R语言实战-02-回归诊断-优化模型
目录
- ☸ A 模型比较
- ☸ B 变量选择
- ☸ B1 逐步回归
- ☸ B2 全子集回归
- ☸ C 深层分析
- ☸ C1 交叉验证
- ☸ C2 相对重要性
本系列是对 《R语言实战》感兴趣部分的阅读笔记,学习的目的在于理解函数,理解图像含义
在了解了可以怎么评价模型以后,我们来看看改怎么根据评价优化模型
在本节内容会学下面的七种方法,然后缓一缓,在后面一篇文章把前面的内容总结一下
☸ A 模型比较
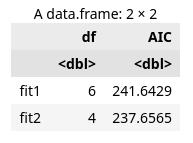
书上讲,可以用基础安装中的anova()函数可以比较两个嵌套模型的拟合优度。在states的多元回归模型中,我们发现Income和Frost的回归系 数不显著,此时你可以检验不含这两个变量的模型与包含这两项的模型预测效果是否一样好
#用anova()函数比较
states <- as.data.frame(state.x77[,c("Murder","Population",
"Illiteracy","Income","Frost")])
fit1 <- lm(Murder ~ Population + Illiteracy + Income +Frost,
data=states)
fit2 <- lm(Murder ~ Population + Illiteracy,data=states)
anova(fit2,fit1)
# 模型1嵌套在模型2中。anova()函数同时还对是否应该添加Income和Frost到线性模型中进行了检验。
# 由于检验不显著(p=0.994),
# 我们可以得出结论:
# 不需要将这两个变量添加到线性模型中,可以将它们从模型中删除。

同时提示可以用AIC(Akaike Information Criterion,赤池信息准则)也可以用来比较模型,它考虑了模型的统计拟合度以及用来拟合的参数数目。AIC值较小的模型要优先选择,它说明模型用较少的参数 获得了足够的拟合度。
☸ B 变量选择
从大量候选变量中选择最终的预测变量有以下两种流行的方法:逐步回归法(stepwise method)和全子集回归(all-subsets regression)
☸ B1 逐步回归
逐步回归中,模型会一次添加或者删除一个变量,直到达到某个判停准则为止。
例如,
- 向前逐步回归(forward stepwise regression)每次添加一个预测变量到模型中,直到添加变量不会使 模型有所改进为止。
- 向后逐步回归(backward stepwise regression)从模型包含所有预测变量开始, 一次删除一个变量直到会降低模型质量为止。
- 向前向后逐步回归(stepwise stepwise regression, 通常称作逐步回归,以避免听起来太冗长),结合了向前逐步回归和向后逐步回归的方法,变量 每次进入一个,但是每一步中,变量都会被重新评价,对模型没有贡献的变量将会被删除,预测 变量可能会被添加、删除好几次,直到获得最优模型为止。
#向后回归
library(MASS)
states <- as.data.frame(state.x77[,c("Murder","Population",
"Illiteracy","Income","Frost")])
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost,
data=states)
stepAIC(fit,direction="backward")
result:
Start: AIC=97.75
Murder ~ Population + Illiteracy + Income + Frost
Df Sum of Sq RSS AIC
- Frost 1 0.021 289.19 95.753
- Income 1 0.057 289.22 95.759
<none> 289.17 97.749
- Population 1 39.238 328.41 102.111
- Illiteracy 1 144.264 433.43 115.986
Step: AIC=95.75
Murder ~ Population + Illiteracy + Income
Df Sum of Sq RSS AIC
- Income 1 0.057 289.25 93.763
<none> 289.19 95.753
- Population 1 43.658 332.85 100.783
