ELMo深层语境化的词表征
Deep contextualized word representations
原文:https://arxiv.org/abs/1802.05365
作者:Matthew E. Peters等人
译者:Peden
时长:约8000字,约20分钟
摘要
我们提出了一种新型的深层语境化的词表征,该方法不仅对词语用法的复杂特征建模(如语法和语义),还对这些词语用法在不同语境中的变化方式建模(如多义性)。我们的词向量是一个深层双向语言模型(biLM)的内部状态的学习函数,该模型是在大型文本语料库上预训练而来。我们证明,这些表征可以很容易地添加到现有模型中,并且显著地提升了六个具有挑战性的NLP问题的最新水平,包括问答、文本蕴涵、情感分析。我们还提出了一个分析,它表明暴露一个预训练网络的深层内部结构是至关重要的,允许下游模型混合不同类型的半监督信号。
1 引言
预训练的词表征(Mikolov等人,2013;Pennington等人,2014)是许多神经语言理解模型的关键组成部分。但是,学习高质量的表征具有挑战性。理想情况下,它们不仅应该对词语用法的复杂特征建模(如语法和语义),还应该对这些词语用法在不同语境中的变化方式建模(如多义性)。在本文中,我们提出了一种新型的深层语境化的词表征,该方法可以直接解决这两个难题,并且可以很容易地集成都现有模型中,并且在一系列具有挑战性的语言理解问题中显著地改善了每一种考虑到的情况下的最新水平。
我们的词表征不同于传统的词嵌入,因为每个符号都被分配了一个表征,该表征是整个输入语句的函数。我们使用一个从双向LSTM派生而来的向量,该向量是在大型文本语料库上使用一对语言模型目标训练而来。因此,我们称它们为ELMo表征(Embeddings from Language Models)。不同于之前的语境化的词向量学习方法(Peters等人,2017;McCann等人,2017),ELMo表征是深层的,从某种意义上说,它们是biLM所有内部层的函数。更具体地说,我们学习了每个终端任务的输入单词上的向量的线性组合,这比仅使用顶层LSTM显著地提高了性能。
以这种方式组合内部状态允许非常丰富的词表征。使用内部任务评价(intrinsic evaluations),我们表明,较高级别的LSTM状态捕获词义的上下文相关方面(如,它们可以在不修改的情况下使用,以在监督词义消歧任务上表现良好),而较低级别LSTM状态为语法的各方面建模(如,它们可以用作词性标注)。同时暴露所有信号是非常有益的,允许学习模型选择半监督类型,它对每个终端任务都是最有用的。
大量实验表明,ELMo表征在实践中非常有效。我们首先表明,它们可以很容易地添加到现有模型中,以解决六个不同的且具有挑战性的语言理解问题,包括文本蕴涵、问答、情感分析。仅添加ELMo表征就可以显著地改善每种情况下的最新技术水平,包括高达20%的相对误差减少。对于可直接比较的任务,ELMo优于CoVe(McCann等人,2017),它使用神经机器翻译编码器来计算语境化表征。最后,ELMo和CoVe的对比分析表明,深层表征优于仅从LSTM顶层派生的表征。我们的训练模型和源代码是开源的,我们希望ELMo为其他NLP任务提供类似的收益。
2 相关工作
由于能够从大规模未标记文本中捕获单词的句法和语义信息,预训练的词向量(Turian等人,2010;Mikolov等人,2013;Pennington等人,2014)是大多数最先进NLP架构的标准组件,包括问答(Liu等人,2017)、文本蕴涵(Chen等人,2017)和语义角色标注(He等人,2017)。然而,这些学习词向量的方法只允许对每个单词进行上下文无关的表征。
