目标
我们如何定义配置文件?一个简单的定义是,个人资料是当前登录的用户的账户。但是如果我的家人正在使用我的帐户,他们的浏览行为可能与我的有很大不同。我们面临着个性化他们当前浏览体验的挑战。这种设计是朝着在同一用户帐户中创建和管理多个配置文件并允许人们选择各自的配置文件并个性化他们的浏览体验的能力迈出的一步。
配置文件系统的另一个目标是提供尺寸和适合度以及美容配置文件作为配置文件级别的一项功能,其中一个帐户可以有多个配置文件,一个配置文件可以有多个作品集,如美容作品集、尺寸和适合作品集,并且在作品集内,可以使用许多属性来个性化用户浏览体验。该项目还将解锁许多高潜力的故事来迎合并提供更深层次的个人资料级别的能力,为用户带来独特的体验,例如美容属性,如基于皮肤属性的产品推荐,能够记录皮肤随时间的个人资料,并构建皮肤轮廓图等
什么是档案系统?
配置文件系统 是一组子系统、服务和指南,用于管理并提供管理配置文件和根据当前选择的配置文件个性化用户体验的能力。我们已经将配置文件系统抽象为多个子系统或微服务,下面是理解整个配置文件系统的非常高层次的图表。
系统边界
Flock 是负责创建、管理和提供配置文件及其属性的主要服务。
Flock 的高级范围
- Flock 可以明确地向用户询问和提供属性 ——Explicit attributes
- Flock 还可以隐式存储和提供属性—— 派生属性
- 由其他服务识别的唯一配置文件属性,可以通过 Flock 存储和提供—— 第二手属性
什么超出了 Flock 的范围?
- 通过数据科学模型预测属性值超出了本系统的范围。
- 此数据的任何分析或批处理都将卸载到 Myntra 数据平台。
- Size & Fit 特定数据和基于 Size and Fit 的建议不在本设计范围内。
- 如果我们向用户询问更多领域特定的问题,该数据将保留在该领域特定的服务中,但是如果有任何可以属于配置文件的唯一属性,它将转到 Flock。
要求
功能要求
- 在用户帐户下创建配置文件。
- 提供配置文件和帐户之间的关系。
- 动态定义新的配置文件属性。
- 支持所有属性中的隐式和显式值。
- 支持属性级别的 值过期。
- 本机支持不同类型的属性,如布尔值、数字、日期、枚举等。
- 提供用户路径和非用户路径的属性更新接口。
- 隐式或显式来源属性的冲突解决方案,并向客户端提供抽象的配置文件属性值。
- 具有阈值的隐式驱动属性值的支持置信度分数。
- 使用基于动态置信度阈值的案例级属*服务性**。
非功能性需求
吞吐量
吞吐量预期可以从 300k RPM 到 1M RPM 不等,并且系统应该可以水平扩展以支持更高的吞吐量。
延迟—— 预期的 p99 百分位数延迟应小于 100 毫秒
