面战场击败过美团的团队(2011、2012年团购业务市场份额超过美团)
- 带领团队历经5年厮杀成为中国第一家O2O行业纳斯达克上市公司
- 培养出成熟的电商技术团队,经历过多次O2O电商大促,自主建设了异地双活体系,日活1000+万笔交易
- 量身定制了本地生活服务所需的大中台支撑体系,集团名下各个公司各条业务线所有线上线下业务均已流程化、电子化、数字化
- O2O业务最高时覆盖全国123个城市,产品覆盖40万家线下门店使用
我们拥有高执行力的团队基因,具有超强的多业务线齐头并进能力:
- 启动某行业的信息化业务,仅一年多的时间,峰值周日均移动交易笔数 782万笔/日
- 某支付营销产品正式上线,仅仅8个月后,就交出了漂亮的答卷:活跃门店5万家,峰值周日均交易笔数450万笔/日
为什么我们如此优秀?总结起来大致有三条:
一,战役文化:有仗打仗,没仗造仗
二,数据驱动:总部为业务铁军提供数据、工具、策略和打法,实时调度
三,大中台体系:快速支撑新业务,技术支撑体系为交易保驾护航
经过十年积淀,我们形成了一系列流程、制度和原则,打造了完整的技术支撑体系和大数据中台体系,下面我将逐一介绍。
注1:Root cause analysis (RCA) is a method of problem solving that triesto identify the root causes of faults or problems that cause operating events.我们还进一步定义了RCA报告的标准格式。
注2:JobCenter,我们2013年自研的定时任务调度与管理平台,2015年起支持任务执行容器化。
注3:NotifyServer,2013年自研的异步消息可靠通知管理平台。
注4:IDCenter,一个内部各个中间件能统一使用的用户认证和权限管理中心,中间件门户。
注5:CloudEngine(简称CE),2016年开始自研的研发协作平台。
注6:iDB,2015年自研的数据库自动化运维平台。CE出现后,打通了CE与iDB的流程。
注7:SimpleWay(简称SW),2016年开始自研的运维自动化平台。CE出现后,打通了CE、iDB与SW的流程,前后贯通,一站式管理线下线上环境,透明管理混合云。
注8:DevOps,一种思想和工作模式,提倡开发和运维协同工作,以实现快速部署和快速响应。工信部软件司把它翻译为“研发运营一体化”。
注9:异地双活,指在生产环境全网灵活地在多个异地机房之间调度客户和用户,实现了自由扩容和多机房容灾的目标。
注10:大中台,业界定义不一,具体到我司,定义是将我司在本地生活服务领域苦心经营多年获得的核心能力随着业务不断发展、业务线不断增多以数字化形式沉淀到平台,不断地将能力标准化、通用化,形成以流程、服务和数据为中心,构建起数据闭环运转的运营体系,保证我司以及上下游合作伙伴更高效地进行业务探索和创新。
2.流程篇
一般性的流程,各家互联网公司大同小异,我就不再赘述。下面讲到的流程,要么与我们的专有技术体系密不可分,要么不遵守就会出大篓子。
流程大致可分为以下五类:
1.运维类
2.硬件类
3.软件类
4.配置管理类
5.数据类
2.1运维类流程
讲运维流程之前,我们先定义一下线上业务故障和事故的级别:
P0 :核心业务重要功能不可用且大面积影响用户。响应时间:立即
P1 :核心业务重要功能不可用,但影响用户有限,如仅影响内部用户。响应时间:小于15分钟
