2021年过去了,虽然疫情反复不断,但AI业界前进脚本并没受到影响,各种令人惊艳的模型还是层出不穷。Transformers开始大行其道,与之相关的自监督预训练模型也开始火了起来,所谓CV界的BERT模型也开始遍地开花,比如具有代表性的有何凯明提出MAE、字节跳动的iBOT等。
下面就是对2021年的一些有趣的进展做一个盘点,一起回顾下AI业界有趣的一些进展。
DALL·E:零样本文本到图像生成
简介:OpenAI训练了一个能够从文本生成图像的Transformer模型DALL·E。它可以从文本创建图像。与GPT-3一样,DALL-E是一个Transformer语言模型,使用文本-图像对训练从文本生成图像。 它有很多能力:包括创建动物和物体的拟人化版本、以合理的方式组合不相关的概念、呈现文本以及对图像进行转换。
论文:https://arxiv.org/abs/2102.12092
代码:https://github.com/openai/DALL-E
项目地址:https://openai.com/blog/dall-e/
体验地址1:https://openai.com/blog/dall-e/
体验地址2:https://huggingface.co/spaces/flax-community/dalle-mini

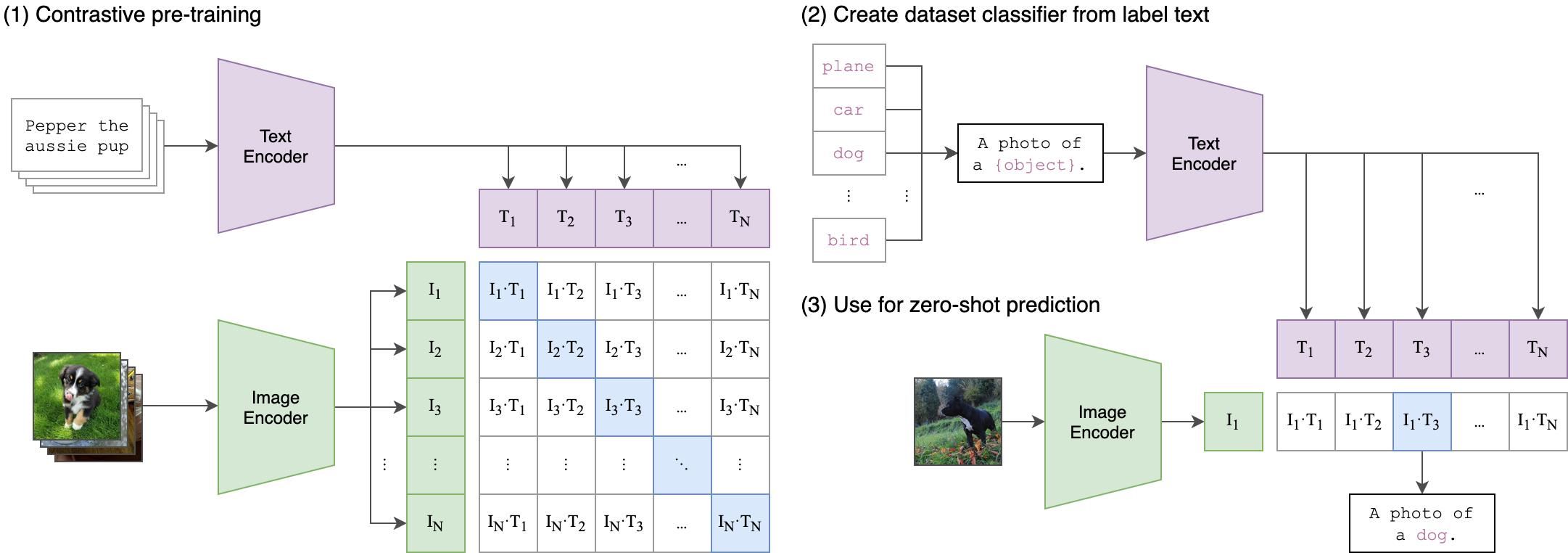
OpenAI推出CLIP:语言图像对比预训练
简介:CLIP(对比语言-图像预训练)是一种针对各种(图像、文本)对进行训练的神经网络。 它可以使用自然语言来预测最相关的文本片段,给出一张图片,而不是直接对任务进行优化,类似于GPT-2和gpt - 3的zero-shot功能。 我们发现CLIP与原始ResNet50在ImageNet“zero-shot”上的性能匹配,没有使用任何原始的1.28M标记的样本。
论文:https://arxiv.org/abs/2103.00020
代码:https://github.com/openai/CLIP
项目:https://openai.com/blog/clip/
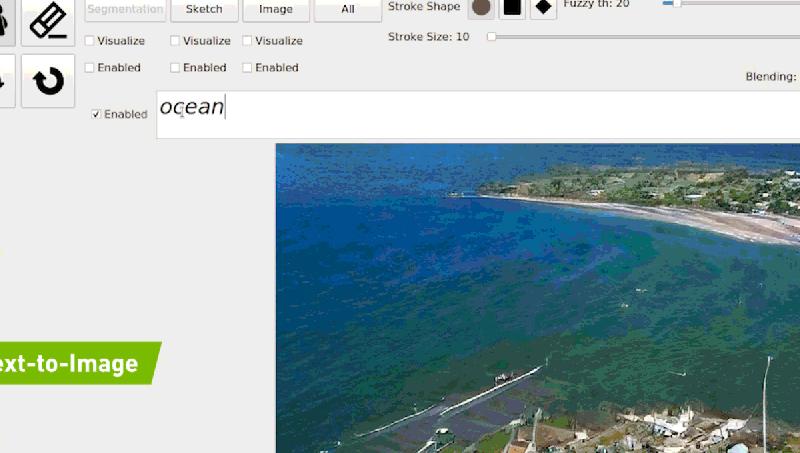
StyleGAN-NADA:文本驱动的(基于CLIP)的图像生成
简介:只需用简单的一个或几个字描述,一张目标领域的图像也不需要,StyleGAN-NADA就能在几分钟内训练出你想要的图片:比如现在在几张狗狗的基础图片上输入“Sketch”,不到1分钟,一张张草图风格狗的图片就出来了。
代码:https://github.com/rinongal/StyleGAN-nada
项目介绍:https://github.com/rinongal/StyleGAN-nada
体验地址:https://replicate.com/rinongal/stylegan-nada

英伟达开源StyleGAN3:皮肤、毛发不再粘屏幕,还能360度旋转
介绍:StyleGAN生成式对抗网络是一种最先进的高分辨率图像合成方法,从最初的GAN到StyleGAN2变体,其图像合成能力一直在突破人类的想象,而这次升级版StyleGAN3的对生成细节的把控更是令人惊叹。它从根本上解决了StyleGAN2 图像坐标与特征粘连的问题,实现了真正的图像平移、旋转等不变性,大幅提高了图像合成质量。
论文:https://arxiv.org/abs/2106.12423
代码:https://github.com/NVlabs/stylegan3
项目介绍:https://nvlabs.github.io/stylegan3/

