此文比较长,但都是真正的数据干货,希望对大家有帮助~~~
前言
本文整理自爱屋吉屋大数据平台架构师王晨在海致BDP上海客户沙龙上的分享。王晨先生重点分享了爱屋吉屋数据平台的搭建和运营经验,他详细讲解了如何收集数据,使用哪些工具处理数据,以及数据怎样呈现等大量实操细节,堪称互联网房产中介行业玩转大数据的教科书。
爱屋吉屋大数据平台产生背景
先说一下我们爱屋吉屋数据平台产生的背景。
爱屋吉屋与很多初创公司一样,先集中精力做产品,后建立数据平台。
爱屋14年才成立,期初大家都在集中精力在产品功能、推上市场、获取客户这三个点上,毕竟产品出来后才能慢慢产生数据,才能基于数据分析用户行为、找出用户需求。
但当一个互联网企业进入快速发展期,会在短时间内经历应用层拆分到数据库,分库分表的过程,这样数据就会很分散。这就导致了一些问题,例如出报表,以前通过一个Mysql Instance 即可,但拆分以后就得跨库或者跨机器了,这些数据可以通过Mysql的Federated引擎做远程关联,却会带来额外的网络开销。
另外,快速发展的互联网产品,业务功能日益复杂化,针对每个业务功能产生的报表也会增多。当报表很多,数据量很大的时,跨平台处理数据速会度特别慢,所以需要有一个数据中心专门来解决这些问题。