数据要求—— 我们估计大约有 1.2 TB 的数据,预计将得到 3-4 倍的支持,以便该系统至少在未来 5 年内可持续发展。
高层设计
设计目标
在高层次上,我们有 2 个目标要实现,管理配置文件的能力,询问和服务多个配置文件属性的能力,我们还应该能够对属性进行分组,我们应该能够动态适应产品需求以创建新的配置文件各种用例的属性。
设计挑战
当我们想到向用户询问一个属性时,我们只有一个答案很简单,但是如果我们想导出该问题/属性的答案怎么办,例如,性别也可以被询问并可以导出,使用数据,使用各种模型。由于属性可以变成多个,因此选择服务哪个属性变得模棱两可,因为答案可以是多个,而且当另一个概念出现时,称为冲突解决。现在的挑战是,如果我们还计划在服务属性时解决冲突,那么服务扩展将是一个挑战。
高层次的挑战是
- 承载多个属性
- 解决冲突
- 具有上述两个考虑因素的数据建模
- 系统缩放
经过一番头脑风暴后,我们意识到使用一个系统解决所有问题是不可持续的,然后我们开始使用第一个设计原则来分离职责。应该有一个服务(S1),其职责应该是从多个来源捕获数据,这将是一个读取密集型系统,它也可以拥有所有权来计算大量数据集合并发布属性的最终值。并且可以有另一个服务(S2),它将使用从 S1 发布的最终值并存储以通过 API 提供服务,基本上是读取密集型路径。如果我们这样想,那些系统就会变得简单、职责分离并且在定义的边界内可扩展
S1我们叫 龙
我们称之为 S2 的是 Flock 。
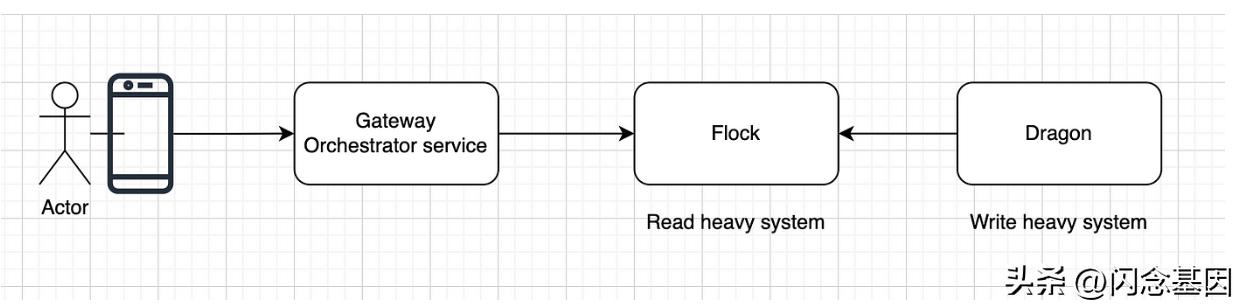
龙的责任与界限
- Dragon 将成为允许多个来源发送数据的系统,例如尺寸和合身度、MDP、产品查找器等,并存储属性的所有可能值。
- 存储在 Dragon 中的属性值不会被直接提供
- 它将有一个冲突解决算法来计算属性的最终值
- 属性的值也可能有 置信度 ,因为值的置信度可能不是 100%
- 属性计算值可以过期,所以也可以有 衰减 机制
- Dragon 不会直接通过 API 提供数据
- 它不会做 MDP 正在做的事情,比如存储大量记录和计算
- 它不会存储负责存储在域特定服务中的内容,例如 size n fit
- 当我们开始使用数据科学来派生各种属性并且需要这些属性来服务多个用例时,Dragon 将发挥更好的作用
Flock 的责任和界限
- Flock 应该有能力创建/管理用户的配置文件,通过为配置文件公开 CRUD API
- Flock 应该保留 Explicit、Derived 和 2nd hand 属性,并服务
- 在 Derived 的情况下,Flock 将存储属性的最终计算的唯一值,而不是属性的多个值