GitHub Copilot(Codex):评估基于代码训练的大型语言模型
简介:GitHub Copilot是由GitHub和OpenAI开发的一款人工智能工具,用于帮助Visual Studio Code、Neovim、JetBrains的用户自动完成代码。GitHub Copilot使用的是OpenAI Codex,它是GPT-3的修订版,旨在生成有效的计算机代码,可在任何许可的GitHub公共库上训练模型。
论文:https://arxiv.org/abs/2107.03374
项目介绍:https://copilot.github.com/
Copilot地址:https://github.com/github/copilot-docs
Codex地址:https://github.com/openai/human-eval

Real-ESRGAN:用纯合成数据训练真实世界的盲超分辨率
简介:ESRGAN、EDVR等超分领域里程碑论文的作者在超分领域的又一力作,他们对ESRGAN进行扩展,将其应用场景从合成数据向真实场景数据走了一大步。针对现有图像超分、盲图像超分退化模型设计的不足,提出了一种高阶退化建模方案;针对高阶退化空间下原始判别不稳定问题,提出了UNet+SN的超强判别器。最终所得Real-ESRGAN在真实场景数据下取得了非常优秀的、视觉效果绝佳的超分效果。
论文:https://arxiv.org/abs/2107.10833
代码:https://github.com/xinntao/Real-ESRGAN
体验地址:https://huggingface.co/spaces/akhaliq/Real-ESRGAN

ADOP:近似可微的单像素点绘制
简介:输入一组照片,渲染出来的不仅仅是一段视频,更是一个3D场景模型,不仅能任意角度随意切换、高清无死角,还能调节曝光、白平衡等参数。论文提出了一种基于点的可微神经渲染流水线ADOP(Approximate Differentiable One-Pixel Point Rendering),用AI分析输入图像,并输出新角度的新图像。
论文:https://arxiv.org/abs/2110.06635
代码:https://github.com/darglein/ADOP

AgileGAN:通过逆映射一致性迁移学习来格式化肖像
简介: AgileGAN框架通过逆映射一致(Inversion-Consistent)的迁移学习生成高质量的风格画像。引入了一种新的分层变分自编码器,以保证逆映射分布符合原始的隐高斯分布,同时将原始空间扩大到多分辨率的隐空间,从而更好地编码不同级别的细节。为了更好地捕捉依赖于属性的人脸特征程式化,还提出了一个属性感知生成器,并采用早停策略来避免过拟合小的训练数据集。
论文:https://guoxiansong.github.io/homepage/paper/AgileGAN.pdf
代码: https://github.com/GuoxianSong/AgileGAN
项目: https://guoxiansong.github.io/homepage/agilegan.html

StyleClip: 文本驱动的StyleGAN图像编辑
简介:StyleClip引入的对比语言-图像预训练(CLIP)模型的能力,为StyleGAN图像操作开发一个基于文本的界面,从而实现交互式文本驱动的图像编辑操作。
论文:https://arxiv.org/abs/2103.17249
代码:https://github.com/orpatashnik/StyleCLIP
体验:https://replicate.ai/orpatashnik/styleclip

GauGAN2.0:英伟达GauGAN上新2.0,将文本转成逼真图像
简介:给几个关键词就能出摄影大片,英伟达GauGAN上新2.0,将文本转成逼真图像。在 2019 年举办的 GTC 大会上,英伟达展示了一款新的交互应用 GauGAN:利用生成对抗网络(GAN)将分割图转换为栩栩如生的图像。时隔 2 年,英伟达官方推出了 GauGAN 的继任者 GauGAN2,允许用户创建不存在的逼真风景图像。GauGAN2 将分割映射、修复和文本到图像生成等技术结合在一个工具中,旨在输入文字和简单的绘图就能创建逼真的图像。
项目:https://www.nvidia.com/en-us/research/ai-demos
体验:http://gaugan.org/gaugan2/
ADOP:用照片还原整个3D场景图
简介:ADOP提出了一种新颖的基于点的、可微的神经绘制流程,用于场景细化和新视图合成。输入是点云和相机参数的初始估计值,输出是由任意相机姿态合成的图像。在渲染之后,神经图像金字塔通过深度神经网络进行阴影计算和孔洞填充。能够比现有方法合成更清晰和更一致的新观点,因为在训练过程中初始重建是细化的。
论文:https://arxiv.org/abs/2110.06635
代码:https://github.com/darglein/ADOP

ByteTrack:基于数据关联方法BYTE的跟踪器,屠榜多目标跟踪
简介:多目标跟踪的目标是估计视频中目标的边界框和特征。ByteTrack提出了一种简单、有效、通用的关联方法,即通过关联每个检测框而不是高分检测框进行跟踪。首次在单个V100 GPU上以30 FPS的运行速度,在mo17测试集上实现了80.3 MOTA, 77.3 IDF1和63.1 HOTA,目前位居MOTChallenge榜单第一。开源代码中加入了将BYTE应用到不同MOT方法中的教程以及ByteTrack的部署代码。
论文:https://arxiv.org/abs/2110.06864
代码:https://github.com/ifzhang/ByteTrack
体验:https://huggingface.co/spaces/akhaliq/bytetrack

LaMa:基于傅里叶卷积的图像修复
简介:现代图像修复(Image Inpainting)系统尽管取得了长足的进步,但往往难以处理大面积的缺失区域、复杂的几何结构和高分辨率图像。研究人员发现造成这种情况的主要原因之一是修复网络和损失函数都缺乏有效的感受野。将快速傅里叶卷积引入网络架构,弥补感受野不足的缺陷,来自三星、洛桑联邦理工学院等机构的研究者提出了 LaMa(large mask inpainting)方法,在一系列数据集上改进了 SOTA 技术。
代码:https://github.com/saic-mdal/lama
项目:https://saic-mdal.github.io/lama-project/
体验:https://huggingface.co/spaces/akhaliq/lama

CIPS-3D:让GAN生成的逼真人像变成3D版
简介:上海交通大学和华为的最新研究CIPS-3D。它是一种基于GAN的3D感知生成器,只用原始单视角图像,无需任何上采样,就能生成分辨率256×256的清晰图像。仿佛有摄像机对着人像直拍,正面、侧面、仰视、俯视不同角度都能展现。而且,这些效果都是由静态单视角图片生成的!甚至能让卡通人像立体起来。
论文:https://arxiv.org/abs/2110.09788
代码:https://github.com/PeterouZh/CIPS-3D
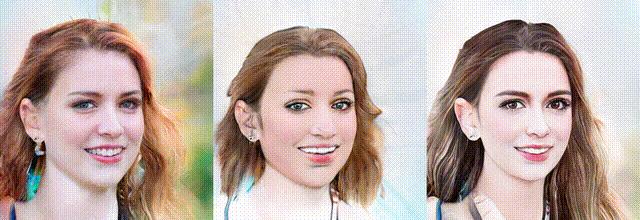
EditGAN:高精度语义图像编辑
简介:EditGAN,一种高质量、高精度的语义图像编辑方法,允许用户通过修改其高度详细的部分分割遮罩来编辑图像,例如,为汽车前照灯绘制新的遮罩。 EditGAN构建在GAN框架之上,只需要少数标注示例——使其成为一个可伸缩的编辑工具。实验表明,EditGAN可以操纵图像与前所未有的细节水平和自由,同时保持完整的图像质量。
论文:https://arxiv.org/abs/2111.03186
项目:https://nv-tlabs.github.io/editGAN/