而且,产品越精细,支撑产品的系统越复杂,监控系统产生的数据也随之复杂化。比如:用户发出一个请求后,可能实现这个请求需要跨过多个机器、多个环节,那么用户在哪个环节停留的时间多,在哪个环节出现了问题,都需要监控系统做数据反馈。于是,我们必须在各个环节大量埋点。埋点所反馈的数据也常常是非结构化的,难以用传统的统计工具如EXCEL来处理。这也是我们需要一个数据中心的原因。
最后一个问题,还是跟监控系统有关。随着公司发展,我们需要监控的不仅仅是“CPU运行正常吗?内存是不是高了?磁盘是不是满了?”作为一家房产互联网公司,业务监控也很重要,且业务监控更需要预警和通过数据监测分析趋势。这一整套东西都需要一个新的数据处理中心满足我们的发展需要。
爱屋吉屋大数据平台架构
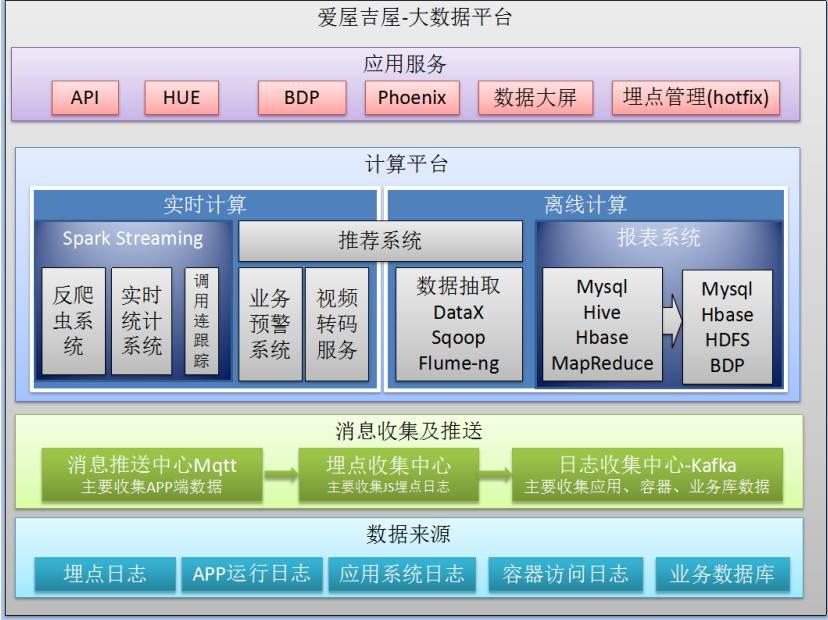
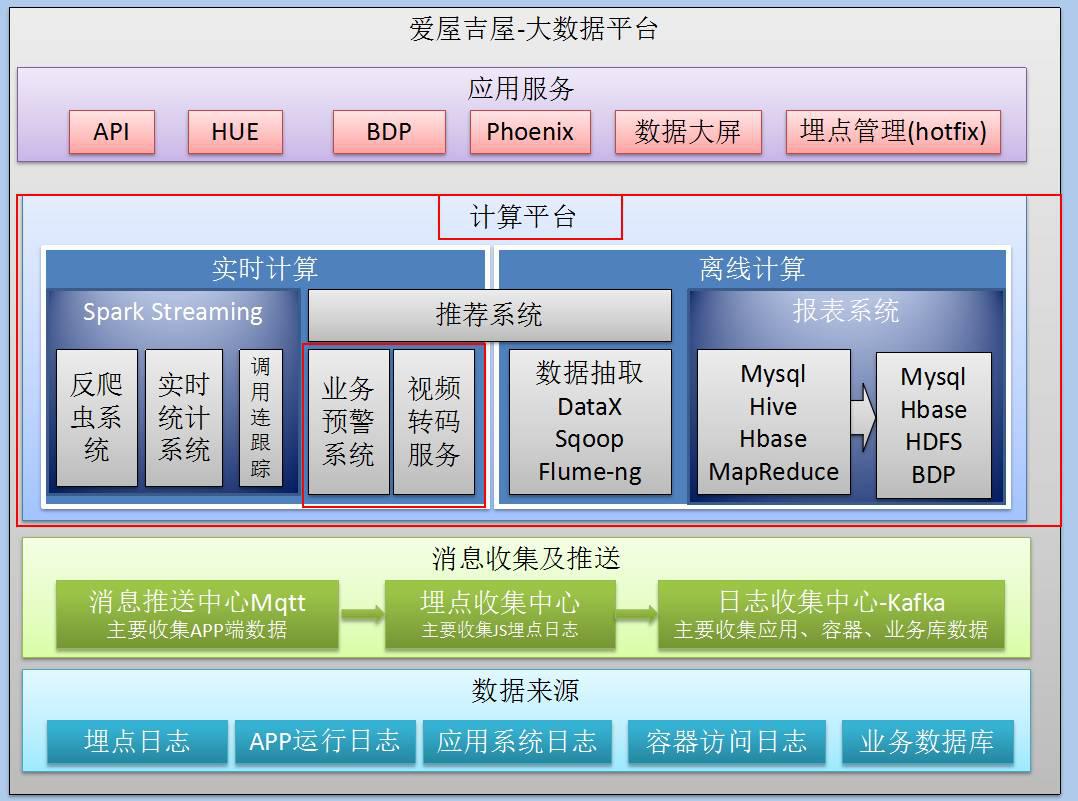
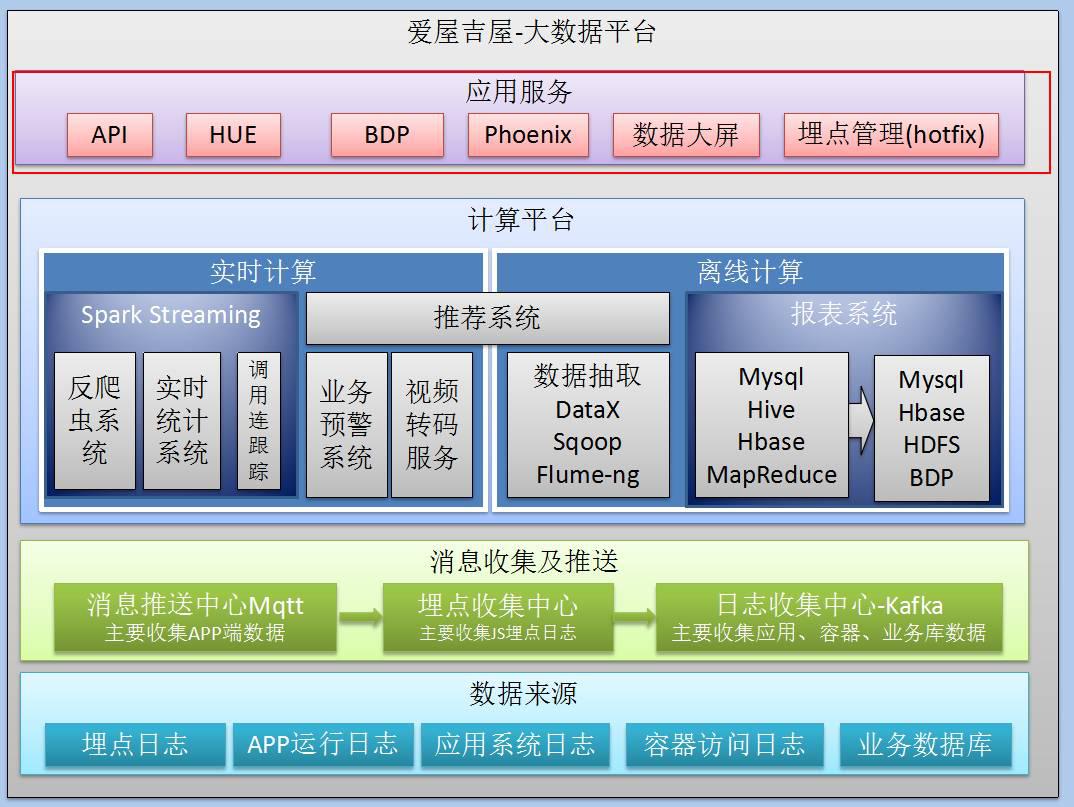
接下来我们来详细看爱屋吉屋这个数据平台的大致构架(如上图),我们的 大数据平台按功能分为四部分:
一.数据来源
二.消息收集及推送
三.计算平台
四.应用服务
我将从最底层的数据来源一层层向上作解释。
一.数据来源
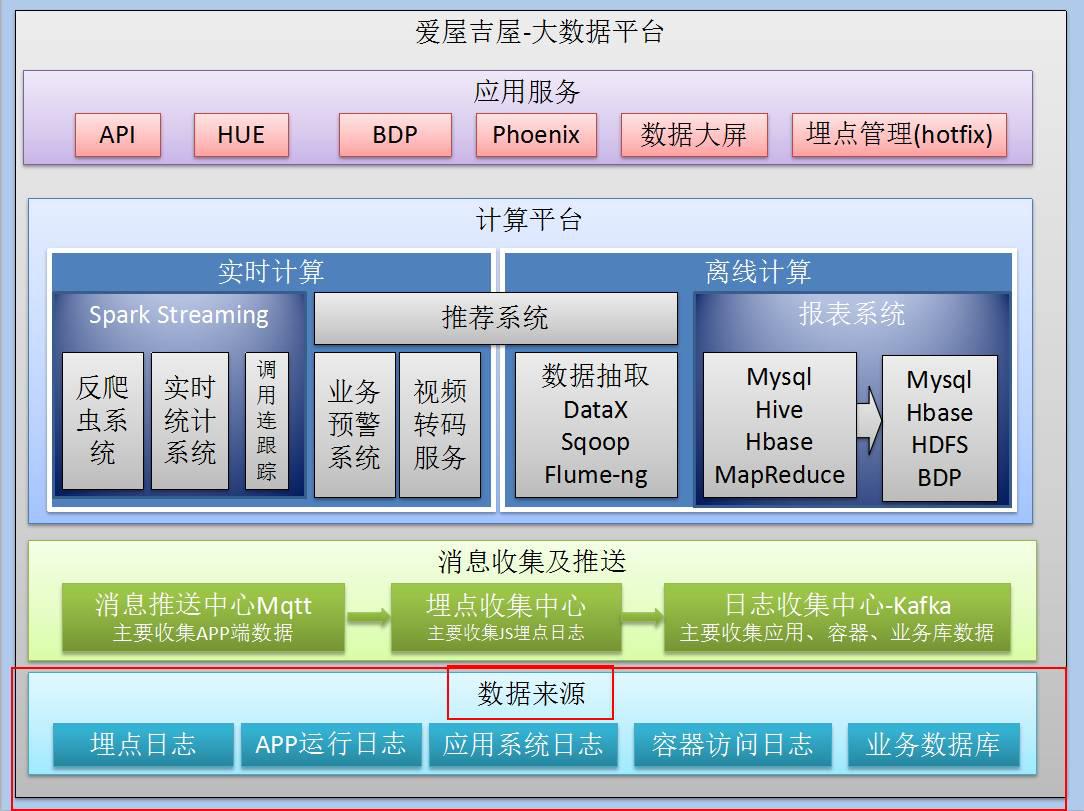
爱屋吉屋有五个数据源。