先前提出的方法克服了传统词向量的一些缺点,要么使用子词信息(subword information)来丰富传统词向量(如Wieting等人,2016;Bojanowski等人,2017),要么为每个词义学习单独的向量(Neelakantan等人,2014)。我们的方法通过使用字符卷积从子词单元(subword units)中受益,并且我们将多义信息无缝地合并到下游任务中,而无需明确地训练以预测预定义的含义类。
其他的近期工作也聚焦在学习语境化的表征。context2vec(Melamud等人,2016)使用双向LSTM(Hochreiter和Schmidhuber,1997)围绕一个中枢词对上下文编码。其他的语境化嵌入学习方法在表征中包括中枢词本身,并且使用有监督的神经机器翻译(MT)系统(CoVe;McCann等人,2017)或无监督语言模型(Peters等人,2017)的编码器来计算表征。这两种方法都得益于大数据集,尽管机器翻译方法受限于并行语料库大小。在本文中,我们充分利用获得丰富的单语数据的优势,在一个大约有3000万句话的语料库上训练我们的biLM。我们还将这些方法推广到深层语境化表征中,我们展示了这些方法在各类各样的NLP任务中都能很好地工作。
以前的研究也表明,深层biRNN的不同层编码不同类型的信息。例如,在深层LSTM的较低层次引入多任务句法监督(如词性标注),可以提高较高层次任务的总体性能,例如,依存分析(Hashimoto等人,2017)或CCG超级标注(Søgaard和Goldberg, 2016)。在基于RNN的编码器-解码器机器翻译系统中,Belinkov等人(2017)表明,在2层LSTM编码器第一层学习到的表征比第二层更擅长预测词性标注。最后,用于编码词上下文的LSTM顶层已经被证明可以学习词义表征。我们表明,基于ELMo表征修改的语言模型目标也会产生类似信号,并且对混合这些不同类型半监督的下游任务的学习模型是非常有益的。
Dai和Le(2015)以及Radachandran等人(2017)使用语言模型和序列自动编码器预训练编码器-解码器对,然后根据特定任务有监督微调。相比之下,在使用未标记数据预训练之后,我们固定了权重并添加额外的特定任务的模型容量,从而使我们能够利用大型、丰富和通用的biLM表征,以应对下游训练数据量要求较小的有监督模型的情况。
3 ELMo
不同于最广泛使用的词表征(Pennington等人,2014),ELMo词表征是整个输入语句的函数,如本节所述。它们是通过字符卷积在两层biLM上计算的得来的(见3.1节),作为内部网络状态的线性函数(见3.2节)。此设置允许我们进行半监督学习,其中,biLM是在一个大规模语料库上预训练而来(见3.4节),并且很容易融入到各种现有的神经NLP架构中(见3.3节)。
3.1 双向语言模型
给定一个包含N个符号的序列(t_1,t_2,...,t_N),一个前向语言模型,通过给定历史(t_1,t_2,...,t_k-1),对符号t_k的概率建模,从而计算序列的概率:
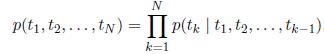
。最近最先进的神经语言模型(J’Ozefowicz等人,2016;Melis等人,2017;Merity等人,2017)计算上下文无关的符号表征x_LM_k(通过符号嵌入或者字符CNN),然后,沿着前向LSTM的L层通过。在每个位置k,每个LSTM层输出一个上下文相关的表征h_LM_k,j(向右),其中,j=1,2,...,L。LSTM顶层输出h_LM_k,L(向右)通过softmax层来预测下一个符号t_k+1。