MAE:将自监督预训练模式用于计算机视觉任务
简介:MAE(Masked AutoEncoders )将NLP领域大获成功的自监督预训练模式用在了计算机视觉任务上,在NLP和CV两大领域间架起了一座更简便的桥梁。此前,大名鼎鼎的GPT和BERT已经将大型自然语言处理(NLP)模型的性能提升到了一个新的高度。现在,何恺明的这篇文章把NLP领域已被证明极其有效的方式,用在了计算机视觉(CV)领域,而且模型更简单。本文证明了掩蔽自动编码器(MAE)是一种可扩展的计算机视觉自监督学习器。 MAE方法很简单:掩盖输入图像的随机补丁,并重建缺失的像素。
论文:https://arxiv.org/abs/2111.06377
代码1(非官方):https://github.com/pengzhiliang/MAE-pytorch
代码2(非官方):https://github.com/FlyEgle/MAE-pytorch

AnimeGANv2:用于照片动画的新型轻量化GAN
简介:AnimeGAN采用的是神经风格迁移 + 生成对抗网络(GAN)的组合。之前提出的AnimeGAN结合了神经风格传递和生成式对抗网络(GAN)来完成这一任务。但是AnimeGAN仍然存在一些明显的问题,如模型生成的图像中存在高频伪影等。AnimeGANv2是AnimeGAN的一个改进版本,通过简单地改变网络*特中**征的标准化来防止高频伪影的产生,同时它进一步缩小了生成器网络的规模,以实现更高效的动画风格转换。
代码:https://github.com/TachibanaYoshino/AnimeGANv2
项目:https://tachibanayoshino.github.io/AnimeGANv2/
体验:https://huggingface.co/spaces/akhaliq/AnimeGANv2

StyleFlow:使用条件连续归一化流的StyleGAN生成图像的属性条件探索
简介:高质量、多样化和逼真的图像现在可以由无条件的GANs生成(例如,StyleGAN)。 但是,使用(语义)属性控制生成过程的选项有限,同时仍然保持输出的质量。此外,由于GAN潜在空间的纠缠性,沿着一个属性执行编辑很容易导致沿着其他属性的不必要的更改。StyleFlow作为一个简单、有效和健壮的解决方案来解决这两个子问题,方法是将条件探索作为一个实例,在属性特征条件下的GAN潜在空间中进行条件连续归一化流。
论文:https://dl.acm.org/doi/10.1145/3447648
项目:https://rameenabdal.github.io/StyleFlow/
代码:https://github.com/RameenAbdal/StyleFlow

VQGAN:Transformers合成高分辨率图像
简介:将GAN和卷积方法的效率与Transformers的表现力相结合,产生了一种强大而高效的语义引导高质量图像合成方法。将卷积方法的效率与变形金刚的表现力结合起来,并以一种感知有意义的方式将对抗训练与可能性训练结合起来。 VQGAN学习一个包含上下文丰富的可视部件的码本,然后用一个自回归转换器对其组成进行建模。
论文:https://arxiv.org/abs/2012.09841
代码:https://github.com/CompVis/taming-transformers
项目:https://compvis.github.io/taming-transformers/


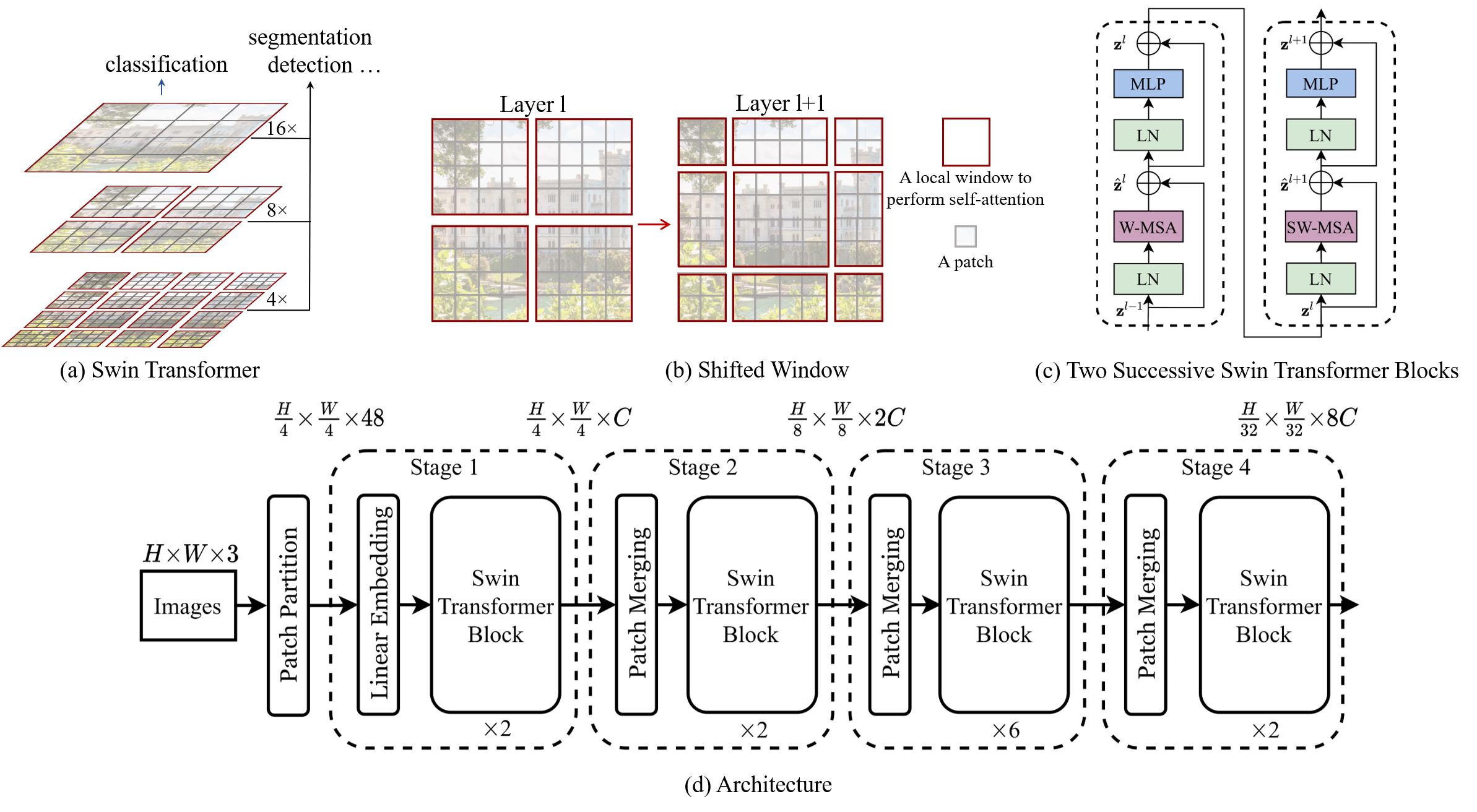
Swin Transformer:使用移位窗口的分层视觉转换器
简介:ICCV2021最佳论文。介绍了一种新的视觉转换器,称为Swin Transformer,它可以作为计算机视觉的通用主干。将Transformer从语言转换为视觉的挑战来自于这两个领域之间的差异,例如视觉实体规模的巨大变化,以及与文本中的文字相比图像中像素的高分辨率。为了解决这些差异,本文提出了一个分层的Transformer,它的表示是通过ShiftWindows来计算的。移窗方案通过将自注意计算限制在不重叠的局部窗口,同时允许跨窗口连接,从而提高了计算效率。Swin Transformer的这些特性使它能够兼容广泛的视觉任务,包括图像分类(ImageNet-1K上87.3 top-1的精度)和密集的预测任务,如对象检测(COCO test-dev上58.7 box AP和51.1 mask AP)和语义分割(ADE20K val上53.5 mIoU)。 它的性能大大超过了之前的最先进水平,在COCO上+2.7盒AP和+2.6掩模AP,在ADE20K上+3.2 mIoU,展示了基于transformer的模型作为视觉骨干的潜力。
论文: https://arxiv.org/abs/2103.14030
代码:https://github.com/microsoft/Swin-Transformer
TryOnGAN:身体感知试穿模型
简介:谷歌使用修改过的StyleGAN2架构创建了一个在线试衣间,在那里你可以只使用自己的图像就自动试穿任何裤子或衬衫。给定一个目标人物的图像和另一个穿着衣服的人的图像自动生成穿着给定服装的目标人物。算法允许服装根据给定的体型变形,同时保留图案和材料细节。以往的方法大多集中在通过成对数据训练进行纹理转移,而忽略了体形变形、皮肤颜色以及服装与人的无缝融合。该模型设计了一个基于姿势的StyleGAN2架构,它带有一个服装分割分支,该分支根据人们穿着服装的图像进行训练。
论文:https://arxiv.org/abs/2101.02285
项目:https://vogue-try-on.github.io
代码:https://github.com/Charmve/VOGUE-Try-On
试玩:https://charmve.github.io/VOGUE-Try-On/web_home/demo_rewrite.html

