背景
小编最近购买了《机器学习之路》一书,发现这本书也算有特色,没有讲复杂的数学原理和推导,很适合想快速进入这个行业,能尽快的会去使用模型的朋友。
为对作者表示尊重,所以在这里向大家推荐购买正版图书。
模型百科——LR
LR:逻辑分类(Logistic Classification),是一种线性分类模型
理解LR
把每个特征对分类结果的“作用”加起来——这就是线性模型。
逻辑分类(Logistic Classification)是一种线性模型,可以表示为y = w * x + b,其中w是训练得到的权重参数(Weight);x是样本特征数据;b是偏置(Bias)。需要说明的是有些资料中逻辑分类也叫作逻辑回归(Logistic Regression),但它本身是用作分类问题的。
逻辑分类模型预测一个样本分为三步:
-
计算线性函数
-
从分数到概率的转换
-
从概率到标签的转换
第一步:线性函数
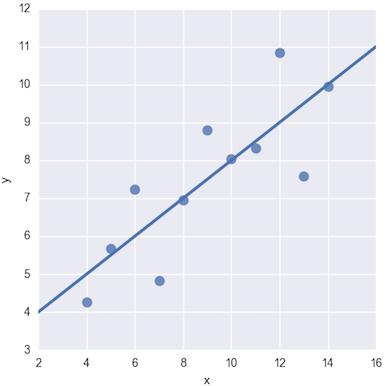
这一节继续以IRIS花卉数据集为例讲解,逻辑分类的第一步:对于某个输入样本x,让它通过一个线性函数,输出一个数值向量S。S向量的长度和分类的类别数量一致,其中向量的每个值是模型对当前样本是否属于该类别的“打分”,见下图。

import numpy as np
对于逻辑分类,训练模型的目标就是找到合适的w和b,让输出的预测值变得可靠。举个简单例子,下面将输入的特征数值打印在平面坐标系上,那么线性表达式的w和b就好比一条直线的斜率和截距,这两个参数调整直线的位置,让直线变得尽可能接近所有的样本点。
第二步:将分数变成概率
首先,我们将输入数据经过线性函数,得到一个分数向量,这个向量如何变换成标签化的结果呢?
答案是我们将线性表达式的输出结果“分数”,先变换成“概率”,再对应标签——概率最高的类别标签就是样本的标签。完成分数到概率变换的函数可以有很多,常用的是sigmoid函数和softmax函数,分别适用于不同的使用场景。
sigmoid函数
sigmoid函数适用于只对一种类别进行分类的场景,通过设置函数阈值(Shrehold),当sigmoid函数输出值大于阈值,则认为“是”这一类别;否则认为“不是”这一类别。
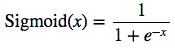
def sigmoid(s):
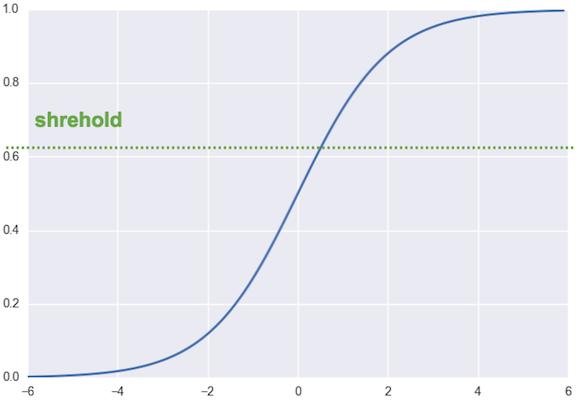
直观地讲,sigmoid就做了两件事:
-
将输入的“分数”的范围映射在(0, 1)之间
-
以“对数”的方式完成到(0, 1)的映射,凸显大的分数的作用,使其输出的概率更高;抑制小分数的输出概率
函数阈值是一个可调节的参数,一般根据模型的成绩以及任务的需求调试。
softmax函数
softmax函数就是sigmoid函数的“多类别”版本,可以将输出值对应到多个类别标签,概率值最高的一项就是模型预测的标签。
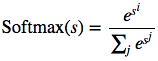
def softmax(s):
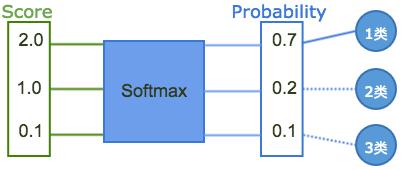
同样,softmax就做了两件事:
-
将输入的“分数”的范围映射在(0, 1)之间,并且所有分数的和为1
-
以“对数”的方式完成到映射,凸显其中最大的分数并抑制远低于最大分数的其他数值
由于IRIS的标签是三个类别,这里选择softmax函数作为分数-概率转化函数。我们可以通过代码侧面感觉一下softmax函数的作用效果。
1. 随机模拟一个scores输出,接着把softmax函数plot出来观察:当x的数值越大,第一个分类的概率值越高,其它的越低
#WeChat: abu_quant %matplotlib inline # 输出图画到notebook端
[<matplotlib.lines.Line2D at 0x1175f4810>,
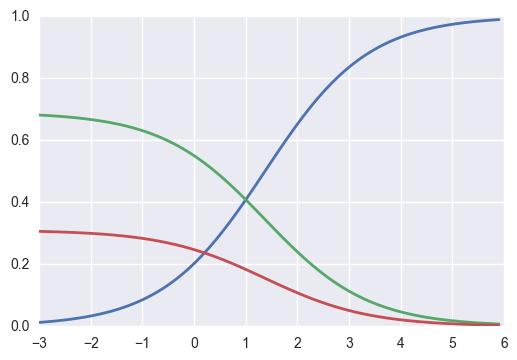
2. 将分数扩大/缩小100倍,观察输出的概率值变化
scores = np.array([2.0, 1.0, 0.1])
[ 0.65900114 0.24243297 0.09856589]
