一.线性回归算法简介
线性回归(Linear Regression)是利用线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为一元线性回归,多于一个自变量情况的叫做多元线性回归。对于参数的求解,需要对函数进行评估以检测是否为最优。一般这个函数被称为损失函数(loss function),用来描述算法好坏的程度。
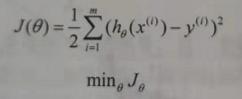
计算损失函数是线性回归的基础,计算损失函数一般使用最小二乘法或梯度下降法。
二.最小二乘法
最小二乘法【最小平方法】是一种数学优化技术。它通过最小化误差的平方来寻找数据的最佳函数匹配。利用最小二乘法可以简便地求出结果,并使得这些求得的结果与实际数据之间误差的平方和最小 。
在Spark ML中,将训练特征转换为矩阵,结果转换为向量,误差函数不变。最小二乘法要求矩阵是列满秩的,而且求矩阵的逆比较慢。
关键概念解释:
- 线性独立【线性无关】:指一组向量中任意一个向量都不能由其它一个或几个向量线性表示。一个矩阵的列秩是矩阵的线性无关的列向量的极大数目,行秩与其类似。矩阵的列秩和行秩总是相等的,可以称为矩阵的秩。
三.梯度下降法
参考头条文章:Python实现随机&批量梯度下降算法
四.线性回归算法代码实现
package org.com.tl.spark.mllib
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.sql.SparkSession
/**
* Created by zhen on 2020/11/25.
*/
object LinearRegressionAnalyse {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("LinearRegressionAnalyse")
.master("local[2]")
.getOrCreate()
val sc = spark.sparkContext
// 加载训练数据
val allData = spark.read.format("libsvm")
.load("D:/spark-2.4.3/data/mllib/sample_linear_regression_data.txt")
allData.count()
val weights = Array(0.8,0.2) //设置训练集和测试集的比例
val split_data = allData.randomSplit(weights) // 拆分训练集和测试集
//随机取样,训练模型
val training = split_data(0)
//随机取样,预测数据
val testing = split_data(1)
// 创建线性回归模型
val lr = new LinearRegression()
.setMaxIter(10) // 最大迭代次数
.setRegParam(0.3) // 正则化参数
.setElasticNetParam(0.8) // 弹性系数
// 训练模型
val lrModel = lr.fit(training)
//各个维度的参数值,类似于一维函数y=ax+b中的a
