
本文原创作者: iot101君
在整条物联网产业链中,芯片无疑是其中最为核心的组成部分,只有拥有了芯片这个大脑,原本愚笨的“物”才能摇身变为在物联网时代大有作为的智能互联设备。粗略来分,物联网芯片可以分为通信芯片和计算芯片两大类,本文将对计算芯片领域的企业进行汇总整理。
随着图像识别、语音识别、车联网等物联网新应用的发展,传统的CPU架构已经无法满足这些日新月异的计算需求,于是,AI芯片借着以“华为mate10”为代表的产品开始逐渐走入大众视野。和需要大量空间去放置存储单元和控制单元而计算单元很少的CPU相比,AI芯片具有大量的计算单元,非常适合大规模并行计算的需求。

CPU和GPU架构对比
基于通用性与计算性能的不同,可以把AI芯片分为GPU、FPGA、ASIC、类脑芯片四大类。

GPU
1,英伟达NVIDIA
芯片: NVIDIA Volta系列、NVIDIA Quadro RTX 系列等
简介:NVIDIA公司是全球可编程图形处理技术领袖,专注于打造能够增强个人和专业计算平台的人机交互体验的产品。公司的图形和通信处理器拥有广泛的市场,已被多种多样的计算平台采用,包括个人数字媒体PC、商用PC、专业工作站、数字内容创建系统、笔记本电脑、*用军**导航系统和视频游戏控制台等。1999 年,NVIDIA 发明了 GPU,这极大地推动了 PC 游戏市场的发展,重新定义了现代计算机图形技术,并彻底改变了并行计算。在人工智能的概念大热后,大家开始广泛使用GPU做深度学习,这使得英伟达的股价从2015年至今飙升了足足10倍。
芯片型号:NVIDIA Volta GV100
芯片架构: Volta
时间节点:于2017年5月年度GTC技术大会上正式发布。
产品介绍:采用台积电专门为NVIDIA定制的12nm FFN新工艺(N代表NVIDIA),集成多达211亿个晶体管,核心面积达到了恐怖的815平方毫米,相比于GP100分别增加了38%、34%。其内部拥有5376个32位浮点核心、2688个64位浮点核心(还是2:1),划分为84组SM阵列、42组TPC阵列、7组GPC阵列,同时搭配336个纹理单元,都比GP100增加了40%,同时还首次加入了672个Tensor Core。Tensor Core是一种新的核心,专门为深度计算操作加入的,更加刚性,不那么弹性,但是依然可以编程。

芯片型号: NVIDIA Quadro RTX 8000/6000/5000 系列
芯片架构:图灵(Turing)
时间节点:2018年8月,在温哥华举行的 SIGGRAPH 2018 专业计算机图形学顶级会议上正式发布。
产品介绍:NVIDIA Quadro RTX 8000/6000/5000 系列是基于NVIDIA 全新的第八代 GPU 架构图灵(Turing)的“全球首款光线追踪 GPU”,其突破性技术包括:
- 全新 RT Core 可实现对象和环境的实时光线追踪,并做到物理上精确的阴影、反射和折射以及全局光照
- Turing Tensor Core 可加速深度神经网络训练和推理,这对于赋力 AI 增强型产品和服务至关重要。
- 全新 Turing Streaming Multiprocessor 架构拥有多达 4608 个 CUDA core,可提供高达 16 teraflops 的计算性能,并行运算每秒 16 万亿次整数运算,以加速模拟真实世界的物理模拟。
- 先进的可编程着色技术可提高复杂视效和图形密集型工作体验。
- 首次采用超快速的三星 16Gb GDDR6 内存,支持更复杂的设计、海量建筑数据集、8K 电影内容等。