反向LM类似于前向LM,但它在序列反向上运行,根据未来上下文来预测前一个符号
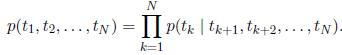
。它可以以类似于前向LM方式来实现,在一个L层的深层模型中,给定(t_k+1,...,t_N),每个反向LSTM层j生成t_k表征h_LM_kj(向左)。
biLM组合了前向和反向LM。我们的公式联合最大化前向和反向LM的对数似然:
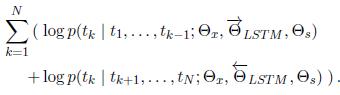
。我们将前向和反向LM的符号表征参数(Θ_x)和softmax层参数(Θ_s)绑定在一起,同时,在每个方向上,为LSTM维护单独的参数。总的来说,该公式类似于Peters等人(2017)的方法,区别是,我们在双向上共享一些权重,而不是完全独立的参数。在下一节中,我们摒弃以前的工作,通过引入一种新方法来学习词表征,它是biLM层的线性组合。
3.2 ELMo
ELMo是biLM的中间层表征的特定任务组合。对于每一个符号t_k,一个L层的biLM计算一个2L+1个表征的集合
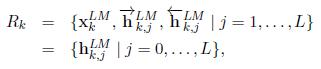
,其中,h_LM_k,0是符号层,并且对每个biLSTM层,h_LM_k,j=[h_LM_k,j(向右), h_LM_k,j(向左)]。
为了纳入下游模型,ELMo将R中所有层折叠进一个向量
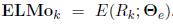
。在最简单的情况下,ELMo仅选择顶层,E(R_k) = h_LM_k,L,如TagLM(Peters等人,2017)和Cove(Mc Cann等人,2017)。一般来说,我们计算biLM所有层的特定任务权重:
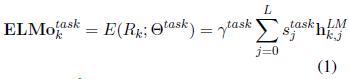
。在(1)中,s_task是softmax归一化权重,并且标量参数r_task允许任务模型缩放整个ELMo向量r。对于优化过程具有实际意义(详见附录)。考虑到biLM的每一层的激活函数有不同分布,在某些情况下,它也有助于在加权前对每一个biLM层应用归一化(Ba等人,2016)。
3.3 使用biLM执行监督NLP任务
针对目标NLP任务,给出了一个预训练的biLM和一个监督架构,利用biLM优化任务模型是一个简单的过程。我们简单地运行biLM,并且为每个单词记录所有的层表征。然后,我们让终端任务模型学习这些表征的线性组合,如下所述。
首先考虑没有biLM的监督模型的最低层。大多数监督NLP模型在最低层共享一个通用的架构,允许我们以一致且统一的方式添加ELMo。给定符号序列(t1,...,tN),对于每个符号位置,使用预训练的词表征和任意的字符表征,形成一个上下文无关的符号表征x_k,它是标准的。然后,通常地,模型使用双向RNN、CNN、或前馈网络形成一个上下文相关的表征h_k。
为了将ELMo添加到监督模型中,我们首先冻结biLM的权重,并且把ELMo向量ELMo_task_k和x_k连接起来,并且将ELMo增强表征[x_k, ELMo_task_k]传递到任务RNN中。对于某些任务(如SNLI、Squad),我们通过两种方式进一步改进:一是通过引入另一组输出特定线性权重,在任务RNN的输出中包含ELMo;二是将h_k替换为[h_k, ELMo_task_k]。由于监督模型剩余部分保持不变,这些添加可能发生在更复杂的神经网络模型的上下文中。例如,请参见第4节中的SNLI实验或者共指消解实验,前者在biLSTM的后面跟着一个双注意力层(bi-attention layer),后者将聚类模型分层到biLSTM上。