分数扩大100倍后,概率值大的越大,小的越小;即:分类器对分类的结果更加“自信”;反之缩小100倍后,分类器显得对分类的结果很“犹豫”。
第三步:从概率到类别
到这里就很简单了,我们选择概率最高的类别作为预测的类别标签。
总结一下,逻辑分类分为三步完成预测样本分类的任务:
-
经过线性函数,将x变换成在不同类别上的预测“分数”S
-
通过Softmax函数(我们会在下文中有更详细的介绍),将每个类别上的分数转换成对应的概率P。概率值越高,就预测样本越可能是这种类别
-
将概率向量P变换成类别y,选出概率值最高的那个维度就是模型预测的类别
简而言之,逻辑分类的预测:线性函数 -> 概率 -> 类别

使用LR
下面将通过“泰坦尼克号生成预测”这一实验案例,介绍使用LR模型时的一些数据、特征的处理技巧。
泰坦尼克号生成预测
泰坦尼克号的沉没是历史上最臭名昭著的沉船之一。 1912年4月15日,在它的首航中,泰坦尼克号在与冰山撞击后沉没,在2224名乘客和船员中丧生1502人。 这一耸人听闻的悲剧震撼了国际社会,并为船舶制定了更好的安全条例。海难导致这种生命损失的原因之一是乘客和船员没有足够的救生艇。 虽然有一些运气涉及幸存下沉,一些人群比其他人更可能生存,如妇女,儿童和上层阶级。

在这个例子中,我们的任务是完成对什么样的人可能生存的分析,应用机器学习的工具来预测哪些乘客幸免于悲剧。
第一步:任务描述:
-
样本数:891名乘客信息(小数据集)
-
原始特征数:11
-
PassengerId:乘客id
-
Pclass:几等舱(1 = 一等舱,2 = 二等舱,3 = 三等舱)
-
Name:名字
-
Sex:性别
-
Age:年龄
-
SibSp:兄弟姐妹/配偶的数量
-
Parch:父母/孩子的数量
-
Ticket:机票号码
-
Fare:票价
-
Cabin:客舱
-
Embarked:登船的港口(C = 瑟堡,Q = 皇后镇,S = 南安普顿)
-
目标:预测Survived(1 = 生存,0 = 死亡)
第二步:观察数据集
备注:从kaggle*载下**的原始数据集文件包含train.csv和test.csv两部分。train.csv用作模型训练,test.csv的样本没有标签,将模型预测test.csv样本的结果提交到kaggle平台,kaggle会给出成绩。下文出于讲解方便的目的,将忽视test.csv,直接在train.csv分割训练-测试集,显式观测成绩。
我们关心的要点有这么几个:
-
采集的样本是否有缺失数据
-
不同类别的样本数量分布是否基本均匀
#WeChat: abu_quant import pandas as pd # pandas是python的数据格式处理类库
<class ’pandas.core.frame.DataFrame’>
data_train.groupby(’Survived’).count()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Survived | |||||||||||
| 0 | 549 | 549 | 549 | 549 | 424 | 549 | 549 | 549 | 549 | 68 | 549 |
| 1 | 342 | 342 | 342 | 342 | 290 | 342 | 342 | 342 | 342 | 136 | 340 |
可以看到,样本类别比例549:342,略不均衡,但差距不大。同时注意到“Age”、“Cabin”、“Embarked”维度的数据有缺失,在开始模型训练之前,我们需要处理这一情况。
第三步:数据预处理
这里要处理特征的输入数据,使其适合模型去训练。
首先,观察并挑选特征。
data_train.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
“Survived”是生存预测的数据标签。特征“PassengerId”、“Ticket”、“Name”维度下的数据基本是完全随机的,这些特征应该和任务的目标生存预测不相关。
两类特征