1.埋点日志:埋点日志又分为用户行为埋点日志,企业运行、运营状态埋点日志。
2.APP运行日志:即是我们说的监控日志。比方说用户发现视频无法*放播**,一点开就跳出或卡死,这种情况我们会监控到、记录下来,形成APP运行日志。
3.应用系统日志:用来记录和手机我们做开发做应用的日常信息。
4.容器访问日志:用来收集外部访问容器、容器互联等相关数据。
5.业务数据库:用来收集业务产生的数据,还会用来做一些监控的工作。基本通过Mysql 来处理。其实这部分,还包含了对敏感数据的监测,比如一些不允许update修改的敏感数据,万一有人有权限对这个数据做了什么动作,我们也能通过Mysql binlog来推倒出他的行为。
采集基础数据之后,还需要通过消息收集和推送,才能让数据流转进计算平台。消息收集和推送这个部分,也分了三个模块。一:消息推送中心+Mqtt 二:埋点收集中心 三:日志收集中心-Kafka
二.消息收集及推送
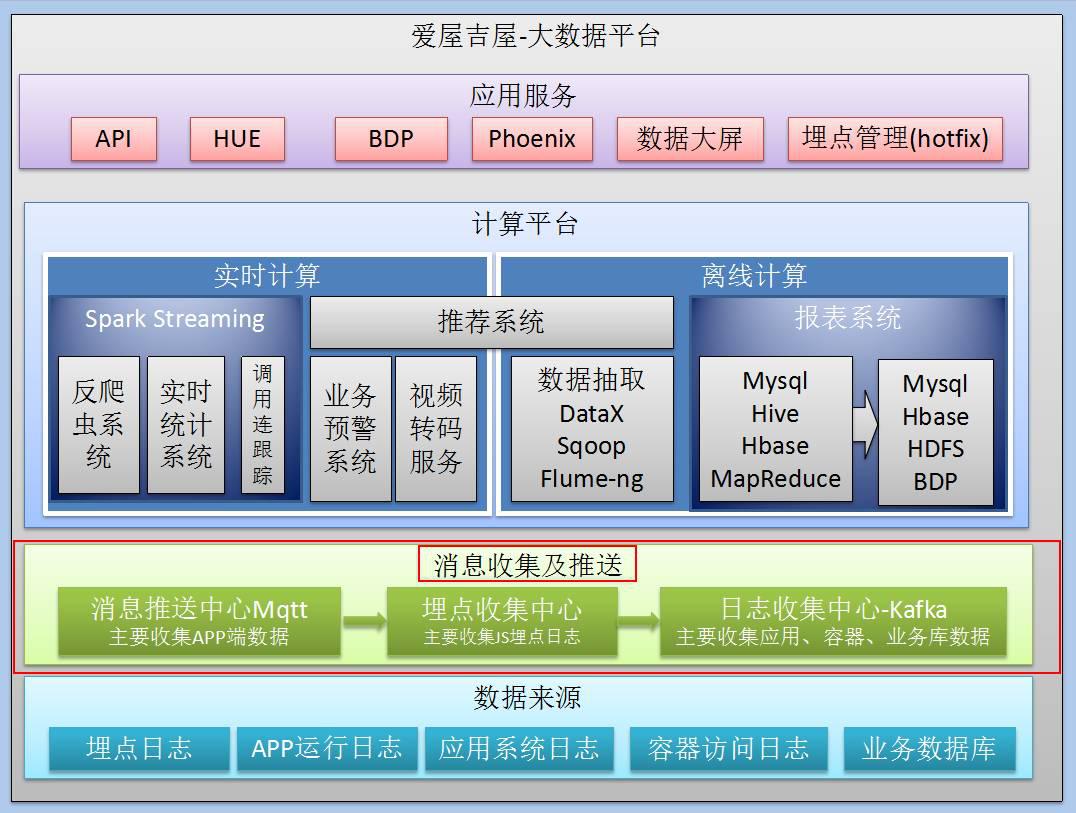
第一个模块:消息推送中心Mqtt
消息推送中心+Mqtt这个模块呢,主要收集APP数据。因为手机端常常需要给用户推送信息,却不像PC端那样能随时建CBD,那么推送这个动作如何与后端挂钩呢?我们自己的消息推送中心就是手机端和后端之间的“岛”,Mqtt则是保持消息推送中心和手机端随时链接的“桥”。这样我们就能很轻易的保持前端与后端的链接并收集数据。