println(s"Coefficients: ${lrModel.coefficients}")
println(s"Intercept: ${lrModel.intercept}") // 截距
// 模型评估
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}") // RMSE:均方根差
println(s"r2: ${trainingSummary.r2}") // r2:判定系数,也称为拟合优度,越接近1越好
// 预测
val predictions = lrModel.transform(testing)
predictions.show()
sc.stop()
}
}
执行结果:

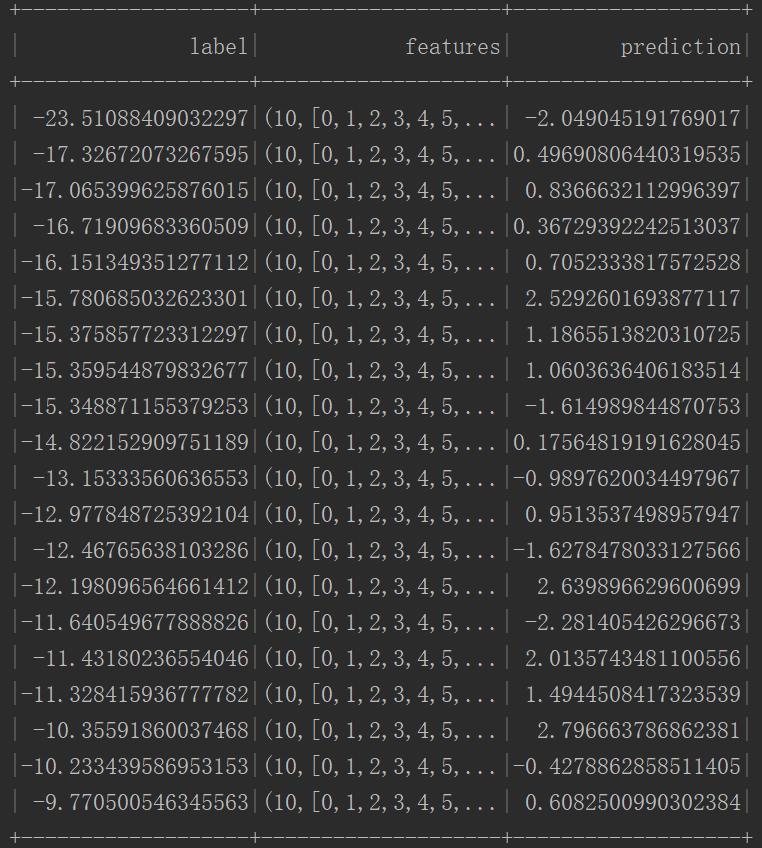
分析结果可以看出,预测的结果是很不理想的,要分析原因,首先看训练数据:

从训练数据中可以看出,首先是训练数据的范围差异较大,第一列的结果值与vector向量参数值之间差异尤为明显;可以使用归一化的方式把数据都转换到0~1之间,实现的代码如下:
/**
* 最大值最小值
*/
val max = allData.select("label").rdd.map(row => row.getAs[Double]("label")).collect().max
val min = allData.select("label").rdd.map(row => row.getAs[Double]("label")).collect().min
val broad_max = sc.broadcast(max)
val broad_min = sc.broadcast(min)
/**
* 定义自定义函数,实现归一化
*/
def normalization(label : Double) = {
val max = broad_max.value
val min = broad_min.value
(label-min) / (max - min)
}
val addNormalization = spark.udf.register("normalization", normalization _)
val normAllData = allData.withColumn("label", addNormalization(allData("label")))
normAllData.count()
五.逻辑回归算法简介
逻辑回归是一种广义线性回归(generalized linear model),因此与多元线性回归分析有很多相同之处。它们的模型形式基本上相同,其区别在于他们的因变量不同,多元线性回归直接将函数结果作为因变量。而逻辑回归则通过函数L将函数结果对应一个隐状态p,然后根据p与1-p的大小决定因变量的值。如果L是逻辑函数,就是逻辑回归,如果L是多项式函数就是多项式回归。

六.逻辑回归算法代码实现
package org.com.tl.spark.mllib
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
/**
* Created by zhen on 2020/11/25.
*/