剩下的输入特征分为两类:一类是有“数值”意义的数据,如:年龄“Age”、票价“Fare”、兄弟姐妹/配偶的数量“SibSp”、父母/孩子的数量“Parch”;另一类是有“类别”意义的数据,比如几等舱“Pclass”、性别“Sex”、登船港口“Embarked”、客舱“Cabin”,这种特征下的数值是没有数量意义的,如特征“Pclass”(几等舱)下的样本数值:“1”和“3”,并不是表示数量或者长度的3倍关系,而仅仅类别标号。
-
数值意义的特征
-
类别意义的特征
当这些数据流入模型时,模型并不知道哪些是数量意义的数值,哪些是类别意义的数值,所以我们需要把这两类特征需要分开处理一下。
处理数据缺失
先处理“数值”意义的特征数据,第一个问题是“Age”的数据缺失。补全缺失数据的唯一要点就是:尽量保持原始信息状态。处理手段视情况而定,总共这么几种:
-
扔掉缺失数据
-
按某个统计量补全;统计量可以是定值、均值、中位数等
-
拿模型预测缺失值
对于大数据集的小比例缺失,可以直接扔掉这部分数据样本,因为样本充分,信息不会损失多少。但泰坦尼克号数据样本总共891条,每条数据样本对模型的训练都是珍贵的,所以我们希望补全这部分信息而不是丢弃。
data_train.info()
<class ’pandas.core.frame.DataFrame’>
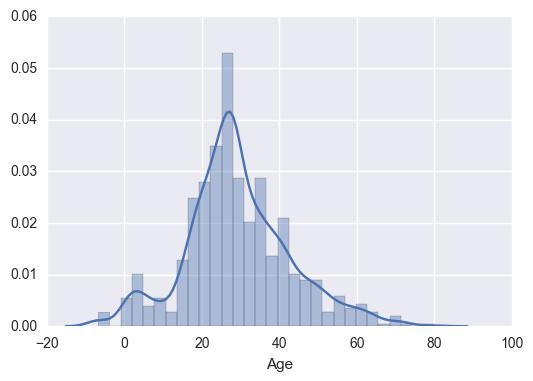
“年龄”特征缺失约20%,可以通过一些统计图形直观观察数据分布,如下面拿使用计直方图观察原始数据分布:
%matplotlib inline
<matplotlib.axes._subplots.AxesSubplot at 0x113e6ff90>
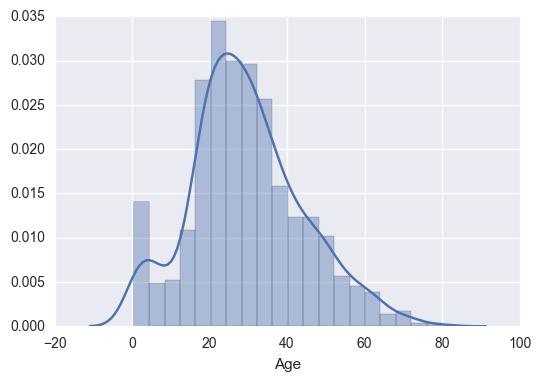
上图中,直方图的横轴是年龄的数值,每个直方块的宽度(bins)代表在一个年龄范围,如Age:0-5这样。纵轴是归一化以后的数量(即该区域的样本数量除以总数),直方块就是统计样本落在每个区间的数量比例。
按均值函数填充后,观察分布:
def set_missing_ages(p_df):
<matplotlib.axes._subplots.AxesSubplot at 0x10f678950>
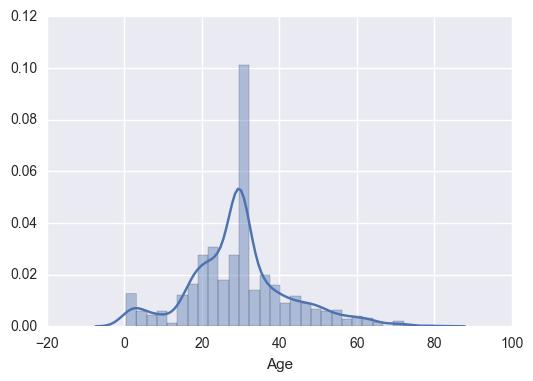
我们无视了数据内在的联系,直接用均值补充数据,这种拍脑袋的做法自然不合理,统计的拟合曲线明显变形了。于是,下面取出一些感觉上和“年龄”相关的特征,比如船票、家庭成员数量等,扔进线性回归模型中,通过模型预测年龄看看:
from abupy import AbuML
<matplotlib.axes._subplots.AxesSubplot at 0x114fc03d0>
下面直观对比下在最后的模型中,使用不同的数据填充方式造成的成绩对比:
data_train_fix1 = set_cabin_type(data_train_fix1)
accuracy mean: 0.798073714675
使用 setmissingages2 ,回归模型预测填充的模型成绩:
data_train_fix2 = set_cabin_type(data_train_fix2)
accuracy mean: 0.809183974577
归一化数值数据
对于两类特征数据混杂的问题,我们可以看到,票价“Fare”、年龄“Age”这两个数值特征和其它特征明显不在同一可以比较的尺度上。回顾上一节所说的梯度下降对输入数据的要求,我们希望所有的输入数据在差不多同一尺度上可比较,所以下面归一化这两个维度的数据。
import sklearn.preprocessing as preprocessing
处理类别意义的特征
客舱号“Cabin”的缺失程度太严重了,在整体样本很小,204/891 = 77%的缺失程度的数据不可能有效恢复。我们的灵感是客舱号信息“Cabin”虽然无法提取,但可以将“有没有在客舱”这一信息提取出来。
def set_cabin_type(p_df):
对于类别意义的特征,数值大小没有任何数量上的意义。就像前面提到的,对于“Pclass”,1和3并不是表示数量关系,而是类别标号。对于类别标号有意义的只有“是”这一类和“不是”这一类。所以,对于所有的类别意义的特征,下面将按类别标号重新建立新的特征,特征的数值只有1和0,标识样本“是”这一类或者“不是”这一类。