最后,我们发现,向ELMo中添加适量的丢弃(dropout)是有益的(Srivastava等人,2014),在某些情况下,通过向损失中添加r||w||_2_2来调整ELMo权重也是有益的。这给ELMo权重施加了一个归纳偏置,以接近所有biLM层的平均值。
3.4 预训练的双向语言模型架构
本文预训练的biLM与J’Ozefowicz等人(2016)和Kim等人(2015)的架构相似。但是进行了修改,以支持双向联合训练,但在LSTM层间增加了残差连接。在这项工作中,我们关注大规模biLM,如Peters等人(2017)强调了使用biLM的重要性,而非仅前向LM和大规模训练。
为了平衡整个语言模型的困惑度和模型的大小以及下游任务计算需求,同时,保持一个纯基于字符的输入表征,我们将J´ozefowicz等人(2016)的单一最佳模型CNN-BIG-LSTM的所有嵌入和隐藏维度减半。最终模型使用L=2层biLSTM,其中有4096个单元和512个维度投影,以及一个从第一层到第二层的残差连接。上下文不敏感类型表征使用2048个字符n-gram卷积过滤器,后面是两个高速路层(Srivastava等人,2015),以及一个向下的512表征的线性投影。因此,biLM为每个输入符号提供三层表征,包括由于纯字符输入而在训练集之外的那些表征。相比之下,传统词嵌入方法只为词汇表中符号提供一层表征。
在1B Word Benchmark(Chelba等人,2014)上经过10个epoch训练后,前向和反向困惑度平均值是39.7,而前向CNN-BIG-LSTM的困惑度是30.0。一般来说,我们发现前向和反向困惑度近似相等,反向的值略低。
一旦经过预训练,biLM可以计算任务的表征。在某些情况下,在特定于域的数据上微调biLM会导致困惑度显著下降,并且增加下游任务的性能。这可以看做是一种领域迁移。因此,在大多数情况下,我们在下游任务中使用一个微调的biLM。详见附录。
4 评估
表1显示了ELMo在六个基准NLP任务的不同集合中的性能。在所考虑的每一项任务中,仅添加ELMo就可以建立一个新的最先进的结果,与强基模型相比,相对误差减少了6-20%。这是不同的集合模型架构和语言理解任务的一个非常普遍的结果。在本节的剩余部分,我们提供了各个任务结果的高级草图,有关完整的实验细节,详见附录。
问答 斯坦福大学的问答数据集SQuAD(Rajpurkar等人,2016)包含100K+个众包问答对(crowd sourced question-answer pairs),其中答案是给定维基百科段落的一个跨度(span)。我们的基线模型(Clark和Gardner,2017)是Seo等人的双向注意力流模型(Bidirectional Attention Flow model)的改进版本。它在双向注意力组件之后增加了一个自我注意力层,简化了一些池化操作,并将LSTM代替GRU(Cho等人,2014)。在基线模型中加入ELMo后,测试集F_1的性能从81.1%提高到85.8%,提高了4.7%,相对误差降低了24.9%,整个单一模型的最新状态提高了1.4%。11个成员的合奏将F_1的性能提高到了87.4%,这是提交排行榜时的最新水平。ELMo的4.7%的增长率也明显高于将CoVe添加到基线模型的1.8%的增长率(McCann等人,2017)。
文本蕴涵 文本蕴涵是一类任务,它根据给定的一个前提,判断一个假设是否为真。斯坦福大学自然语言推理(SNLI)语料库 (Bowman等人, 2015)提供了大约550K个假设/前提对。我们的基线是来自Chen等人 (2017)的ESIM序列模型,它使用biLSTM来编码前提和假设,后面跟着一个矩阵注意力层、一个局部推理层、另一个biLSTM推理组合层、以及输出层之前的一个池化操作。总的来说,将ELMo添加到ESIM模型中,在五个随机种子上,将平均准确率提高了0.7%。5个成员的合奏将整体准确率提高了89.3%,超过先前的合奏的88.9%的最佳准确率(Gong等人,2018)。