Gansformer:生产对抗转换器
简介:Gansformer是一种新型高效变压器网络,该网络采用了两部分结构,能够在图像上实现长距离交互,同时保持线性效率的计算,可以很容易地扩展到高分辨率合成。
论文:https://arxiv.org/abs/2103.01209
代码:https://github.com/dorarad/gansformer

Infinite Nature:从单一图像生成自然场景的永久视图
简介:我们引入了长期视图生成的问题:对应于给定单一图像的任意长相机轨迹的新视图的长期生成。这是一个具有挑战性的问题,远远超出了当前的视图合成方法的能力,当呈现大的相机运动时,这些方法会迅速退化。Infinite Nature的方法可以从一组单目视频序列训练。可以在大相机轨迹上生成更长的时间视界的可信场景。
论文:https://arxiv.org/abs/2012.09855
项目:https://infinite-nature.github.io/
代码:https://github.com/google-research/google-research/tree/master/infinite_nature
体验:https://colab.research.google.com/github/google-research/google-research/blob/master/infinite_nature/infinite_nature_demo.ipynb

Barbershop: 基于分割掩码的GAN图像合成
简介:Barbershop提出了一种新的隐空间图像混合算法,该算法能够更好地保留细节和编码空间信息,并提出了一种新的GAN嵌入算法,该算法能够对图像进行轻微的修改以符合常见的分割掩码。 新表现方式可以从多个参考图像中转移视觉属性,包括痣和皱纹等特定细节,因为在一个潜在空间中进行图像混合,我们能够合成连贯的图像。
论文:https://arxiv.org/abs/2106.01505
项目:https://zpdesu.github.io/Barbershop/
代码:https://github.com/ZPdesu/Barbershop

GIRAFFE:将场景表示为合成生成神经特征域,使得图像合成更加可控
简介:CVPR2021最佳论文。在生成模型中加入了合成3D场景表示,这使得图像合成更加可控。深度生成模型允许高分辨率的真实感图像合成。但对于许多应用程序来说,这还不够:内容创建还需要可控。 虽然最近的一些工作研究了如何解开数据中变化的潜在因素,但大多数工作都是在2D上进行的,忽略了我们的世界是三维的。此外,只有少数工作考虑到场景的构图性质。GIRAFFE的关键假设是,将合成3D场景表示与生成模型相结合,可以实现更可控的图像合成。将场景表示为合成生成神经特征域,使其能够从背景中分离出一个或多个对象,以及单个对象的形状和外观,同时无需任何额外的监督,从非结构化和非摆拍的图像集合中学习。 将这种场景表示与神经绘制管道相结合,可以得到一个快速而真实的图像合成模型。实验证明,该模型能够解开单个物体,并允许在场景中平移和旋转它们,以及改变相机的姿势。
论文:https://arxiv.org/abs/2011.12100
项目:https://m-niemeyer.github.io/project-pages/giraffe/index.html
代码:https://github.com/autonomousvision/giraffe

SDEdit:用随机微分方程进行图像合成与编辑
简介:SDEdit是一个基于随机微分方程(SDEs)的图像合成和编辑框架,允许基于笔画的图像编辑和图像合成,而不需要特定的任务优化。给定一个用户编辑的输入图像(例如,手绘的颜色笔画),首先根据SDE向输入添加噪声,然后通过模拟反向SDE对其进行降噪,以逐渐增加其在先验条件下的可能性。该方法不需要特定任务的损失函数设计,这是目前基于GAN反演的图像编辑方法的关键组成部分。与有条件的GAN相比,该方法不需要为新的应用程序收集原始和编辑图像的新数据集。 因此,该方法无需再训练模型就能快速适应测试时的各种编辑任务。
论文:https://arxiv.org/abs/2108.01073
项目:https://sde-image-editing.github.io/
代码:https://github.com/ermongroup/SDEdit

