
之前方案
关注GPT的人应该都知道,之前有很多教程,类似“一分钟教会你使用ChatGPT打造PPT”,很适合非技术人员,抽象流程大概就是这样:

简述就是:
- 与ChatGPT对话
- 生成带有Markdown源码大纲的回复
- 从回复中获取源码
- 粘贴到在线工具网站
- *载下**PPT或PDF
无需多步的方案
其实上面的方案我也强调说到,那是给非技术人员用的方案,逻辑很简单,就是比较麻烦。
而技术从业者是有能力将其中第3,4直接自动化掉,再加上ChatGPT的对话能力早就被技术通过GPT3(gpt-3.5-turbo)实现了,所以可以精简为这样(用户视角):
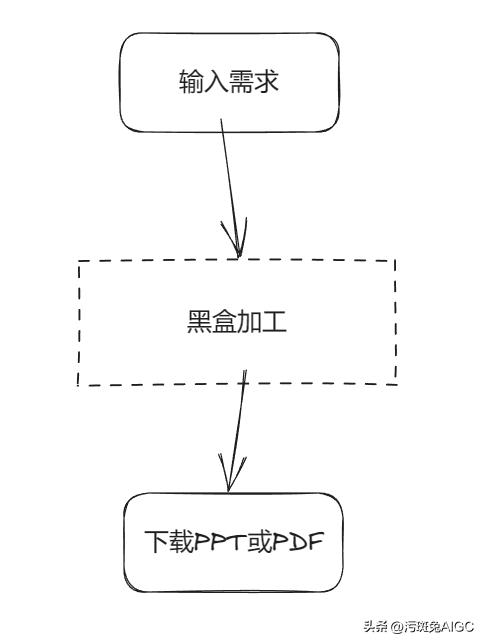
简述就是:
- 用户输入自己的PPT要求
- 等待(黑盒加工)
- *载下**PPT或PDF
由于等待是逻辑上必须的,无外乎时间长短问题,所以对于用户来说,就是输入+输出,没有什么复制粘贴,什么Markdown之类的额外认知负担。
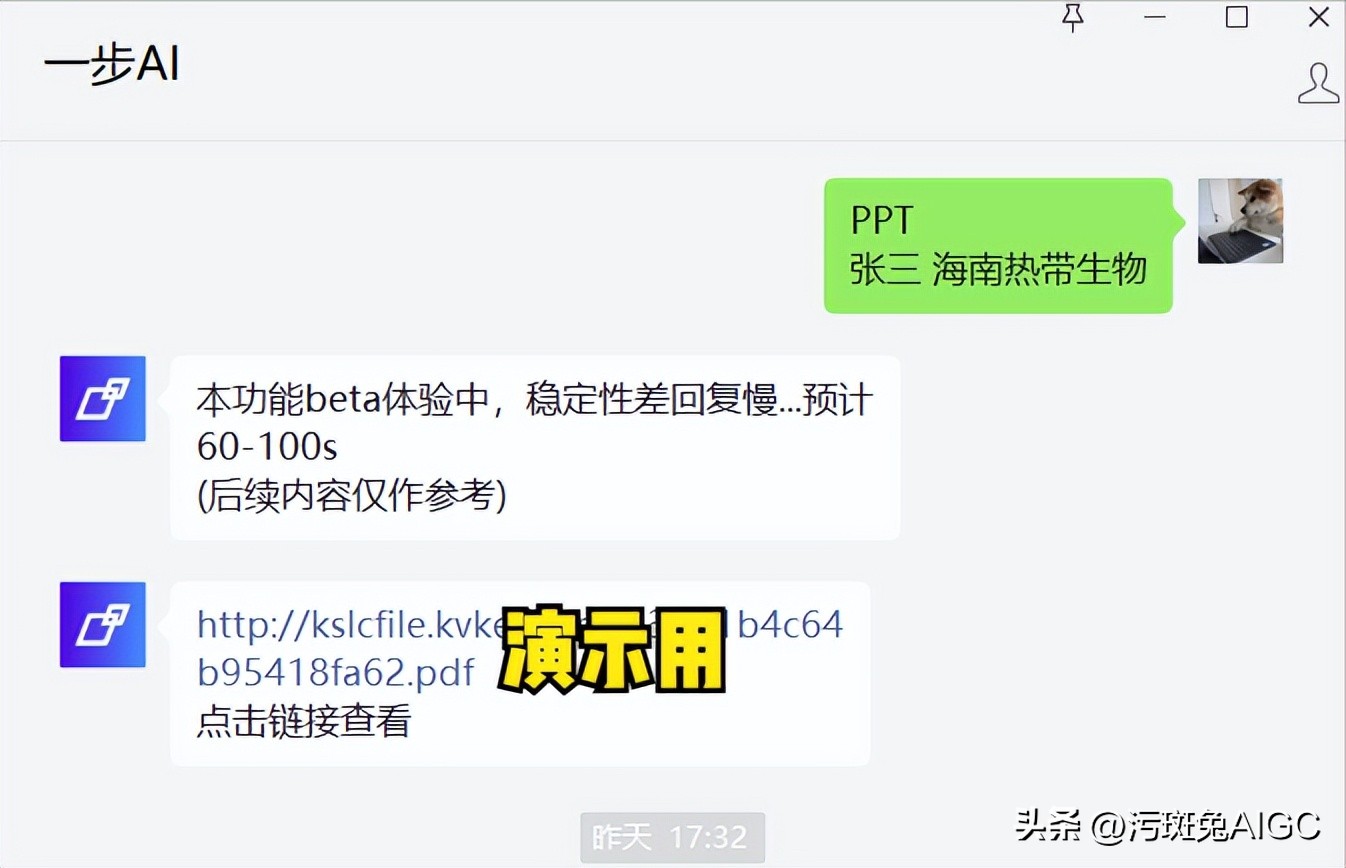
实际使用就是这样(我们的Demo):
具体技术实现
不关心具体实现的可以溜啦。
这里的表述将脱离实际的应用场景,以抽象描述为主,辅以关键代码说明:
- 通过表单也好,通过解析也罢,获取到用户的用户名与主题
- 将数据通过GPT转一下,让它按照我们想要的解析格式输出
- 将输出的Markdown核心内容转给生成器
- 生成器自动运行,并将结果上传到远程文件上
- 最终返回给用户一个可用的*载下**链接
下面逐步解析:
第一、假设让用户按照“ppt+换行+用户名+空格+主题”方式输入
那么就可以这样解析
let [author, name] = ask.replace(/^ppt\n+/i, '').trim().split(' ')
第二、通过类似的模板让GPT给你生成PPT相关的Markdown输出
我的名字叫做 ${ author } ,帮我制作一篇内容为《 ${ name } 》PPT,要求如下:
第一、一定要使用中文。
第二、页面形式有3种,封面、目录、列表。
第三、目录页要列出内容大纲。
第四、根据内容大纲,生成对应的PPT列表页,每一页PPT列表页使用=====列表=====开头。
第五、封面页格式如下:
=====封面=====
# 主标题
## 副标题
演讲人:我的名字
第六、目录页格式如下:
=====目录=====
# 目录
## CONTENT
1. 内容
2. 内容
第七、多个要点时要分多个列表,列表页格式如下:
=====列表=====
# 页面主标题
1. 要点1
要点描述内容=====列表=====# 页面主标题2. 要点2要点描述内容第八、列表页里的要点描述内容是对要点的详细描述,10个字以上,50个字以内。
这里注意,这段话是不可靠的(从知乎抄的,如有侵权请联系删除),但是可以在Demo上用。
拿到数据后记得把一些非Markdown的东西删掉,里面包含Markdown与非Markdown,比如“====”这种,就是一些在线工具要用的,而我们选用的生成器根本用不到,但是却可以给我们当做占位符。
可以通过这样的代码删掉
let result = answer.replace(/=+封面=+\n/, '').replace(/=+.+=+/g, '\n---\n')
第三、将输出内容交给转换器
这里牵扯到两个问题,选型与并发。
我们是这样考虑的,选型尽量支持原生Markdown,不要让GPT再去限制生成Markdown里面特定的东西,所以我们选用了开源的Slidev。
而并发,我们用了一台现成的服务器跑,简单测试就目前来说足够用,这个得结合实际情况,不要盲目参考。
这一步没什么好说的,由于我们是另外一台机子,所以走了HTTP,把消息发了过去。
第四、生成器自动运行,并将结果上传到远程文件上
这一步相对来说有一些技术挑战,你得知道一些OS操作,比如文件读取与写入以及删除、Shell脚本的运行等。
