背景
众所周知,Cobalt Strike作为一款强大工具,已被众多渗透测试团队和实际攻击团队广泛采用。其功能完善和配置灵活性高等特点使得在满足攻击需求和规避检测方面表现出色。然而,这也给各大防御团队带来了巨大的防御和检测成本。尽管通过严格监控终端行为可以有效发现高危行为并追踪Cobalt Strike木马,但终端行为检测的滞后性使公司安全团队难以接受,因此纷纷转向网络通信检测,试图从网络通信角度迅速精确发现Cobalt Strike 入侵。
我们关注 Cobalt Strike 的常用网络通信协议,如HTTP、HTTPS和 DNS。由于HTTP 和 DNS通信特征均为明文,各种检测逻辑已广泛应用于开源IDS 设备,可以有效检测。然而,HTTPS成为了一个难以攻克的难题。Cobalt Strike 利用 HTTPS加密机制将通信特征隐藏,使流量检测设备束手无策。据了解,当前针对HTTPS 的检测仅能针对已公开的IOC,例如证书信息和已被安全人员分析的HTTPS 包等已知特征。然而,这些方法均无法对未出现过的HTTPS 进行检测。在实际攻击场景中,攻击者可轻松配置Cobalt Strike 的HTTPS 通信,并在每次攻击时重新配置(更改证书、域名、通信特征等),使基于现有IOC 检测 HTTPS通信的方法几乎无效。
那么如何检测 Cobalt Strike 的 HTTPS通信呢?让我们一起探讨如何在机器学习热潮的推动下,尝试使用机器学习方法来检测Cobalt Strike 的HTTPS 通信。
02
二、机器学习基础
2.1监督学习
监督学习是通过使用有标签的训练数据学习得到一个模型,然后用这个模型对新样本进行预测。例如,向计算机输入两张图片,第一张带有蔡徐坤的标签,让计算机学习其特征;第二张带有王境泽的标签,让计算机学习其特征。本质上,输入数据中包含导师信号。此方法将用于后续检测木马。


2.2无监督学习
无监督学习直接对数据进行建模,不需要事先标记过的训练范例。所用数据没有属性或标签。事先不知道输入数据对应的输出结果。例如,向计算机输入蔡徐坤和王境泽的图片,让计算机通过算法自行分类或分群,寻找数据模型和规律。本质上,输入数据中没有导师信号,不需要人工打标签。
2.3 K-近邻算法
K-近邻算法(K-nearest neighbors,KNN)是最简单的机器学习分类算法之一,适用于多分类问题。简言之,物以类聚。例如,要判断中心的待预测样本点属于三角形还是正方形,我们可以以该点为圆心,画一个半径为k的圆,观察圆内三角形和正方形的数量,哪个多则归为哪一类。
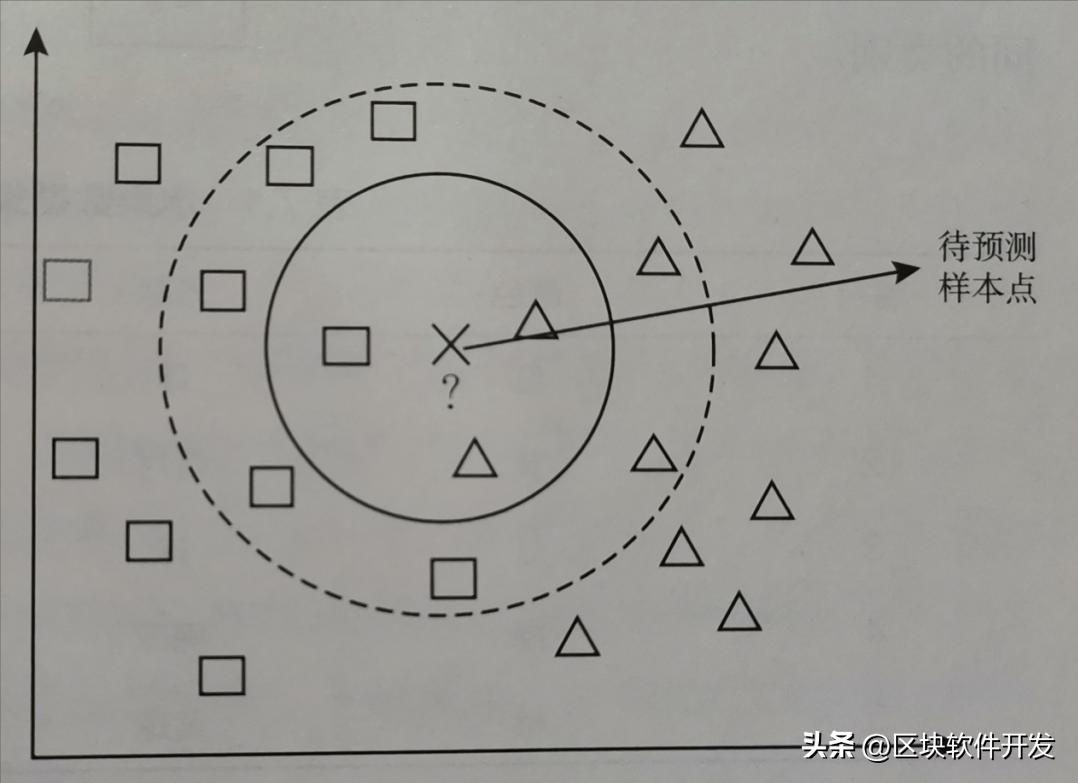
