一、免密登录
1、生成秘钥
有三台服务器举例子 比如 flinka flinkb flinkc
举个例子,在flinkc上生成密码
ssh-keygen -t rsa
2、把公钥发给flinkb flinc flina 是的,自身也要设置免密
ssh-copy-id flinkb
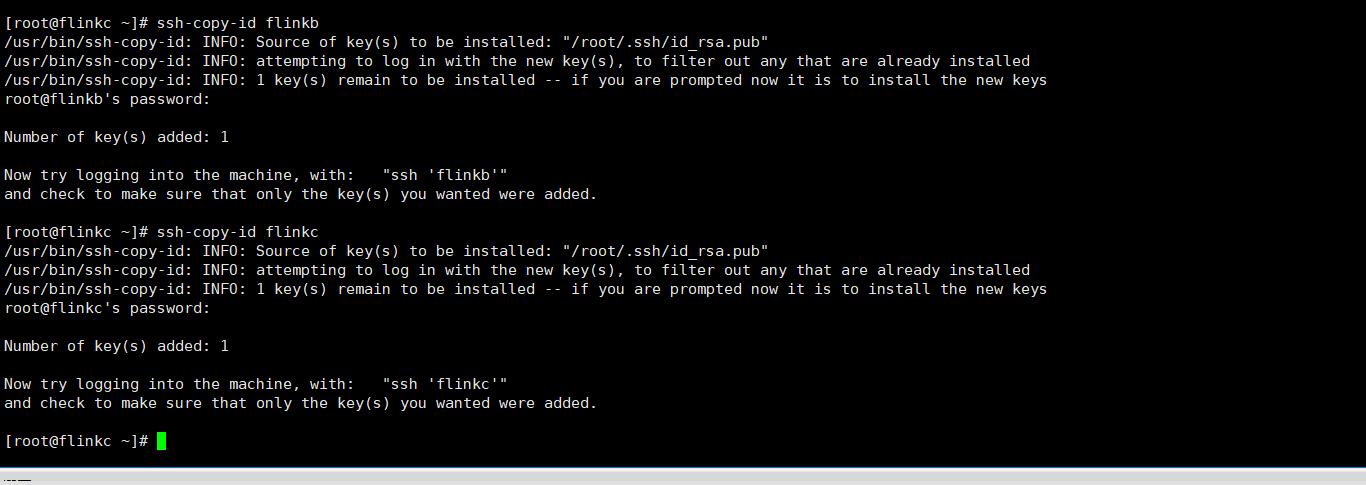
3、测试是否设置成功
ssh flinka
ssh flinkb
ssh flinkc


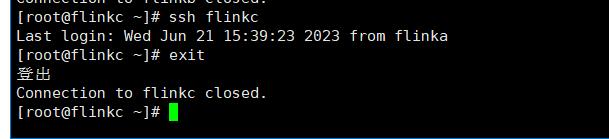
都不用设置密码的,就可以登录!!
在flinkb flinka另外两台服务器上也这样设置
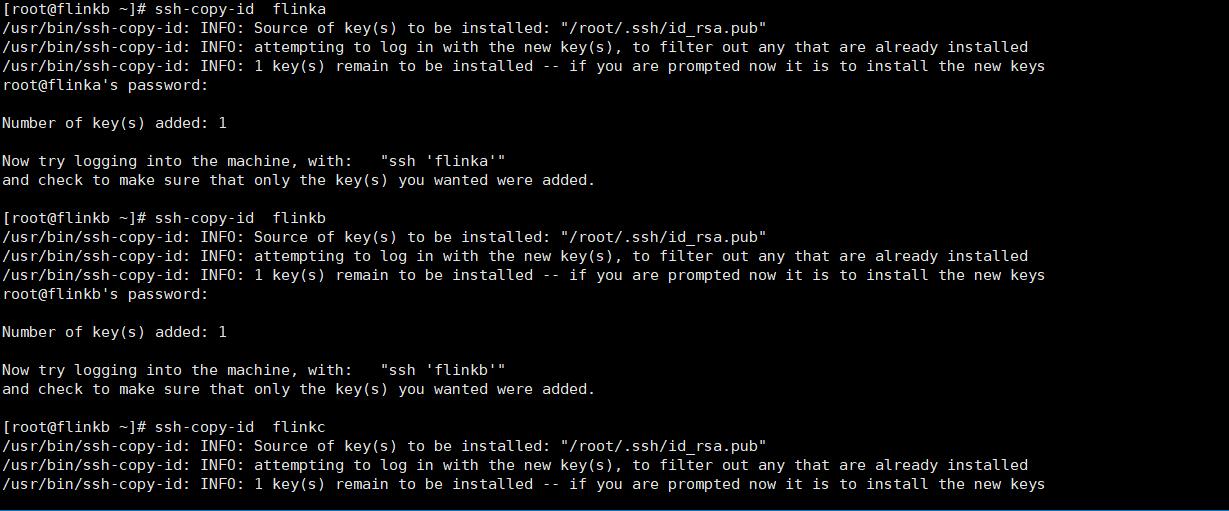