P2 :核心业务周边功能不可用,持续故障将大面积影响用户体验。响应时间:小于15分钟
P3 :周边业务功能不可用,轻微影响用户体验。响应时间:小于4小时
P4 :周边业务功能不可用,但基本不影响用户正常使用。响应时间:小于6小时
很快我们就会用到这个故障级别。
2.1.1故障处理善后流程
很多研发同学误以为线上出现问题后,有BUG就修BUG,修完就万事大吉了。这是一种非常不负责任的工作习惯,说严重点,这属于有始无终、有头无尾、毫无责任感。BUG虽然不与个人绩效挂钩,但是谁捅的篓子谁负责到底。
修完BUG之后,还有三件事需要做:
1.评估影响范围并纠正
2.撰写RCA报告并通报
3.举一反三防范风险
做完这三件才叫处理完了。
(一)评估影响范围并纠正
线上出现问题后,很有可能会出现几种我们不希望看到的情况:
- 数据库出现脏数据:不仅仅是数据错误,最可怕的是数据不一致;
- 客户 或 用户 注1 的资产被错误处置:比如重复扣款,结算金额算错,支付渠道费率变更错误;
首先,我们必须认认真真地评估事故的影响范围,影响了多少条数据?影响了多少位用户?涉及到多少客户?其次,我们还需要逐一纠正这些错误。
注1:客户和用户的区分为:
面向C(Customer)的时候:未注册用户统一称为“用户”,已注册用户统一称为“会员”;
面向B(Business)的时候:一般来说我们属于B2B2C商业模式,B端商户是我们的客户。
(二)撰写RCA报告并通报
查缺补漏之后, 责任人必须撰写RCA报告,并将报告发送给CTO审阅,最后由CTO向全员通报。

图2.1 《黑匣子思维》
这里我要重点推荐《黑匣子思维》(马修·萨伊德2017年7月出版)这本书,航空业的“黑匣子思维”与一般人思维的根本区别在于:
一般人认为错误是不好的,出于本能会为错误找各种借口。而这套方*论法**会把错误看成进步的契机。犯错的人要改正,没犯错的人也要自省,从而杜绝重复犯错,使整个组织,甚至整个行业都能从中获益。
比如下面三个例子就是把错误变成行业进步的契机:
- 因埃塞俄比亚航空961号的错误而要求救生衣必须出舱后再充气
- 因UPS航空6号班机的错误而要求锂电池必须随身携带
- 因911事件而要求所有的飞机都安装密码驾驶舱门
航空业更愿意正视错误,飞行员们总体上说对自身的失误都抱着公开和坦诚的态度,毕竟一旦出错就有可能身死道消。这个行业里有强势且独立的组织专门负责对空难进行调查,失败不会被当成控诉某一位飞行员的理由,而会被视为能让所有飞行员、航空公司和管理者们学习进步的一次宝贵机会。
所以在日常技术工作中,对于事故处理,我们一向遵从航天二十字诀: 定位准确、机理清楚、可以复现、措施有效、举一反三。我们坚持每错必查、错了又错就整改、每错必写,用身体力行告诉每一个研发员工直面错误、公开技术细节、分享给所有人,长此以往,每一次事故都会变成我们的宝贵财富,成为团队的传承和家底。
RCA报告的标准格式为:
- 背景知识(可选)
- 问题现象
- 影响范围
- 问题原因
- 问题分析过程(可选)
- 解决办法
- 后续处理措施(可选)
- 经验教训
- RCA类型:如代码问题、实施问题、配置问题、设计问题、测试问题等
(三)举一反三防范风险
有时候大家在RCA报告里写的“解决办法”其实只是短期解决办法而已,治标不治本。而作为公司里最认真的、最负责的团队,我们不仅仅需要亡羊补牢,还需要一劳永逸。
第一个例子:Redis双机房数据不一致引发机具收款不能核销红包