- Flock 将存储显式属性,通过配置文件流直接向客户询问的问题,因为显式属性将比隐式属性具有更高的优先级,因此不需要发送给 Dragon 并通过冲突解决,因此 Flock 可以直接存储和服务它
- Flock 必须非常小心地决定什么是配置文件属性,什么不是配置文件属性
- Flock 还应该存储和提供那些可以唯一定义用户行为的第二手属性,并可用于为不同的用例提供服务,例如腰围尺寸。
- Flock 数据也应该复制到 MDP,这样我们就可以运行查询并构建多个产品功能,如个性化、配置文件理解等。
- 属性可以组合在一起,我们可以称之为桶,我们应该能够通过 API 提供桶级数据
- 我们永远不会通过将 API 中的动态输入作为属性列表来提供属性,它只能通过 bucket 来完成
- 桶不会有桶。我们最初想到了它,但后来管理起来在技术上变得复杂,没有任何额外的优势,所以我们只坚持一个级别。
- 桶定义和端到端管理应该是管理员的责任。
在将这些职责分离为 2 个不同的服务后,它们可以独立扩展。
高层设计图
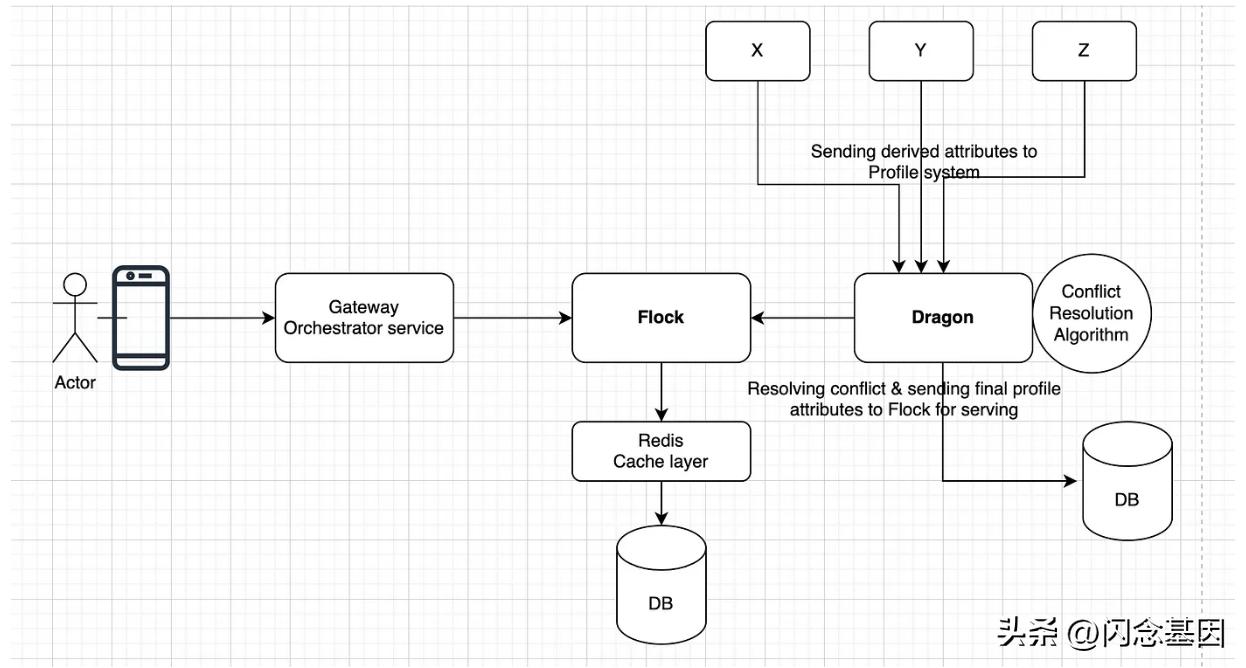
Flock 是服务层,它可以托管配置文件和属性,它具有持久层,我们在其中使用 MongoDB,并且为了扩展吞吐量,它还具有 Redis 缓存层。
Dragon是一个写密集型系统,它可以接收来自多个其他系统的数据,进行冲突解决并将数据发送给Flock进行服务。
高级设计——配置文件系统的集成视图
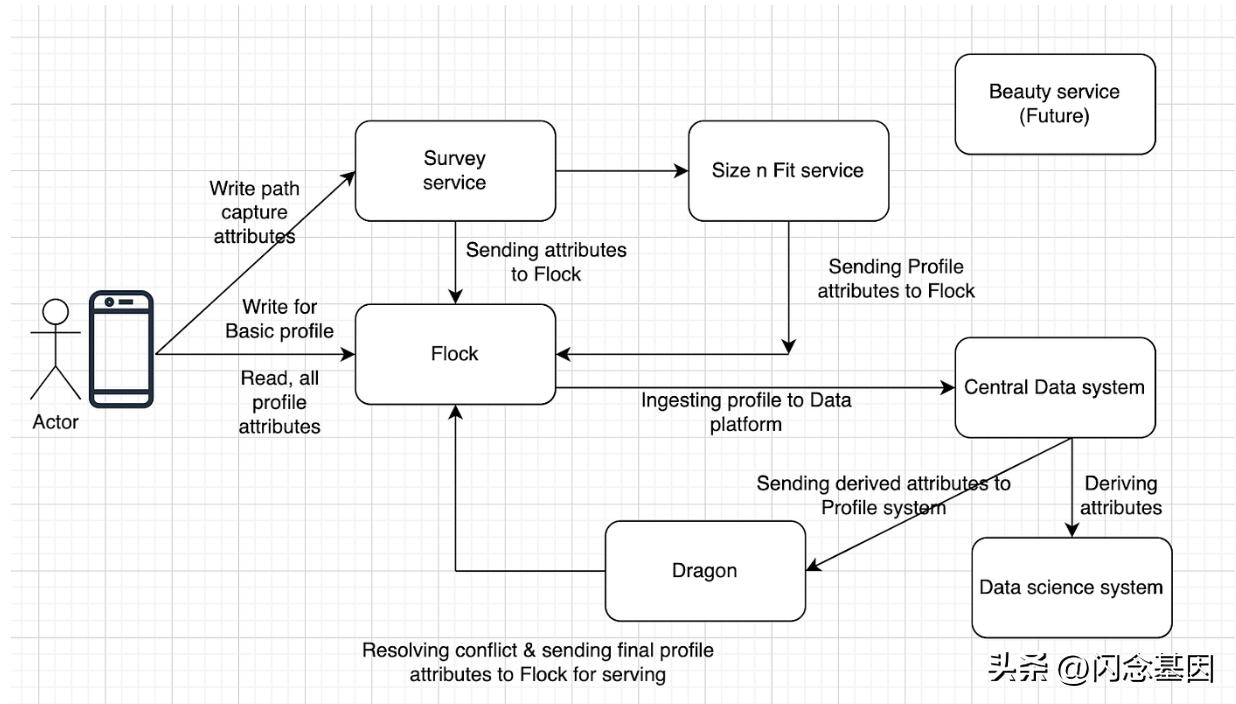
配置文件系统是对配置文件和属性管理的综合理解,上图提供了如何处理配置文件和属性的整个生命周期的视图。
Flock 是一个中央微服务,负责托管配置文件和属性,但还有许多其他服务将在构建整个配置文件系统中发挥至关重要的作用。
调查服务将拥有向用户提出的问题并持久化其答案,问题可以设计为表单或调查,最后调查将与配置文件属性相关的问题和答案发送给 Flock。
Size and fit 服务,将拥有size 和fit 特定域属性,我在本文档中解释了域特定属性和profile 属性的区别,查看“Profile 属性和非profile 属性的区别”部分。
美容服务将是另一种拥有美容特定领域属性的服务,与 Size 和 fit 相同,但它可能具有不同的结构和用例,因此我们定义了不同的服务。
中央数据系统会摄取flock profile属性,也会通过不同的系统摄取其他profile属性,最终将所有派生的属性发送给Dragon,Dragon最终解决属性值的冲突并发送给flock进行服务目的。
底层设计
数据模型——需求
数据建模是这个项目中最复杂的问题之一,让我们先看看对数据建模的高层次需求以及解决它的不同方法。