第二个模块:埋点收集中心
埋点收集中心主要收集JS埋点数据,JS埋点数据主要来自三个端:APP、H5、PC端。用户无论在APP、H5、PC哪个端有动作,都会直接调用我们的埋点收集中心接口,一方面我们记录这一事件的发生,好之后来分析用户行为。埋点收集中心还会打包原始数据,存到本地磁盘,这一步是为了保证不丢失数据。最后,埋点收集中心还会发送数据到Kafka里。
第三个模块:日志收集中心-Kafka
Kafka里面数据源比较多,埋点数据、应用系统日志、容器访问日志、业务数据库都会放进Kafka。在ETL(Extract抽取-Transform转化-Load加载 )的过程中,我们主要使用Flume,因为Flume比较容易扩展,比如处理业务数据库时,我们只要定义定义一个Flume的source,再把数据转换出来,塞进Kafka就可以了。这样就可以减轻我们的开发量。
三:计算平台

在Kafka的后面,我们有一个计算平台。
这个计算平台分为两块,一是实时计算,二是离线计算。
先说实时计算:
其中,用到了Spark Streaming来计算,共涉及三个系统:
1.反爬虫系统
在房产中介行业,很多第三方公司都喜欢用爬虫收集各种数据,比如房价的趋势,房屋的信息等等,所以每天会有很多同行在我们的网站上收集这样的数据,反爬虫系统打击的呢,就是这些网站——会把他们抓出来,交给业务系统,采取相应的措施,比如屏蔽IP,关小屋一段时间啊等等。
2.实时统计系统
它的应用场景主要是在房源展示上,它可以实时展示某个房子,用户在线看了多少次,经纪人带着用户在线下又看了多少次。这个实时展示其实是一个“伪实时”,为什么呢?因为它有延迟,有一个时间窗口——系统会把一分钟内的数据聚合起来再计算,所以它至少有1分钟的延迟。
3.调用连跟踪
这个调用连跟踪,就是字面的意思。我们的系统登录环节比较多,一个请求产生后,在哪一个环节上故障率比较高,或者说,在哪一个环节出错率比较高,我们需要有一个全程的监控,来监控这种跨结点的信息。
没有用Spark Streaming计算的有业务预警系统和视频转码服务。
业务预警系统也是实时的,因为预警嘛,出了问题第二天才发现,才报出来,就起不到预警的意义了。
这个业务系统也是一个机群,它可以扩展,比如我们注册量特别大的时候,一台服务器忙不过来了,这个时候信息就会堆积,预警系统就会有延迟,因为它只有处理了某个时间发生的错误,才能把预警发出来。
再有就是,视频转码服务。
爱屋吉屋的一个特点就是,房子是用视频来看的,当视频上传以后,可能格式是不统一的,而且有的大,有的小,我们在*放播**的时候,就会把他转成不同的码率。
