随着以 GPT 为代表的新一代人工智能技术的出现以及在各行各业的探索与实践。2023年,由映魅咨询主办的DevTalk“开发者说”聚焦在以AI、Metaverse(元宇宙)为代表的技术基础设施以及行业应用中,并邀请在技术、产品、运营等方面的专业从业者进行探讨和分享。

2023年5月26日下午,由映魅咨询主办的DevTalk“开发者说”新一代AI与行业应用趋势第一站在上海举行。 Dmgdata创始人潘佳鸣受邀参与,潘佳鸣是原复星集团智能中台执行总经理,eBay TNS风控组敏捷开发组长。现主要从事用户增长相关项目等,在采用大模型进行自动分析、智慧供应链智能决策的探索以及采用大模型进行定价决策的智能分析探索等方面拥有多年实践经验。
潘佳鸣就新一代AI在物流供应链及价格策略中的应用研究和试点进行了深入的分享与交流。

Dmgdata创始人潘佳鸣
以下是潘佳鸣的分享内容概要:
大家好,很高兴有机会和大家做分享。现在我主要在国内Web2里做企业大模型方案落地,与将大模型用于应用层不同,我们更多地是将大型模型应用于企业中间层。例如医药行业的供应链流程,通过市场情报采集,企业能够了解要开展哪些业务,并需要什么样的物料。在物料方面,企业需要快速调动全球供应链进行配药,订单管理、排期、客户沟通等一系列细节。此外我们还做类似于芝麻信用的信用评级,以确定其业绩和销售对接方。下面给大家分享一些应用案例:
物流供应链及价格策略
这是一家大型制药公司的供应链流程,涉及到投融信息、研究机构、学术机构等,通过市场情报采集和分析决定要研发的药品和物料,通过调动全球供应链对配药进行管理、排期、沟通等。流程非常精细,包括商机、业绩、物料、供应链、SOP流程等,牵涉到整个人货场和订单管理。
某大型制药公司的供应链流程
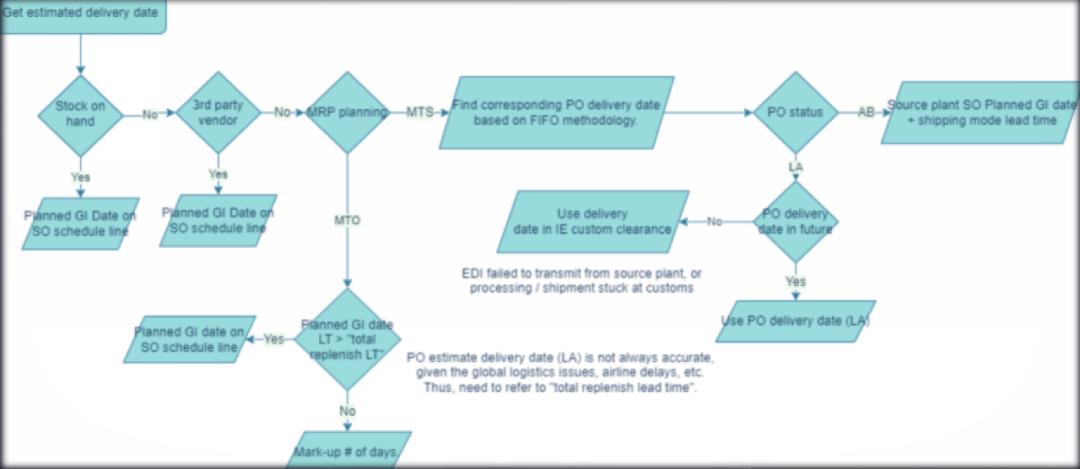
我们使用大模型给这家制药公司打造了一套自动化物流供应链及价格策略。首先,我们用大模型快速建立SOP流程、业务流程和给配交付流程。其次,基于大模型强大的推理能力,快速判断哪些针对性材料需要进行药物配置。这个过程原本需要规则引擎,需要花费很大的维护成本,而现在可以用模型推理能力来做到。这样就能实现销售立刻根据客户要求提供相应的供应链策略和SOP流程,以满足客户需求和自动生成所需的全国调度方案。
