上章搭好了整个构架,这章主要列出思路和网址爬取
首先,列下思路吧;你做一个程序,肯定需要知道怎么做,需要哪些功能,这个一定要在自己心里有个普,最好是写下来;
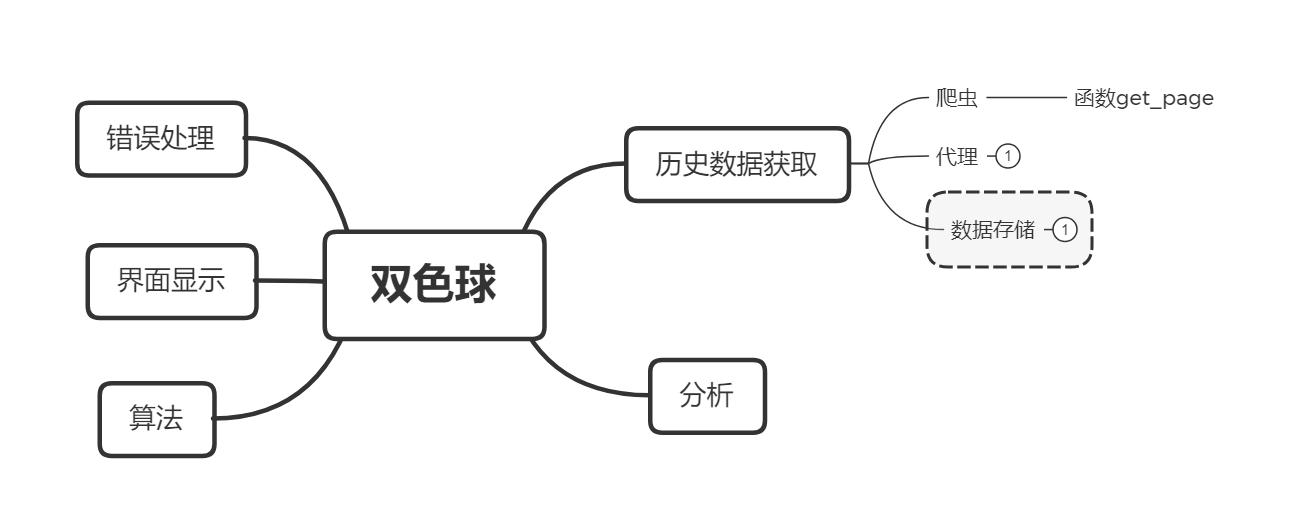
我大致写了5个方向,5个主要的功能,再逐项的展开:
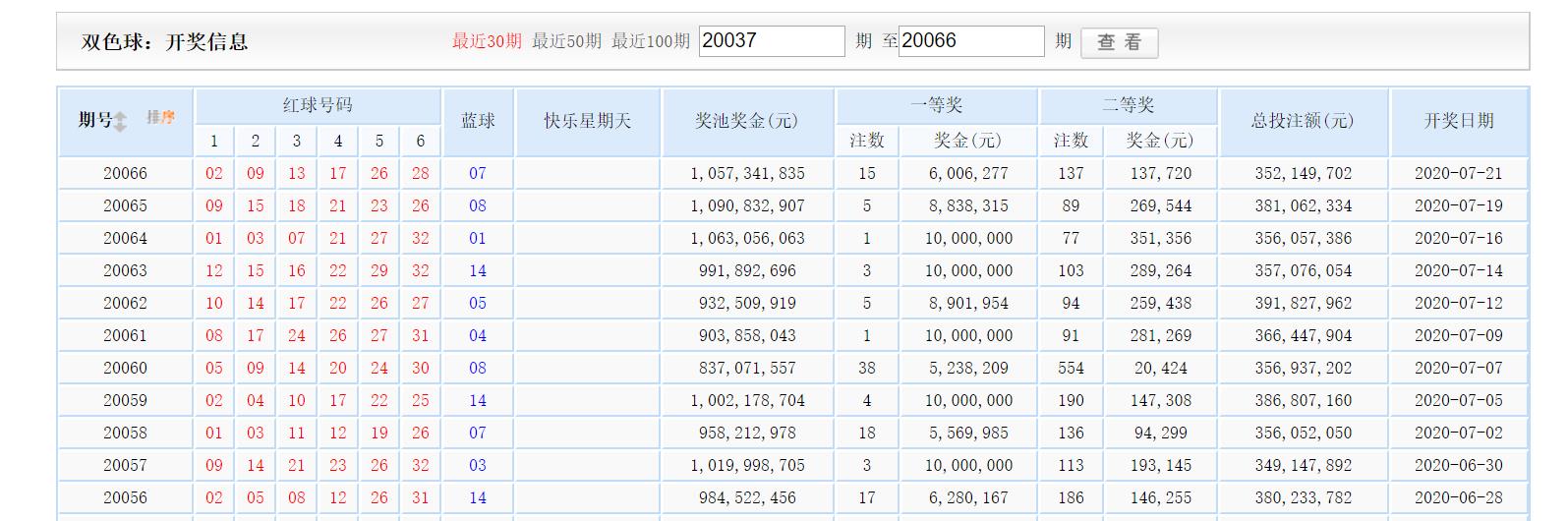
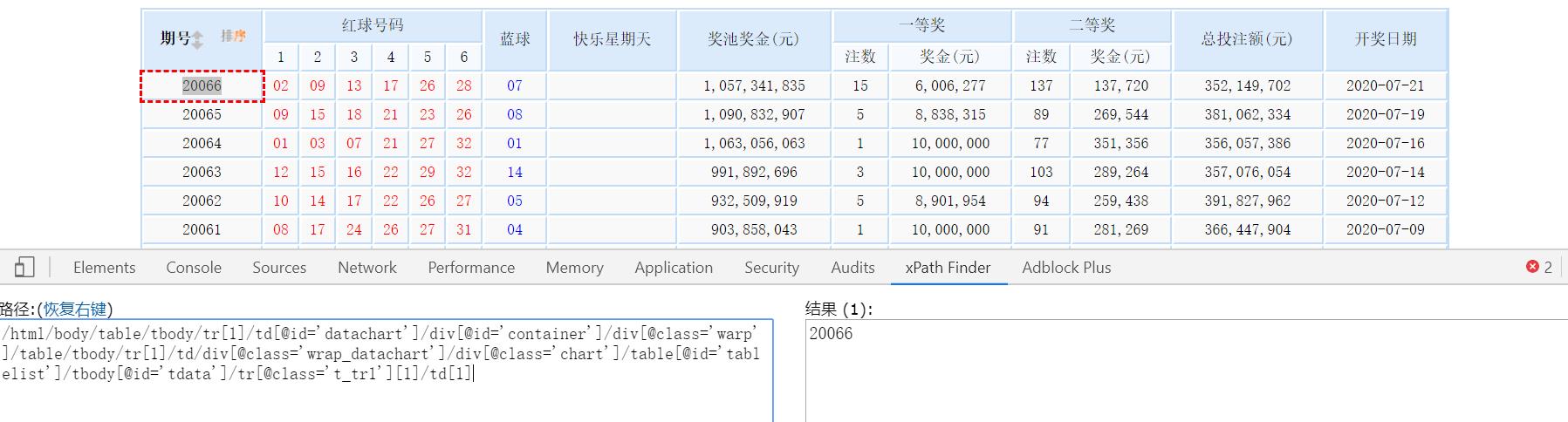
首先实现第一个功能,get_page()函数,他主要实现什么功能呢,一,获取指定网址的内容,二,转换分析为我想要的数据;首先看看我们的网页http://datachart.500.com/ssq/history/history.shtml;大家发现了吧,这就是我们想要的数据
首先输入我们需要的库:
import requests
from lxml import etree
这两个库是比较经典的爬虫库,request处理网络链接,lxml处理分析网页的文本数据;
request获取相关的网页requests.get(url,……),这个函数很简单,就可以直接获得你想要的网页,然后返回网页的内容;lxml里面最重要的函数,etree.HTML(网页结果).xpath(),展开网页,获取相关信息,并以列表的形式返回;
#coding=utf-8
import requests
from lxml import etree