某日,机具收款,用户的openIDA和unionID落库华北机房;次日,该用户扫码打开小程序,openID B和unionID落库,触发两个openID帐号合并事件,同时清理Redis缓存,但代码只清理了华北机房缓存,未清理华东机房的,导致华东机房存在脏数据。
对此如何一劳永逸解决问题呢?不能依赖于程序员每一次都记得修改多活机房的每一份数据,需要一个自动化机制。所以对于这种数据量不大(如低于1GB)的Redis端口,可以引入我司 的 Rotter 注2实现跨机房 Redis 实时同步。
注2:Rotter,我们自研的跨机房Redis实时同步管控系统。
2.1.2开源软件定期更新机制流程
我们很多RCA报告总结起来就一个根本原因:开源软件(类库/组件)版本有BUG,被我们撞上了,新版本可能已经修复了这个BUG。所以我总是强调,对于开源软件,最佳实践是 保持版本更新很重要,千万别死在那些早已被修复的BUG上。
所以我们会这么做:
1.定期由运维同学发起检查,与研发同学一起确定哪些升级确有必要,升到哪一个版本
2.在线下环境先升级,观察两周时间,经历几个应用更新周期,由测试同学确认本次升级不影响业务
3.再在线上环境升级,注意一个机房一个机房的升级,别一次性把双活机房都升级了。升一个,观察一天,经历完整的早中晚交易高峰时段,再升另一个
第一个例子:P0级,JDBC驱动的致命缺陷
2015年4月22日(周日)晚间,线上TaskMall工程频繁报警,分析JVM表明在内存使用上确实存在问题,有大量对象不正常堆积。田志全进一步分析堆栈信息发现,系统中有大量的CancelTask定时任务需要执行,分析JDBC源码发现它确实会导致CancelTask对象大量累积,从而引发频繁FullGC。他还发现,MySQL 最新的JDBC驱动已经解决了这个缺陷……
事后在线下复现了这个问题,频繁的大数据查询场景下,mysql-5.1.34驱动的性能远优于 mysql-5.0.7驱动。所以同志们啊,一定要及时升级驱动!千万不要迷信所谓的官方出品,不要长年累月使用同一个版本的驱动或开源系统。小组长们要定期核查自己的业务用了哪些驱动或系统,要不要升级到最新稳定版本。
第二个例子:升级未成功的例子
2018年负责开发IoT平台的潘军发现一个致命缺陷,用来与智能设备做MQTT协议通讯的RabbitMQ集群中部分节点重启会造成设备不能订阅消息。后台报错信息为:
404,<<"NOT_FOUND -no binding .shadow.get.…… between exchange 'amq.topic' in vhost '/'and queue 'mqtt-subscription- ……qos1' in vhost'/'">>
GitHub上早在2016年就有人提过这个问题,一直没有被解决,源码贡献者最后一次回答这个问题是在2018年的6月5号,但依然没有解决。
后来这个BUG在2019年3月8日发布的3.7.13版本里fix掉了:
Bug Fixes
Binding and unbindingoperations could fail with a NOT_FOUND channel exception if bindingtables got out of sync.
所以我决定为了规避集群脑裂重大风险,虽然危险但还是要升级,刚好可以在春节前趁着绝大多数设备都停机了,做一次升级。线下在此之前已经测试了一个月之久,业务一切正常。
