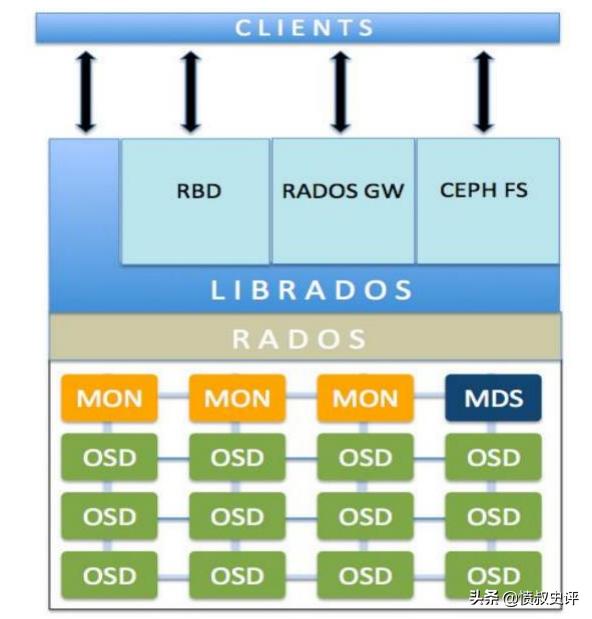
基本概念:
Ceph monitors(MON): Ceph monitor负责监控整个集群的健康状况。 它们以守护进程的形式存在,这些守护进程通过存储集群的关键信息来维护集群成员状态、对等节点状态, 以及集群配置信息。Ceph monitor通过维护整个集群状态的主副本来完成它的任务。集群map包括monitor、OSD、PG、CRUSH和MDS map。
Ceph 对象存储设备(OSD): 一旦应用程序向 Ceph 集群发出写操作,数据就以对象
的形式存储在 OSD 中。 这是 Ceph 集群中存储实际用户数据的惟一组件,通常,一个 OSD 守护进程绑定到 集群中的一个物理磁盘。因此,通常来说,Ceph 集群中物理磁盘的总数与在每个物理磁盘 上存储用户数据的 OSD 守护进程的总数相同。
Ceph metadata server (MDS): MDS 跟踪文件层次结构,仅为 Ceph FS 文件系统存储
元数据
• RADOS: RADOS 对象存储负责存储这些对象,而不管它们的数据类型如何。RADOS
层确保数据始终保持一致 ,它执行数据复制、故障检测和恢复,以及跨集群节点的数据迁移和再平衡
Librados: librados 库是一种访问 RADOS 的方便方法,支持 PHP、Ruby、Java、Python、
C 和 c++编程语言。它为 Ceph 存储集群(RADOS)提供了本机接口,并为其他服务提供了基 础,如 RBD、RGW 和 CephFS,这些服务构建在 librados 之上。librados 还支持从应用程序 直接访问 RADOS,没有 HTTP 开销。
RBD:提供持久块存储,它是瘦配置的、可调整大小的,并在多个 osd 上存储数据条
带。RBD 服务被构建为一个在 librados 之上的本机接口。
• RGW:RGW 提供对象存储服务。它使用 librgw (Rados 网关库)和 librados,允许应用
程序与 Ceph 对象存储建立连接。RGW 提供了与 Amazon S3 和 OpenStack Swift 兼容的
RESTful api 接口。
• CephFS: Ceph 文件系统提供了一个符合 posix 标准的文件系统,它使用 Ceph 存储集
群在文件系统上存储用户数据。与 RBD 和 RGW 一样,CephFS 服务也作为 librados 的本机 接口实现。
Ceph manager: Ceph manager 守护进程(Ceph -mgr)是在 Kraken 版本中引入的,它
与 monitor 守护进程一起运行,为外部监视和管理系统提供额外的监视和接口。
——————————————end 基本概念———————————————
环境准备:
操作系统:CentOS 7.5 , 每台配置50G数据盘
Ceph-node1: 172.16.10.2 : ceph-deploy , ceph-mon , RAG ,OSD mds
ceph-node2: 172.16.10.4 : ceph-mon , RAG ,OSD
Ceph-ndoe3: 172.16.10.7 : ceph-mon , RAG ,OSD
1. 命名统一: hostnamectl set-hostname ceph-node1 , ceph-node2 , ceph-node3
2. 配置host: /etc/hosts

3. 配置NTP服务
yum -y install ntpdate ntp
ntpdate ntp1.aliyun.com
systemctl restart ntpd ntpdate && systemctl enable ntpd ntpdate
查看ntp 是否同步:ntpq -p -n

