在阅读此文之前,麻烦您点击一下“关注”,既方便您进行讨论和分享,又能给您带来不一样的参与感,感谢您的支持。

文 | 晓池扶玥
编辑 | 晓池扶玥
前言
介绍使用MNIST数据集构建的经典和连续可变量(CV)量子神经网络混合多分类器。目前已有的分类器只能对两个类别进行分类。提出的架构允许网络对多达nm个类别进行分类,其中n表示截断维度,m表示光学量子计算机上的qumodes数量。CV模型中截断维度和概率测量方法的组合使得量子电路能够产生大小为nm的输出向量。

这些向量被解释为 使用one-hot编码的标签, 并用nm-10个零进行填充。文章构建了七个不同的分类器,使用了2、3、...、6和8个qumodes在光学量子计算模拟器上,这些分类器基于“连续变量量子神经网络”中提出的二分类器架构。它们由经典前馈神经网络、量子数据编码电路和CV量子神经网络电路组成。
4-qumode的混合分类器
在一个截断的MNIST数据集上,一个4-qumode的混合分类器实现了100%的训练准确率。与最初的假设相反,量子计算机并不会取代经典计算机,量子处理单元(QPUs)正在成为类似图形处理单元的特定任务专用处理单元。
目前可用的QPUs被称为近期量子设备,因为它们尚未完全容错,并且具有浅层和短量子电路的特点。这些设备的可用性使得可以积极研究针对它们的特定量子算法,特别是在 量子化学、高斯波色子采样、图优化和量子机器学习方面。

QPUs基于量子计算的两种不同理论模型:离散变量(基于量子比特)模型和连续变量模型[2]。离散变量模型是计算空间从{0, 1}扩展到二维复数空间,具有计算基 {|0⟩, |1⟩}[3]。连续变量模型将计算空间扩展到无限维的希尔伯特空间,其计算基是无限的,即 {|0⟩, |1⟩, ⋯, |n⟩, ⋯}。信息通道(qumode)的量子态由这些基态的无限复合线性组合表示。
在实践中,它通过仅使用有限的基态 {|0⟩, |1⟩, ⋯, |n⟩} 的有限线性组合来近似。用于近似的基态数量称为截断维度。在具有截断维度n的m-qumode系统上,计算状态空间的维数为nm。通过改变截断维度和用于计算的qumode数量,可以 控制计算空间的维度。