线上版本由原来的3.7.7版本变更为3.8.9版本,也一切正常。但一个月后,开学季到来了。3月3日中午12点之后,RabbitMQ集群开始发疯,如下图所示。表现为:在Connections没有异动的情况下,各个节点的内存快速上涨并打满。
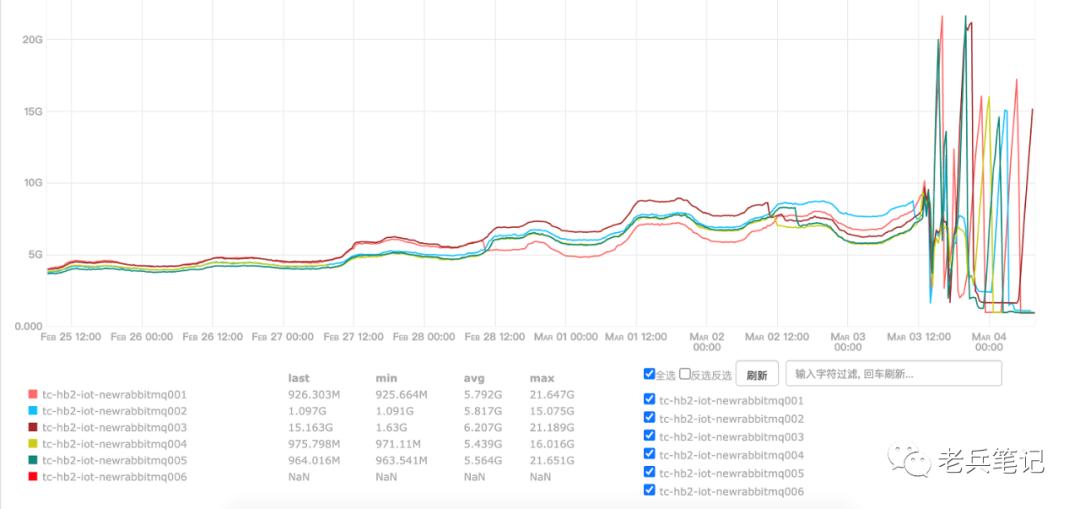
图2.2 RabbitMQ发疯
最终迫于无奈,我们只好退回到老版本。
2.1.3核心业务上线观察机制
经常维护核心业务的老兵都知道,系统发布之后,不经历几个交易周期的波峰波谷,真不敢说发布成功。经历过多次磨难之后,我们定义了这样的观察机制:
- 发布时机的选择
- 灰度发布 小心求证
- 发布后观察窗口
- 重大变更间隔发布
(一)发布时机的选择
虽然说持续发布可以让大家随时发布,但是对于本地生活服务的核心业务,也有不建议发布的时间窗口。 早中晚三个就餐高峰肯定是不建议发布的。
历史上有好几次惨痛教训,发布之后等性能开始告警的时候,却发现故障处理小分队都去吃饭了,等一个一个电话叫回来,小事故拖成了大事故。
(二)灰度发布 小心求证
我们的SW有灰度发布能力。对于核心系统, 新功能首次上线的时候,务必灰度发布,小心求证,不要全量发布,以免造成大面积影响。可以在SW里设置灰度规则,按照不同的流量规则(比如按商户id,或按流量百分比,或按URL地址关键字,或按访问IP地址等)做灰度验证。
(三)发布后观察窗口
很多开发同学没经历过大流量系统,还习惯于发布后等了几分钟就欣喜地下班跑路了。性能出现问题有一个发展的过程,量变引起质变。所以我们约定,核心系统发布后,所有参与同学必须 一起留下来观察至少半小时。测试负责人宣布发布成功,让大家走才能走。
(四)重大变更间隔发布
核心系统重大更新,或者关键组件重大升级,必须错开:第一天升级,第二天观察,第三天再升级,第四天观察。按照这个间隔发布原则,核心系统升级一般会选择:
周二和周四。
不允许选择周五做重大升级,否则等到周六高峰期出事的时候,很多人都联系不上,就算电话联系上,也难以统一指挥和及时处理。
第一个例子:P1级,升配双活机房RDS
我们一家公司的数据库管理员于某日凌晨将华北和华东机房的主力RDS数据库做了升配。在云计算时代,对数据库做升配降配本是一个很平常的操作。
却不料从早高峰就出现了性能恶化的征兆,到了午高峰前夕,形势已不可收拾,双活机房的主力RDS数据库均出现了CPU使用率不高、IO正常、但连接数飙升、连接耗时过长、处理能力下降的现象,连累我司支付网关以及上游支付应用堵塞,交易失败率升高。
11点41分,DBA做了RDS数据库主备切换,备库成为了主库,一瞬间性能恢复了,更加说明这是阿里云自己的问题。
当天我司一直在与阿里云技术支持工程师沟通,对方以及数据库内核值班人员和服务专家团队始终未能定位问题。直到6月2日下午阿里云团队定位了问题,通知我司,可以简单理解为还是阿里云RDS数据库的线程池老问题,又一次被我们撞了出来。
2019年12月25日至27日,我们一家公司做了RDS数据库降配,实例内核小版本为rds_20191212,这个版本有BUG,因而在大访问量的情况下引发了主备频繁切换。事发后,阿里云发布了公告,随后做了紧急修复,关闭了thread pool默认特性。
但进入2020年,它的内核小版本rds_20200331版本中该参数沿用了优化后的参数模板,所以thread pool特性又被打开了。我们升配升到了这个小版本之后,由于我们业务访问量大,很快暴露了这个问题,主库性能下降。