不过相信小伙伴们都不会被难住,所以我们只提一下用了什么:fs模块与child_process模块,一个负责文件处理,一个负责运行下Shell脚本。
let text = req.body.text
try {
let time = Date.now()
let mdname = time + '.md'
// 主题处理, 随机选一个
let theme = ['shibainu', 'seriph', 'bricks'][Math.floor(Math.random() * 3)]
text = `---\ntheme: ${theme}\n---\n\n` + text.replace(/\n/g, '\n\n')
// console.log('ppt文字')
// console.log(text)
console.log('ppt主题: ' + theme)
fs.writeFileSync('./' + mdname, text, 'utf-8')
// 安装依赖
await new Promise(s => {
exec('npx playwright install', (err: any, stdout: any, stderr: any) => {
if (err) {
console.error(err)
return res.status(500).send('安装playwright失败: ' + err)
} else if (stderr) {
// console.error(stderr)
}
// console.log(stdout)
s(stdout)
})
})
// 运行脚本
await new Promise(s => {
exec('slidev export ' + mdname, (err: any, stdout: any, stderr: any) => {
if (err) {
console.error(err)
return res.status(500).send('生成ppt失败: ' + err)
} else if (stderr) {
// console.error(stderr)
}
// console.log(stdout)
console.log('生成ppt成功')
s(stdout)
})
})
let pdfname = time + '-export.pdf'
let base64 = fs.readFileSync(pdfname, { encoding: 'base64' })
console.log(base64.length)
// 文件base64内容给客户端
res.json(rule.success({ base64, type: 'pdf' }))
// 处理完删除原文件
fs.rmSync(mdname)
fs.rmSync(pdfname)
} catch (error: any) {
res.status(500).send('主生成ppt失败: ' + (error.message || error))
}
核心代码就是这些
这里因为是处理*定位机**,所以不涉及业务的处理,故单纯返回base64,虽说增大了流量,但是将业务简单化了。
这里有一点一定一定要注意,
一定要自己在Shell上先跑一遍完整的导出流程,因为有太多依赖需要安装,不跑的话,上面代码一定没法用。
客户端(也是后端),进行base64的反序列化根据后缀生成文件,然后上传至文件管理器即可。
第五、返回URL给用户
类似上面公众号,就是走微信的临时素材方案,没啥可说的。
结束
这个流程其实非常简单,理一下就很清晰了,当时这个Demo也就花了两小时的样子,主要还都是卡在了配置上,而不是代码实现上。
不过上面仅仅是一个Demo,有小伙伴真的需要的话,可以自己实现一个基于自己复杂业务的PPT-GPT生成器。
你觉着这种建议PPT是否有市场价值,欢迎评论区讨论。