在量子计算机上实现机器学习算法是一个活跃的研究领域。可以在具有参数化量子门的变分量子电路上实现量子机器学习算法。 量子电路是一组量子门, 通过电路引起的量子态的变化被认为是量子计算。通过测量提取的量子计算结果被合并到在经典电路上执行的优化和参数更新计算中。
量子神经网络
量子神经网络(QNN)是量子机器学习的一个子集,遵循相同的架构框架:在QPUs上的QNN和在CPU上的优化。经典神经网络的主要组件可以描述为 L(x)=ϕ(Wx+b),其中包括仿射变换 Wx+b 和非线性激活函数 ϕ(⋅)。在量子比特模型中,所有可用的幺正门都是线性的,因此无法直接实现偏置添加和非线性激活函数。

在连续变量模型中, 位移门实现了偏置添加, 而Kerr门实现了非线性激活函数。模型中自然嵌入了 L(x)=ϕ(Wx+b) 的量子版本 L(|x⟩)=|ϕ(Wx+b)⟩。所提出的连续可变量(CV)MNIST分类器是基于Xanadu的X8模拟器构建的,该模拟器模拟了一个8-qumode的光学量子计算机。
根据qumode的数量和截断维度的概念,可以控制输出向量的大小,从而产生MNIST数据集的one-hot编码标签。介绍了不同的架构,从2个qumodes、3个qumodes一直到8个qumodes。是经典-量子混合网络,由经典前馈神经网络、量子数据编码电路和CV量子神经网络电路组成,遵循Killoran等人提出的CV二分类器的架构。
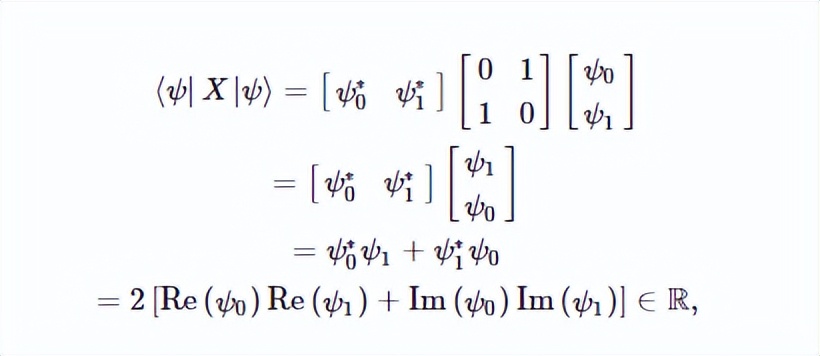
量子机器学习软件库PennyLane 用于量子电路,Tensorflow Keras用于经典电路和优化。 这些分类器在训练中实现了95%以上的准确率。组织结构如下:讨论量子计算的CV模型,特别是计算状态空间的无限维度以及截断维度的概念如何控制每个计算实例的空间维度。详细讨论CV模型的量子神经网络的细节。介绍七个混合分类器的架构和实验结果。
CV模型的量子状态空间是一个无限维的希尔伯特空间,为了实际的信息处理目的,它被有限维空间近似表示。在该模型的相空间表示下,计算基态是高斯态,而不是单个点。将这些高斯态变换为高斯态的量子门提供了比量子比特模型中的幺正(线性)变换更丰富的变换方式。
电磁场的量子态作为信息载体
