
作者:陈熹
来源:早起Python
大家好,今天分享一个实用的办公脚本: 将多个PDF合并为一个PDF ,例如我手上现在有如下3个PDF分册,需要整合成一个完整的PDF

如果换成你操作的话,是不是打开百度搜索:PDF合并,然后去第三方网站操作,可能会收费不说还担心文件泄漏,现在有请Python出场,简单快速,光速合并,拿走就用!
首先导入需要的库和路径设置
importos
fromPyPDF2importPdfFileReader,PdfFileWriter
if__name__=='__main__':
#设置存放多个pdf文件的文件夹
dir_path=r'C:\ScientificResearch\Knowladge\Ophthalmology\ChineseOphthalmology'
#目标文件的名字
file_name="中华眼科学(第3版)合并版.pdf"
接着获取所有pdf文件的绝对路径,这里需要利用os库中的os.walk遍历文件和os.path.join拼接路径
fordirpath,dirs,filesinos.walk(dir_path):
print(dirpath)
print(files)
#结果返回当前路径、当前路径下文件夹,并以列表返回所有文件

建议直接将需要合并的pdf放在一个文件夹,这样就无需再对文件后缀进行判断,包装成函数后如下:
defGetFileName(dir_path):
file_list=[os.path.join(dirpath,filesname)\
fordirpath,dirs,filesinos.walk(dir_path)\
forfilesnameinfiles]
returnfile_list
调用该函数的结果

现在建立合并PDF的函数
defMergePDF(dir_path,file_name):
#实例化写入对象
output=PdfFileWriter()
outputPages=0
#调用上一个函数获取全部文件的绝对路径
file_list=GetFileName(dir_path)
forpdf_fileinfile_list:
print("文件:%s"%pdf_file.split('\\')[-1],end='')
#读取PDF文件
input=PdfFileReader(open(pdf_file,"rb"))
#获得源PDF文件中页面总数
pageCount=input.getNumPages()
outputPages+=pageCount
print("页数:%d"%pageCount)
#分别将page添加到输出output中
foriPageinrange(pageCount):
output.addPage(input.getPage(iPage))
print("\n合并后的总页数:%d"%outputPages)
#写入到目标PDF文件
print("PDF文件正在合并,请稍等......")
withopen(os.path.join(dir_path,file_name),"wb")asoutputfile:
#注意这里的写法和正常的上下文文件写入是相反的
output.write(outputfile)
print("PDF文件合并完成")
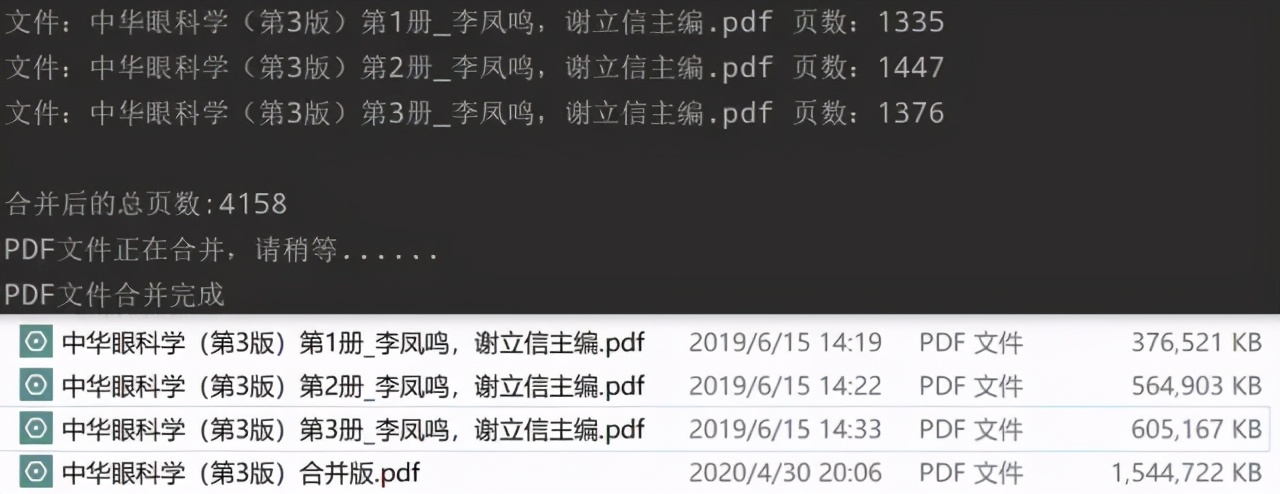
可以看到虽然待合并的PDF文件比较大,但是依旧快速的合并成功!最后附上完整代码,只需将代码中PDF的路径和文件名修改即可使用!
importos
fromPyPDF2importPdfFileReader,PdfFileWriter
defGetFileName(dir_path):
file_list=[os.path.join(dirpath,filesname)\
fordirpath,dirs,filesinos.walk(dir_path)\
forfilesnameinfiles]
returnfile_list
defMergePDF(dir_path,file_name):
output=PdfFileWriter()
outputPages=0
file_list=GetFileName(dir_path)
forpdf_fileinfile_list:
print("文件:%s"%pdf_file.split('\\')[-1],end='')
#读取PDF文件
input=PdfFileReader(open(pdf_file,"rb"))
#获得源PDF文件中页面总数
pageCount=input.getNumPages()
outputPages+=pageCount
print("页数:%d"%pageCount)
#分别将page添加到输出output中
foriPageinrange(pageCount):
output.addPage(input.getPage(iPage))
print("\n合并后的总页数:%d"%outputPages)
#写入到目标PDF文件
print("PDF文件正在合并,请稍等......")
withopen(os.path.join(dir_path,file_name),"wb")asoutputfile:
#注意这里的写法和正常的上下文文件写入是相反的
output.write(outputfile)
print("PDF文件合并完成")
if__name__=='__main__':
#设置存放多个pdf文件的文件夹
dir_path=r'C:\ScientificResearch\Knowladge\Ophthalmology\ChineseOphthalmology'
#目标文件的名字
file_name="中华眼科学(第3版)合并版.pdf"
MergePDF(dir_path,file_name)