说明: ntpq -p查看时间同步情况时报localhost: timed out, nothing ,使用ntpq -4p(即指定通过ipv4 地址获取返回值),如果正常显示,但是使用ntpq -6p(即指定通过ipv4 地址获取返回值)异常,则说明时因为开启了Ipv6 ,默认ntpq 先走Ipv6的通道,而ECS linux 默认无法直接访问ipv6地址,因此会访问超时 , 可以禁用接口的IPv6,然后就会正确,方法如下:/etc/sysctl.conf 文件尾添加如下参数重启网络
# 禁用整个系统所有接口的IPv6
net.ipv6.conf.all.disable_ipv6 = 1
# 禁用某一个指定接口的IPv6(例如:eth0, eth1)
net.ipv6.conf.eth1.disable_ipv6 = 1
net.ipv6.conf.eth0.disable_ipv6 = 1
4. 关闭selinux
/etc/selinux/config= disabled
setenforce 0
5 删除默认的源,配置国内base源和epel源
# yum clean all # mkdir /mnt/bak # mv /etc/yum.repos.d/* /mnt/bak/
# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
添加ceph源
# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=0
priority =1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=0
priority =1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS
gpgcheck=0
priority=1
5. 免密钥登录:ssh-keygen ssh-copy-id -i /root/.ssh/id_rsa.pub ceph-node1/ceph-node2/ceph-node3
6 准备磁盘: mkfs.xfs /dev/vdb ,所有磁盘
——————————————end 基础环境准备完毕———————————————
1 开始安装ceph-deploy : yum update -y && sudo yum install ceph-deploy -y
2 创建创建cluster目录 :mkdir cluster cd cluster
3 创建集群 (monit节点的主机名,这里monit节点和管理节点是同一台机器) : ceph-deploy new ceph-node1
4 修改ceph.conf文件(注意:mon_host必须和public network 网络是同网段内!)
[cephuser@ceph-admin cluster]$ vim ceph.conf #添加下面两行配置内容
public network = 192.16.10.2/24
osd pool default size = 3 (指的初始osd 个数)
5 执行安装:ceph-deploy install ceph-admin ceph-node1 ceph-node2 ceph-node3 (管理节点ceph-node1 ) : 需要等待的时间比较长
6. 初始化mon节点,并收集密钥:
[cephuser@ceph-node1 cluster]$ ceph-deploy mon create-initial
[cephuser@ceph-node1 cluster]$ ceph-deploy gatherkeys ceph-admin
7 把配置信息拷贝到各节点:ceph-deploy admin ceph-node1 ceph-node2 ceph-node3