CV模型基于自然的波动性质。它使用玻色模式(qumodes)的电磁场的量子态作为信息载体。其物理实现是使用包含多个qumodes的线性光学。每个qumode中以概率方式包含一定数量的光子,通过量子门进行计算操作。
光子是一种电磁辐射形式。 位置波函数Ψ(x)描述了qumode中光波的电磁强度,取决于其中存在的光子数量,表示为Ψ:R→C:x↦α,其中x是光子的位置。它是关于实值变量的复值函数。多于一个光子的波函数显示了光子之间的构造性和破坏性干涉。
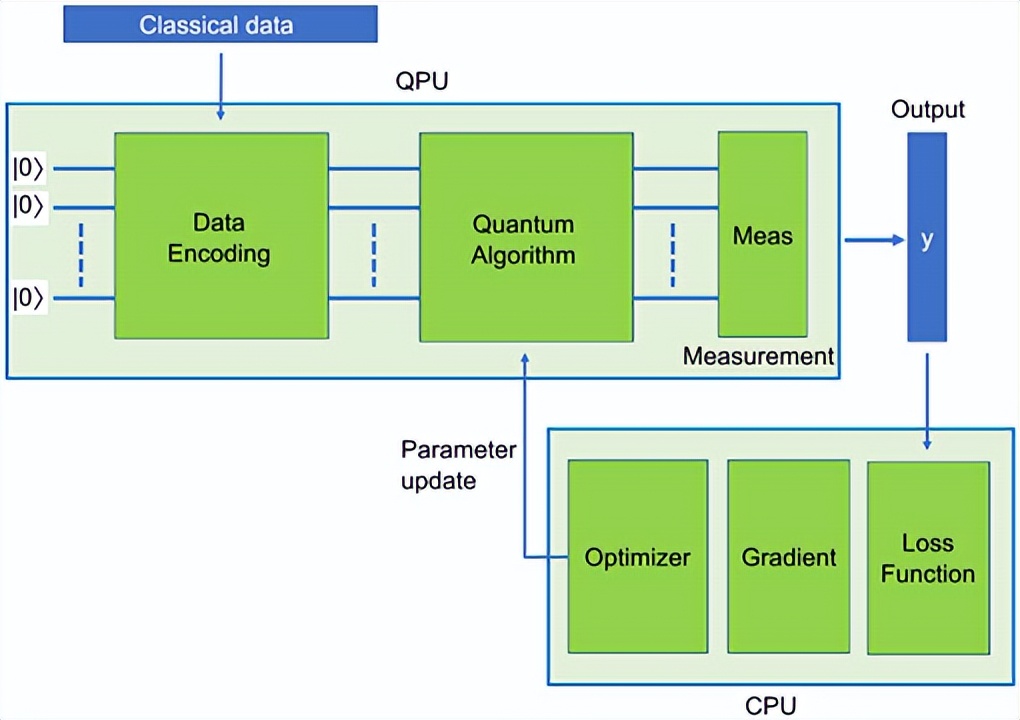
机器学习是一种通过学习最优参数的数学表达式,从数据中提取隐藏的模式的方法。用于模式提取的数学表达式称为机器学习算法。通过训练学习到的具有最优参数的算法称为模型。随着云上提供的近期设备,现在可以在量子计算机或模拟器上执行量子机器学习(QML)算法。
QML算法是由可变电路构成的,即由参数定义操作的参数化电路。训练是“学习”电路参数的过程,以便为新的数据样本产生尽可能准确的推断。在QPU上运行的可变电路的测量结果被发送到CPU进行参数优化,即 计算目标函数、梯度和新参数。 更新的参数被反馈给量子电路,以调整参数化电路用于下一次迭代。
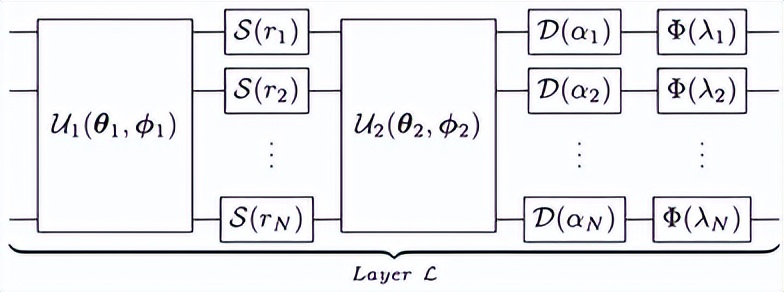
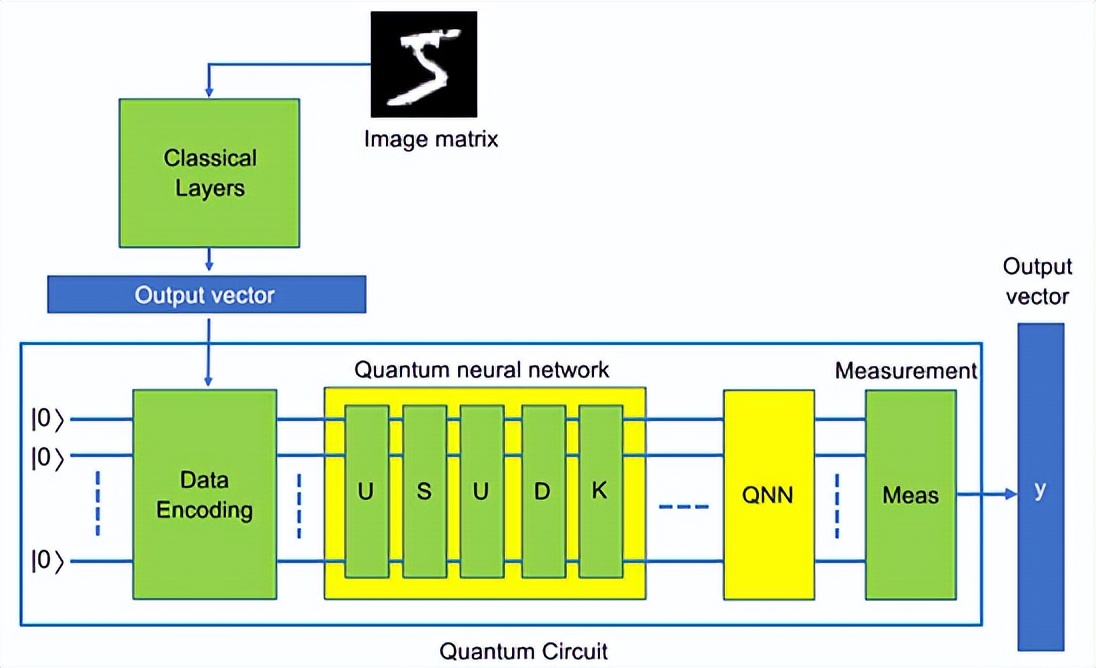
图2显示了该过程的示意图。Google和Xanadu提供了专门用于量子机器学习的基于Python的软件包:TensorFlow Quantum(Google)和PennyLane(Xanadu)。神经网络是机器学习算法的一个子集,由一系列层组成,每一层由仿射变换Wx+b和非线性激活函数ϕ(⋅)组成。神经网络的每一层可以用数学方式描述为L(x)=ϕ(Wx+b)。
非线性激活函数
一个层的输出被作为输入传递到下一层。整个网络是不同层的组合:L(x)=Lm∘Lm−1∘⋯∘L1(x)。对于具有m层的网络,矩阵W和偏置向量b的条目是 通过迭代训练过程中学习到的参数。 目标是找到一组最优参数{W1,W2,⋯,Wm,b1,b2,⋯,bm},用于具有m层的网络。在量子神经网络中,目标是将经典数学表达式L(x)=ϕ(Wx+b)实现为量子态L(|x⟩)=|ϕ(Wx+b)⟩。