- Illiteracy 1 236.196 525.38 123.605
Step: AIC=93.76
Murder ~ Population + Illiteracy
Df Sum of Sq RSS AIC
<none> 289.25 93.763
- Population 1 48.517 337.76 99.516
- Illiteracy 1 299.646 588.89 127.311
Call:
lm(formula = Murder ~ Population + Illiteracy, data = states)
Coefficients:
(Intercept) Population Illiteracy
1.6515497 0.0002242 4.0807366
开始时模型包含4个(全部)预测变量, 然后每一步中,AIC列提供了删除一个行中变量后模型的AIC值, <none> 中的AIC值表示没有变量删除时模型的AIC。 第一步,Frost被删除,AIC从97.75降低到95.75; 第二步,Income被删除,AIC继续下降,成为93.76。 然后再删除变量将会增加AIC,因此终止选择过程。
☸ B2 全子集回归
顾名思义,全子集回归是指所有可能的模型都会被检验。分析员可以选择展示所有可能的结果,也可以展示n个不同子集大小(一个、两个或多个预测变量)的最佳模型。例如,若nbest=2, 先展示两个最佳的单预测变量模型,然后展示两个最佳的双预测变量模型,以此类推,直到包含 所有的预测变量。 全子集回归可用leaps包中的regsubsets()函数实现。你能通过R平方、调整R平方或 Mallows Cp统计量等准则来选择“最佳”模型。
R平方含义是预测变量解释响应变量的程度; 调整R平方与之类似,但考虑了模型的参数数目。R平方总会随着变量数目的增加而增加。当与样本量相比,预测变量数目很大时,容易导致 过拟合。R平方很可能会丢失数据的偶然变异信息,而调整R平方则提供了更为真实的R平方估计。 另外,Mallows Cp统计量也用来作为逐步回归的判停规则。广泛研究表明,对于一个好的模型, 它的Cp统计量非常接近于模型的参数数目(包括截距项)
#全子集回归
install.packages("leaps")
library(leaps)
states <- as.data.frame(state.x77[,c("Murder","Population", "Illiteracy","Income","Frost")])
leaps <-regsubsets(Murder ~ Population + Illiteracy + Income +
Frost, data=states, nbest=4)
plot(leaps, scale="adjr2")
library(car)
subsets(leaps,statistic="cp",
main="Cp Plot for All Subsets Regression")
abline(1,1,lty=2,col="red")
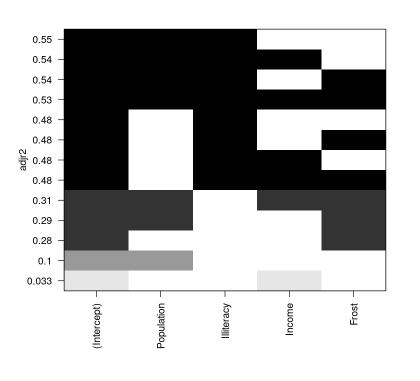
我发现书中这段解读很关键,需要多看几次
。第一行中(图底部开始),可以看到含intercept(截距项)和Income的模型调整R平方为0.33,含intercept和Population的模型调整R平方为0.1。 跳至第12行,你会看到 含intercept、Population、Illiteracy和Income的模型调整R平方值为0.54,而仅含intercept、Population 和Illiteracy的模型调整R平方为0.55。 此处,你会发现含预测变量越少的模型调整R平方越大(对 于非调整的R平方,这是不可能的)。图形表明,双预测变量模型(Population和Illiteracy)是最佳 模型。
☸ C 深层分析
☸ C1 交叉验证
我需要大段的引用来说明为什么要使用交叉验证
若你最初的目标只是描述性分析,那么只需要做回归模型的选择和解释。但当目标是预测时,你肯定会问:“这个方程在真实世界中表现如 何呢?”提这样的问题也是无可厚非的。 从定义来看,回归方法本就是用来从一堆数据中获取最优模型参数。对于OLS回归,通过使得预测误差(残差)平方和最小和对响应变量的解释度(R平方)最大,可获得模型参数。由于 等式只是最优化已给出的数据,所以在新数据集上表现并不一定好。 我们讨论了一个例子,生理学家想通过个体锻炼的时间和强度、年龄、性别与BMI来预测消耗的卡路里数。如果用OLS回归方程来拟合该数据,那么仅仅是对一个特殊的观测 集最大化R平方,但是研究员想用该等式预测一般个体消耗的卡路里数,而不是原始数据。你知 道该等式对于新观测样本表现并不一定好,但是预测的损失会是多少呢?你可能并不知道。通过 交叉验证法,我们便可以评价回归方程的泛化能力。