语义角色标注 语义角色标注(SRL)系统对句子的谓词-论元建模,这通常被描述为回答"谁对谁做了什么"。He等人(2017)将SRL建模为BIO标注问题,并使用一个正反向交叉的8层深层biLSTM,紧跟Zhou和Xu (2015)。如表1所示,当把ELMo 添加到He等人(2017)提出的单一模型的重新实现中,测试集F_1的性能从81.4%提升到84.6%,提升了3.2%,在OntoNotes基线上取得了新的最新水平(Pradhan等人,2013),并将之前的最佳合奏结果提升了1.2%。
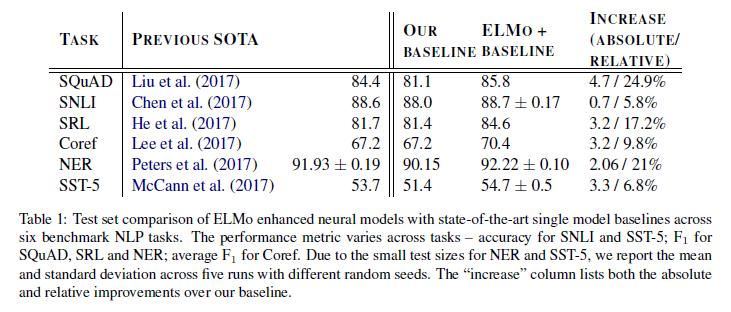
共指消解 共指消解是文本中提到的聚类分析任务,指的是同一个潜在的现实世界实体。我们的基线模型是Lee等人 (2017)的端到端跨度(span)的神经模型。它首先使用biLSTM和注意力机制计算跨度(span)表征,然后应用一个softmax排序模型,以发现共指链。在我们的实验中,使用来自CoNLL 2012共享任务(Pradhan等人,2012)的OntoNotes共指注解,添加ELMo可以将F_1的平均性能从 67.2%提升到70.4%,提高了3.2%,建立了一个最新的最优水平,再次在F_1上将以前的最佳合奏结果的性能提高了1.6%。
命名实体抽取 CoNLL 2003 NER任务(Sang和Meulder,2003)由路透社RCV1 语料库的新闻专线组成,该语料库标记有四种不同实体类型(PER, LOC, ORG, MISC)。根据最新最先进的系统(Lample等人,2016;Peters等人,2017),基线模型使用预训练词嵌入,一个字符CNN表征,两个biLSTM层,以及一个随机条件场(CRF)损失(Lafferty等人,2001),类似于Collobert等人的模型(2011)。如表1所示,我们的ELMo增强biLSTM-CRF在F_1上取得了5次平均92.22%的性能。我们的系统与Peters等人(2017)先前的最新技术的系统之间的关键区别是,我们允许任务模型学习所有biLM层的加权平均值,然而Peters等人(2017)仅使用biLM的顶层。如5.1节所示,使用所有层而不是最后一层可以提高跨多个任务的性能。
情感分析 斯坦福情感Treebank(SST-5;Socher等人,2013)中细粒度情感分类任务,涉及从五个标签中选择一个(从非常消极到非常积极)来描述电影评论的一个句子。这些语句中包含了各种语言现象(如习语)和复杂的句法结构(如难以学习的否定)。我们的基线模型是来自McCann等人(2017)的双注意力分类网络(BCN),它增加CoVe嵌入,保持了先前的最先进的结果。在BCN模型中,将CoVe替换为ELMo,可使绝对准确率比现有的最先进水平提高了1.0%。
5 分析
本节提供了剥离分析,以验证我们的主要观点,并阐明ELMo表征的一些有趣方面。5.1节表明,在下游任务中使用深层语境化表征,与仅使用顶层的先前工作相比,无论是biLM或MT编码器生成,都可以提高性能,而且ELMo表征提供了最佳整体性能。5.3节探讨了不同类型的从biLM中捕获的语境化信息,并且使用两个内部任务评价来表明,较低层更好地表征语法信息,较高层较好地捕获语义信息,与MT编码器一致。它还表明,我们的biLM始终提供比CoVe更丰富的表征。此外,我们分析了敏感性因素,例如,ELMo在任务模型中所处的位置(5.2节)、训练集大小(5.4节)、可视化ELMo学习的任务权重(5.5节)。