一般在有wifi的情况下,我们可能会给用户高清的码率,看的比较清晰;但在没有wifi的情况下,可能就使用流畅的码率,*放播**没那么清晰。
所以整个视频转码服务也是实时的——你不能让用户投诉说,我传了一次视频,我要等很长时间,才能看。
视频转码服务我们基本上调用的是第三方的服务,有一个服务中转站,当我们收到视频文件地址以后,会把他放在对应的平台上去,比如金山云、阿里云我们都有备份,然后两个平台同时去转化,转码。
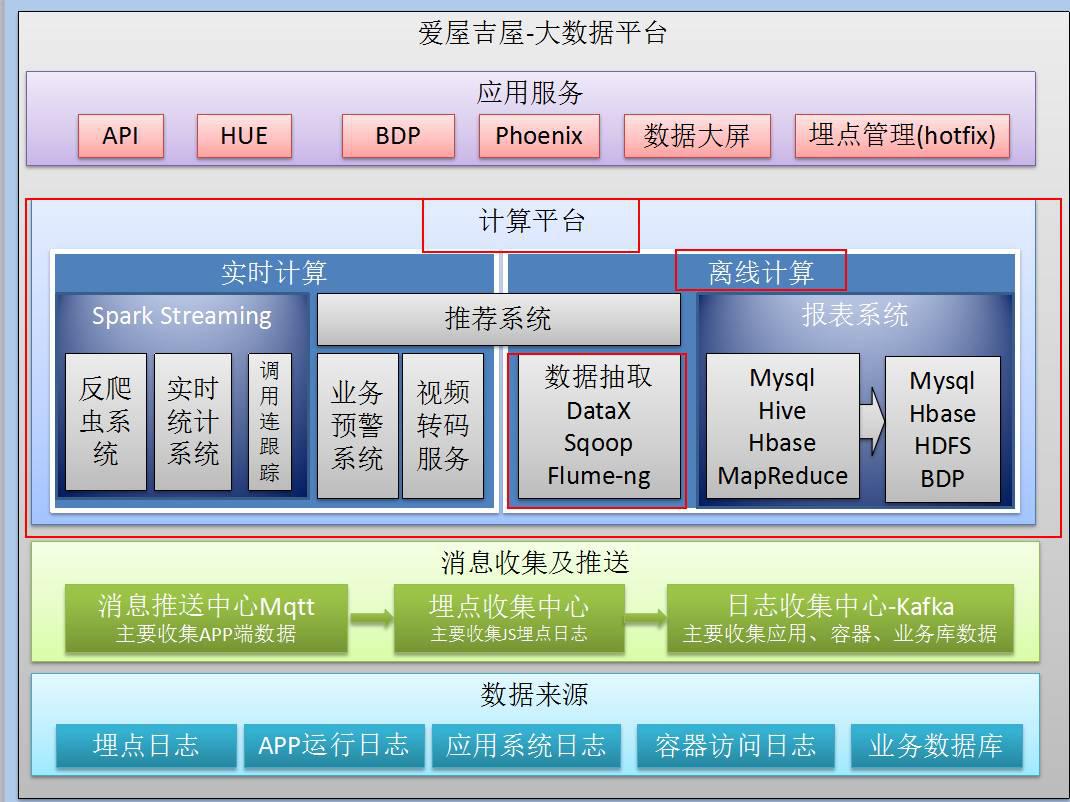
下面说离线计算:
数据抽取是离线计算中很重要的一部分,它主要有三层:
一是DataX,二是Sqoop,三是Flume-ng
DataX里面的数据很多,有一些数据可能是比较敏感的。
因此,我们要对数据做脱敏处理,比如说用户买了一栋楼房他想出售,或者她想出租,可能数据里有这个用户的手机号,还有详细地址,比如说在哪个小区,几楼,几室——这些数据很敏感,也很值钱。
这种数据我们不会外泄,在整个DataX中间,我们会把敏感数据筛掉,剩余不敏感的数据,才会把他转换出来,然后放在BDP里面,或者放在我们自己的数据中心里,不需要做太多的权限控制,就可以分析使用。
所以,数据脱敏,或者说简单的的数据统计过程,我们会更多用Datax来做操作。