物流供应链及价格策略
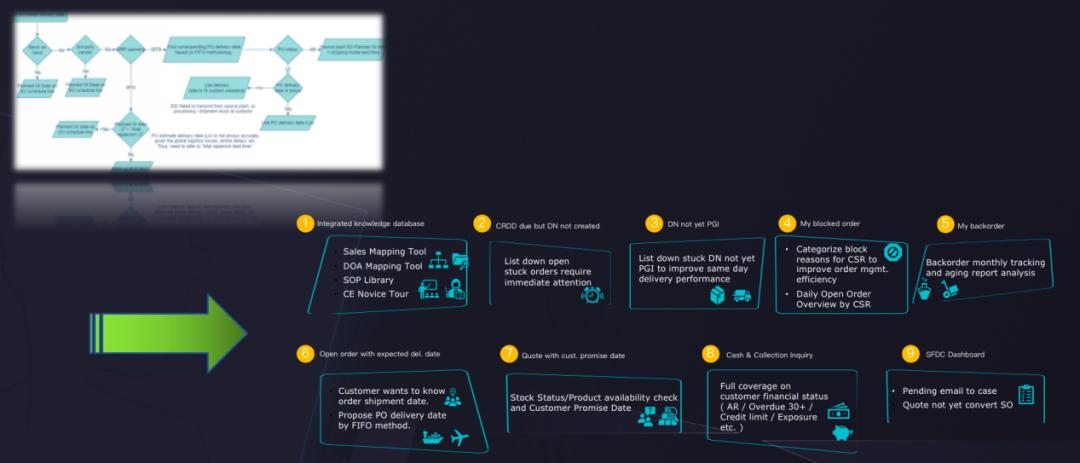
制药公司物流供应链中经常会出现锁单的情况,并对造成锁单情况的原因进行分析,这个过程叫锁单归因。在过去,锁单归因需要大量的人力进行操作并需要监督部门的审批,但现在可以通过大型模型推理能力完成。大型模型能够进行细分类的归类,帮助企业快速出具最佳的分析结果。
锁单摘要及归因
此外,在物流中涉及到大量的非结构化数据,例如票据和行文等,需要进行归因分析。原来这些工作都是由规则引擎或审计团队完成,但现在可以通过大型模型推理能力进行处理。这种方法能够快速锁定问题节点的位置,提高归因分析的准确性。
电商全渠道价格策略方案及消费者聆听
在电商领域中,有一家合作伙伴致力于做全网电商情报数据业务,他们主要做两件事:第一是收集企业的ToC(即面向消费者的业务)相关数据。比如拆分业务中相关的商品在全网电商的价格数据等,通过价控策略等手段进行监控;第二是将这些数据进行分析,以实现定价策略和新品研发的决策。他们正在尝试使用大模型,为客户提供价格策略和研发新品的决策支持。
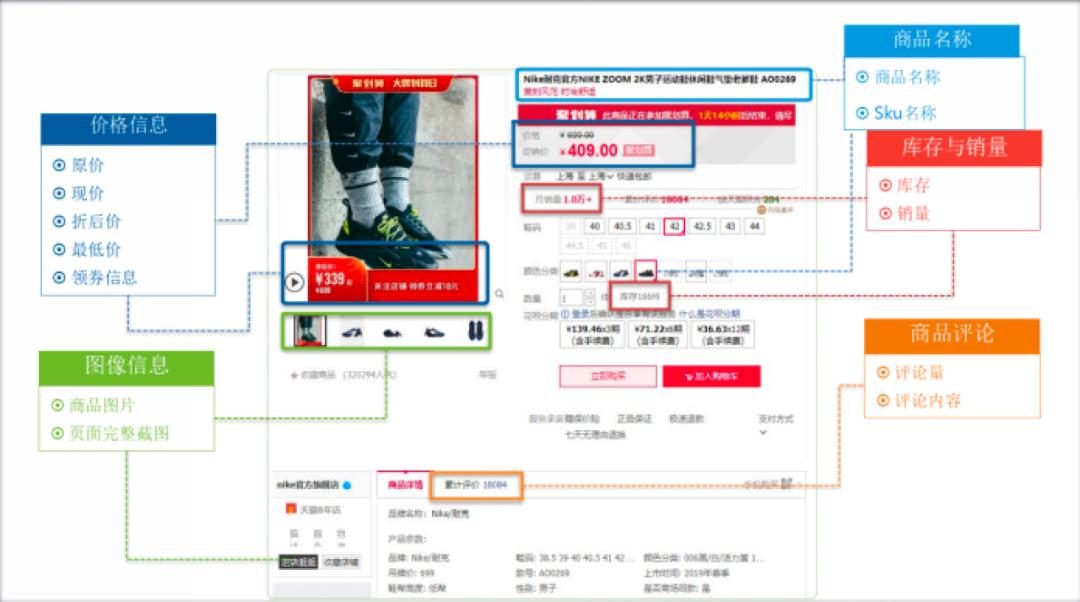
某全球电商情报数据方案业务场景
我们为他们提供了电商全渠道价格策略及消费者聆听解决方案。方案的优势在于:
第一、将市场数据喂给大模型进行分析,以确保结论有数据依据。第二、提供画图功能。 将大模型的能力与垂直行业的数据和全网电商数据相结合,以提供分析类需求和预测可能的爆品趋势,包括价格、SKU和店铺等信息,通过分析市场趋势来推导消费者对当季产品的喜好。

电商全渠道价格策略方案及消费者聆听解决方案
通过应用大模型,我们不仅可以提供价格监控和破价提醒等传统服务,更可以为客户提供基于行情数据的运营策略分析和推理服务,挖掘出市场中的潜在商机。
提供模型本地化部署能力