在CV模型中,嵌入了量子门,可以直接实现表达式L(|x⟩)=|ϕ(Wx+b)⟩。仿射变换Wx+b通过D∘U2∘S∘U1的组合来实现, 其中Uk表示第k个干涉仪, S表示一组m个压缩器,D表示一组m个位移门。非线性激活函数ϕ(|⋅⟩)通过一组Kerr门来实现,这些门是非线性的。ϕ∘D∘U2∘S∘U1作用于量子态|x⟩可以得到所需的态L(|x⟩)=|ϕ(Wx+b)⟩。
相位无关的干涉仪Uk对量子态|x⟩=⊗mk=1|xk⟩的作用相当于在|x⟩上施加一个正交矩阵操作。正交矩阵就是具有实值条目的幺正矩阵,可以产生保持长度不变的旋转。正交矩阵的转置表示原矩阵的逆向旋转是正交的。U2∘S∘U1的组合可以看作是O2∘S∘(OT1)T的组合,其中O2和OT1是正交矩阵。

假设想要用 量子电路实现线性变换矩阵W。 任何矩阵W都可以使用奇异值分解分解为W=UΣV∗,其中U和V∗是正交的,Σ是对角矩阵。参数化的压缩器S(rk)作用于量子态|xk⟩的效果为S(rk)|xk⟩=e^(-rk/2)|e^(-rk/2)xk⟩,对于每个第k个qumode。它们共同具有对|x⟩=⊗mk=1|xk⟩作用的对角矩阵S=S1⊗S2⊗⋯⊗Sm。U2∘S∘U1实现了量子版本的线性变换矩阵W。
偏置添加使用位移门D来实现。位移门对第k个qumode的效果为D(αk)|ψk⟩=|ψk+√2αk⟩。然后对于αT=[α1,α2,⋯,αm],D(α)|ψ⟩=|ψ+√2α⟩。对于一些期望的偏置b,取α=b/√2,则位移门的集合实现了偏置添加。D∘U2∘S∘U1作用于量子态|x⟩可以得到仿射变换。

qumodes组成的Xanadu X8光子量子模拟器
在由8个qumodes组成的Xanadu X8光子量子模拟器上运行。有两个模型用于对八个类别进行分类,另外五个模型用于对十个类别进行分类。这些模型的测量输出向量被解释为图像标签的one-hot编码预测。八类别分类器使用了3个qumodes和8个qumodes进行构建,这是由于使用不同测量方法可以得到这些结构的不同输出大小。
经典神经网络被用作预处理步骤,将原始的28×28=784大小的图像矩阵降维为较短的向量,以适应数据编码电路的要求。 对于数据编码电路,使用了压缩器、干涉仪、位移门和Kerr门。 对于量子神经网络,使用了实现L(|x⟩)=|ϕ(Wx+b)⟩的量子电路,就像二元分类器中一样。