dummies_pclass = pd.get_dummies(data_train[’Pclass’], prefix=’Pclass’)
| Pclass_1 | Pclass_2 | Pclass_3 | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 1.0 |
| 1 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 |
对于特征“Embarked”,缺失的数据样本只有两条,对于这两条数据,在按特征标签展开时,每个特征标签数值都为0。
dummies_embarked = pd.get_dummies(data_train[’Embarked’], prefix=’Embarked’)
Embarked_C 0.0
预处理其它类别数据,把“Sex”的文本换成数字类别标号。
dummies_sex = pd.get_dummies(data_train[’Sex’], prefix=’Sex’)
| Sex_female | Sex_male | |
|---|---|---|
| 0 | 0.0 | 1.0 |
| 1 | 1.0 | 0.0 |
| 2 | 1.0 | 0.0 |
接下来把处理好的数据维度合并进去,不需要的数据维度扔掉:
df = pd.concat([df, dummies_embarked, dummies_sex, dummies_pclass], axis=1)
到这里为止,输入数据就预处理好了,看下模型将要用哪些特征。
# 选择哪些特征作为训练特征
| Survived | SibSp | Parch | Age_scaled | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Sex_female | Sex_male | Pclass_1 | Pclass_2 | Pclass_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | -0.592481 | -0.502445 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
接入模型看看成绩:
# WeChat: abu_quant from abupy import AbuML
accuracy mean: 0.79919731018
构造非线性特征
我们希望逻辑分类模型可以做得更好。前面提到,逻辑分类是一个”线性模型“,所谓线性模型就是把特征对分类结果的作用加起来,也就是说线性模型能表示类似于y=x1+x2关系的表达式(y表示分类结果,x1、x2表示特征对分类的作用),但线性模型无法表示一些非线性的关系如y=x1*x2。所以我们打算人工构造一些新的特征,弥补线性模型对非线性表达式表达能力的不足。
特征的非线性的表达式可以分为两类:
-
用于表达“数值特征”本身的非线性因素
-
用于表达特征与特征之间存在非线性关联,并且这种关联关系对分类结果有帮助
第一种情况是说特征对目标类别的作用不是线性关系。比如两个样本的特征数值是1和3,对应的,这个特征对分类产生的作用其实是1^2和3^2,或者ln1和ln3。这类问题的本质是数字内在的线性数量描述并不符合真实的关系描述。
对于第一种,仅适用于数值特征,对应的构造特征的方式有两种:多项式化和离散化。多项式构造指的是将原有数值的高次方作为特征;数据离散化是指将连续的数值划分成一个个区间,以数值是否在区间内作为特征。高次方让数值内在表达变得复杂,可描述能力增强;而离散则是让模型来拟合逼近真实的关系描述。
举个简单的实现例子,对于特征“Age”,可以构造平方特征,也可以是否满足Age<=10这一条件划分区间构造出新特征。
# 划分区间
接着尝试构造新特征表达特征与特征之间的非线性关联,同样源自多项式的思路。比如:我们觉得“Pclass”数值越大越不容易生存下来,头等舱的遇害人员应该比三等舱的更可能被照顾;同时年龄越大的人也越不容易生存下来,越小的越可能被照顾,会不会这两个特征之间也有一些关联,并且这种关联对生存预测有指导意义呢?