然而,KNN算法的缺点显而易见,主要是对参数的选择敏感。以上述例子为例,选取不同的参数K时,我们会得到完全不同的结果。例如,选取K=10时(如图中虚线所示),其中有6个正方形和4个三角形,则待预测样本点被判断为正方形,即使它可能是三角形。KNN算法的另一个缺点是计算量大,每次分类都需要计算未知数据和所有训练样本的距离,尤其在训练集非常大的情况下。因此,在实际应用中,KNN算法并不经常被采用。
03
如何检测CS流量
想要利用机器学习检测Cobalt Strike的通信包,我们需要首先分析问题。我们的目标是通过机器学习找出通信规律,然后用这个规律对新的通信包进行检测。虽然Cobalt Strike可以通过配置文件实现应用层通信特征的灵活变动,但传输层特征应该保持不变,因为它们独立于攻击者的配置,由软件和操作系统决定。因此,我们可以从传输层特征入手寻找规律。
1、通常,实现机器学习检测需要以下几个步骤:
2、原始数据采集
3、转换为机器学习能理解的数据
4、通过机器学习得出通信规律
5、使用规则部署检测系统
6、传入通信包特征,检测是否为Cobalt Strike 木马通信
机器学习的术语:
- 原始数据采集
- 特征工程
- 学习建模
- 模型发布
- 在线预测
数据采集
针对检测CS通信流量这个问题,在机器学习领域,他算是一个分类问题。我们需要把CS的流量从普通业务流量中找出来。因此数据采集阶段,我们需要采集两部分数据,一部分为CS的通信数据(黑数据),一部分为普通业务流量(白数据),采用监督学习的方式给两部分流量打上标签,然后送给算法建模。
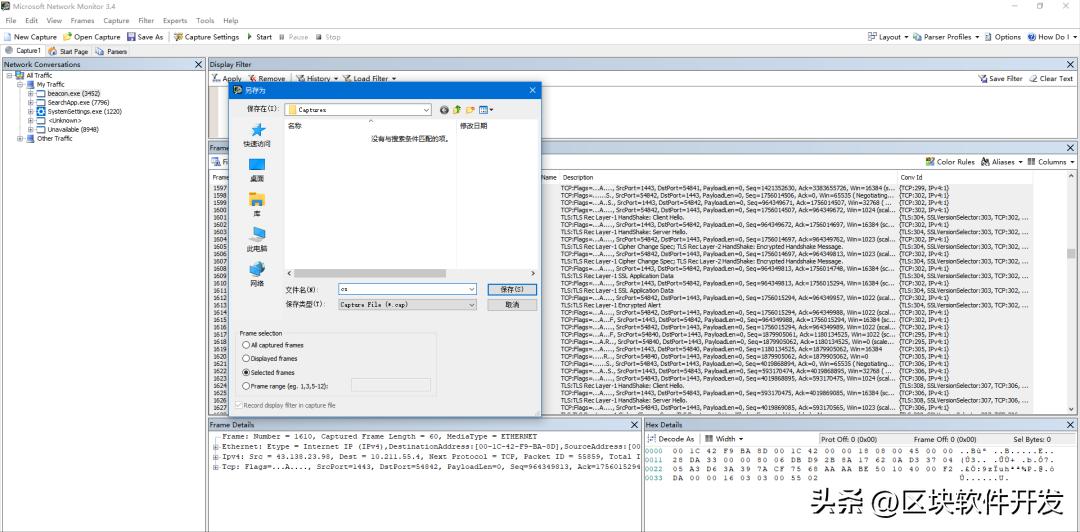
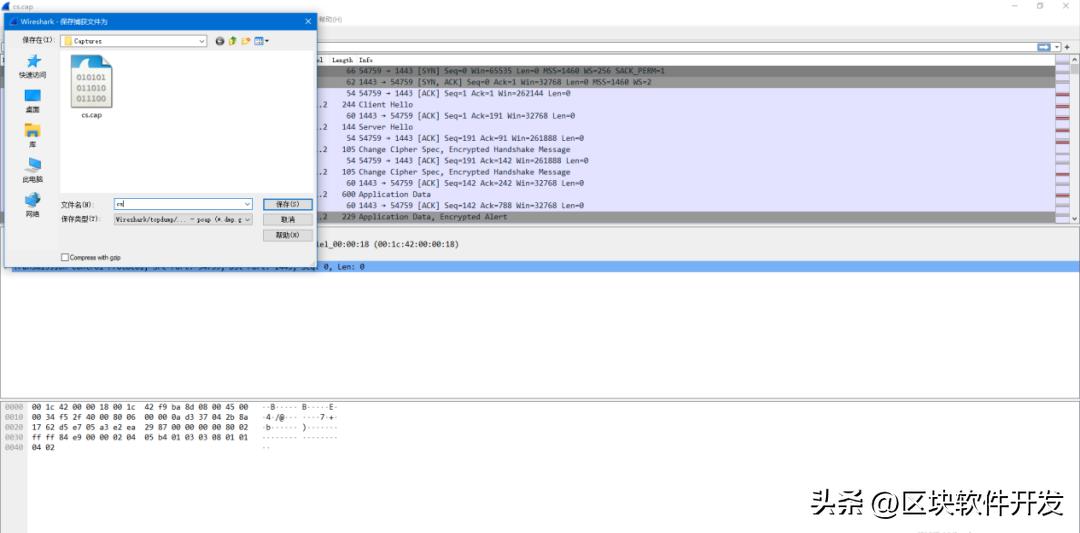
这里我们使用 Microsoft Network Monitor来抓取流量。直接选取beacon进程,将beacon与c2服务器的通讯流量保存为cap数据包。然后使用wireshark将cap数据包转为pcap数据包,这就是我们的黑数据。白数据,就懒得说了,wireshark随便抓点流量。

特征工程
特征工程就是把原始数据转换为机器学习能理解的数据。
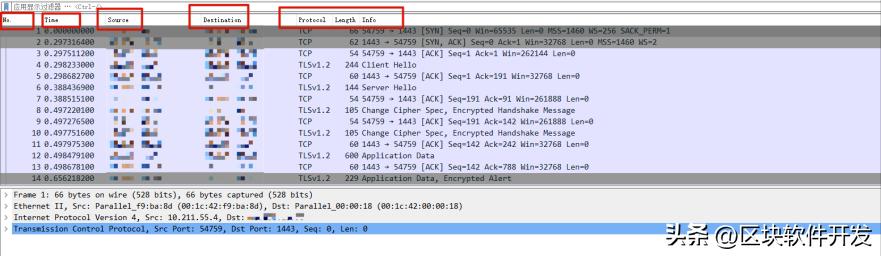
点开wireshark,我们可以都到如下7个字段,这些信息是给人看的,如果要喂给机器看的话我们就需要进行转换。将其转换为tcp流量的通信特征。
特征提取我们采用的工具是 cicflowmeter,CICflowmeter是一款流量特征提取工具,该工具输入pcap文件,输出pcap文件中包含的数据包的特征信息,共80多维,以csv表格的形式输出。
使用 cicflowmeter我们将pacp包转换为csv文件。
转换的csv如下:
特征字段对应关系如下:
|
id |
字段名 |
说明 |
|
1 |
flow_duration |
流持续时间 |
|
2 |
flow_byts_s |
流字节率,即每秒传输的数据包字节数 |
|
3 |
flow_pkts_s |
流包率,即每秒传输的数据包数 |