(用ceph-deploy把配置文件和ceph-node1 管理节点密钥拷贝到管理节点和Ceph节点,这样你每次执行Ceph命令行时就无需指定monit节点地址 )
添加OSD 到集群:
8.检查OSD节点上所有可用的磁盘
[cephuser@ceph-admin cluster]$ ceph-deploy disk list ceph-node1 ceph-node2 ceph-node3
使用zap选项删除所有osd节点上的分区
[cephuser@ceph-node1 cluster]$ceph-deploy disk zap ceph-node1:/dev/vdb ceph-node2:/dev/vdb ceph-node3:/dev/vdb
准备OSD(使用prepare命令)
[cephuser@ceph-node1 cluster]$ceph-deploy osd prepare ceph-node1:/dev/vdb ceph-node2:/dev/vdb ceph-node3:/dev/vdb
激活OSD
[cephuser@ceph-node1 cluster]$ ceph-deploy osd activate ceph-node1:/dev/vdb1 ceph-node2:/dev/vdb1 ceph-node3:/dev/vdb1
所有的磁盘加入集群都需要执行一遍
9. 查看osd :
[cephuser@ceph-node1 cluster]$ ceph-deploy disk list ceph-node1 ceph-node2 ceph-node3
[ceph-node1][DEBUG ] /dev/vdb2 ceph journal, for /dev/vdb1 #如下显示这两个分区,则表示成功了
[ceph-node1][DEBUG ] /dev/vdb1 ceph data, active, cluster ceph, osd.0, journal /dev/vdb2
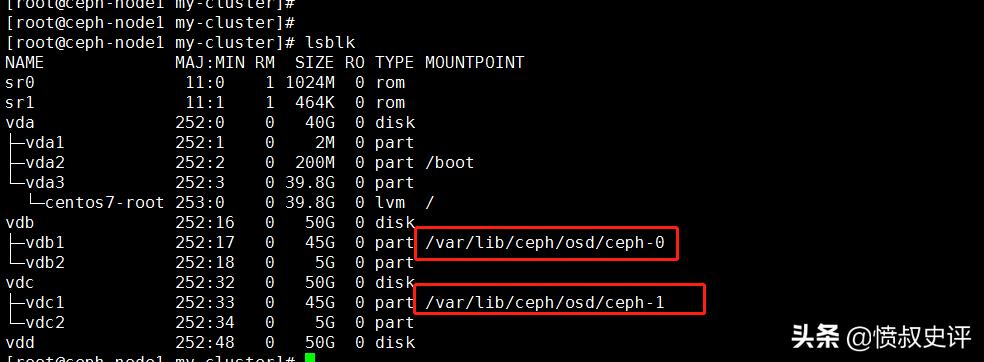
查看osd的目录树: [root@ceph-node1 my-cluster]# ceph osd tree
查看ceph osd运行状态 :[root@ceph-node1 my-cluster]# ceph osd stat
查看monit监控节点的服务情况:systemctl status ceph-mon@ceph-node1
分别查看下ceph-node1、ceph-node2、ceph-node3三个节点的osd服务情况systemctl status ceph-osd@1.service
10. 创建MDS
先查看管理节点状态,默认是没有管理节点的。
[root@ceph-node1 my-cluster]# ceph mds stat
e1:
创建管理节点 ceph-deploy mds create ceph-node1
再次查看管理节点状态
[root@ceph-node1 my-cluster]# ceph mds stat
e2:, 1 up:standby
systemctl status ceph-mds@ceph-node1
11 pool
查看pool:
[root@ceph-node1 my-cluster]# ceph osd lspools
0 rbd
创建pool: ceph osd pool create zgycloud 20 #后面的数字是PG的数量
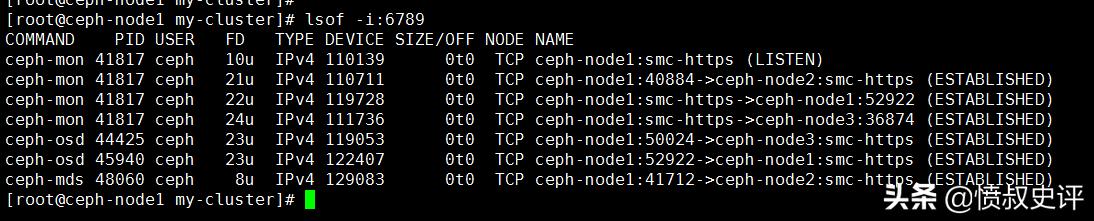
12 查看ceph 集群的端口:lsof -i:6789
此外,小编这里还有很多ceph 学习得资料,关注我私信分享