- 对于属性,我们没有所有属性的固定类型。
- 我们需要对属性的 User_ID 和 Profile_ID 进行二级索引。
- 根据数据来源,值的类型可以是显式的或隐式的。
- 对于每个属性,我们可以有多个来源。龙服务将解决冲突。并存储最终输出。
- 在解决了最终输出的冲突之后,我们必须将数据存储在同一个地方,这个地方也可以在中央数据系统中使用。
- 我们不想每次将新属性加载到系统时都更改任何代码。
方法 1(配置文件和属性隔离)
集合是
Profile_attribute_meta — 包含元数据、作品集关系等。
User_profile — 包含个人资料基本数据,如姓名、关系、默认值(是/否)
User_profile_attribute — 包含所有属性(显式和隐式)— 将用于个性化
- 对于每个用户,以下集合 (b,c) 中将有一条记录
- 每个字段只不过是一个属性,例如性别、亲和力(姓名、关系和个人资料图像除外)
- 置信度——每个属性、每个来源都有一个分数
- Expiry——每个属性都有一个名为 created_at 的字段,它将与该属性的 meta_data 进行比较,并评估该属性是否已过期
- 在 User_profile_attribute 中,显式属性和隐式属性是不同的记录——考虑到隐式数据可以使用 mongodb 特性自动过期
- 显式属性将是一个对象,而隐式属性将是一个对象列表——当我们起草第一个版本时,我们正在考虑显式将始终覆盖前一个,而隐式可以是多个。
方法 2(显式和隐式的两个不同集合)
集合是
Profile_attribute_meta — 包含元数据、作品集关系等。
User_Profile_attribute_explicit — 包含明确的属性
User_Profile_attribute_implicit — 包含隐式属性
User_Profile — 包含与配置文件相关的基本信息,如默认配置文件
- 对于每个用户,以下集合 (b,c,d) 中将有一条记录
- 如果用户是新用户,那么 Profile_attribute_implicit 中不会有任何数据,由 Data science team 预测
- 每个字段只不过是一个属性,例如姓名、性别、亲和力、关系
- 置信度——每个属性、每个来源都有一个分数
- Expiry——每个属性都有一个名为 created_at 的字段,它将与该属性的 meta_data 进行比较,并评估该属性是否已过期
- 显式属性将是一个对象,而隐式属性将是一个对象列表
方法 3(单个属性和列表属性的分离)
- 集合是
- Profile_attribute_meta — 包含元数据、作品集关系等。