|
4 |
fwd_pkts_s |
每秒前向包的数量 |
|
5 |
bwd_pkts_s |
每秒后向包的数量 |
|
6 |
tot_fwd_pkts |
在正向上包的数量 |
|
7 |
tot_bwd_pkts |
在反向上包的数量 |
|
8 |
totlen_fwd_pkts |
正向数据包的总大小 |
|
9 |
totlen_bwd_pkts |
反向数据包的总大小 |
|
10 |
fwd_pkt_len_max |
包在正向上的最大大小 |
|
11 |
fwd_pkt_len_min |
包在正向上的最小大小 |
|
12 |
fwd_pkt_len_mean |
数据包在正向的平均大小 |
|
13 |
fwd_pkt_len_std |
数据包正向标准偏差大小 |
|
14 |
bwd_pkt_len_max |
包在反向上的最大大小 |
|
15 |
bwd_pkt_len_min |
包在反向上的最小大小 |
|
16 |
bwd_pkt_len_mean |
数据包在反向的平均大小 |
|
17 |
bwd_pkt_len_std |
数据包反向标准偏差大小 |
|
18 |
pkt_len_max |
流的最大长度 |
|
19 |
pkt_len_min |
流的最小长度 |
|
20 |
pkt_len_mean |
流的平均长度 |
|
21 |
pkt_len_std |
流长度的方差 |
|
22 |
pkt_len_var |
最小包到达间隔时间 |
|
23 |
fwd_header_len |
用于前向方向上的包头的总字节数 |
|
24 |
bwd_header_len |
用于后向方向上的包头的总字节数 |
|
25 |
fwd_seg_size_min |
在正方向观察到的最小 segment 尺寸 |
|
26 |
fwd_act_data_pkts |
在正向方向上具有至少 1 字节 TCP 数据有效负载的包 |
|
27 |
flow_iat_mean |
两个流之间的平均时间 |
|
28 |
flow_iat_max |
两个流之间的最大时间 |
|
29 |
flow_iat_min |
两个流之间的最小时间 |
|
30 |
flow_iat_std |
两个流之间标准差 |
|
31 |
fwd_iat_tot |
在正向发送的两个包之间的总时间 |
|
32 |
fwd_iat_max |
在正向发送的两个包之间的最大时间 |
|
33 |
fwd_iat_min |
在正向发送的两个包之间的最小时间 |
|
34 |
fwd_iat_mean |
在正向发送的两个包之间的平均时间 |
|
35 |
fwd_iat_std |
在正向发送的两个数据包之间的标准偏差时间 |
|
36 |
bwd_iat_tot |
反向发送的两个包之间的总时间 |