- NVIDIA NVLink 可通过高速链路联通两个 GPU,将内存容量扩展至 96 GB,并可通过高达 100GB / s 的数据传输提供更高性能。
- 提供对 USB Type-C 和 VirtualLink 的硬件支持。VirtualLink 是一种新的开放式行业标准,旨在通过单一 USB-C 连接器满足下一代 VR 头显的功率、显示和带宽需求。
- 全新增强型技术可提高 VR 应用性能,这些技术包括可变速率着色(Variable Rate Shading)、多视角渲染(Multi-View Rendering)和 VRWorks Audio。
2,美国超威半导体公司AMD
芯片:AMD Navi系列
简介:美国AMD半导体公司成立于1969年,专门为计算机、通信和消费电子行业设计和制造各种创新的微处理器(CPU、GPU、APU、主板芯片组、电视卡芯片等),以及提供闪存和低功率处理器解决方案。人工智能时代,NVIDIA和Intel两大巨头在拼命争夺市场,AMD则显得有些太过低调。但基于GPU的通用计算在AI领域的巨大优势,AMD也并不是全无机会。
据悉,AMD预计将于2018年推出新一代显卡架构:Navi仙后座,本次的仙后座将会采用7nm工艺,预计是GF的第一代,DUV(深紫外)技术。同时还会集成人工智能专用芯片以提升仙后座在机器学习性能。另外,2017年9月还有消息称,特斯拉将与AMD联手打造自动驾驶芯片,目前芯片进展顺利,特斯拉已经收到了第一批样品,正在进行相关测试工作。

芯片型号:AMD Navi系列
芯片架构:AMD Navi仙后座
时间节点:预计2018年第四季度发布
产品介绍:确定将会采用7nm工艺,GFX10架构,AMD还将在Navi显卡上集成与AI(人工智能)相关的电气化元件以强化自动学习的性能。
FPGA
1,Xilinx(赛灵思)
芯片:珠穆朗玛峰(Everest)
简介:赛灵思是 FPGA、可编程 SoC 及 ACAP 的发明者,Xilinx研发、制造并销售范围广泛的高级集成电路、软件设计工具以及作为预定义系统级功能的IP核。客户使用Xilinx及其合作伙伴的自动化软件工具和IP核对器件进行编程,从而完成特定的逻辑操作。赛灵思首创了现场可编程逻辑阵列(FPGA)这一创新性的技术,并于1985年首次推出商业化产品,眼下Xilinx满足了全世界对 FPGA产品一半以上的需求。
2018年7月18日,赛灵思宣布收购中国 AI 芯片领域的明星创业公司——深鉴科技。有“中国英伟达”之称的AI芯片初创企业将继续在其北京办公室运营。目前,交易金额及细节尚未公布。

芯片型号:珠穆朗玛峰(Everest)
芯片架构:ACAP
时间节点:预计将于2018年内实现流片,2019年向客户交付发货
产品介绍:2018年3月,赛灵思宣布推出全新一代AI芯片架构ACAP,并将基于这套架构推出一系列芯片新品;其中首款代号为“珠穆朗玛峰(Everest)”的AI芯片新品将采用台积电7nm工艺打造,今年内实现流片,2019年向客户交付发货。ACAP是以新一代的FPGA架构位核心,基于ARM架构,结合分布式存储器与硬件可编程的DSP模块、一个多核 SoC以及一个或多个软件可编程且同时又具备硬件灵活应变性的计算引擎,并全部通过片上网络(NoC)实现互连。简单地来讲,ACAP是基于赛灵思的传统优势FPGA芯片,又通过架构、制程等一揽子升级打造的计算引擎,目标是达到在针对性领域远超传统GPU、CPU的计算性能。
2,北京深鉴科技有限公司
芯片:“听涛”、“观海”