到这里免密登录结束
二、解压hadoop安装包,重命名为hadoop-3.3.0文件夹

1、配置core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-3.3.0/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>flinka:2181,flinkb:2181,flinkc:2181</value>
</property>
</configuration>
2、配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>flinka:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>flinka:9870</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>flinkb:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>flinkb:9870</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn3</name>
<value>flinkc:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn3</name>
<value>flinkc:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://flinka:8485;flinkb:8485;flinkc:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop-3.3.0/journal/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<value>shell(true)</value>
</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 连接超时-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
3、配置yarn-site.xml文件
<configuration>
<!-- 启用日志聚合功能,应用程序完成后,收集各个节点的日志到一起便于查看 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 启动HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 集群的Id,使用该值确保RM不会做为其它集群的active -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<!--指定两个ResourceManager的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!--指定rm1的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>flinka</value>
</property>
<!--指定rm2的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>flinkb</value>
</property>
<!--指定rm3的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>flinkc</value>
</property>
<!-- 配置第一台机器的resourceManager通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>flinka:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>flinka:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>flinka:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>flinka:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>flinka:8088</value>
</property>
<!-- 配置第二台机器的resourceManager通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>flinkb:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>flinkb:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>flinkb:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>flinkb:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>flinkb:8088</value>
</property>
<!-- 配置第三台机器的resourceManager通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>flinkc:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>flinkc:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>flinkc:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm3</name>
<value>flinkc:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>flinkc:8088</value>
</property>
<!--开启resourcemanager自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--指定ZooKeeper集群-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>flinka:2181,flinkb:2181,flinkc:2181</value>
</property>
<!--开启resourcemanager故障自动切换,指定机器-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<!-- 启动NodeManage时,server的加载方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!-- 设置不检查虚拟内存的值,不然内存不够会报错 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>100</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
</configuration>
3、启动Zookeeper
zkServer.sh start
zkServer.sh status
4、启动journalnode服务
4.1、在三台服务器上运行
hdfs --daemon start journalnode
4.2、在主节点flinka上
hdfs namenode -format
启动namenode
hdfs --daemon start namenode
4.3、在其他的节点上同步namenode并且启动namenode
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode
4.4、启动三个节点的datanode
hdfs --daemon start datanode
4.5、测试namenode是否故障转移,kill掉Active的节点,看看是否存在其他的Active
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getServiceState nn3
5、在leader上格式化
hdfs zkfc -formatZK
7、关闭所有的 stop-all.sh
8、开启所有的 start-all.sh
9、测试yarn集群的故障转移是否可用
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
yarn rmadmin -getServiceState rm3
查看哪个是Active 然后Kill掉,看看会不会出现一个Active,若能出现,说明故障转移成功,否则失败!!!!