|
37 |
bwd_iat_max |
在反向发送的两个包之间的最大时间 |
|
38 |
bwd_iat_min |
反向发送的两个包之间的最小时间 |
|
39 |
bwd_iat_mean |
反向发送的两个数据包之间的平均时间 |
|
40 |
bwd_iat_std |
在正向发送的两个数据包之间的标准偏差时间 |
|
41 |
fwd_psh_flags |
在正向传输的数据包中设置 PSH 标志的次数 (UDP 为 0) |
|
42 |
bwd_psh_flags |
在反向传输的数据包中设置 PSH 标志的次数 (UDP 为 0) |
|
43 |
fwd_urg_flags |
在正向传输的数据包中设置 URG 标志的次数 (UDP 为 0) |
|
44 |
bwd_urg_flags |
反方向数据包中设置 URG 标志的次数 (UDP 为 0) |
|
45 |
fin_flag_cnt |
带有 FIN 的包数量 |
|
46 |
syn_flag_cnt |
带有 SYN 的包数量 |
|
47 |
rst_flag_cnt |
带有 RST 的包数量 |
|
48 |
psh_flag_cnt |
带有 PUSH 的包数量 |
|
49 |
ack_flag_cnt |
带有 ACK 的包数量 |
|
50 |
urg_flag_cnt |
带有 URG 的包数量 |
|
51 |
ece_flag_cnt |
带有 ECE 的包数量 |
|
52 |
down_up_ratio |
*载下**和上传的比例 |
|
53 |
pkt_size_avg |
数据包的平均大小 |
|
54 |
init_fwd_win_byts |
在正向的初始窗口中发送的字节数 |
|
55 |
init_bwd_win_byts |
在反向的初始窗口中发送的字节数 |
|
56 |
active_max |
流在空闲之前处于活动状态的最大时间 |
|
57 |
active_min |
流空闲前激活的最小时间 |
|
58 |
active_mean |
流在空闲之前处于活动状态的平均时间 |
|
59 |
active_std |
流在空闲之前处于活动状态的标准偏差时间 |
|
60 |
idle_max |
流在激活之前空闲的最大时间 |
|
61 |
idle_min |
流在激活之前空闲的最小时间 |
|
62 |
idle_mean |
流在激活之前空闲的平均时间 |
|
63 |
idle_std |
流量在激活前处于空闲状态的标准偏差时间 |
|
64 |
fwd_byts_b_avg |
在正向上的平均字节数块速率 |
|
65 |
fwd_pkts_b_avg |
在正向方向上数据包的平均数量 |
|
66 |
bwd_byts_b_avg |
在反向上的平均字节数块速率 |
|