简介:深鉴科技成立于2016年,致力于成为国际先进的深度学习加速方案提供者。公司提供基于原创的神经网络深度压缩技术和DPU平台,为深度学习提供端到端的解决方案。通过神经网络与FPGA的协同优化,深鉴提供的嵌入式端与云端的推理平台更加高效、便捷、经济,现已应用于安防与数据中心等领域。
深鉴科技由清华团队创办,自成立以来,深鉴科技已经获得了天使到A+轮的3轮融资,累计融资金额超1亿美金,投资方包括金沙江创投、高榕资本、Xilinx、联发科、清华控股、蚂蚁金服、三星风投等。2018年7月18日,赛灵思宣布收购深鉴科技。
如今,深鉴科技已成长为一家具备神经网络压缩编译工具链、深度学习处理器DPU设计、FPGA开发与系统优化等技术能力的初创公司。其中,最为核心的,即为DPU(Deep Learning Processing Unit),以及神经网络压缩编译技术,它不仅可以将神经网络压缩数十倍而不影响准确度,还可以使用“片上存储”来存储深度学习算法模型,减少内存读取,大幅度减少功耗。目前,深鉴科技的产品主要应用于安防监控与数据中心两大领域。

芯片型号:“听涛”、“观海”
芯片架构:亚里士多德
时间节点:预计2018年下半年发布
产品介绍:“听涛”系列芯片,采用台积电28纳米制程,核心使用深鉴自己的亚里士多德架构,峰值性能1.1瓦 4.1 TOPS
3,百度
芯片:XPU
简介:百度在2017年8月Hot Chips大会上发布了XPU,这是一款256核、基于FPGA的云计算加速芯片。合作伙伴是赛思灵(Xilinx)。XPU采用新一代AI处理架构,拥有GPU的通用性和FPGA的高效率和低能耗,对百度的深度学习平台PaddlePaddle做了高度的优化和加速。据介绍,XPU关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似CPU的灵活性。但目前XPU有所欠缺的仍是可编程能力,而这也是涉及FPGA时普遍存在的问题。到目前为止,XPU尚未提供编译器。
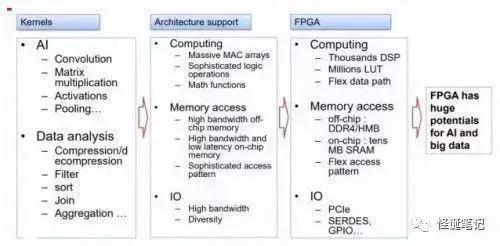
4,英特尔(Altera)
简介:Altera公司(阿尔特拉)是世界上“可编程芯片系统”(SOPC)解决方案倡导者。Altera结合带有软件工具的可编程逻辑技术、知识产权(IP)和技术服务,在世界范围内为14000多个客户提供高质量的可编程解决方案。
2015年12月英特尔斥资167亿美元收购了Altera公司,后来随着收购完成,英特尔也在 Altera 的基础上成立了可编程事业部。此后,英特尔一直在推进 FPGA 与自家至强处理器的软硬件结合并取得了相应的进展。
产品介绍:英特尔采用*管双**齐下的FPGA战略:一方面打造CPU-FPGA混合器件,让FPGA与处理器协同工作;另一方面基于Arria FPGA或Stratix FPGA打造可编程加速卡(PAC/programmable acceleration card)。
基于FPGA技术,英特尔已经构建了一个完善的NFV生态,覆盖软硬件厂商、系统集成商、电信运营商、OTT厂商等相关企业。此外,英特尔还为OME厂商提供一个面向包含FPGA的英特尔至强可扩展处理器的英特尔加速堆栈,进而为客户提供完整的软硬件一体的FPGA解决方案。
英特尔在7月收购芯片公司eASIC后将其并入PSG部门,并随后透露这一收购案主要是为了满足解决客户痛点,满足FPGA客户端的降低成本和能耗需求,并提供可降低16nm、10nm、7nm制程的FPGA产品成本的规模化技术。
目前加速卡还是FPGA进入硬件领域的主要形态之一,不过英特尔已经在进行其他方向、其他形态的探索,并在积极推进和其他数据中心OEM厂商在FPGA方面的合作。