- User_profile_attribute — 包含一个属性的单个对象
- User_profile_attribute_list — 包含一个属性的对象列表
- 对于每个用户,以下集合 (b,c) 中将有一条记录
- 对于读取路径——我们将使用 User_profile_attribute
- 数据科学团队将写入 User_profile_attribute_all 表
- 解决冲突的进程会有一个,从User_profile_attribute_all中读取并得出一个值写入User_profile_attribute
- 每个字段只不过是一个属性,例如姓名、性别、亲和力
- 置信度——每个属性、每个来源都有一个分数
- Expiry——每个属性都有一个名为 created_at 的字段,它将与该属性的 meta_data 进行比较,并评估该属性是否已过期
- 在这两个集合中,不同的属性将保存在不同的文档中
最后进近
- 集合是
配置文件属性元
配置文件存储桶元
轮廓
配置文件属性
配置文件隐式属性
- Profile Bucket Meta 是属性的集合,不鼓励单属性读写,只能通过buckets实现。
- Profile 集合将仅包含 Name 和 Image,因为它们是固定信息,不用于行为跟踪、预测或个性化。
- Profile attributes 是存储属性名称及其值的集合,值可以是单个值或列表,性别,亲和力和所有可能的个人资料信息都将成为该集合的一部分。
最终数据模型——设计细节
我们将如何支持新属性的加入? 我们使用了两种不同的集合属性元数据和属性桶来管理元数据。配置文件属性元数据包含属性的定义。如果我们想引入一个新的属性,我们可以简单地将它添加到这个集合中,并且对于该属性读/写将无需任何代码即可工作。
collection_name: “Profile attribute meta” 为了组织属性的层次结构,我们正在维护存储桶。
collection_name :“配置文件桶元”

一个桶可以包含一组属性,所以桶是一个平面结构。配置文件存储桶元数据包含存储桶信息,存储桶的定义、取消定义和重新定义将在此集合中发生。我们设计为不提供写入/读取属性级别数据,我们不想提供这种灵活性,以便我们可以控制流量模式并在限制范围内很好地工作以实现更好的性能。也许基于最易访问的桶或桶优先级,我们可以选择一种缓存策略,如果没有桶作为紧密边界,这是不可能的。
属性详情
出于不同目的,属性数据保存在 2 个不同的集合中。显式数据目前只有一个值,而隐式数据可能有多个值,因此将它们存储在不同的集合中。

分辨率—— 也可以基于分数、时间或任何其他逻辑发生,所以只提及该字段中的分辨率逻辑