所谓交叉验证,即将一定比例的数据挑选出来作为训练样本,另外的样本作保留样本,先在 训练样本上获取回归方程,然后在保留样本上做预测。由于保留样本不涉及模型参数的选择,该 样本可获得比新数据更为精确的估计。
在k重交叉验证中,样本被分为k个子样本,轮流将k–1个子样本组合作为训练集,另外1个子 样本作为保留集。这样会获得k个预测方程,记录k个保留样本的预测表现结果,然后求其平均值。 (当n是观测总数目,且k为n时,该方法又称作刀切法,jackknifing。)
bootstrap包中的crossval()函数可以实现k重交叉验证。
install.packages("bootstrap")
#R平方的k重交叉验证
shrinkage <- function(fit, k=10){
require(bootstrap)
theta.fit <- function(x,y){lsfit(x,y)}
theta.predict <- function(fit,x){cbind(1,x)%*%fit$coef}
x <- fit$model[,2:ncol(fit$model)]
y <- fit$model[,1]
results <- crossval(x, y, theta.fit, theta.predict, ngroup=k)
r2 <- cor(y, fit$fitted.values)^2
r2cv <- cor(y, results$cv.fit)^2
cat("Original R-square =", r2, "\n")
cat(k, "Fold Cross-Validated R-square =", r2cv, "\n")
cat("Change =", r2-r2cv, "\n")
}
states <- as.data.frame(state.x77[,c("Murder", "Population",
"Illiteracy", "Income","Frost")])
fit <- lm(Murder ~ Population + Income + Illiteracy + Frost, data=states)
shrinkage(fit)
fit2 <- lm(Murder ~ Population + Illiteracy, data=states)
shrinkage(fit2)
result:
Original R-square = 0.5669502
10 Fold Cross-Validated R-square = 0.4782075
Change = 0.0887427
Original R-square = 0.5668327
10 Fold Cross-Validated R-square = 0.5274321
Change = 0.03940053
通过选择有更好泛化能力的模型,还可以用交叉验证来挑选变量。例如,含两个预测变量 (Population和Illiteracy)的模型,比全变量模型R平方减少得更少(0.03 vs. 0.12)
☸ C2 相对重要性
本章我们一直都有一个疑问:“哪些变量对预测有用呢?”但你内心真正感兴趣的其实是: “哪些变量对预测最为重要?”潜台词就是想根据相对重要性对预测变量进行排序。这个问题很 有实际用处。例如,假设你能对团队组织成功所需的领导特质依据相对重要性进行排序,那么就 可以帮助管理者关注他们最需要改进的行为。
若预测变量不相关,过程就相对简单得多,你可以根据预测变量与响应变量的相关系数来进行排序。但大部分情况中,预测变量之间有一定相关性,这就使得评价变得复杂很多。
评价预测变量相对重要性的方法一直在涌现。最简单的莫过于比较标准化的回归系数,它表示当其他预测变量不变时,该预测变量一个标准差的变化可引起的响应变量的预期变化(以标准 差单位度量)。在进行回归分析前,可用scale()函数将数据标准化为均值为0、标准差为1的数 据集,这样用R回归即可获得标准化的回归系数。(注意,scale()函数返回的是一个矩阵,而 lm()函数要求一个数据框,你需要用一个中间步骤来转换一下。)

此处可以看到,当其他因素不变时,文盲率一个标准差的变化将增加0.68个标准差的谋杀率。 根据标准化的回归系数,我们可认为Illiteracy是最重要的预测变量,而Frost是最不重要的。