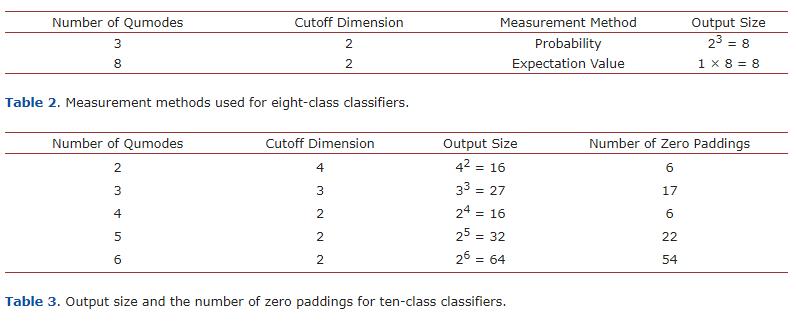
十类别分类器建立在2、3、…、6个qumodes上。图像矩阵的标签k∈{0,1,⋯,9}经过one-hot编码转换后变成长度为10的向量,除了第k个条目为1外,其他都为0。为了使输出向量的长度超过10,选择了适当的截断维度。对于每个分类器,根据电路的输出大小,用不同数量的零填充到one-hot编码标签中。
图6中的架构描述了数据流程:图像矩阵 → 经典层 → 缩小的输出向量 → 数据编码 → 量子神经网络 → 测量 → 输出向量作为one-hot编码标签。方框U、S、D和K分别代表干涉仪、一组m个压缩器、一组m个位移门和一组m个Kerr门,其中m是qumode的数量。
量子数据编码电路
经典神经网络的输出向量处于 经典状态。 量子数据编码电路将经典状态转换为量子态。用于数据编码的量子门包括压缩器、干涉仪、位移门和Kerr门。经典向量的条目被用作这些参数化量子门的参数。
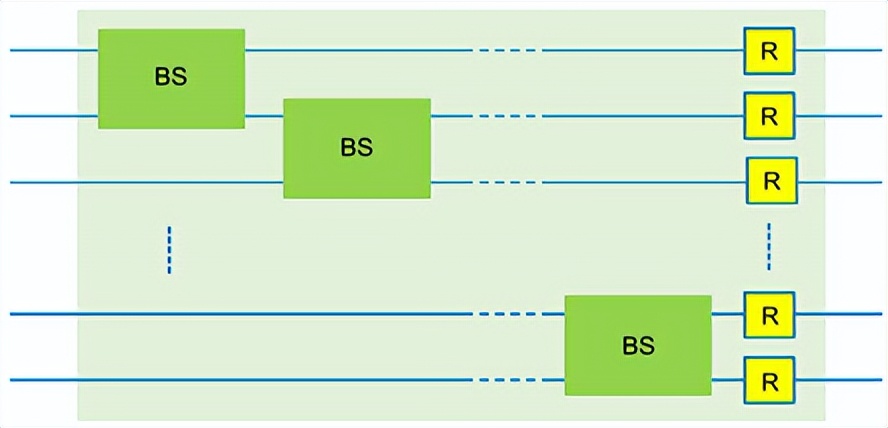
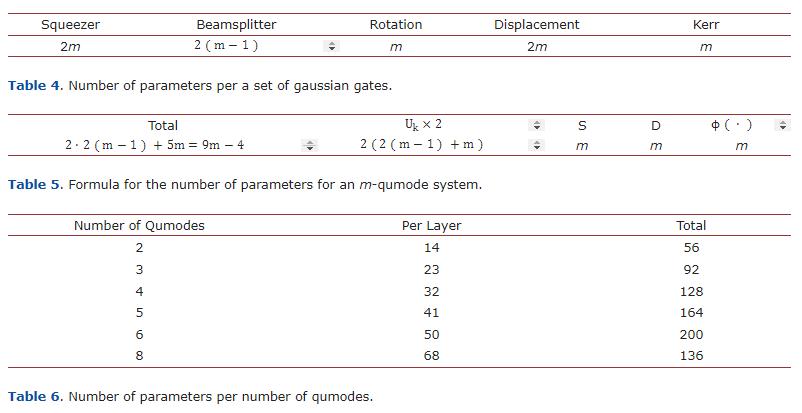
干涉仪由相邻qumode的分束器和旋转矩阵组成。压缩器S(z)和位移门D(α)可以被视为单参数门或双参数门,当参数z、α∈C转换为Euler公式z=a+bi=r(cosθ+isinθ)=reiθ时。在提出的电路中,它们被用作双参数门。这些门可以容纳的参数数量对于m-qumode电路为8m−2,如表4所示。
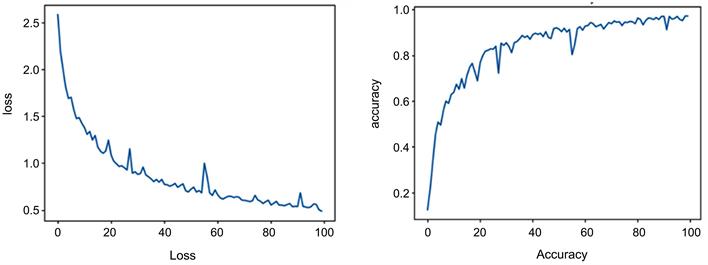
基于这些值,确定了 经典网络输出向量的大小。 在600个数据样本上,4-qumode分类器的训练准确率达到100%。使用Tensorflow Quantum和Qiskit进行qubit-based二元分类器的准确率比较列在表7中。
所有经过测试的分类器都实现了超过95%的训练准确率。对于8-qumode分类器,使用了300个样本和两层QNN,进行了50个epochs的训练。对于其他分类器,使用了600个样本和四层QNN。使用4-qumode分类器,70个epochs就实现了100%的训练准确率。