所以 对阿里云RDS数据库做升配或降配的时候,一定要单个机房顺序操作,升一个观察一天,不要一下子全升。
第二个例子:P0级,升级双机房关键工程
某日,某业务线同时升级了双活机房的ERP工程。
结果到了早餐时段,全国多地反馈,支付宝支付时报“获取顾客账户信息失败”。只是支付宝用户被扫随机出现问题,不涉及微信支付,也不涉及支付宝用户主扫。
由于双机房都升级了,所以一时之间难以确定根本原因在我方,还是在支付宝。查找无果,双机房均回滚版本,此类错误绝大部分消失。
所以强调一万遍都不为过, 大型发布上线,先上单机房,观察一天之后再上另一个机房,就不会这么狼狈,连是自己的错误,还是支付宝错误,都分不清楚。华东更新了,华东有问题,华北没问题,一目了然。
2.1.4重大节假日封机房机制
周六日还好,大家不会一窝蜂离开北京。但是每逢重大节假日,员工们就会提前坐火车坐飞机离开北京,即使有人值班,在此之前的更新发布也会变成一个非常危险的动作,很有可能带来无尽的灾难。
所以我们痛定思痛,由达摩院质量控制部负责人出头约定:
每逢佳节必封版 。
第一,打一个提前量,比如提前一周封版。
第二,封版之后严禁做任何系统更新。
第三,如确需上线,比如紧急bugfix,必须获得CTO的审批。
2.3软件类流程
软件其实包罗万象,前后端开发,小程序开发,APP客户端开发,太通用的流程我们就不讲了。
2.3.1数据库访问帐号的申请和审批流程
新加入进来的同学,可能还没有意识到我们这套技术支撑体系给大家提供了哪些好处,这是一个曾经历过四大事务所做企业内部安全审计、登陆过NASDAQ的团队,我们不是一个初创团队,我们致力于让每一个有志于成为独角兽、有志于境外上市的初创团队有一个成功的IT基础:
- 依法合规 :有了研发协作三剑客CE+iDB+SW,大数据协作魔盒,以及它们底层依赖的TouchStone,MDC,CloudBase,磐石……(如下图所示),直接获得合规性,轻松应对上市审计,即,第一,环境变更,有审核记录,有操作记录,事后可回溯,第二,用户岗位职责与系统用户权限相符合,责权利对称;
- 体验统一,快速迁移,快速复制 :我们这个技术团队的人,不管是云纵云停业务,还是禧云信息业务,不管是北京还是武汉秦皇岛,不管是应用部署在线上,线下,私有云,还是公有云,认知和体验一致,便于培训、维护和迁移。
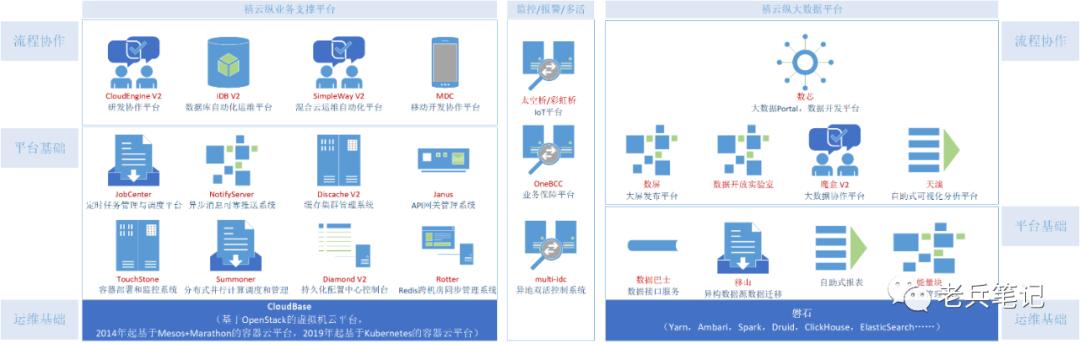
图2.9 体系中第一层是完成流程协作的几个系统
为了严格保证员工岗位职责与用户权限相符,为了避免发生各种不必要的流血事件(比如刷库刷错,比如一个慢查打挂数据库,比如删库跑路),我们约定:
- 测试环境和生产环境的数据库,统一由数据库管理员也就是DBA管理,开发员工没有权限操作;
- DBA管理数据库的重要工具之一就是我们自研的iDB。
研发同学可以通过iDB提交两种数据库帐号的开通和权限分配:
- 工程帐号 :工程访问数据库(读库或写库)的帐号;
- 个人帐号 :申请开通个人帐号及相应数据表和字段权限之后,方可使用iDB的“线上数据查询”功能查询指定机房、指定数据库的数据。
实际例子:我要的是我以为,不是你以为
某日午高峰刚刚过去,13点23分,阿里云短信报警:
【阿里云】云监控-应用分组下云数据库RDS版实例于<13:23>发生报警, CPU使用率(98.7>80.0),持续时间1分钟。
可怕吗?