在 Flock 系统中根本不需要配置文件隐式属性,而在 Dragon 服务中则需要它,但我们正在讨论架构以明确数据模型以构建整个配置文件系统。如果您查看下面的模式,显式属性将具有一个值,而隐式属性将始终具有一系列值。
集合:“配置文件隐式属性”
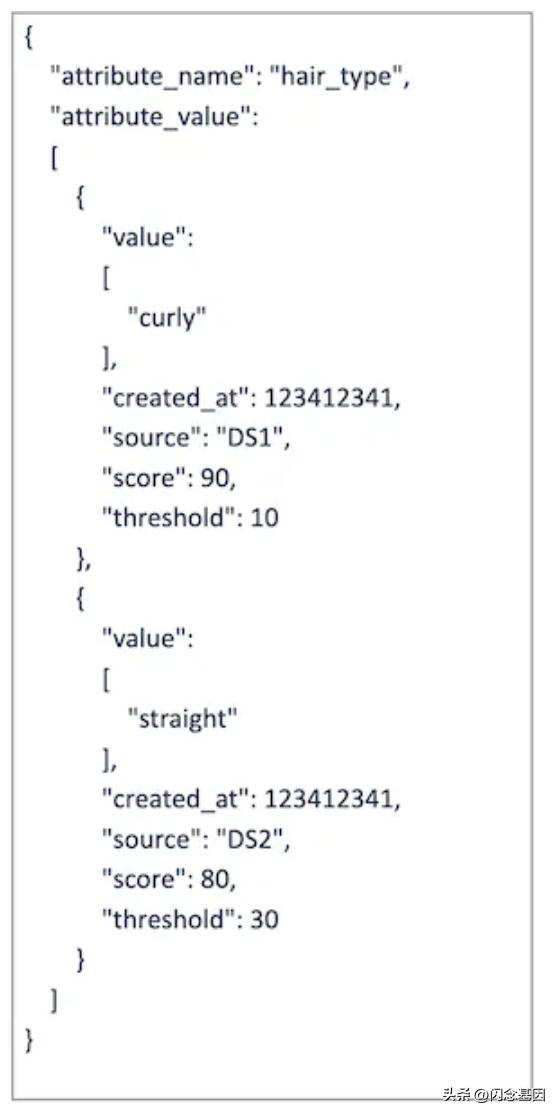
来源、分数、阈值和到期字段的定义
不同来源的每个属性都有一个分数,来源可以是数据科学派生的,在这种情况下,分数可以是精度/召回类型的值,来源可以是基于用户购买的样式的分析,同样,一个分数将是与之关联的是,源也可以通过其他一些产品用例显式输入,比如有人正在触发一组问题并提供产品建议,也许他们也可以将数据发送给 Flock,因此该模式提供了保持相同的不同值的能力通过不同来源的属性,每个来源都可以有它的相关分数。
Expiry—— 每个属性都有一个名为 created_at 的字段,它将与该属性的 meta_data 进行比较,并评估该属性是否已过期
为什么我们选择将性别保留为属性的一部分而不是个人资料?
个人资料收集只是个人资料的创建,例如姓名,我们也将图像视为个人资料的一部分,图像也可以是头像或真实图像。配置文件的属性可以是性别、品牌亲和力、价格亲和力等。性别不是配置文件,因为性别意味着我们需要开始个性化用户体验。如果我们将性别保留在属性中,那么理解数据模型会很复杂,我们将使用它来个性化用户体验。然而,这种隔离仅在数据层上,在前端我们有性别,因为它也是配置文件创建的一部分,因此处理配置文件和性别持久性是在 API 级别完成的。
属性类型
我们将属性分为以下几类
- 明确的属性——Flock 可以明确地向用户询问和提供属性
- 隐式属性
派生属性——Flock 也可以存储和服务隐含的属性,Dragon将拥有它,并解决冲突并将其发送给Flock进行服务。
第二手属性—— 由其他服务识别的唯一配置文件属性,可以通过 Flock 存储和提供,例如调查服务正在提问并发现这是配置文件属性,在这种情况下,调查直接发送给 flock,是第二手属性,它不是通过 Dragon 发送的。
显式属性将通过 Flock API 直接写入和读取,而隐式属性将有不同的写入和读取路径。
缓存
为了服务于性别等高流量用例,我们通过缓存来提供服务。对于缓存,我们探索了redis和aerospike内存缓存,aerospike和Redis都可以在很小的延迟下获取数据,所以让我们看一下它们的比较视图。
Redis 与 Aerospike 的优缺点
- Redis 是较旧的技术,redis 的社区支持要强大得多。
- aerospike(社区版)中的簇大小受到限制。在 Redis 中,集群的大小可以大得多。