67 |
bwd_pkts_b_avg |
在反向方向上数据包的平均数量 |
|
68 |
fwd_blk_rate_avg |
在正向方向上平均 bulk 速率 |
|
69 |
bwd_blk_rate_avg |
在反向方向上平均 bulk 速率 |
|
70 |
fwd_seg_size_avg |
观察到的前向方向上数据包的平均大小 |
|
71 |
bwd_seg_size_avg |
观察到的后向方向上数据包的平均大小 |
|
72 |
cwe_flag_count |
带有 CWE 的包数量 |
|
73 |
subflow_fwd_pkts |
在正向子流中包的平均数量 |
|
74 |
subflow_bwd_pkts |
反向子流中数据包的平均数量 |
|
75 |
subflow_fwd_byts |
子流在正向中的平均字节数 |
|
76 |
subflow_bwd_byts |
子流在反向中的平均字节数 |
白流量同样的处理方式,这里不再赘述。
数据处理
在进行训练建模之前,我们需要对特征工程输出的数据进行处理,以便于消耗更低的算力获取更高的准确度。
有些字段是对我们训练模型是没有帮助的,比如Flow ID、Src IP、Dst IP、Timestamp等等,我们需要在数据处理中将这些字段的数据删除。我们还需要给黑白流量打上标签,因此我们需要增加一个标签“hacker”,我们使用python的pandas库对csv文件简单的处理一下。
处理结果如下,
同样的我们将白数据也这样处理,然后和黑数据合并。考验大家Excel技术的时候到了,当然你也可以用pandas库处理。

处理好的数据如下,
机器学习建模
这个步骤我们可用python的Numpy、Pandas、sklearn、seaborn等模块,通过代码实现,但我懒啊,图形化工具启动。
把数据处理的数据导入,
然后我们要对数据进行简单的处理,首先是异常值的处理,比如说有些值是空的,我们这就可以将空值替换为平均值。
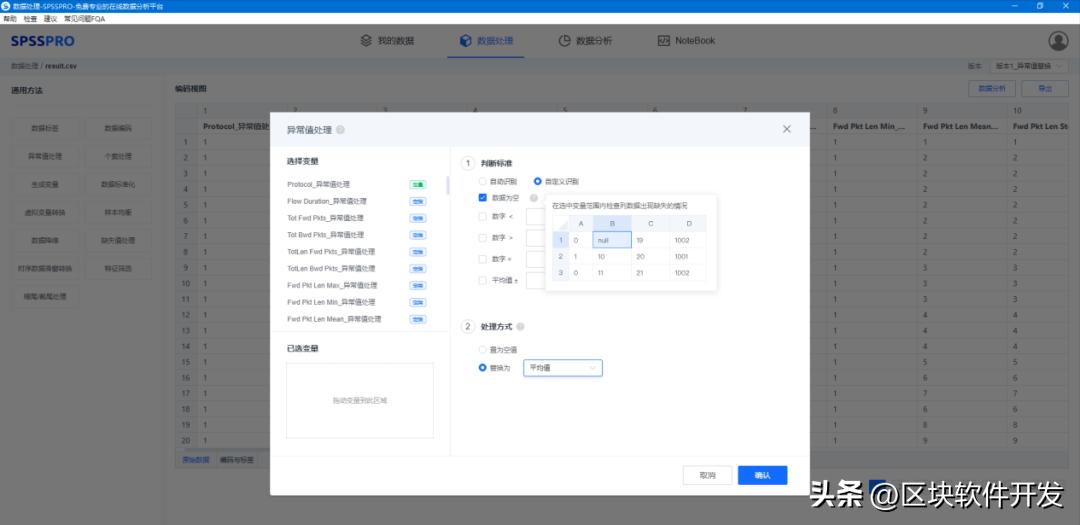
然后进行数据标准化,在做训练时,需要先将 特征值 与 标签 标准化,可以防止梯度防炸和过拟合;人话就是这样可以提升模型精度。我们这就用min-max标准化来处理数据,让所有数据线性变换使其落到[0,1]之间,具体计算公式为 (X-min)/(max-min)。
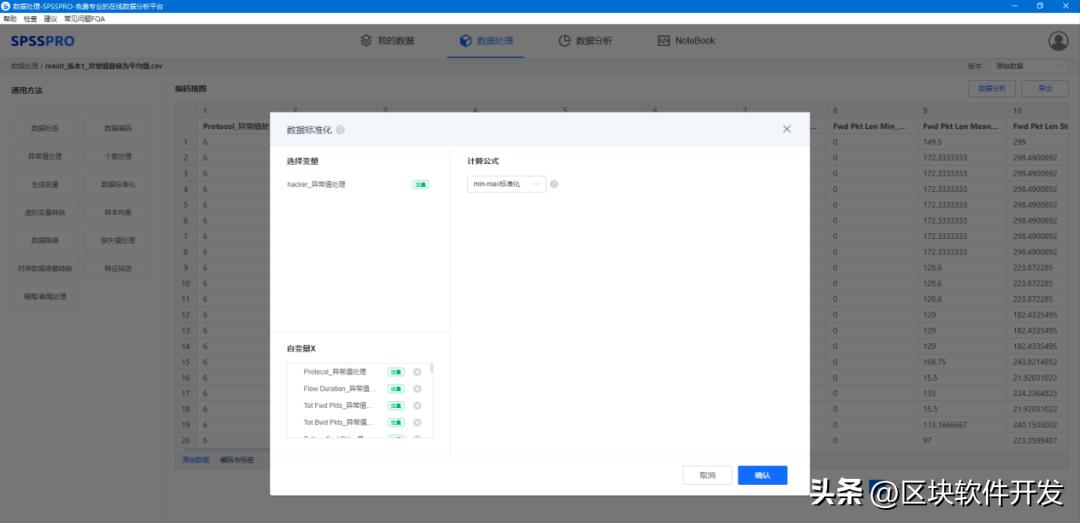
然后我们就可以开始数据分析工作了。我们选取机器学习分类中的knn分类算法。
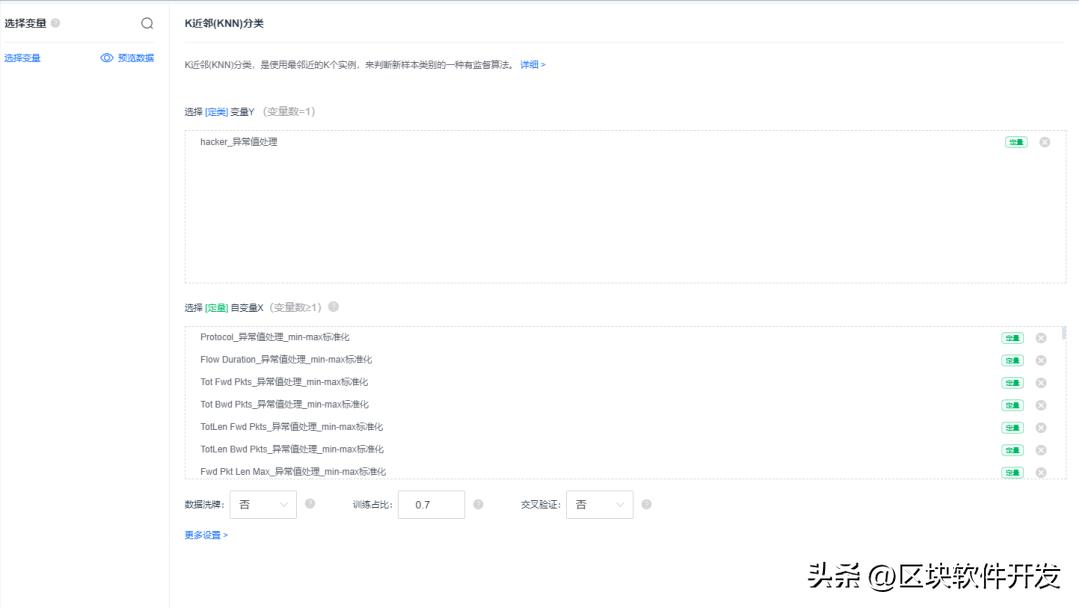