首先,这是峰值日,全国员工都在一线作战共同打交易峰值。其次,在此之前机房已经为此封版,我千叮咛万嘱咐。
结果还是有人顶风作案!
原来是一位研发员工“以为”高峰期已经过了,所以他通过堡垒机来直连 MyCat查询交易库,用count(*)语法查询某个时间段内的交易笔数。交易库做了水平分库,拆为32个库,因为他输入的SQL语句没走索引,所以32个库并发查,一把就把RDS所在的宿主机的CPU利用率打到100%,长达一两分钟。
我不要你以为,我要的是我以为!
是不是只需要叮嘱大家不要在交易高峰期查询生产数据库就可以了呢?
不!
是!
的!
如果放大时间轴,以年为单位,只要这个口子开着,早晚会有人“不小心”把核心业务的关键数据库查挂! 而且他还是用工程所使用的数据库帐号,直连 MyCat,你不把 MyCat 日志与堡垒机登录日志对照,还真不一定能找到“凶手”。
所以我们应该怎么做呢?
第一条,从技术上杜绝所有研发同学直连MySQL/MyCat的可能性:
堵住技术人员在没有任何监管的情况下直接查生产数据库(含私有云和公有云)的同时,必须给他们一条通路,那就是:第一,用 iDB,第二,用数据开放实验室。iDB的线上数据查询功能,本来也有拦截高危SQL的能力。
第二条,从技术上杜绝所有工程(包括PHP)配置文件里写明文密码的可能性:
CE和iDB建设之初,我要求的是高度自动化。工程师只是在iDB里为应用访问某个环境里的数据源申请工程帐号而已,部署和上线发布对他来说是透明的,他根本不需要接触到数据库密码这件事。他不知道明文密码,也就没有机会犯错。
2.3.2核心交易流程定期压力测试流程
每年双十二之前,阿里巴巴和蚂蚁都会对合作伙伴做压测。以2016年为例,压测是按照下面这四个场景逐个压云纵的纵横客系统,每次压测大约持续3~4个小时,按50 QPS递增,直至2000QPS停止压测:
- 集点加减
- 查询集点详情
- 集点兑换及领券(含集点冻结、领券,消息通知,集点解冻,集点扣减等功能点)
- 组合压
即既有单场景接口压测,也有组合场景(多个接口串起来)。
除了接口压测之外,还有一种全链路压测,它适用于这种场景:第一,针对链路长、环节多、服务依赖复杂的系统,全链路压测可以更快更准确地定位问题;第二,系统必须有完备的监控报警,在压测出现问题的时候可以随时终止操作;第三,有明显的业务峰值和低谷。比如说美团采用自主开发的pTest压测工具对核心交易做全链路压测。
在全链路压测的研究中,业界基本形成了四种解决方案:
第一种是 基于TCP/HTTP流量录制和回放 ,如网易的tcpcopy,twitter的diffy,都是在应用外部基于网络层实现流量的录制、回放和倍数放大。