- 他们几乎同时在客户端服务的延迟。
- 随着新版本的发布,aerospike 停止对旧版本的支持,不支持不同版本的集群。
- Aerospike 有 bin 的概念。它不会使用任何哈希数据结构。
- 在 aerospike 中重新分片总是很简单。我们必须添加一台主机。它将负责重新分片,对于 Redis,添加新节点需要一些停机时间。
Redis 看起来很合适,因为我们正好需要缓存,而且最近的数据量可能不会增长到很大,记住以上几点,我们决定使用 Redis。
什么都去 Redis
- 个人资料数据(姓名、个人资料图片)
- 属性
- 默认配置文件
Redis 架构
- 轮廓
Redis 密钥:<前缀>:<用户 UUID>
值:HSET,配置文件 UUID 作为哈希键。
2.属性
Redis 键:<prefix>:<Profile-UUID>
Value:以key为属性名,value为属性值的HSET。
3. 默认配置文件——Redis 键为 User_ID,值是默认配置文件的有效负载,包括 Profile_ID。如果我们允许更改默认配置文件,这可能会导致一致性问题。目前,默认配置文件更改不是我们拥有的模拟的一部分。
profile属性和非profile属性的区别
Flock 应该存储所有的配置文件属性,或者一些属性或一些属性,哪些属性存储哪些不存储,为什么,这个清晰度是超临界的。如果我们不定义它,它将成为一个通用系统来转储和提供任何数据,最终变得难以管理,并且无法扩展。
让我们考虑用户位置,我们认为它应该在 Flock 中吗?从技术上讲,它看起来很简单,有许多个性化用例需要用户或配置文件的位置,而 Flock 应该为它提供服务,但如果我们这样想,为什么不存储和提供用户支付选项,也许还有订单,或者也许愿望清单也是,所以我们需要非常清楚地定义它。
任何可以唯一标识配置文件行为且不特定于某个域的属性都可以认为是通过 Flock 存储和服务的,这些属性可以称为配置文件属性。
如果我们想到位置,理想情况下应该去位置服务,因为在位置数据之上,有人可以要求制作更多的 API 和功能,比如给我用户的等级或密码,基于密码,给我前 1000用户,所有这些功能都不能在 Flock 中构建,不是吗?所以很明显 Location 应该在位置服务中存储和服务。
现在考虑 Size n Fit 属性,就像我们要求用户提供上衣尺码信息一样,在这种情况下,我们通过自己的方式询问,因为它的产品需要,请看下面的截图。
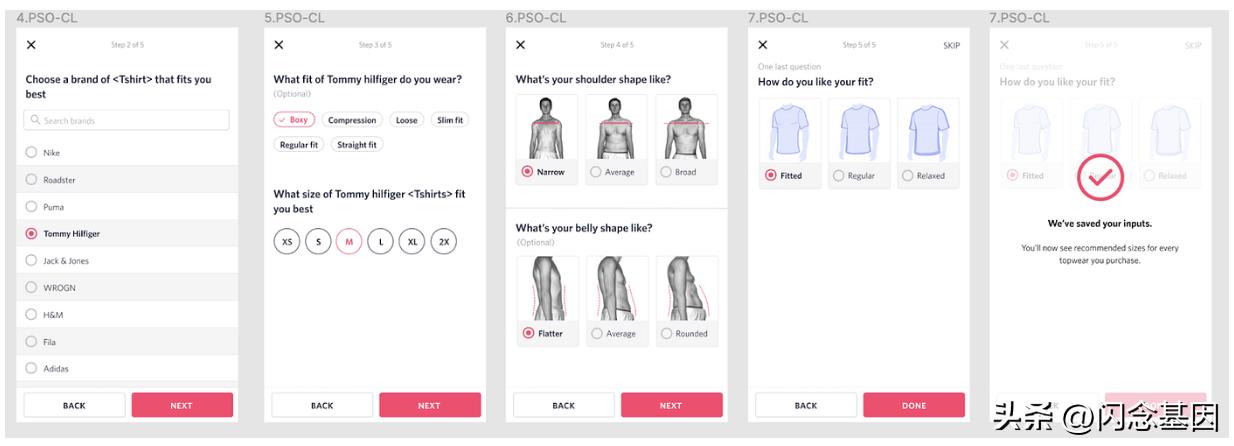
现在的问题是,我们是否应该在 Flock 中存储和提供所有这些数据,甚至是否在 Dragon 中,基本上是一个配置文件系统?