填一下自变量和因变量。开启数据洗牌,将数据重新打乱顺序按照训练重新分割数据。交叉验证也选一下,交叉验证就是格数据集划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,剩下的那一个子集作为测试集,进行k次训练和测试,最后返回k个评估结果的均值。可以避免数据划分不合理而导致的在训练集上过拟合问题。说人话就是通常我们将数据集分为两部分,即训练集和测试集;训练集数据是用于模型训练和开发,测试集是用于验证模型的性能。交叉验证是重复多次选取训练集,并将全部数据遍历验证的过程。

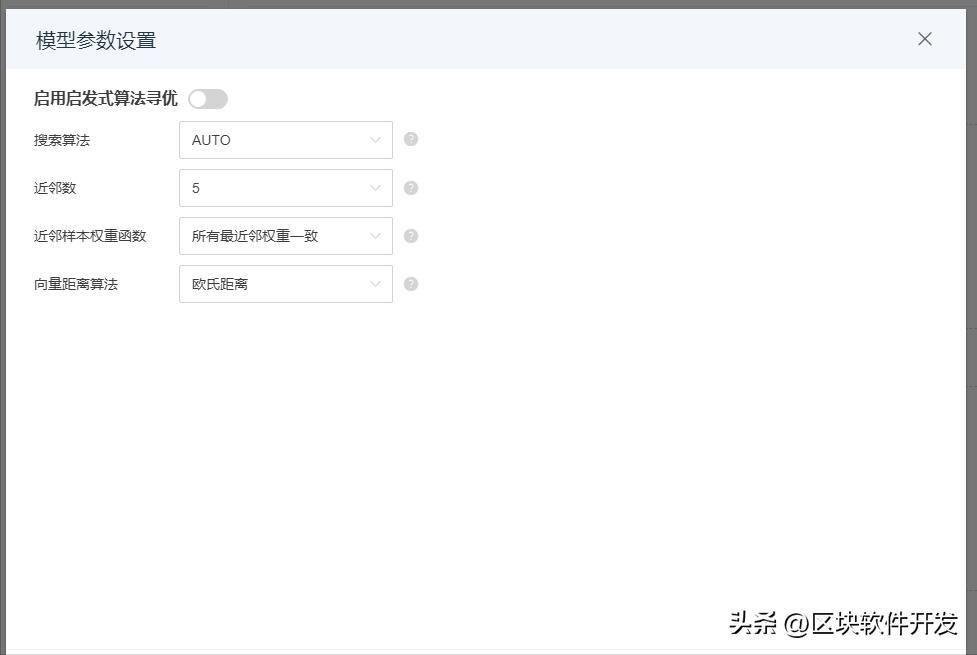
然后就是更多设置里啊这些东西,什么遗传算法、近邻样本权重函数这些,就懒得调了,不是我不懂啊。
然后运行等结果就行了。
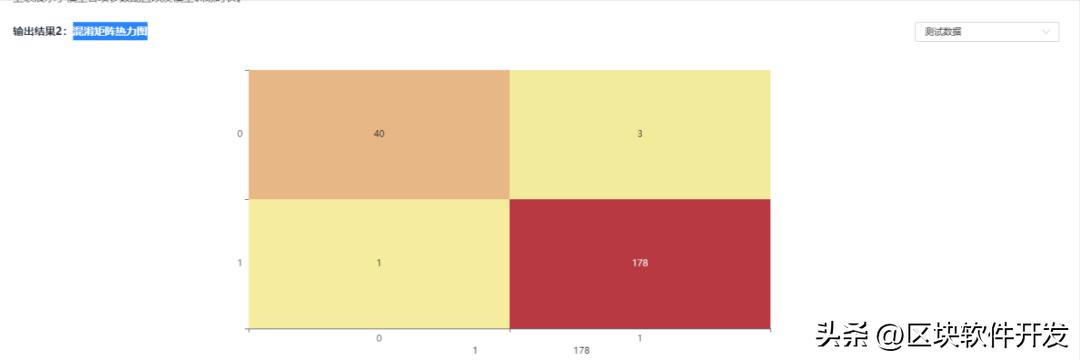
混淆矩阵热力图
简单解释下,这是一个最简单的二分类混淆矩阵,只区分0或1,它的行代表真实的类别,列代表预测的类别。比如右下角,行为1列为1,有178个1类别的标签被预测为1。
模型评估结果
自己看下面图表说明,简单的来说,这个模型准确率有98%
|
准确率 |
召回率 |
精确率 |
F1 |
|
|
训练集 |
0.967 |
0.967 |
0.967 |
0.967 |
|
交叉验证集 |
0.955 |
0.955 |
0.958 |
0.954 |
|
测试集 |
0.982 |
0.982 |
0.982 |
0.982 |
图表说明: 上表中展示了交叉验证集、训练集和测试集的预测评价指标,通过量化指标来衡量K近邻(KNN)的预测效果。其中,通过交叉验证集的评价指标可以不断调整超参数,以得到可靠稳定的模型。
● 准确率:预测正确样本占总样本的比例,准确率越大越好。
● 召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
●F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
模型发布
这个图形化的工具还是只能我们做研究用,找了半天没找到模型导出的地方,只能在他这个平台导数据进去预测,捞。找了一下,他模型放“C:\Users\Administrator\AppData\Roaming\spsspro\spsspro\report\attachment”这个目录。
这个mdl文件就是训练出来的二进制模型。
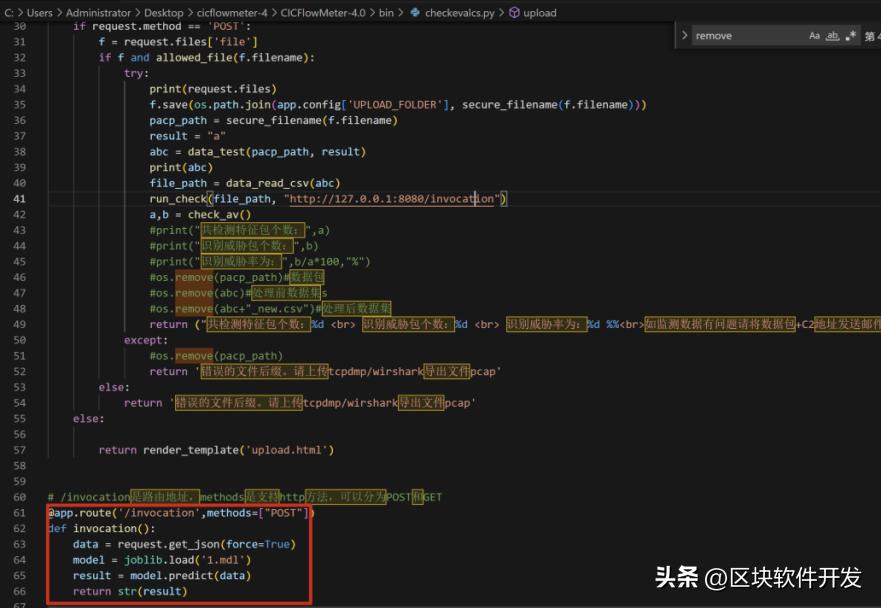
然后,我们简单的用flask写个检测平台。找大佬要现成的代码。
然后我们搭搭环境,调试调试就能跑了。代码不复杂,核心就是上传pacp,os.system运行cicflowmeter,pandas处理下csv文件然后用joblib加载我们的模型,进行预测就行了。
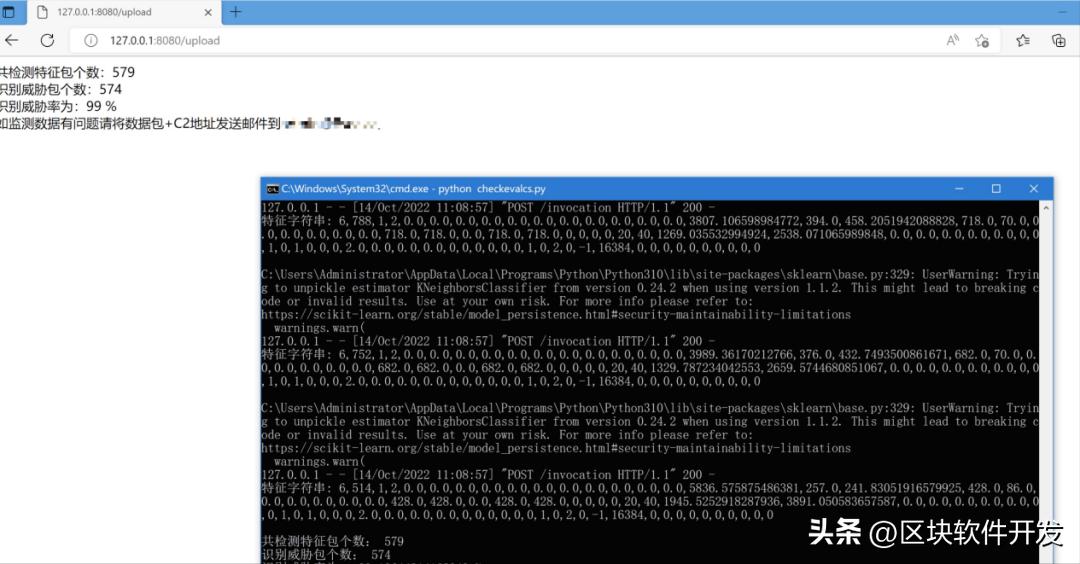
测试结果如下,可以看到,准确率还是非常高的。
04