5,莱迪思(Lattice)半导体公司
简介:Lattice(莱迪思半导体公司)创建于1983年,总部位于美国俄勒冈州波特兰市(Portland, Oregon),是全球智能互连解决方案市场的领导者,也是全球第二大FPGA厂,提供市场领先的IP和低功耗、小尺寸的器件,在2015年3月收购多媒体连接供应商----矽映电子(Silicon Image)。Silicon Image不仅在通讯介面有雄厚的基础,同时推动了HDMI、DVI、MHL和WirelessHD等行业标准的制定。
6,Microsemi Corporation
芯片:PolarFire FPGA
简介:Microsemi Corporation总部设于加利福尼亚州尔湾市,是一家领先的高性能模拟和混合信号集成电路及高可靠性半导体设计商、制造商和营销商。Microsemi的产品包括独立元器件和集成电路解决方案等,可通过改善性能和可靠性、优化电池、减小尺寸和保护电路而增强客户的设计能力。Microsemi公司所服务的主要市场包括植入式医疗机构、防御/航空和卫星、笔记本电脑、监视器和液晶电视、汽车和移动通信等应用领域。

产品介绍:2017年2月,Microsemi在京召开新闻发布会,宣布推出PolarFire FPGA,定位低功耗、中等密度产品。
PolarFire有四大优势:1.低功耗,比竞争对手低50%功耗;2.成本优化;3.可靠性与安全性优势;4.逻辑范围扩展至1K-500K LE,因此和竞争对手一样,可覆盖从低密度的CPLD到中密度的FPGA。
ASIC
1,北京中科寒武纪科技有限公司
芯片:寒武纪1H8、寒武纪1H16、寒武纪1M、MLU100
简介:“寒武纪”成立于2016年,是北京中科寒武纪科技有限公司的简称,由中科院计算所孵化,于2017年8月获得了国投、阿里巴巴、联想等共计1亿美元融资,成为估值近10亿美元的智能芯片领域独角兽公司。寒武纪主要面向深度学习等人工智能关键技术进行专用芯片的研发,可用于云服务器和智能终端上的图像识别、语音识别、人脸识别等应用。

公司未来的愿景是让人工智能芯片计算效率提高一万倍,功耗降低一万倍。为了实现这一目标,寒武纪AI芯片能在计算机中模拟神经元和突触的计算,对信息进行智能处理,还通过设计专门存储结构和指令集,每秒可以处理160亿个神经元和超过2万亿个突触,功耗却只有原来的十分之一。未来甚至有希望把类似Alpha Go的系统都装进手机,让手机帮助我们做各种各样的事情,甚至通过长期的观察和学习,真正实现强大的智能。
2016,寒武纪发布了世界上第一个商用深学习处理器IP,即寒武纪1A处理器。2017年,寒武纪授权华为海思使用寒武纪1A处理器,搭载于麒麟970芯片和Mate 10系列手机中。
2017年11月,寒武纪在北京发布了三款新一代人工智能芯片,分别为面向低功耗场景视觉应用的寒武纪1H8,高性能且拥有广泛通用性的寒武纪1H16,以及用于终端人工智能和智能驾驶领域的寒武纪1M。
2018年5 月 3 日,寒武纪科技在上海举办了 2018 产品发布会。会上,寒武纪正式发布了采用 7nm 工艺的终端芯片 Cambricon 1M和首款云端智能芯片 MLU100 。
芯片型号:寒武纪1M
时间节点:2018年5月8日正式发布
产品介绍:1M 使用 TSMC 7nm 工艺生产,其 8 位运算效能比达 5Tops/watt(每瓦 5 万亿次运算)。寒武纪提供了三种尺寸的处理器内核(2Tops/4Tops/8Tops)以满足不同场景下不同量级智能处理的需求,寒武纪称,用户还可以通过多核互联进一步提高处理效能。