应用我们在位置数据的情况下应用的相同逻辑,因为这些是非常具体的 Size n Fit 域的信息,我们应该将它们存储在 SizeNFit 服务中,而不是在配置文件服务 (Flock) 中。因为基于特定领域的信息,产品会想要构建自己的能力,而构建所有这些能力将不会是 Flock 中的可扩展性,因此从现在开始只定义隔离,将为架构提供更好的方向。
因此, 那些非常特定于业务领域的属性应该转到特定领域的服务中,而不是在 Flock 中。
有一种可能性是特定领域的服务可以有一个通常不会经常改变的属性,它可以帮助丰富用户的个人资料,也可以去 Flock,我们称它们为第二手属性,例如腰围尺寸, 胸围尺寸,由 SizeNFit 服务询问并存储,但 Flock 也可以存储这些属性并提供服务。
存储第二手属性的目的是
- 个人资料完整性,我们将了解更多关于个人资料的信息
- 可以使用 Flock API 构建一些产品功能,如推荐、通信等。(注意——如果产品需要特定于该领域的更深层次的数据,我们最好使用特定于领域的服务,而不是 Flock)
看看下面的截图
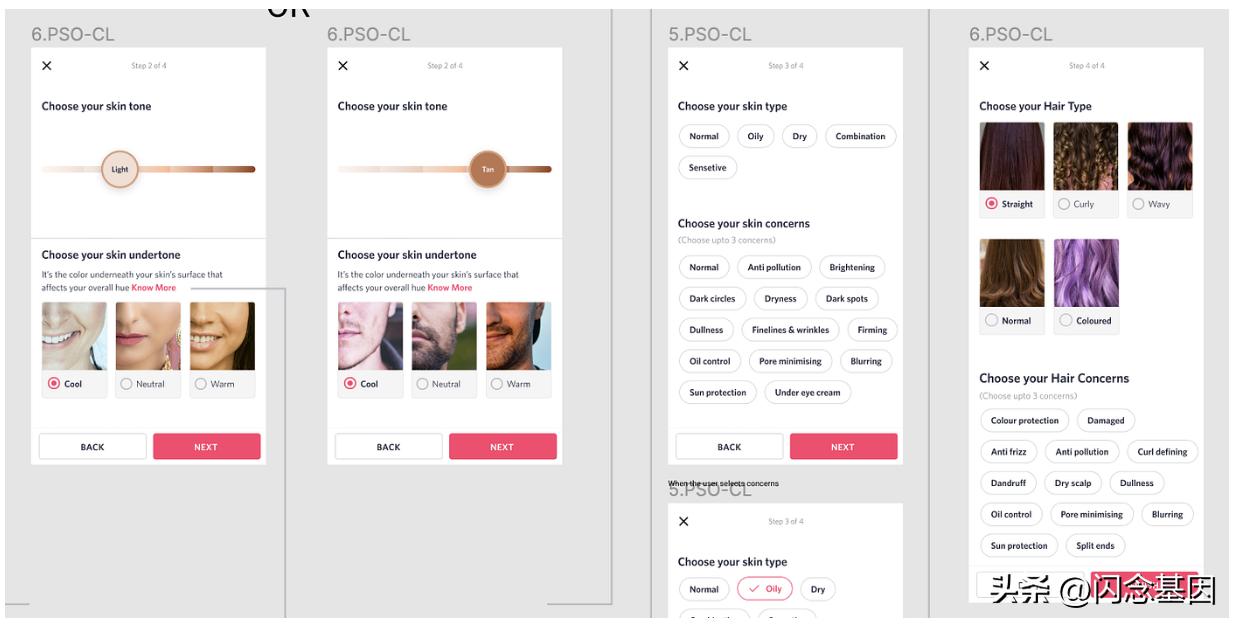
这都是特定于美容作品集或美容档案的,那么这些数据应该去哪里呢?
再次应用相同的原则,如果信息是非常具体的美容,理想情况下应该去美容服务(或 BPC 服务),但是那些可以是个人资料独有的属性也可以在 Flock 中存储/提供。例如皮肤类型,通常不会改变,所以可以去 Flock,但皮肤问题会随着时间的推移而变化,我们可以创建皮肤数据的时间线视图并创建产品功能,为用户提供更好的皮肤问题体验,皮肤问题等,所以信息应该去美容服务。因为,到目前为止我们还没有 Beauty 特定的用例,这意味着这些属性将非常独特并且除了存储和服务之外没有任何其他功能,我们选择仅将它们临时存储在 Flock 中。但是任何下一个针对 Beauty profile 的功能开发,我们将创建 Beauty 作为一项新服务并存储在那里。这创造了一个美丽的思维过程和路线图,当产品进化时,技术将确切地知道如何扩展它,因为我们已经考虑过了。
学分
Project Flock 由一群工程师开发,每个人的贡献都受到高度重视,因为它是在充满热情和技术深度的情况下开发的。
作者:Prashant Kumar
出处:https://medium.com/myntra-engineering/how-we-designed-a-multi-profile-system-b846ff5752d6