总结
如上经过各种尝试,当前机器学习模型可以对测试的cobalt strike 的通信数据进行准确检测,但这仅仅是demo而已。cobalt strike不同版本,不同通信方式,不同的profile配置是否对模型准确度有影响,这些都是需要进一步研究学习的。实际上,这个demo因使用的学习算法、数据量、数据处理方式等还存在误报率高的问题,需要研究人员,研究合适的学习算法,数据处理方式,输入大量的白数据来降低误报率。而模型在接收到大量白数据的同时,还需要关注模型的准确率是否有下降。
参考文献
[1]Towards enriching the quality of k -nearest neighbor rule for document classification [J] . Tanmay Basu,C. A. Murthy. International Journal of Machine Learning and Cybernetics . 2014 (6)
[2]Efficiency classification by hybrid Bayesian networks—The dynamic multidimensional models [J] . Han-Ying Kao,Bo-Shan Chen. Applied Soft Computing Journal . 2014
[3]On the importance of the validation technique for classification with imbalanced datasets: Addressing covariate shift when data is skewed [J] . Victoria López,Alberto Fernández,Francisco Herrera. Information Sciences . 2014
[4]Almost optimal estimates for approximation and learning by radial basis function networks [J] . Shaobo Lin,Xia Liu,Yuanhua Rong,Zongben Xu. Machine Learning . 2014 (2)
[5]Online neural network model for non-stationary and imbalanced data stream classification [J] . Adel Ghazikhani,Reza Monsefi,Hadi Sadoghi Yazdi. International Journal of Machine Learning and Cybernetics . 2014 (1)
