1、官方文档
https://www.rabbitmq.com/admin-guide.html
2、AMQP 0-9-1 模型解释
生产者:产生数据发送消息的程序。
交换机:是 RabbitMQ 非常重要的一个部件,一方面它接收来自生产者的消息,另一方面它将消息推送到队列中。交换机必须确切知道如何处理它接收到的消息,是将这些消息推送到特定队列还是推送到多个队列,亦或者是把消息丢弃,这个得有交换机类型决定。
队列:队列是 RabbitMQ 内部使用的一种数据结构,尽管消息流经 RabbitMQ 和应用程序一样,但它们只能存储在队列中。队列仅受主机的内存和磁盘限制的约束,本质上是一个大的消息缓冲区。许多生产者可以将消息发送到一个队列,许多消费者可以尝试从一个队列接收数据。
惰性队列:https://www.rabbitmq.com/lazy-queues.html;
消费者:大多数时候是一个等待接收消息的程序。请注意生产者,消费者和消息中间件很多时候并不在同一机器上。同一个应用程序既可以是生产者又可以是消费者。
模型解释文档 https://www.rabbitmq.com/tutorials/amqp-concepts.html
发布者文档 https://www.rabbitmq.com/publishers.html
消费者 https://www.rabbitmq.com/consumers.html
队列 https://www.rabbitmq.com/queues.html
协议扩展 https://www.rabbitmq.com/extensions.html
3、工作原理
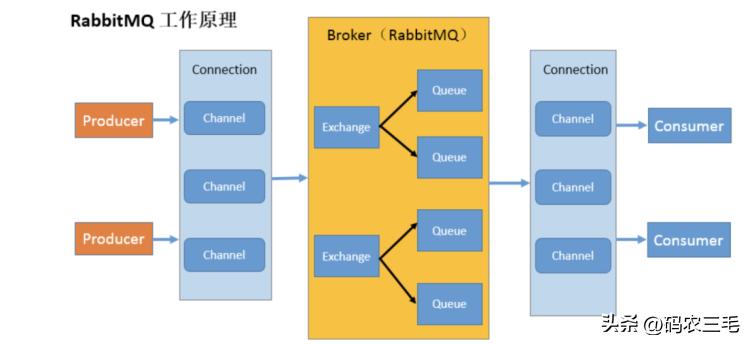
Broker:接收和分发消息的应用, RabbitMQ Server 就是 Message Broker Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当多个不同的用户使用同一个 RabbitMQ server 提供的服务时,可以划分出多个 vhost,每个用户在自己的 vhost 创建 exchange/ queue 等 Connection: publisher/ consumer 和 broker 之间的 TCP 连接

https://www.rabbitmq.com/connections.html 涉及mq性能调优。
Channel:如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCPConnection 的开销将是巨大的,效率也较低。 Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的 channel 进行通讯, AMQP method 包含了 channel id 帮助客户端和 message broker 识别 channel,所以 channel 之间是完全隔离的。 Channel 作为轻量级的Connection 极大减少了操作系统建立 TCP connection 的开销
https://www.rabbitmq.com/channels.html Exchange: message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到 queue 中去。常用的类型有: direct (point-to-point), topic (publish-subscribe) and fanout(multicast) Queue: 消息最终被送到这里等待 consumer 取走
https://www.rabbitmq.com/queues.html Binding: exchange 和 queue 之间的虚拟连接, binding 中可以包含 routing key, Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
https://www.rabbitmq.com/tutorials/amqp-concepts.html google翻译成中文不妨碍阅读

4、业务用途
4.1、应用解耦
解决多个系统链式调用耦合导致整个业务失败的情况。解决多个系统链式调用耦合导致整个业务失败的情况。
4.2、异步处理
4.3、流量削峰
4.4、监控
文档 https://www.rabbitmq.com/monitoring.html
5、性能调优
https://www.rabbitmq.com/runtime.html
6、MQ扩展
https://www.rabbitmq.com/extensions.html
6.1、持久化
从内存持久化消息到硬盘(生产者),再从硬盘加载到内存(消费者)。

6.2、不公平分发
RabbitMQ默认是轮训分发模式,就是两个消费者轮流接受消息,但是这种模式在某些场景下是不恰当的,如果其中一个消费者执行的时间很长,而消息的产生有很快,就会导致大量消息的堆积,效率很低,是不科学的
为了避免上述情况的出现,我们应使用不公平分发 (能者多劳)
//设置为不公平分发
/* * 0:默认,表示轮训分发 * 1:表示不公平分发 **/
channel.basicQos(1);
6.3、预取值
该值定义通道上允许的未确认消息的最大数量,一旦数量达到配置的数量, RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认
也就是说,定义一个信道上的最大数量是5,则信道中最多只能有5个待消费的消息
/** 0:默认,表示轮训分发* 1:表示不公平分发* 大于2:表示预取值**/
channel.basicQos(5);//表示最大只能有5个待处理的消息
6.4、发布确认
生产者将信道设置成 confirm 模式,一旦信道进入 confirm 模式,所有在该信道上面发布的 消息都将会被指派一个唯一的 ID(从 1 开始),使生产者知道消息已经正确到达目的队列,
如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出0
confirm 模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信 道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调 方法来处理该确认消息,如果 RabbitMQ 因为自身内部错误导致消息丢失,就会发送一条 nack 消 息,生产者应用程序同样可以在回调方法中处理该 nack 消息。
代码示例 https://www.jianshu.com/p/2c5eebfd0e95
错误示例