def get_page(url):
html=requests.get(url)
html.encoding="gb2312"
return html.text
if __name__=='__main__':
html=get_page('http://datachart.500.com/ssq/history/history.shtml')
print(html)
我们看看出来的是什么结果
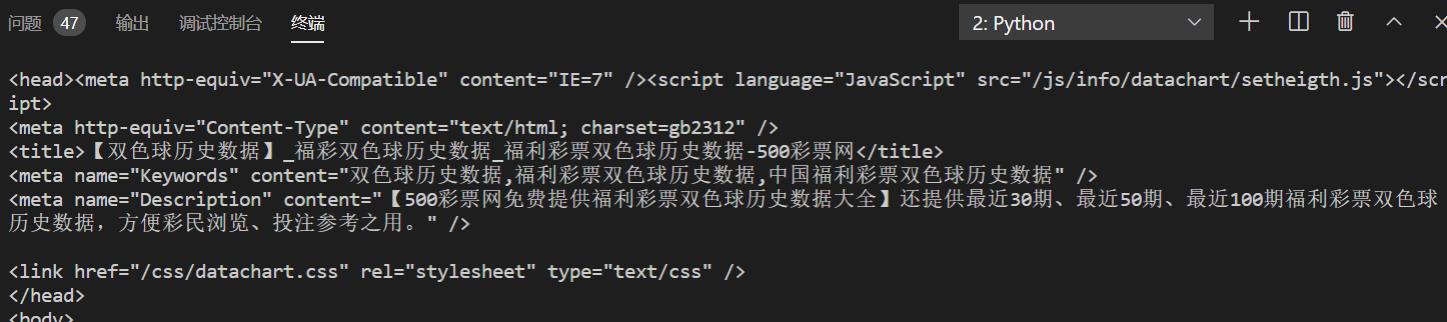
数据已经出来,是不是跟我们右键看网页的源码一样啊
现在问题来了,我们怎么去获取相关行列的信息呢?用刚才说的XPath,我这里有一个简单的返回,装360极速浏览器,安装XPath控件,在打开的网页按F12,
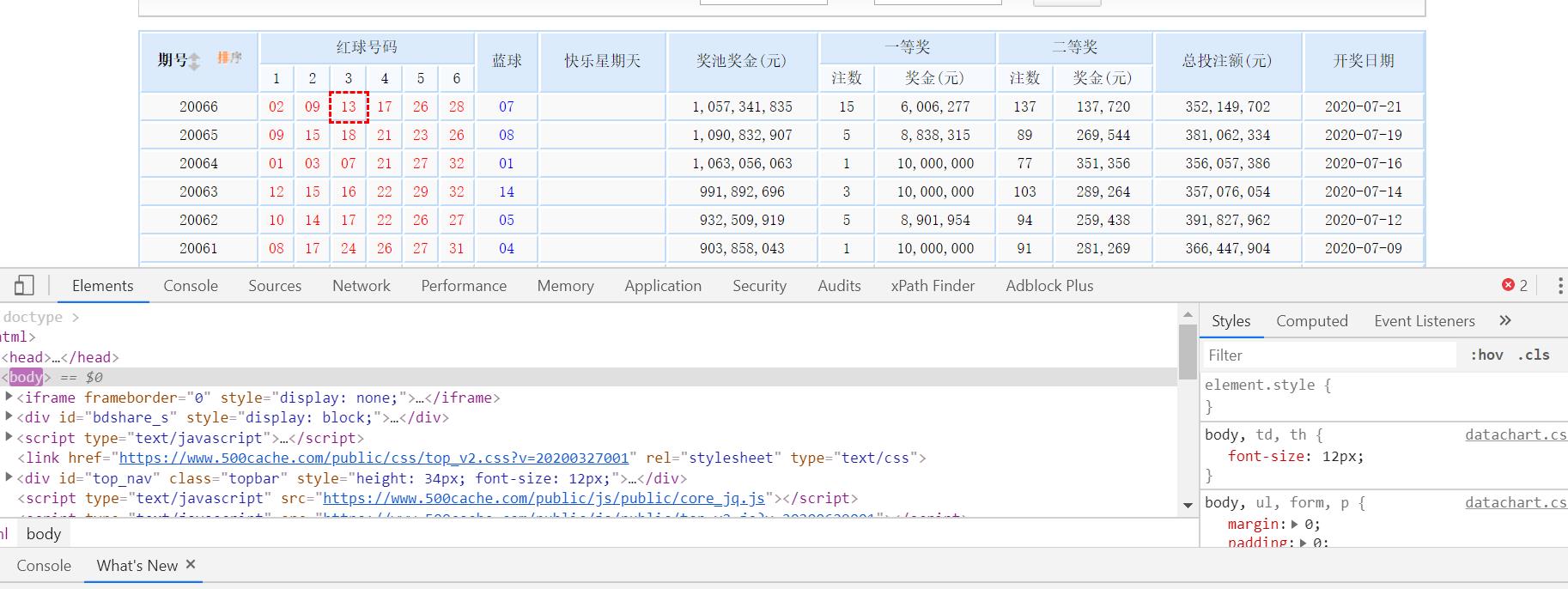
在你需要字符串上右键选择xpath,并点击下半部分出来的菜单栏中‘xpath folder’,我们会得到“/html/body/table/tbody/tr[1]/td[@id='datachart']/div[@id='container']/div[@class='warp']/table/tbody/tr[1]/td/div[@class='wrap_datachart']/div[@class='chart']/table[@id='tablelist']/tbody[@id='tdata']/tr[@class='t_tr1'][1]/td[1]” 这就是我们想要的xpath展开信息,当然你可以直接用这个得到你想要的数据,这边我在这儿优化一下,
优化后的代码:
#coding=utf-8
import requests
from lxml import etree
def get_page(url):
html=requests.get(url)
html.encoding="gb2312"
pg=etree.HTML(html.text).xpath('.//tbody[@id="tdata"]/tr')
info_re=[]
for m in pg:
tmp_text=m.xpath('./td/text()')
info_re.append([tmp_text[0]]+[tmp_text[15]]+tmp_text[1:8]+[tmp_text[14]]+[tmp_text[9]]+tmp_text[10:14])
return info_re
if __name__=='__main__':
html=get_page('http://datachart.500.com/ssq/history/history.shtml')
print(html)
我运行看看结果:

对下表,是不是我们最新的双色球的结果,到这里,我们初步完成了单网页的爬取;也有的同学说爬虫用xpath,太麻烦,其实也有一个简单的方法用pandas里面的read_html函数,可以自行百度搜索