GANSketching:手绘草图生成真实图像
简介:GANSketching方法采用一个或几个手绘草图,并定制一个现成的GAN来匹配输入草图。 当我们的新模型改变一个物体的形状和姿势时,其他的视觉线索,如颜色、纹理、背景,都在修改后被忠实地保留下来。传统上,创建GAN模型需要收集大规模的范例数据集和深度学习中的专业知识。 相比之下,素描可能是传达视觉概念的最普遍的方法。 这项工作提出了一种方法,重写一个或多个草图的GAN,以使初学者更容易训练GAN。实验表明,该方法可以塑造GAN来匹配草图指定的形状和姿态,同时保持真实性和多样性。
论文:https://arxiv.org/abs/2108.02774
项目:https://peterwang512.github.io/GANSketching/
代码:https://github.com/PeterWang512/GANSketching
TimeLens:基于事件的视频帧插值
简介:最先进的帧插值方法通过从连续的关键帧推断图像中的物体运动来生成中间帧。在缺乏额外信息的情况下,必须使用一阶近似,即光流,但这种选择限制了可建模的运动类型,导致在高度动态场景下的误差。事件摄像机是一种新颖的传感器,它通过在帧与帧之间的盲时间内提供辅助视觉信息来解决这一限制。它们异步测量每像素的亮度变化,并以高时间分辨率和低延迟来实现这一点。 基于事件的帧插值方法通常采用基于合成的方法,其中预测的帧残差直接应用于关键帧。 然而,虽然这些方法可以捕获非线性运动,但它们会遭遇鬼影,并且在事件较少的低纹理区域表现不佳。因此,基于合成的方法和基于流程的方法是互补的。TimeLens引入了时间透镜,利用了两者的优点。
论文:https://arxiv.org/abs/2106.07286
项目:http://rpg.ifi.uzh.ch/TimeLens.html
代码:https://github.com/uzh-rpg/rpg_timelens

VGPNN:单一视频的生成多样化视频
简介:VGPNN提出了一种快速和实用的方法来从单个自然视频生成和处理视频,它在几秒钟内生成不同的高质量视频输出。 该方法可以在几分钟内进一步应用于全高清视频剪辑。除了不同的视频生成,还演示了其他几个具有挑战性的视频应用,包括时空视频重定向(例如,视频扩展和视频摘要),视频结构类比和条件视频修复。
论文:https://arxiv.org/abs/2109.08591
项目:https://nivha.github.io/vgpnn/
代码:https://github.com/nivha/vgpnn

BlendGAN:任意风格人脸合成
简介:BlendGAN通过利用灵活的混合策略和通用的艺术数据集来生成任意风俗化的人脸。首先在通用的艺术数据集上训练一个自我监督的样式编码器来提取任意样式的表示。此外,提出了一种加权混合模块(WBM),以隐式混合人脸和风格表示,并控制任意风格化效果。 通过这样做,可以优雅地将任意样式拟合到一个统一的模型中,同时避免逐个准备样式一致的训练图像。BlendGAN还提出了一种新的大规模艺术人脸数据集AAHQ。大量的实验表明,在潜在引导和参考引导的程式化人脸合成中,BlendGAN在视觉质量和风格多样性方面都优于最先进的方法。
论文:https://arxiv.org/abs/2110.11728
代码:https://github.com/onion-liu/BlendGAN
项目:https://onion-liu.github.io/BlendGAN
体验:https://huggingface.co/spaces/akhaliq/BlendGAN

NÜWA(女娲):微软北大提出的统一的多模态预训练模型
简介:MSRA和北大联合团队提出的统一多模态预训练模型NÜWA(女娲),它可以为各种视觉合成任务生成新的或操作现有的视觉数据(即图像和视频)。为了满足不同场景下同时涵盖语言、图像和视频的需求,NÜWA设计了一种3D转换器编码器-解码器框架,该框架不仅可以将视频处理为3D数据,还可以将文本和图像分别处理为1D和2D数据。 此外,还提出了一种3D邻近注意(3DNA)机制,以考虑视觉数据的性质,降低计算复杂度。 我们在8个下游任务上评估NÜWA。 在8个下游任务中,NÜWA在文本到图像生成、文本到视频生成、视频预测等方面取得了新的SOTA。其中,在文本到图像生成中的表现直接超越DALL-E。
论文:https://arxiv.org/abs/2111.12417
代码:https://github.com/microsoft/NUWA
Game Life Restart:人生重开模拟器
简介:一款纯文字内容的网页游戏,3天就创造2亿访问量。玩法超级简单:“你”重开人生,扮演一个刚诞生的婴儿,通过“开局10连抽”为自己选择3种天赋,并将20点(在天赋作用下点数总值会变动)初始属性值分配到颜值、智力、体质和家境,即可以文字描述的方式开启“新人生”。
代码:https://github.com/VickScarlet/lifeRestart
体验:https://liferestart.syaro.io/view/index.html

GFP-GAN达到盲人脸修复新里程碑
简介:盲人脸修复通常依赖于人脸先验,如人脸几何先验或参考先验,来恢复真实可信的细节。 然而,非常低质量的输入不能提供精确的几何先验,而高质量的参考是不可访问的,这限制了在真实世界场景中的适用性。GFP-GAN利用丰富和多样化的先验封装在一个预先训练的人脸GAN中进行盲人脸恢复。 这种生成人脸先验(GFP)通过新的通道分割空间特征变换层被纳入人脸恢复过程中,这使得该方法能够实现真实和逼真度的良好平衡。由于强大的生成面部先验和精致的设计,GFP-GAN可以联合恢复面部细节和增强颜色,而GAN反演方法需要在推理时进行昂贵的图像特定优化。 大量的实验表明,该方法在合成数据集和真实数据集上都取得了优于现有技术的性能。
论文:https://arxiv.org/abs/2101.04061
代码:https://github.com/TencentARC/GFPGAN
项目:https://xinntao.github.io/projects/gfpgan
体验1:https://huggingface.co/spaces/akhaliq/GFPGAN
体验2:https://replicate.com/tencentarc/gfpgan