5.1 交替分层加权方案
为了组合biLM层,等式1有许多备选方案。以前的语境化表征工作仅使用最后一层,无论是来自biLM(Peters等人,2017)或MT编码器(Cove;McCann等人,2017)。正则化参数r的选择也很重要,因为较大的值(例如r=1)有效地将加权函数减少到各层简单平均值,而较小的值(例如r=0.001)允许各层权重发生变化。
表2比较了SQuAD, SNLI和SRL这些备选方案。包含所有层的表征比仅使用最后一层的表征提高了整体性能,并且最后一层的语境化表征比基线提高了性能。例如,对于SQuAD,仅使用最后一个biLM层,在F_1上,比基线性能提高了3.9%。平均所有biLM 层而不是仅使用最后一层又将F_1的性能提高了0.3%(比较Last Only列和r=1列),并且允许任务模型学习单层权重又将F_1的性能提高了0.2%(比较r=1列和r=0.001列)。在大多数情况下,ELMo优先使用较小的r值,但NER(一个训练集较小的任务)对r不敏感(未显示)。
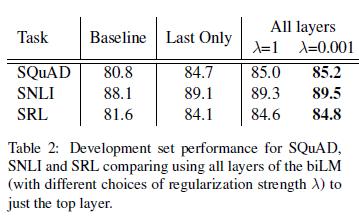
总体趋势与CoVe相似,但基线增长较小。对于SNLI,使用r=1平均所有层,比仅使用最后一层,将准确率从88.2%提升到88.7%。与仅使用最后一层相比,使用r=1的情况下,SRL F_1的性能增加了0.1%,直到82.2%。
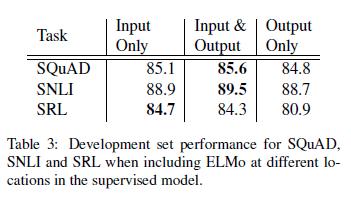
5.2 ELMo位置
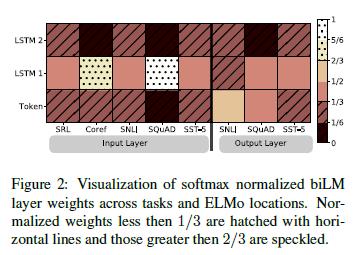
本文中所有的任务架构只包含词嵌入作为biRNN的最低层输入。但是,我们发现,在特定任务架构中,将ELMo 作为biRNN 的输出层,可以提升一些任务的总体结果。如表3所示,对于SNLI和SQuAD而言,在输入层和输出层都包含ELMo,比仅在输入层包含ELMo,性能有改进,而对于SRL而言,性能最高。对此结果的一个可能解释是,SNLI和SQuAD架构在biRNN层后使用注意力层,所以在此层引入ELMo,允许模型直接关注biLM的内部表征。在SRL案例中,特定任务的上下文表征比来自biLM的表征更重要。
5.3 biLM表征捕获的信息
由于添加ELMo比单独使用词向量提高了性能,因此biLM的语境化表征必须对NLP任务的有用信息进行编码,而词向量未捕获这些信息。直觉上,biLM通过上下文消除单词的歧义,想想"play",就是一个多义词。表4的顶部列出了使用GloVe向量的"play"的最相近的语义。它们有好几种词性(例如played和playing作为动词,player和game作为名词),但是集中在与"play"运动相关感官。相反,下面两行显示了SemCor数据集上最邻近的语句(见下文),使用源语句中"play"的biLM上下文表征。在这种情况下,biLM能够消除源语句的词性和词义的歧义。

这些观察结果可以用类似Belinkov等人 (2017) 的语境化表征的内部任务评价来量化。为了隔离由biLM编码的信息,这些表征直接用于预测细粒度的词义消歧任务 (WSD) 和词性标注任务。使用这种方法,还可以和CoVe比较,以及每个单独的层。
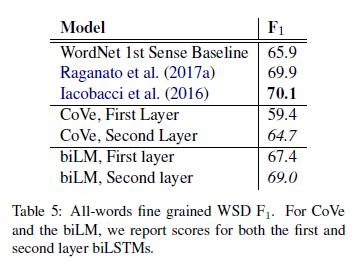