寒武纪 1M 处理器延续了前两代 IP 产品(1H/1A)的完备性,可支持 CNN、RNN、SOM 等多种深度学习模型,此次又进一步支持了 SVM、k-NN、k-Means、决策树等经典机器学习算法的加速。这款芯片支持帮助终端设备进行本地训练,可为视觉、语音、自然语言处理等任务提供高效计算平台。据悉,该产品可应用于智能手机、智能音箱、摄像头、自动驾驶等不同领域。
芯片型号:MLU 100云端芯片
芯片架构: MLUv01 架构
时间节点:2018年5月8日正式发布
产品介绍:MLU100 采用寒武纪最新的 MLUv01 架构和 TSMC 16nm 工艺,可工作在平衡模式(主频 1Ghz)和高性能模式(1.3GHz)主频下,等效理论峰值速度则分别可以达到 128 万亿次定点运算/166.4 万亿次定点运算,而其功耗为 80w/110w。与寒武纪系列的终端处理器相同,MLU100 云端芯片具有很高的通用性,可支持各类深度学习和常用机器学习算法。可满足计算机视觉、语音、自然语言处理和数据挖掘等多种云处理任务。搭载这款芯片的板卡使用了 PCIe 接口。
2,华为海思半导体
芯片:麒麟970、麒麟980
芯片型号:麒麟970
时间节点:2017年9月2日在柏林消费电子展上正式对外发布
产品介绍:华为麒麟970是华为于2017年9月2日在柏林消费电子展上正式对外发布的新款内置人工智能(AI)芯片。这款芯片将被用于华为下一代智能手机,主要用于抗衡对手苹果和三星电子公司。该芯片采用了行业高标准的TSMC 10nm工艺,集成了55亿个晶体管,功耗降低了20%,并实现了1.2Gbps峰值*载下**速率。创新性集成NPU专用硬件处理单元,创新设计了HiAI移动计算架构,其AI性能密度大幅优于CPU和GPU。相较于四个Cortex-A73核心,处理相同AI任务,新的异构计算架构拥有约 50 倍能效和 25 倍性能优势,图像识别速度可达到约2000张/分钟。高性能8核CPU,对比上一代能效提高20%。率先商用 Mali G7212-Core GPU,与上一代相比,图形处理性能提升20%,能效提升50%,可以更长时间支持3D大型游戏的流畅运行。

芯片型号:麒麟980
时间节点:2018年8月31日在柏林消费电子展上正式对外发布
产品介绍:麒麟980一上来就达成了六项全球首发记录:
- 全球首款7nm SoC
- 全球首发ARM Cortex-A76 CPU核心
- 全球首发双核NPU
- 全球首发Mali-G76 GPU
- 全球首发1.4Gbps LTE Cat.21基带
- 全球首发支持2133MHz LPDDR4X运行内存
首先,麒麟980采用7nm工艺,集成了69亿个晶体管。据TSMC的官方统计,相比上一代旗舰——10nm工艺制程的麒麟970,980性能提升约20%,能效提升约40%,逻辑电路密度提升60%,即原来的1.6倍。
至于芯片架构,麒麟980首次搭载寒武纪1A的优化版,采用双核结构,其图像识别速度比970提升120%。
而在通用芯片CPU上,980基于ARM Cortex-A76 CPU架构进行开发,性能比970提升75%,能效同步提升58%,比骁龙845性能领先37%,能耗降低32%。这套全新设计的CPU架构麒麟CPU子系统,由2个超大核、2个大核和4个小核的三档能效架构组成。
在GPU上,980成为首款搭载最新的Mali-G76 GPU架构的移动端芯片。和970相比,其GPU性能提升46%,能效提升178%。最直接的感受,就是在玩大型游戏时,不易卡顿。游戏性能的提升,也回应了用户一直以来对其GPU性能的担忧。
3,地平线机器人
芯片:征程(Journey)、旭日(Sunrise)