第二种是 基于Java AOP录制和回放 ,在Java应用内通过AOP切面编程方式实现的流量录制和回放,并且有Mock机制,可实现写流量的回归验证。阿里早年间有一个DOOM,后来它被放入阿里云的云效里,这是一个收费项目。据称阿里内部几乎所有交易核心系统都通过DOOM去做引流回归测试。
第三种是 基于接口和预置CSV数据 ,典型代表是阿里云的PTS和ARMS(Application Real-Time Monitoring Service)服务。PTS+ARMS就是个 JMeter注4 在线豪华版,所以JMeter脚本可以转为PTS脚本。
第四种是 基于RPC调用录制和回放 ,如滴滴的RDebug。
毋庸讳言,核心交易流程更新频繁,如果不定期做一次体检,早晚会出事,而且一出事就是大事。 压测应由达摩院质量控制部发起,各个业务产研团队必须通力配合。
大家要注意做压测的初心,做压测方案的时候别跑偏了。压测的目的有四条:
第一条, 了解现状 ,得到现有应用方案在一个或多个特定配置下的性能基准值。
第二条, 性能调优 ,根据压测,必然能够暴露很多问题,比如我们认为怎么着也得压到1000 QPS吧,但实际上压到500 QPS服务就爆掉了,那就得调优了。
第三个, 把握未来 ,根据基准定期观察新版本的性能是上升了还是下降了,所以几个大版本发布之后必须再安排一次压测。
第四个, 容量预估 ,交易笔数翻一倍怎么扩容,翻两倍怎么扩,不能拍脑袋。
实际例子:PTS+ARMS
2019年7月,针对ERP系统、开放平台和支付网关这条链路做了基于阿里云PTS+ARMS和 支付宝挡板机注5 的压力测试方案。
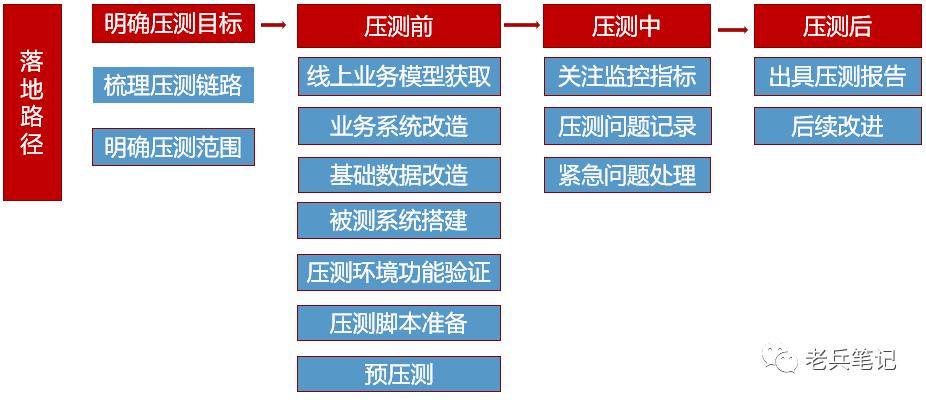
图2.15 压力测试的主要工作内容
出于安全考虑,本次压力测试与原有业务做了物理隔离,同时引入了支付宝挡板机,形成了以下三个特点:
- 压测环境业务形成闭环
- 与生产机房物理隔离
- 启用了与生产环境完全独立的外网域名
同时为了便于识别,订单生成规则和生产环境也不一样。
本次压测的大致做法为:
- 将已有的JMeter脚本导入PTS自研交互中,使用 PTS 自研引擎;
- 或导入JMeter脚本并使用原生JMeter引擎进行压测,PTS 提供自定义的压力构造和监控数据汇聚等产品服务;
- 或使用PTS自研云端录制器,零侵入录制业务请求并导入PTS自研交互中进行进一步设置;
- 监控工具:OpenFalcon,以及阿里云的监控工具,可以对Mesos、MyCat、Nginx、Redis、ZooKeeper等的I/O、CPU、内存使用情况、平均负载情况、ESTAB连接数进行监控。
当然,上述方案开发、搭建和维护的成本太高,也并不是最优选择。
注4:Apache JMeter是一款经典的基于Java的压力测试工具。
注5:支付宝挡板机是支付宝提供的,可以免费使用的支付网关mock系统。
2.4配置管理类流程