词义消歧 对于一个句子,我们可以使用biLM表征预测目标词的含义,使用一个类似Melamud等人 (2016)的1-最邻近方法。为此,首先我们使用biLM计算我们的训练集Sem-Cor 3.0(Miller等人, 1994)中所有层表征,然后取每个词义表征的平均值。在测试时,我们再次使用biLM目标词的表征,并且从训练集中取最邻近的语义,从WordNet返回到训练中未观察到的引理的第一感觉。
表格5在Raganato等人(2017a)的四个测试集的同一套测试组件中,使用Raganato等人(2017b)的评估框架比较了WSD结果。总的来说,biLM顶层表征的F_1为69.0,并且在WSD上优于第一层。这与使用手工设计特征(Iacobacci等人,2016)的最先进的特定WSD的监督模型有竞争力,并且是一个使用辅助粗粒度语义标注和词性标注(Raganato等人,2017a)训练的特定任务biLSTM。CoVe biLSTM层遵循与biLM层类似的模式(与第一层相比,第二层的整体性能更高),但是,我们的biLM优于CoVe biLSTM,后者跟踪第一感觉基线。
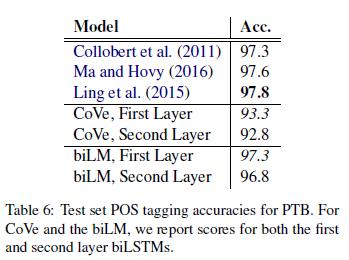
词性标注 为了检测biLM是否捕获基本语法,我们使用语境化表征作为线性分类器的输入,该分类器预测Penn Treebank(PTB) (Marcus等人, 1993)的华尔街日报部分的词性标注。由于线性分类器只增加少量模型容量,这是biLM表征的直接测试。与WSD类似,biLM表征与精调且任务相关的biLSTM相比具有竞争力(Ling等人,2015;Ma和Hovy,2016)。但是,与WSD不同,第一个biLM层的准确度高于顶层,这与多任务训练 (Søgaard和Goldberg, 2016; Hashimoto等人, 2017)和MT (Belinkov等人, 2017)的深层biLSTM的结果是一致的。CoVe的词性标注的准确度与biLM类似,并且跟WSD一样,biLM比CoVe编码器取得更高准确度。
监督任务影响 总之,这些实验证实了biLM中不同层代表了不同类型信息,并解释了为什么包含所有biLM层对下游任务最高性能是重要的。另外,相比CoVe,biLM表征更易迁移到WSD和词性标注任务中,这有助于说明为什么在下游任务中ELMo优于CoVe。
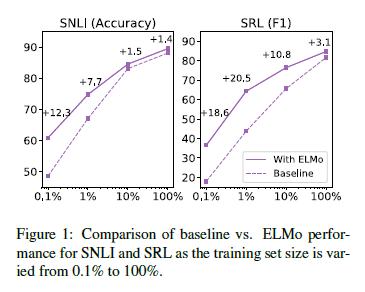
5.4 样本效率
将ELMo添加到模型中,可以显著地提高样本效率,包括获取最佳性能的参数更新次数,以及整个训练集大小。例如,未使用ELMo时,SRL模型在486个epoch训练后达到最大F_1,使用ELMo后,模型在10个epoch就超过基线最大值,为达到相同性能所需的更新次数相对下降了98%。此外,ELMo增强模型使用更小的训练集,比未使用ELMo效率更高。图1比较了训练全集百分比从0.1%到100%时,有无ELMo时基线模型的性能。ELMo 的改进对较小数据集来说是最大的,并且显著地减少了达到给定性能水平的训练集数量。在SRL情况下,ELMo模型使用1%的训练集数据,与基线模型使用10%的训练集数据,取得相同的F_1值。
5.5 可视化学习权重
图2显示了softmax归一化学习的层权重。在输入层,任务模型倾向于biLSTM首层。对于共指(coreference)和SQuAD,这是最受欢迎的,但是对其他任务来说,分布的峰值要小一些。输出层权重相对均衡,对较低层有轻微的偏好。
6 总结
我们介绍了一种通用方法,从biLM中学习高质量的深层的上下文相关的表征,并且当将ELMo应用到广泛的NLP任务时显示很大的改善。通过剥离实验(ablations)和其他可控实验,我们也证实了,biLM有效地编码了上下文单词的不同类型的语法和语义信息,并且使用所有层提高了整个任务的性能。
参考
见原文
附录
见原文