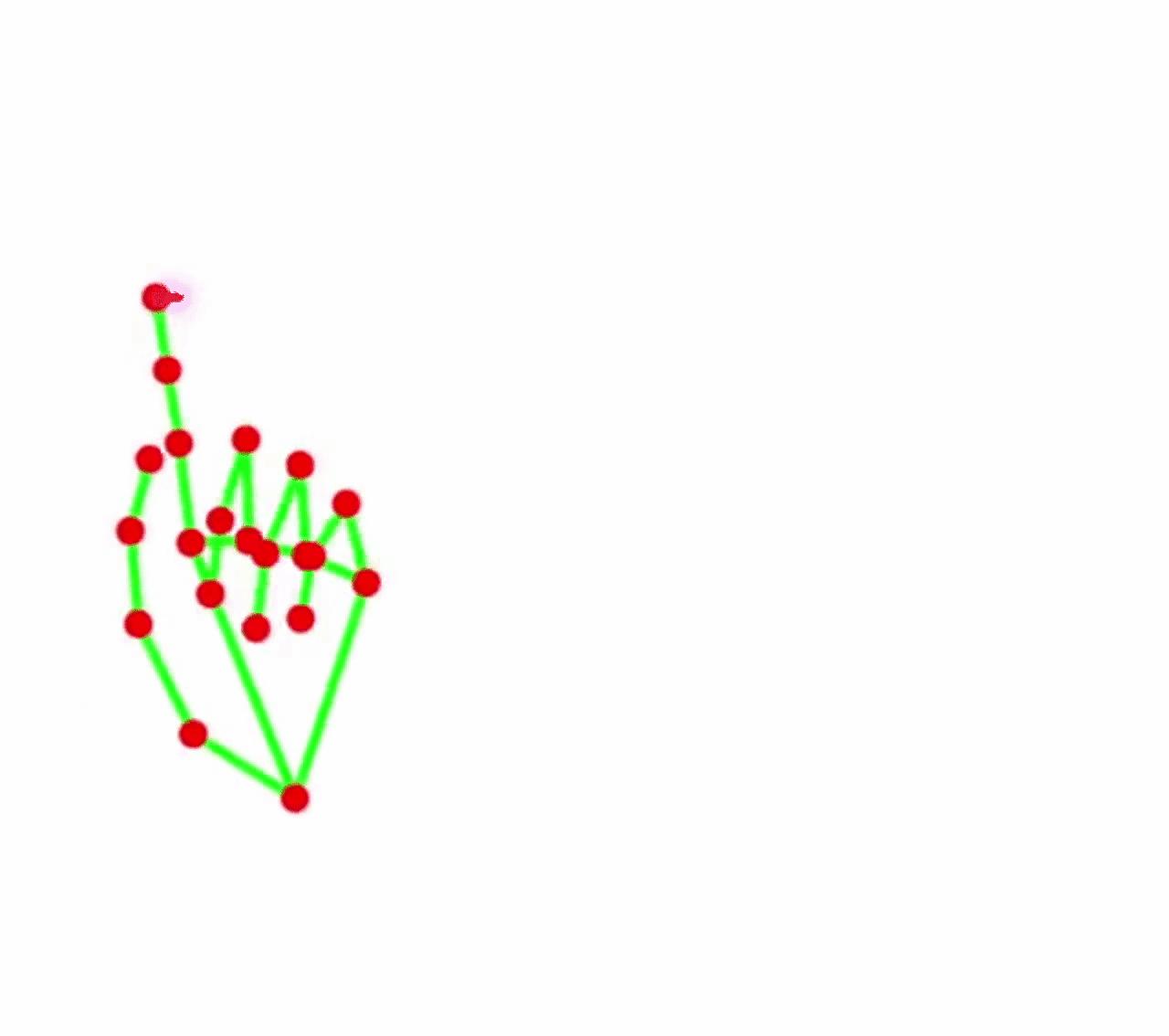
air-drawing:电脑端的手势姿态估计,隔空写字绘图
简介:这个工具使用深度学习来帮助你用你的手和网络摄像头画画和写作。 一个深度学习模型被用来预测用户意图:你是想要笔画(“向下”)还是只是移动你的手(“向上”),随着手指的移动,可以在屏幕上隔空绘制图形。
代码:https://github.com/loicmagne/air-drawing
体验:https://loicmagne.github.io/air-drawing/
RobustVideoMatting:具有时间引导的鲁棒高分辨率视频抠图
简介:来自字节跳动最新研究,RobustVideoMatting专为稳定人物视频抠像设计。不同于现有神经网络将每一帧作为单独图片处理,RVM 使用循环神经网络,在处理视频流时有时间记忆。RVM 可在任意视频上做实时高清抠像。在 Nvidia GTX 1080Ti 上实现 4K 76FPS 和 HD 104FPS。
论文:https://arxiv.org/abs/2108.11515
代码:https://github.com/PeterL1n/RobustVideoMatting
代码:https://peterl1n.github.io/RobustVideoMatting
体验:https://peterl1n.github.io/RobustVideoMatting/#/demo

Omnimatte:谷歌最新视频抠图术,影子烟雾都能抠
简介:计算机视觉在分割图像或视频中的对象方面越来越有效,然而与对象相关的场景效果。比如阴影、反射、产生的烟雾等场景效果常常被忽略。识别这样的场景效果,并将其与产生它们的物体联系起来,对于提高我们对视觉场景的基本理解非常重要,也可以帮助各种应用,如删除、复制或增强视频中的物体。Omnimatte采取一步来解决这个新的问题,自动关联对象和他们的效果在视频中。给定一个普通的视频和一个或多个感兴趣的对象在一段时间内的粗略分割蒙版,该方法估计每个对象的全域图像——一个alpha蒙版和彩*图色**像,包括对象及其所有相关的时变场景元素。模型只以一种自我监督的方式对输入视频进行训练,没有任何手动标签,而且是通用的——它对任意对象和各种效果自动产生无所不在的效果。
论文:https://arxiv.org/abs/2105.06993
代码:https://github.com/erikalu/omnimatte
项目:https://omnimatte.github.io/

CoCosNetv2:“高配版”图像翻译
简介:针对图像翻译(image translation)任务,微软亚洲研究院的研究员们曾在CVPR2020发表的论文中提出了 CoCosNet 算法,解决了图像生成过程中风格精细控制的难题。目前这一基于样例的图像翻译技术再升级,相比第一代算法,CoCosNet v2 能够应用到高清大图的生成过程中,同时也能节省大量的计算内存开销。
论文:https://arxiv.org/abs/2012.02047
代码:https://github.com/microsoft/CoCosNet-v2

GANsNRoses:稳定,可控,多样的图像到图像翻译
简介:来自伊利诺伊大学香槟分校的研究者提出了一种新的GAN迁移方法GANsNRoses(简写为 GNR),这一多模态框架使用风格和内容对映射进行直接的形式化(formalization)。简单来讲,研究者展示了一种以人脸图像的内容代码为输入并输出具有多种随机选择风格代码的动漫形象。大量的定性结果表明,该方法可以产生比SOTA更多样化的风格范围。
论文:https://arxiv.org/abs/2106.06561
代码:https://github.com/mchong6/GANsNRoses
体验:https://gradio.app/hub/AK391/GANsNRoses

GPEN:基于GAN先验嵌入网络的自然人脸盲恢复
简介:从自然中退化的人脸图像中恢复盲人脸是一个非常具有挑战性的问题。由于问题的高病态性和复杂的未知退化,直接训练深度神经网络(DNN)通常不能获得可接受的结果。GPEN提出了一种新的方法,首先学习GAN生成高质量的人脸图像,并将其嵌入到U形DNN中作为先验解码器,然后用一组合成的低质量人脸图像对GAN先验嵌入DNN进行微调。设计GAN块,保证DNN的深层特征和浅层特征分别生成GAN输入的潜码和噪声,控制重建图像的全局人脸结构、局部人脸细节和背景。GPEN易于实现,可以生成视觉逼真的结果。
论文:https://arxiv.org/abs/2105.06070
代码:https://github.com/yangxy/GPEN
体验1:https://huggingface.co/spaces/akhaliq/GPEN
体验2:https://replicate.com/yangxy/gpen