一个专业的技术团队可以没有云原生,可以没有大中台,可以没有中间件,但不能没有配置管理。从配置管理上一叶知秋,能看出一个团队是否专业,能走多远。
2.4.1日常代码分支管理流程规范
我司代码统一使用Gitlab做维护和管理,但不对公网开放。
注意事项:
严禁开发同学私自上传项目代码到公有的代码托管平台上。受国内外开源思想影响,程序员爱逛各大开源社区、代码托管平台,时常会在无意间将公司的工程代码发布到公网!这样会被全网白帽子、黑客和生态维护者(如蚂蚁)侦测到,导致服务器的IP地址、用户名密码、数据库帐号密码等泄露,引发不可收拾的灾难。这些代码托管平台包括但不限于:Github、GoogleCode、码云、码市、CSDN Code、百度效率云等。
实际例子:外部安全事故
2015年4月14日,多位Yahoo北京前员工将内部代码包括密钥上传到了github,以至于他们的安全部门开出了S0 tickets。
2017年8月28日,大疆宣布“大疆威胁识别奖励计划”,然而在此之前,大疆农业事业部某员工将企业私有源代码上传到了github。就职于大疆竞对公司Department13公司的美国人Kevin Finisterre向大疆提交了一份31页的报告,列出了他与其同事找到的漏洞,包括通过github找到的大疆AWS的SSL凭证密钥的漏洞。2019年4月上旬,深圳法院对事件中进行该违规操作导致代码和密钥泄露的员工作出了一审判决,该员工被以侵犯商业秘密罪判处有期徒刑六个月,并处罚金20万元。
2.4.1.2分支管理
为了减轻开发人员拉取和合并分支的压力,常用分支只维护以下四个:
开发分支(Feature)
测试分支(Release)
上线分支(Release-online)
稳定分支(Master)
对照下图,我们下面一一论述。
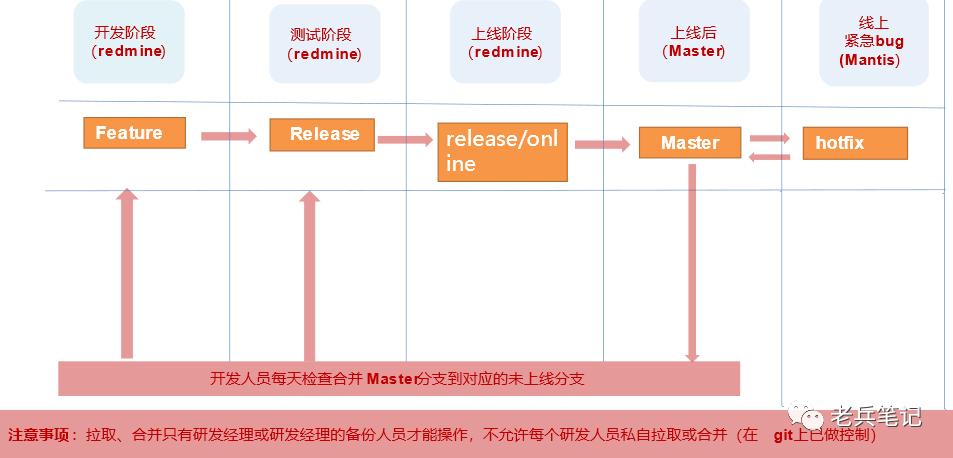
图2.17 分支管理示意图
(一)开发分支
由研发经理从Master分支上拉取作为研发人员开发使用,对应的分支为Feature。对应多个开发任务,添加版本号即可。
(二)测试分支
开发自测完成后,由研发经理合并到测试分支(Release),提交给测试人员进行测试验证。
(三)上线分支
测试完成后,测试人员发送邮件给开发人员、产品经理、达摩院质量控制部。验收通过后,研发经理将测试通过的Release分支合并到Release-online分支,再由测试人员做上线前验证。
(四)稳定分支
Release分支上线后,对应的功能验证通过,再经过一天业务高峰低谷的运行,确认无问题后,将Release-online分支合并到Master分支。
(五)紧急分支
仅仅针对线上的紧急BUG必须立即修复的,从Master分支拉取Hotfix分支做紧急上线,上线验证通过必须合并到Master分支。
注:本文源自《CLOUDZ集团研发员工指南》,为禧云信息内部编著的技术交流资料。