object LogisticRegressionAnalyse {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.appName("LogisticRegressionAnalyse")
.master("local[2]")
.getOrCreate()
// 加载训练数据
val allData = spark.read.format("libsvm")
.load("D:/spark-2.4.3/data/mllib/sample_libsvm_data.txt")
allData.count()
val weights = Array(0.8,0.2) //设置训练集和测试集的比例
val split_data = allData.randomSplit(weights) // 拆分训练集和测试集
// 创建逻辑回归对象
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// 训练模型
val lrModel = lr.fit(split_data(0))
lrModel.transform(split_data(1))
.select("label", "features", "probability", "prediction")
.show()
val trainingSummary = lrModel.summary
// 评估
val accuracy = trainingSummary.accuracy
val falsePositiveRate = trainingSummary.weightedFalsePositiveRate // 失败率
val truePositiveRate = trainingSummary.weightedTruePositiveRate // 正确率
val fMeasure = trainingSummary.weightedFMeasure // 查全率
val precision = trainingSummary.weightedPrecision // 查准率
val recall = trainingSummary.weightedRecall // 召回率
println(s"Accuracy: $accuracy\nFPR: $falsePositiveRate\nTPR: $truePositiveRate\n" +
s"F-measure: $fMeasure\nPrecision: $precision\nRecall: $recall")
//关闭spark
spark.stop()
}
}
执行结果:
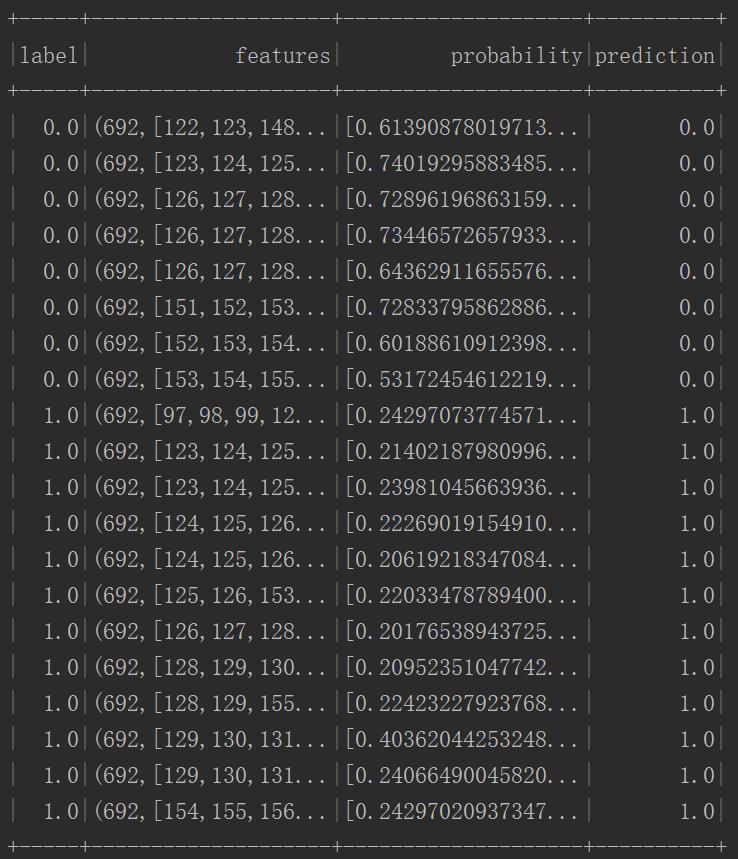
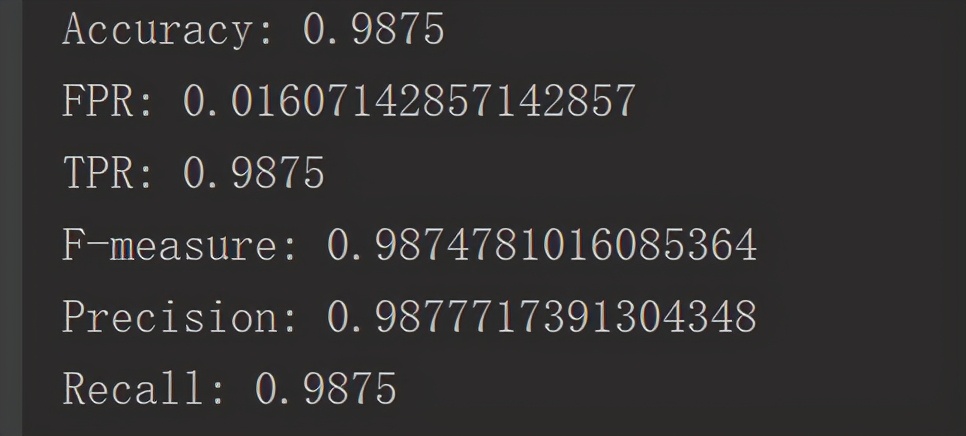
从结果上来看还是令人满意的,先去看看训练数据:

相比于上面线性回归的连续型数据,使用逻辑回归【其实是逻辑分类】对离散型数据做二分类是比较容易的,得到较高的准确率是很正常的表现【毕竟蒙还有50%的准确率。。。】。
七.总结
线性回归算法做回归预测不是一个很好的选择,线性回归一般应用于简单的逻辑,训练数据的维度较小;多维度的分析一般使用逻辑回归或神经网络;下面附上基本算法图鉴: