前段时间,大规模的云服务器宕机故障占领了热搜与程序员们的朋友圈,一大拨程序员、运维专员都从睡梦中被叫醒跑去办公室干活。除了加班的程序员们,其他受到影响的各种应用使用者们也是一头雾水。
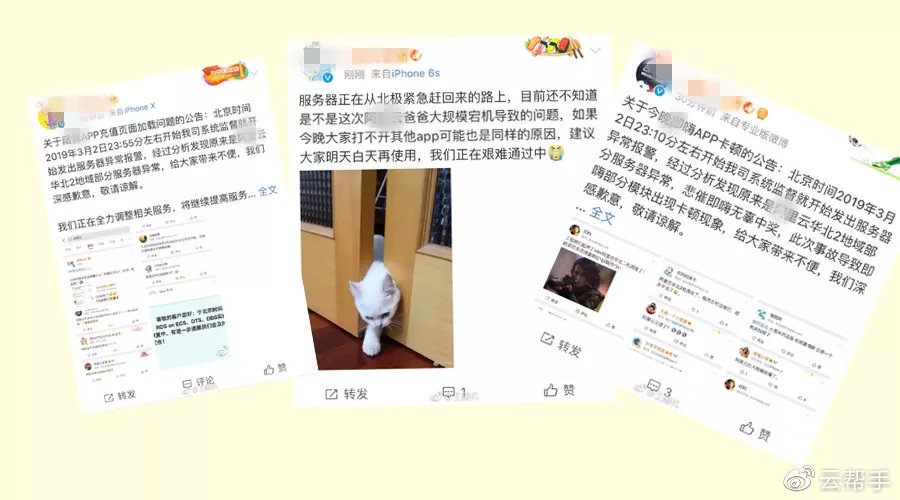
有网友称,疑似阿里云华北2部分机器故障,怀疑是磁盘问题,部分硬盘无法访问,凡是会读写故障盘的系统软件或服务程序,都会收到影响。
▎随后 阿里云官方回应道:
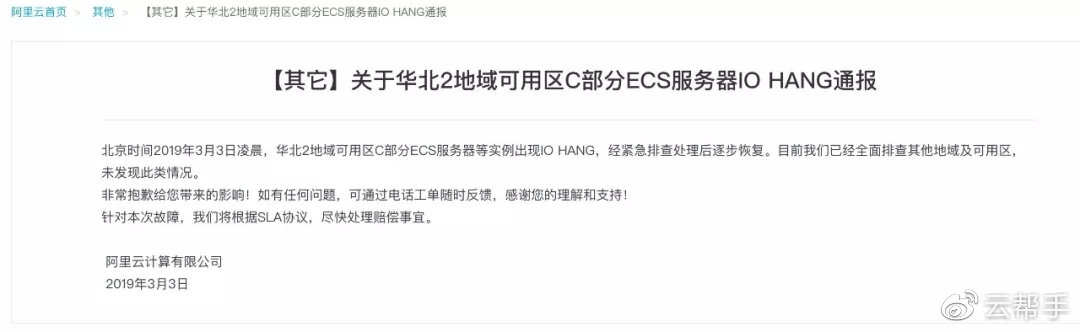
华北2地域可用区C部分ECS服务器等实例出现IO HANG,经紧急排查处理后逐步恢复。目前我们已经全面排查其他地域及可用区,未发现此类情况。
那么问题来了,IO HANG 是个什么鬼?
简单的说,就是服务器磁盘读写过慢,导致线程和进程挂起。大量读写线程/进程挂起导致服务器宕机...
阿里云有大量的类似RDS,HybridDB数据库,支持海量数据在线事务(OLTP)和在线分析(OLAP),需要大量的IO读写,而Linux的IO性能将直接影响SQL的执行速度,严重情况下将导致服务器卡死和宕机。

小到网页加载卡顿,传不了邮件,大到网站,app崩溃,业务停摆。说了这么多,到底什么是宕机?
宕机的常见原因
1、硬件故障,如硬盘故障,电源故障
2、黑客攻击
3、流量负载过大
4、人为误操作
5、程序猿删库跑路
6、地震海啸自然灾害等等
对运营商来说:
1、宕机不可避免,强化预警机制才能最快发现问题。
2、在第一时间发出公告,让用户有所准备,不然只能在爆炸的报障工单与热搜中艰难挽回声誉了。
3、定期的运维检查当然少不了,不断提高系统可靠性依然是现阶段所有云服务商要努力的事情。

站在商业的层面,无论市场如何变化,云服务厂商为客户提供优质服务的内核都不应受到任何影响。在更为复杂的和多元化的云服务方案中,相比现在云服务厂商只与企业对接,未来将不可避免的与同行、友商们站在同一“战壕”,协同作战。这就要求,云服务厂商除了有过硬的技术能力随时帮助企业解决问题之外,还应放弃门户之见,以更为开放的心态与同行合作,服务企业。
近年来,“去运维”的相关讨论甚嚣尘上,有人认为这只是杞人忧天,并反问“阿里云自己都刚宕机,还想说不需要运维吗?”,有人则认为英雄所见略同,还有人进一步将未来的运维阐述成“云维”。
专家认为,运维团队的实力也是云计算服务商的核心竞争力,云计算要求更高的运维能力,能够保障大规模基础设施和业务稳定运行。对于企业用户而言,底层基础设施的运维工作确实可以甩给第三方公有云服务商统一负责,但上层应用的运维工作还需要企业自己来承担,比如环境配置,不过更多的是 DevOps。
技术的发展不能缺少埋头苦干的人,但也少不了抬头看路的人。在云时代,运维人员并不是没有价值,而是会变得更加重要。云计算承诺高弹性、高可用、高性能、智能化,运维的自动化和智能化也是未来的重要发展趋势。
除了提示自身运维能力之外,一款好的运维工具可以帮助运维大大提高工作效率,并能够解决人为不可控制的难题,让服务更有保障。云帮手7*24小时安全巡检、资源监控功能可以帮助运维人员解决值守难、巡检难的问题,并能够根据服务器运行情况及时产生告警,方便运维人员快速反应处理,避免再次出现服务器宕机的问题。
面对不断变化的市场需求,企业需要具备专业的技术团队来更好地将云服务落地,并保证服务的可用性和可靠性,运维人员仍然在公司中具有重要地位。而运维人员必须学会适当的角色转变,选择高效的运维软件来提高效率,并不断学习和提升自己的技能,保持自身的与时俱进,这才是应对万变的根本之道。