简介:地平线机器人(Horizon Robotics)由前百度深度学习研究院负责人余凯创办,致力于打造基于深度神经网络的人工智能“大脑”平台。2017年10月,这家公司拿到了英特尔、嘉实投资、高翎资本、红杉资本等近亿美元的A+轮投资。
地平线基于自主研发的人工智能芯片和算法软件,以智能驾驶,智慧城市和智慧零售为主要应用场景, 提供给客户开放的软硬件平台和应用解决方案。为多种终端设备装上人工智能“大脑”,让它们具有从感知、交互、理解到决策的智能。地平线具有世界领先的深度学习和决策推理算法开发能力,将算法集成在高性能、低功耗、低成本的嵌入式人工智能处理器及软硬件平台上。基于创新的人工智能专用处理器架构BPU(Brain Processing Unit ) ,地平线自主设计研发了中国首款全球领先的嵌入式人工智能视觉芯片——面向智能驾驶的征程(Journey) 系列处理器和面向智能摄像头的旭日(Sunrise) 系列处理器,并向行业客户提供“芯片+ 算法+ 云”的完整解决方案。

芯片型号:征程(Journey) 系列
芯片架构:高斯架构
时间节点:2017年12月20日正式发布自动驾驶处理器征程1.0架构;2018北京国际车展期间,地平线发布新一代自动驾驶处理器征程2.0架构,并公布了基于2.0处理器架构的L3级以上自动驾驶计算平台Matrix 1.0。
产品介绍:征程1.0 是面向ADAS的处理器(BPU 1.0,高斯架构),征程2.0 则是面向L3及以上自动驾驶的处理器(BPU 2.0,伯努利架构)。据介绍,内置征程2.0的自动驾驶计算平台Matrix 1.0 结合深度学习技术,支持多传感器融合,可每秒处理720P视频30帧,实时处理4路视频,实现20种不同类型物体的像素级语义分割,功耗为31W,已经达到应用和产品化水平。
芯片型号:旭日(Sunrise) 系列
芯片架构:高斯架构
时间节点:2017年12月20日正式发布
产品介绍:旭日1.0 是一款面向摄像头的 AI 视觉芯片,它基于高斯架构,并集合了地平线的深度学习算法,因而能够在前端实现大规模人脸检测跟踪、视频结构化等应用,可广泛应用于智慧城市、智能商业等场景。
4,北京异构智能科技有限公司
芯片:NovuTensor
简介:NovuMind(异构智能)是由百度前人工智能杰出科学家吴韧博士带领一批全球顶尖的AI技术人才于 2015 年 8 月在美国加州硅谷成立的 AI 公司,主要为汽车、安防、医疗、金融等领域提供 ASIC 芯片,并提供芯片+模型+训练的全栈式 AI 解决方案。2016年12月,NovuMind获得洪泰基金、宽带资本、真格基金、英诺天使和臻迪科技等1500 多万美元的A轮融资,据悉该团队正在进行B轮融资。目前团队共有 50 余人,包括在美国的 35 名以及北京的 15 名顶尖技术工程师。
相较于英伟达的GPU 或 Cadence 的DSP等通用的深度学习芯片设计,NovuMind 专注于开发更有效进行推理 (interference)的深度学习加速器芯片。NovuMind AI 芯片的重点在于,不仅让一个小型的本地“终端”设备具有“看”的能力,而且还具备“思考”以及“识别”的能力,另外,这些都不需要通过数据中心的支持,不占用任何带宽,吴博士将之称为智能物联网(I²oT,Intelligent Internet of Things)。

芯片型号:NovuTensor
时间节点:2018年CES正式发布
