
softmax计算成本高的根源在于softmax最后一步需要做归一化操作,这个随着vocabulary大小增加,计算成本越来越高。

下面我们稍微具体的描述下这个问题,

我们目标现在就是怎么能够近似的计算

下面是几种优化方法,先介绍第一大类 基于采样的方法。
Sampling-based Softmax Approximations
基于采样的方法,目的是近似归一化因子
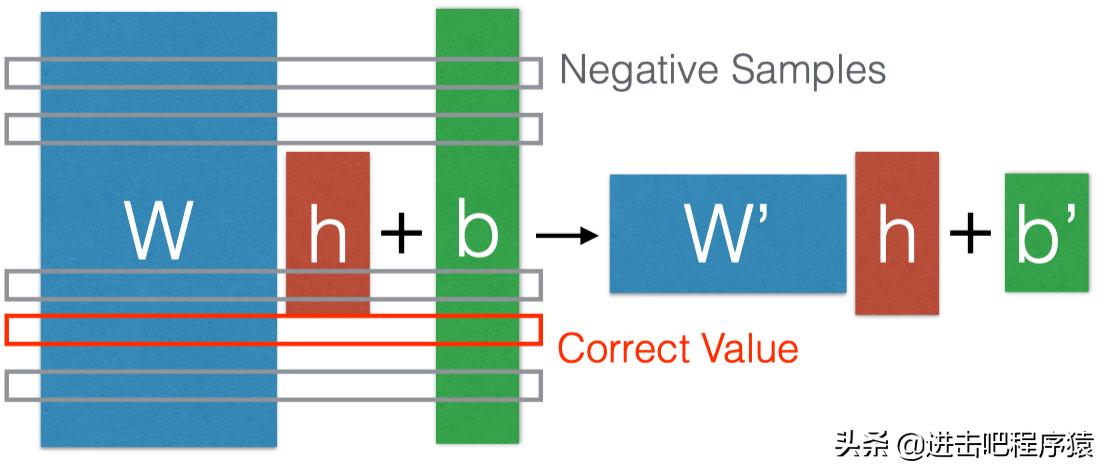
H大小是不变的,变化的是w,通过采样,有效的减少w大小。
此处 Negative samples 采样方法是根据 单词的频率来,这个做的一个依据是:
假设我们最后输出是 10,20,30,那对应的 就是 e10, e20, e30, 而 e30≈10^13,而e20 ≈ 5*10^9,此处e30是远大于其他值的,于是我们通过采样最大的几个值,基本上就可以近似估计归一化因子了。
Importance Sampling
关于重要性采样可以查看 重要性采样(Importance Sampling)
我们从一个简单分布Q中采样出xi,然后计算权重 e^s/Q,方法如下:
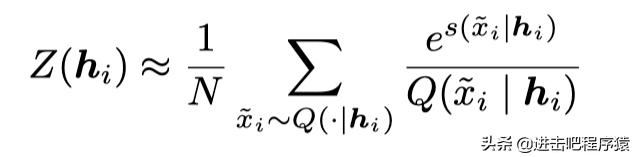
当N小的时候,这是一个有偏估计。
下面是一个详细的推导


Noise Contrastive Estimation
详细可以看我之前写的文章 Noise Contrastive Estimation
其主要思想通过引入噪音数据点,对每个数据进行二分类预测,通过最大化预测其是噪音点还是实际数据点概率,从而保证softmax的最大化。
更通俗一点,就是我们通过最大化二分类概率,保证了
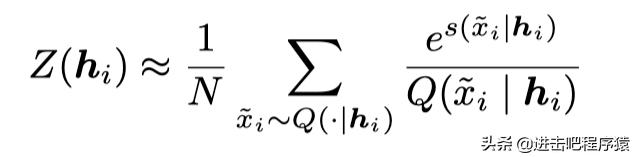
归一化因子z==1.
下面是真假数据的后验概率:
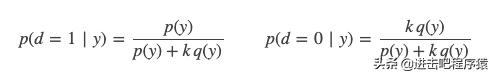
Simple Negative Sampling
这是在word2vec中采用的采样方法,也就是在NCE中我们令 k = |V|,并且 q(y) 为均匀分布,就得到了 kq(y) == 1

损失函数是

所以如果我们做采样的时候,q(y)不是均匀分布,而且也没有采样 k = |V| 个数的话,其实我们是保证不归一化因此 z(h) == 1的,也即训练出来的模型不是一个严格的概率分布。
下面我们来看 negative-sampling 方法的实现 wordemb-skip-ns.py
下面我们开始另一大类的优化方法:Structure-based Softmax Approximations。
主要分为下面3大类
- Class-based softmax
- Hierarchical softmax
- Binary codes
Class-based Softmax
先预测类别,再预测word

Hierarchical Softmax
二分树,由原先的预测V,改为了根号V。
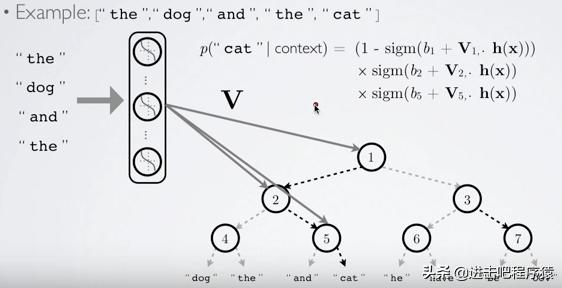
图片来源:Hugo Lachorelle’s Youtube lectures
Binary Code Prediction
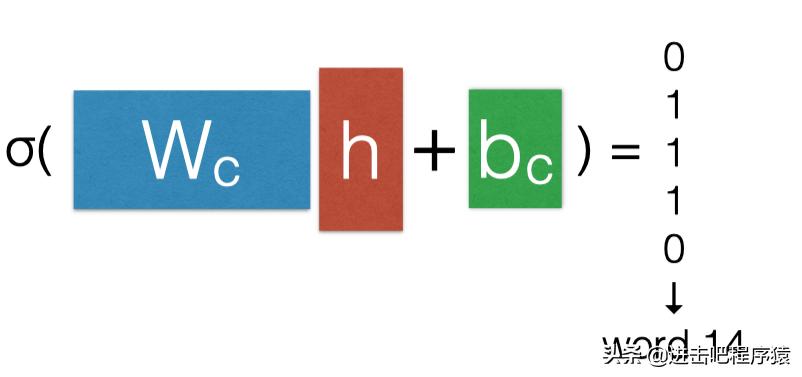
直接将单词进行二进制编码。为什么这种做法有效呢?
参考:
http://ruder.io/word-embeddings-softmax/
word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
Cmu 第5课课件
Neural Machine Translation via Binary Code Prediction