PTI:真实图像的潜在编辑的枢轴调整
简介:最近利用预先训练的StyleGAN的生成能力面部编辑技术被提出。要成功地以这种方式编辑图像,必须首先将图像投射(或倒置)到预先训练的生成器域。然而,事实证明,StyleGAN的潜在空间导致了失真和可编辑性之间的内在平衡,即保持原始外观和令人信服地改变其某些属性之间的平衡。实际上,这意味着将保存ID的面部潜在空间编辑应用于生成器域之外的面部仍然是一个挑战。PTI提出了一种方法来弥补这一差距。该技术略微改变了生成器,以便将域外图像忠实地映射为域内潜在代码。关键的想法是枢轴调整(pivotal tuning),一个简短的训练过程,保持域内潜在区域的编辑质量,同时改变其描述的身份和外观。在枢轴调整反转(PTI)中,初始反向潜码作为枢轴,围绕着生成器进行微调。同时,正则化项保持附近恒等式不变,以局部包含该效应。这种外科手术训练过程最终改变了主要代表身份的外貌特征,而不影响编辑能力。
论文:https://arxiv.org/abs/2106.05744
代码:https://github.com/danielroich/PTI

HifiFace:高保真换脸重建人脸3D信息
简介:HifiFace提出了一种高保真的人脸交换方法,它可以很好地保持源人脸的形状,并产生照片真实感的结果。与现有的人脸交换算法仅使用人脸识别模型来保持身份相似性不同,该方法提出了三维形状感知身份,利用三维mm的几何监督和三维人脸重建方法来控制人脸的形状。同时引入语义人脸融合模块,优化编码器和解码器特征的组合,并进行自适应混合,使结果更加逼真。实验表明,该方法可以保持更好的身份,特别是在人脸形状上,可以产生比以前的最先进的方法更逼真的结果。
论文:https://arxiv.org/abs/2106.09965
项目:https://johann.wang/HifiFace/
代码:https://github.com/mindslab-ai/hififace

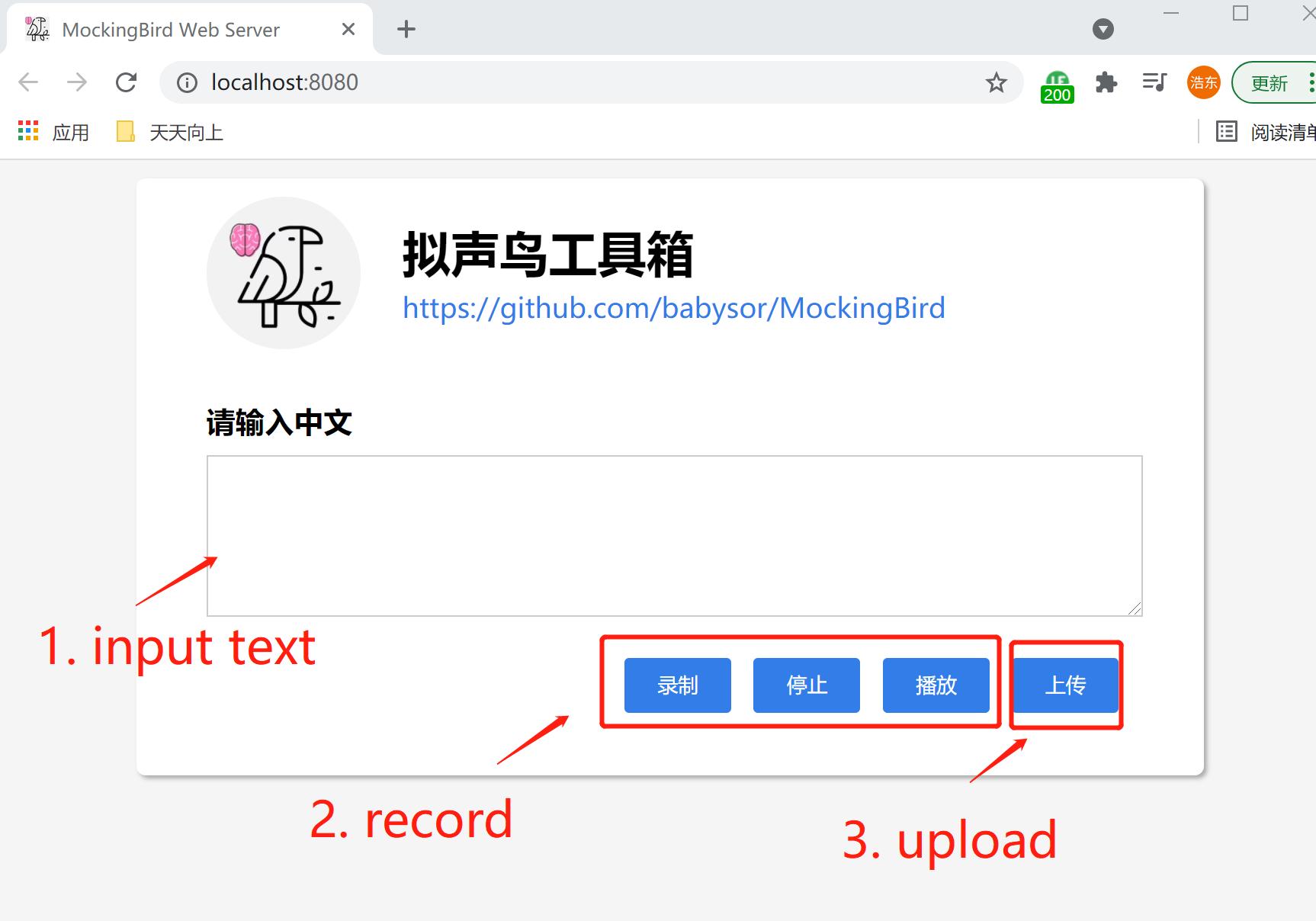
MockingBird:AI拟声,5秒内克隆您的声音并生成任意语音内容
简介:GitHub上有一个项目最近登上了每日趋势榜,只需5秒,就能用AI 技术来模拟声音来生成任意语音内容,并且还支持中文。
代码:https://github.com/babysor/MockingBird
视频:https://www.bilibili.com/video/BV17Q4y1B7mY
EGVSR:高糊视频秒变4K,速度比TecoGAN快了9
简介:EGVSR设计了一种高效通用的VSR网络,提出的EGVSR基于时间一致性的时空对抗学习。为了追求达到4K分辨率的更快的VSR处理能力,尝试选择轻量级的网络结构和高效的上采样方法,在保证高视觉质量的前提下,减少EGVSR网络所需的计算量。此外,在实际硬件平台上实现了批量归一化计算融合、卷积加速算法等神经网络加速技术,以优化EGVSR网络的推理过程。EGVSR实现了4K@29.61FPS的实时处理能力。与目前最先进的VSR网络TecoGAN相比,计算密度降低了85.04%,性能提升了7.92倍。
论文:https://arxiv.org/abs/2107.05307
代码:https://github.com/Thmen/EGVSR