我们可以构造一个新特征“Age * Class”,加入模型中。
df[’Age*Class’] = data_train[’Age’] * data_train[’Pclass’]
看下模型现在用的特征:
# filter加入新增的特征
| Survived | SibSp | Parch | Age_scaled | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Sex_female | Sex_male | Pclass_1 | Pclass_2 | Pclass_3 | Child | Age*Age_scaled | Age*Class_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | -0.592481 | -0.502445 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0 | -0.636573 | 0.031376 |
新加入的这些特征,对模型的表现是否有提升呢?
train_np = train_df.as_matrix()
accuracy mean: 0.804752298264
评估特征作用
一般而言,机器学习中看一个新特征是否发挥作用,最常用的方法就是加进去看模型成绩是否提升。可以同时观察模型给特征分配的权重,看特征发挥作用的大小:
titanic.importances_coef_pd()
********************LogisticRegression********************
| coef | columns | |
|---|---|---|
| 0 | [-0.410298136384] | SibSp |
| 1 | [-0.173336882199] | Parch |
| 2 | [-0.208459115049] | Age_scaled |
| 3 | [0.165577117349] | Fare_scaled |
| 4 | [0.0] | Embarked_C |
| 5 | [0.0] | Embarked_Q |
| 6 | [-0.405822408349] | Embarked_S |
| 7 | [1.99640288087] | Sex_female |
| 8 | [-0.715926302128] | Sex_male |
| 9 | [0.663404977168] | Pclass_1 |
| 10 | [0.0] | Pclass_2 |
| 11 | [-1.03255600599] | Pclass_3 |
| 12 | [1.28640364062] | Child |
| 13 | [0.0] | Age*Age_scaled |
| 14 | [-0.129278692295] | Age*Class_scaled |
可以看到,在训练好的模型中,特征“Child”有效发挥了作用,而“Age*Class”、“Age*Age”没有什么用。
对于一些特定的应用场景中,模型的训练非常耗时,可能几天甚至更长。这些应用场景中,需要一些新的数学方法估计新特征是否有效。机器学习中有很多方法评估特征在模型中发挥的作用,对于这些方法,只要知道它们基本上都是通过某种数学公式,计算特征和预测值之间的相关性就可以了。
构造特征的数学意义
通过人工构造非线性特征,可以弥补线性模型表达能力的不足。这一手段之所以能够生效,背后的原因是:低维的非线性关系可以在高维空间线性展开。
解释这一观点,让我想起霍金先生的巨著《时间简史》中提及的一个例子:“这正如同看一架在非常多山的地面上空飞行的飞机。虽然它沿着三维空间的直线飞,在二维的地面上它的影子却是沿着一条弯曲的路径。——飞机影子的运动轨迹在二维地表上看到的是一条非线性的曲线,起伏不定,很难用函数表示;但在三维空间中,其运动轨迹仅仅是一条笔直的直线而已,一个简单的线性函数就可以说明。也就是说在二维空间中看到的复杂表达式,当增加一个维度,其表达式可能就变得非常简单了。

同样的道理,我们可以增加新的特征维度,让分类任务背后的数学表达式变得更简单,让分类模型更容易挖掘出信息——这正是构造新特征有意义的地方:增加特征维度,构造出模型表达不出来的内在表达式。对于逻辑分类模型而言,就是通过增加新的非线性特征,完成特征维度的扩展,构造出模型表达不出的非线性的内在关系。
逻辑分类因为是线性模型,原型简单,所以有着训练速度快、易分布式部署等特点。现在业界对逻辑分类仍然有着广泛的应用,尤其适合那些数据海量、特征高维并且稀疏的应用场景。比如在一些涉及海量用户的个性化推荐任务中,海量数据上,把每个用户ID作为一个特征,使用逻辑分类就可以快速有效地完成任务目标。