[6]An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics [J] . Victoria López,Alberto Fernández,Salvador García,Vasile Palade,Francisco Herrera. Information Sciences . 2013
[7]Cognitive gravitation model for classification on small noisy data [J] . Guihua Wen,Jia Wei,Jiabing Wang,Tiangang Zhou,L. Chen. Neurocomputing . 2013
[8]Gravitation based classification [J] . Parsazad Shafigh,Sadoghi Yazdi Hadi,Effati Sohrab. Information Sciences . 2013
[9]ACOSampling: An ant colony optimization-based undersampling method for classifying imbalanced DNA microarray data [J] . Hualong Yu,Jun Ni,Jing Zhao. Neurocomputing . 2013
[10]Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches [J] . Alberto Fernández,Victoria López,Mikel Galar,María José del Jesus,Francisco Herrera. Knowledge-Based Systems . 2013
[11]Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[12]Hall P, Park BU, Samworth RJ. Choice of neighbor order in nearest-neighbor classification. Annals of Statistics. 2008, 36 (5): 2135–2152. doi:10.1214/07-AOS537.
[13]Everitt, B. S., Landau, S., Leese, M. and Stahl, D.(2011)Miscellaneous Clustering Methods, in Cluster Analysis, 5th Edition, John Wiley & Sons, Ltd, Chichester, UK.
from https://mp.weixin.qq.com/s/BgTQ98yfLALrYkHbsh_Agw