DouZero:用自玩式深度强化学习掌握斗地主
简介:快手团队开发的斗地主AI命名为DouZero,意思是像AlphaZero一样从零开始训练,是一个为斗地主设计的强化学习框架,不需要加入任何人类知识。只用4个GPU,短短几天的训练时间,就在Botzone排行榜上的344个斗地主AI中排名第一。
论文:https://arxiv.org/abs/2106.06135
代码: https://github.com/kwai/DouZero
体验: https://www.douzero.org
SimSwap:一个高效的高保真换脸框架
简介:SimSwap提出了一个高效的框架,旨在实现广义和高保真的人脸交换。相比以前的方法推广到任意的身份,要么缺乏能力或未能保护属性如面部表情和视线方向,该框架能够将一个任意的身份来源脸换到任意一个目标,同时保留目标的属性的脸。实验表明SimSwap能够在保持属性的同时实现竞争身份性能。
论文:https://arxiv.org/abs/2106.06340
代码: https://github.com/neuralchen/SimSwap

DINO:自监督视觉Transformers
简介:Facebook开发的DINO算法,特点是无需对数据进行标记,就能够对 transformers 机器学习模型进行训练。具体说来是,作为计算机视觉领域中最困难的挑战之一,其需要人工智能对图像中的内容进行理解。DINO能够在不指定特定目标的情况下,发现和分割图像/视频中的对象。
论文:https://arxiv.org/abs/2104.14294
代码:https://github.com/facebookresearch/dino

DeepFaceEditing:深脸生成和编辑与解纠缠几何和外观控制
简介:DeepFaceEditing是一种新的基于几何和外观解耦的人脸编辑的方法,可以通过草图自由编辑人脸。基于该方法的智能人脸编辑软件,不需要用户拥有专业的PS技术,就能够通过草图实现面部细节的编辑与控制,并且同时支持个性化的外观定制,从而降低了人脸肖像修图的门槛。
代码:https://github.com/IGLICT/DeepFaceEditing-Jittor
项目:http://www.geometrylearning.com/DeepFaceEditing/

Few-Shot-Patch-Based-Training:基于少镜头训练的交互式视频风格化
简介:先给一张侧脸,再给一张正脸,然后仅仅根据这两张图片,AI处理了一下,便能生成整个运动过程,而且不只是简单的那种,连在运动过程中的眨眼动作也“照顾”得很到位。Few-Shot-Patch-Based-Training提出了一种基于学习的方法来实现基于关键帧的视频风风化,它允许艺术家将风格从几个选定的关键帧传播到序列的其余部分。与以前的样式转换技术相比,该方法不需要任何冗长的训练前过程,也不需要大型的训练数据集。
论文:https://arxiv.org/abs/2004.14489
代码:https://github.com/OndrejTexler/Few-Shot-Patch-Based-Training
项目:https://ondrejtexler.github.io/patch-based_training/

co-mod-gan:基于共调制生成对抗网络的大规模图像补全
简介:图像填充是深度学习领域内的一个热点任务。尽管现有方法对于小规模、稀疏区域的填充可以取得不错的效果,但对于大规模的缺失区域始终无能为力。为解决这一问题,微软亚洲研究院提出了协同调制生成式对抗网络,通过条件和随机风格表示的共调制,在图像条件和最近调制的无条件生成架构之间架起桥梁。这一方法不但能够高质量、多样地填充图像任意规模的缺失区域,同时也能被应用于更广泛的图像转换任务。
论文:https://arxiv.org/abs/2103.10428
代码:https://github.com/zsyzzsoft/co-mod-gan
体验:https://www.microsoft.com/en-us/ai/ai-lab-CoModGAN

faceblit:即时实时的基于示例的风格转移到面部视频
简介:faceblit是一个实时的基于示例的人脸视频风格转移系统,该系统以语义上有意义的方式保留了该风格的纹理细节,即用于描述该风格的特定特征的笔画出现在目标图像的适当位置。与以前的技术相比,该系统保留了目标主题的身份,并实时运行,不需要大型数据集,也不需要冗长的训练阶段。它可以即时地将艺术风格从单个肖像以交互速率传输到目标视频,甚至在移动设备上。
论文:https://dcgi.fel.cvut.cz/home/sykorad/Texler21-I3D.pdf
项目:https://ondrejtexler.github.io/faceblit/
代码:https://github.com/AnetaTexler/FaceBlit

SeFa:隐语义的封闭分解
简介:SeFa检查了由GANs学习的内部表示,以一种无监督的方式揭示潜在的变异因素。特别地,深入研究了GAN的生成机制,并进一步提出了一种通过直接分解训练好的权值来发现潜在语义的封闭式分解算法。SeFa不仅能够找到语义上有意义的维度,与最先进的监督方法相比,而且能够在广泛的数据集上训练的多个GAN模型上产生更多通用的概念。
论文:https://arxiv.org/abs/2007.06600
代码:https://github.com/genforce/sefa
项目:https://genforce.github.io/sefa/

MeInGame:从单个肖像创建游戏角色脸
简介:MeInGame提出了一种自动创建角色人脸的方法,该方法可以预测人脸的形状和纹理,并可以集成到现有的大多数3D游戏中。为了获得逼真度高的纹理,MeInGame提出了一种低成本的人脸纹理获取方法,一种可以将三维mm网格形状转换为游戏形状的形状转移算法,以及一种用于训练三维游戏人脸重构网络的新方法。该方法不仅可以生成与输入人像相似的游戏人物形象,而且可以消除光照和遮挡的影响。
论文:https://arxiv.org/abs/2102.02371
代码:https://github.com/FuxiCV/MeInGame

img2pose:基于6DoF的人脸对齐和检测和姿态估计
简介:img2pose提出了实时、6自由度(6DoF)的三维人脸姿态估计,无需人脸检测或地标定位。估计人脸的6DoF刚性变换是一个比人脸地标检测更简单的问题,通常用于3D人脸对齐。此外,6DoF提供了比面包围框标签更多的信息。在AFLW2000-3D和BIWI上的测试表明,img2pose是实时运行的,并优于目前最先进的人脸姿态估计器。
论文:https://arxiv.org/abs/2012.07791
代码:https://github.com/vitoralbiero/img2pose

FuSta:基于混合神经融合的全帧视频稳像
简介:现有的视频稳定方法通常会产生可见的失真或需要对帧边界进行大幅度裁剪,从而导致视场变小。 FuSta提出了一种帧合成算法来实现全帧视频稳定。 我们首先从相邻帧估计密集的翘曲场,然后通过融合翘曲内容合成稳定的帧。FuSta核心技术创新在于基于学习的混合空间融合,减轻了光流误差和快速移动物体造成的伪影。 在NUS, selfie和DeepStab视频数据集上验证了该方法的有效性。
论文:https://arxiv.org/abs/2102.06205
代码:https://github.com/alex04072000/FuSta
项目:https://alex04072000.github.io/FuSta/