结论
研究使用不同数量的qumodes和截断维度的经典和CV混合量子分类器。贡献在于提出并成功实现了能够处理多于两个类别的量子神经网络分类器。目前可用的量子神经网络架构只能对最多两个类别进行分类。
CV模型中可用的量子门可以自然地实现量子神经网络层L(|x⟩)=|ϕ(Wx+b)⟩。不同测量方法 产生不同长度的输出向量的灵活性 使得网络能够生成被解释为one-hot编码标签的结果。因此,任何具有截断维度n和m个qumodes的CV量子神经网络都能够对多达nm个类别进行分类。
在近期设备中将经典数据编码为量子态存在限制,这是由于Xanadu的X8光子量子处理器上的qumode数量目前为8个。经典网络被用于减少图像矩阵中的条目数量,以便进行量子数据编码。尽管经典网络的作用是预处理,但通过训练过程学习的大部分参数位于经典网络方面。
将图像矩阵的所有条目编码的一种方法是 迭代处理图像的较小部分, 这自然地引出了卷积操作。量子卷积网络层和量子神经网络层的组合是实现纯量子网络的一种方式。在从经典到量子实现机器学习算法时,CV模型相比基于qubit的模型具有许多优势。CV模型中qumode的量子计算态空间是无穷维的,而基于qubit的模型中只有二维。
参考文献
[1] Killoran, N., Bromley, T., Arrazola, J., Schuld, M., Quesada, N., & Lloyd, S. (2019). 连续变量量子神经网络. 《物理评论研究》, 1, 文章编号: 033063.
[2] Weedbrook, C., 等. (2012). 高斯量子信息. 《物理评论快报》, 84, 621.
[3] Nielsen, M., & Chuang, I. (2010). 量子计算与量子信息. 剑桥大学出版社, 剑桥.
[4] Schuld, M., Bocharov, A., Svore, K., & Wiebe, N. (2018). 电路为中心的量子分类器. 《物理评论A》,101,文章编号: 032308.
[5] Bergholm, V., 等. (2018). PennyLane: 混合量子-经典计算的自动微分. arXiv:1811.04968.