产品介绍:NovuMind 方面表示其最新推出的高性能、低功耗的 AI 芯片 NovuTensor是截至目前世界上唯一一款能够实际运行的、性能达到主流 GPU/TPU 水平而性能/功耗比却远超主流 GPU/TPU 的芯片——在功耗 12w 的情况下,NovuTensor 每秒可识别 300 张图像,每张图像上,最多可检测 8192 个目标,相比目前最先进的桌面服务器 GPU(250W,每秒可识别 666 张图像),仅使用 1/20 电力即可达到其性能的 1/2;而相比目前最先进的移动端或嵌入式芯片,相同用电的情况下,性能是其三倍以上。
据了解,本次 CES 展示的仅仅是 FPGA 版本,等正在流片的 ASIC 芯片正式出厂,性能将提高 4 倍,耗电将减少一半,耗能不超过 5 瓦、可进行 15 万亿次运算的超高性能。
5,谷歌
芯片:TPU
简介:谷歌在2016年的I/O大会上推出了专门为加速深层神经网络运算能力而研发的一款AI芯片——张量处理器TPU(第一代)。谷歌表示,尽管在一些应用上利用率很低,初代TPU平均比那时候的GPU或CPU快15-30倍,性能功耗比(TOPS/Watt)高出约30-80倍。
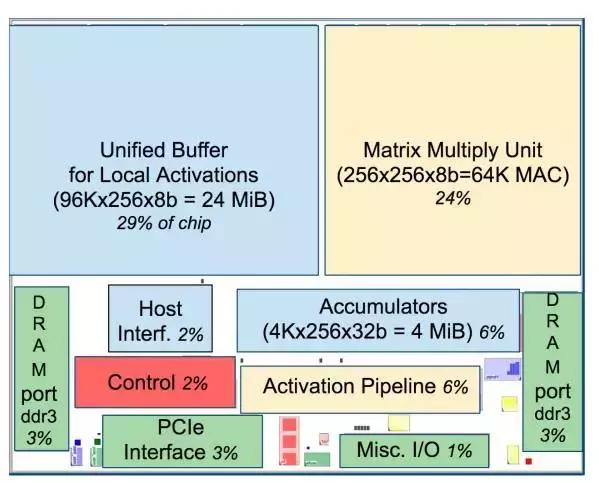
TPU芯片布局图
2017年5月I/O大会上,谷歌发布了第二代TPU,峰值性能达到180TFLOPS/s。第一代TPU只加速推理,但第二代TPU新增了训练的功能。不仅如此,谷歌的用户还能通过专门的网络,在云端利用TPU构建机器学习的超级计算机。
在第二代TPU里,每个TPU都包含了一个定制的高速网络,构成了一个谷歌称之为“TPU舱室”(TPU POD)的机器学习超级计算机。一个TPU舱室包含64个第二代TPU,最高可提供多达11.5千万亿次浮点运算,内存400万兆字节,4倍快于当时市面上最好的32台GPU。
Cloud TPU带来的最大好处,则是谷歌的开源机器学习框架TensorFlow。TensorFlow现在已经是Github最受欢迎的深度学习开源项目,Cloud TPU出现以后,开发人员和研究者使用高级API编程这些TPU,这样就可以更轻松地在CPU、GPU或Cloud TPU上训练机器学习模型,而且只需很少的代码更改。
6,英特尔(Movidius)
简介:Movidius是一家专注于计算机视觉的创业公司,也是谷歌ProjectTango 3D传感器技术背后的功臣。2016年9月,英特尔宣布将收购Movidius。

2017年8月,英特尔发布了下一代Movidius视觉处理芯片,该芯片可提高尖端设备的处理能力,比如无人机、VR头盔、智能摄像头、可穿戴设备和机器人。其上最新的视觉处理单元(Vision Processing Unit,简称VPU)采用的是Myriad X系统级芯片,它配备了一个专用的神经计算引擎,支持边缘深度学习推断。芯片上的硬件块是专门针对深层神经网络而设计的,它以高速和低功耗来运行深层神经网络。英特尔说,深度神经网络加速器可以在DNN推断时实现每秒1万亿次运算。
7,中星微电子有限公司
芯片:NPU
简介:2016年6月20日,中星微率先推出中国首款嵌入式神经网络处理器(NPU)芯片,这是全球首颗具备深度学习人工智能的嵌入式视频采集压缩编码系统级芯片,取名“星光智能一号”。这款基于深度学习的芯片运用在人脸识别上,最高能达到98%的准确率,超过人眼的识别率。该NPU采用了“数据驱动”并行计算的架构,单颗NPU(28nm)能耗仅为400mW,极大地提升了计算能力与功耗的比例。
目前“星光智能一号”出货量主要集中在安防摄像领域,其中包含授权给其他安防摄像厂商部分。未来将主要向车载摄像头、无人机航拍、机器人和工业摄像机方面进行推广和应用。

8,北京云知声信息技术有限公司