我们还可以为合作伙伴部署本地化的开源及国产大模型,以满足其员工对大模型的应用需求,不再需要购买外部账号,以降低内部数据泄露的风险。
企业可以将海量数据与大模型的推理能力相结合,形成自己的推理能力解决方案,包括部署小模型服务于其垂直能力范围。此外,企业可以拥有和ChatGPT聊天的功能,也可以给ChatGPT嵌入其他功能,如语音和邮件服务等。三个主要应用场景为:内部大模型推理能力、API数据服务策略、以及中小型客户使用场景方案落地。
我们正在与一些企业进行试点合作,并总结了用于部署大模型的工作流程。首先使用开源模型进行学习,并向合作伙伴介绍各个模型的特点,以便进行选择。接下来我们会对数据进行标注和精标,包括通用行业数据和标准化数据的自动标注系统,以及精标数据。使用这些数据,再与企业自己的数据系统结合,形成一个基础合成的模型。 我们帮助企业将底层和云端的大数据系统整合到大模型推理能力提升之中,为了提高响应速度,可能需要使用GPU和矢量数据库以提高效果。

大模型内部使用场景
另外,我们预判未来 数据审计在国内将会越来越重要 ,当下我们会从两方面做支撑。 第一,提供定向审计题库进行模型测试,保证企业的模型对这些题库能够考试通过。第二,使用指令集和停用词库过滤出企业内部无法公开的敏感信息。 例如药企无法公布药名或者药的品名。模型数据出来时,会在上面加一层规则引擎,确保合规成本有所考虑。此外,还包括MA和定期的数据维护和持续迭代。企业自身的数据会不断增加,还需要与企业现有的系统进行集成,比如智能绘画机器人、销售管理系统的议事决策系统、BI中心和EHR系统。我们使用一个部署框架进行集成,将大模型和企业本身应用进行接口集成,解决企业内部的客户系统对接问题。部署框架基于LangChain设计开发,采用容器式开箱部署。
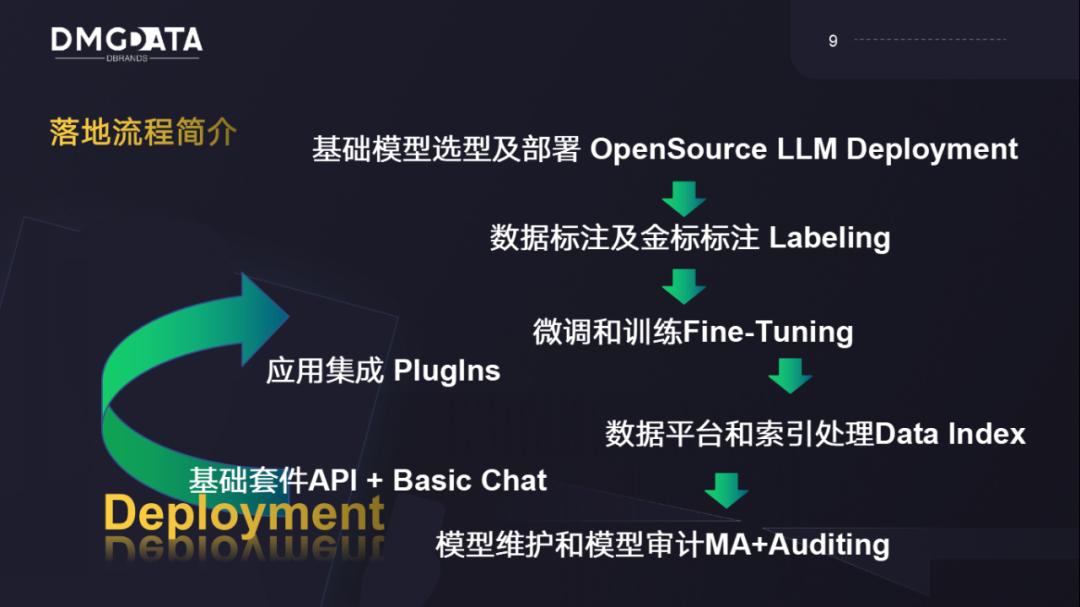
数据维护和数据审计解决方案
我们的目标是帮助企业快速应用大模型能力,同时解决数据审计及内外部数据处理等方面的问题,提供完整的落地支持方案,使企业能够更好地采用,管理和利用其数据,实现大模型时代的AI工业化赋能。