芯片:雨燕(Swift)
简介:云知声是一家智能语音识别技术公司,成立于2012年,总部位于北京。

2018年5月16日,云知声在北京正式发布全球首款面向物联网领域的AI芯片“雨燕”(Swift)。作为云知声UniOne系列的第一代物联网AI芯片,“雨燕”完全由云知声自主设计研发,采用云知声自主AI指令集,拥有具备自主知识产权的DeepNet、uDSP(数字信号处理器),支持DNN/LSTM/CNN等多种深度神经网络模型。
除了提供芯片和终端引擎,云知声还将应用部分向客户开源,同时提供相应定制化工具以及云端AI能力服务。通过云端芯结合,“雨燕”将应用于智能家居、智能音箱、智能车载等各个具体场景中。
类脑芯片
1,IBM
芯片:TureNorth
简介:DARPA与IBM合作建立了一个项目,名为“神经形态自适应伸缩可塑电子系统计划(SyNAPSE)”。该计划意图还原大脑的计算功能,从而制造出一种能够模拟人类的感觉,理解,行动与交流的能力的系统,用途非常明确:辅助士兵在战场动态复杂环境中的认知能力,用于无人*器武**的自动作战。
该项目中最引人注目的是类脑芯片TureNorth。2011年,IBM发布第一代TrueNorth芯片,它可以像大脑一样具有学习和信息处理能力,具有大规模并行计算能力。2014年,IBM发布第二代TrueNorth芯片,性能大幅提升,功耗却只有70毫瓦,神经元数量由256个增加到100万个,可编程突触由262144个增加到2.56亿个。高通也发布了Zeroth认知计算平台,它可以融入到高通Snapdragon处理器芯片中,以协处理方式提升系统认知计算性能,实际应用于终端设备上。
2,西井科技
芯片:DeepSouth(深南)、DeepWell(深井)
简介:西井科技是一家开发“类脑人工智能芯片+算法”的科技公司,其芯片用电路模拟神经,成品有100亿规模的仿真神经元。由于架构特殊,这些芯片计算能力强,可用于基因测序、模拟大脑放电等医疗领域。在团队方面,西井科技有50名员工,其中40人是英国帝国理工、牛津、加州大学伯克利分校等相关专业的博士、硕士。据悉,西井科技曾于2015年6月、2016年1月分别获得天使轮和pre-A轮融资。
西井科技是用FPGA模拟神经元以实现SNN的工作方式,有两款产品:
仿生类脑神经元芯片DeepSouth(深南),第三代脉冲神经网络芯片SNN,基于STDP(spike-time-dependentplasticity)的算法构建完整的突触神经网络,由电路模拟真实生物神经元产生脉冲的仿生学芯片,通过动态分配的方法能模拟出高达5000万级别的“神经元”,功耗为传统芯片在同一任务下的几十分之一到几百分之一。
深度学习类脑神经元芯片DeepWell(深井),处理模式识别问题的通用智能芯片,基于在线伪逆矩阵求解算法(OPIUM lite)对芯片中神经元间的连接权重进行学习和调整;拥12800万个神经元,通过专属指令集调整芯片中神经元资源的分配;学习与识别速度远远高于运行在通用硬件(如CPU, GPU)上的传统方法(如CNN),且功耗更低。,
3,高通公司
芯片型号:Zeroth
简介:芯片巨头高通也在进行类脑芯片的研发,早在2013年高通就曾公布一款名为Zeroth的芯片,Zeroth不需要通过大量代码对行为和结果进行预编程,而是通过类似于神经传导物质多巴胺的学习(又名“正强化”)完成的。高通为了让搭载该芯片的设备能随时自我学习,并从周围环境中获得反馈,还为此开发了一套软件工具。在公布的资料中高通还用装载该芯片的机器小车进行了演示,使小车在受人脑启发的算法下完成寻路、躲避障碍等任务。