至于,Sqoop和Flume-ng这里就不再细说了。
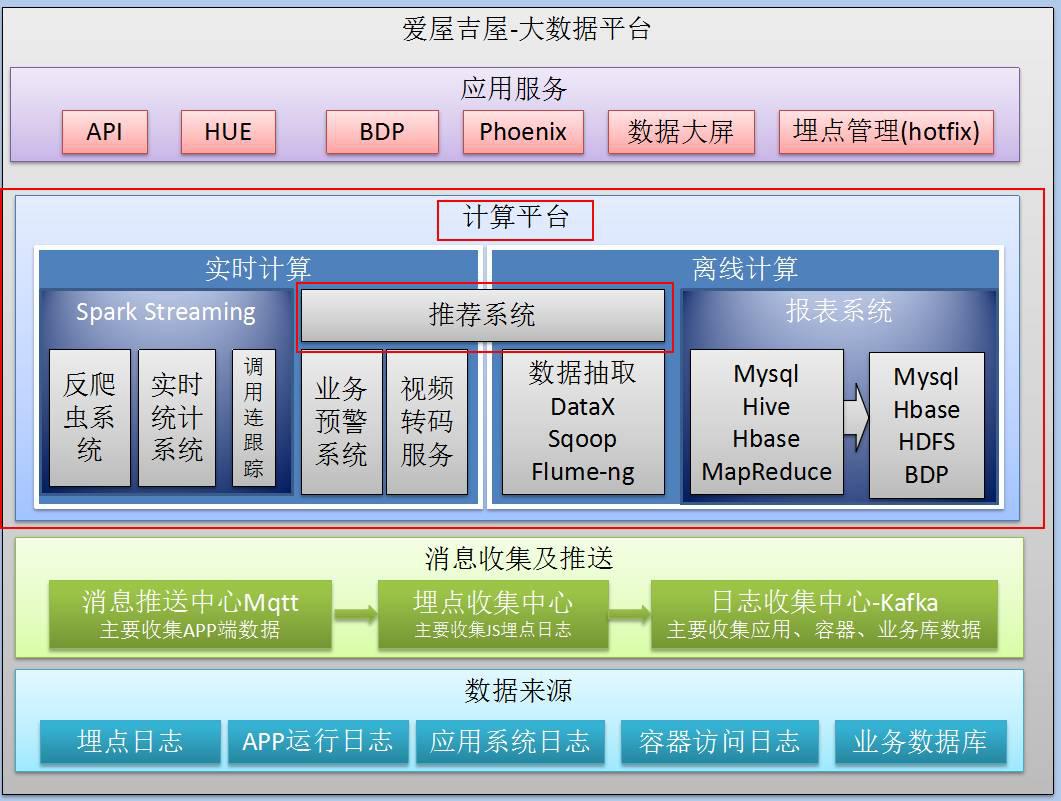
推荐系统在整个平台的中间,它包含的内容在上面都已经说到了,它横跨实时计算和离线计算两边,既有实时计算,也有离线计算。
为什么呢?
这是由具体的应用场景决定的。
我们知道推荐系统的基础数据量比较大。
举个例子:
比如,某个用户在看完一套房子之后,我们可能要根据用户访问的这套房子的情况,大致分析下他想要看什么样的房子,比如分析出价格在200-300万,要中间层等等信息,然后向他推荐相似的房源。
也就是说,系统要从最近半年的房源里面,找出一个相似的房源,做推荐。
这种应用场景下,爱屋吉屋尽管是个创业时间不长的公司,但是数据量还是蛮大的。
在半年房源这么大的一个数据基础上,找相似房源,实时计算是很难做到的,而且也没有必要——因为,在计算完成之后,一个星期之内我们可能不再需要重复计算这套数据了——房源的变化并没有那么快。
这是离线计算。
那实时计算什么时候用呢?
当一个用户看到一套房子后,我们马上就给他推荐,这时就需要实时计算——计算与这个房源相似的房子有哪些——相似的房源我们已经通过离线计算抓出来了,就放在Redis里面,这时候实时计算找到它。
这样,通过离线和实时的结合,我们就实现了快速的推荐。
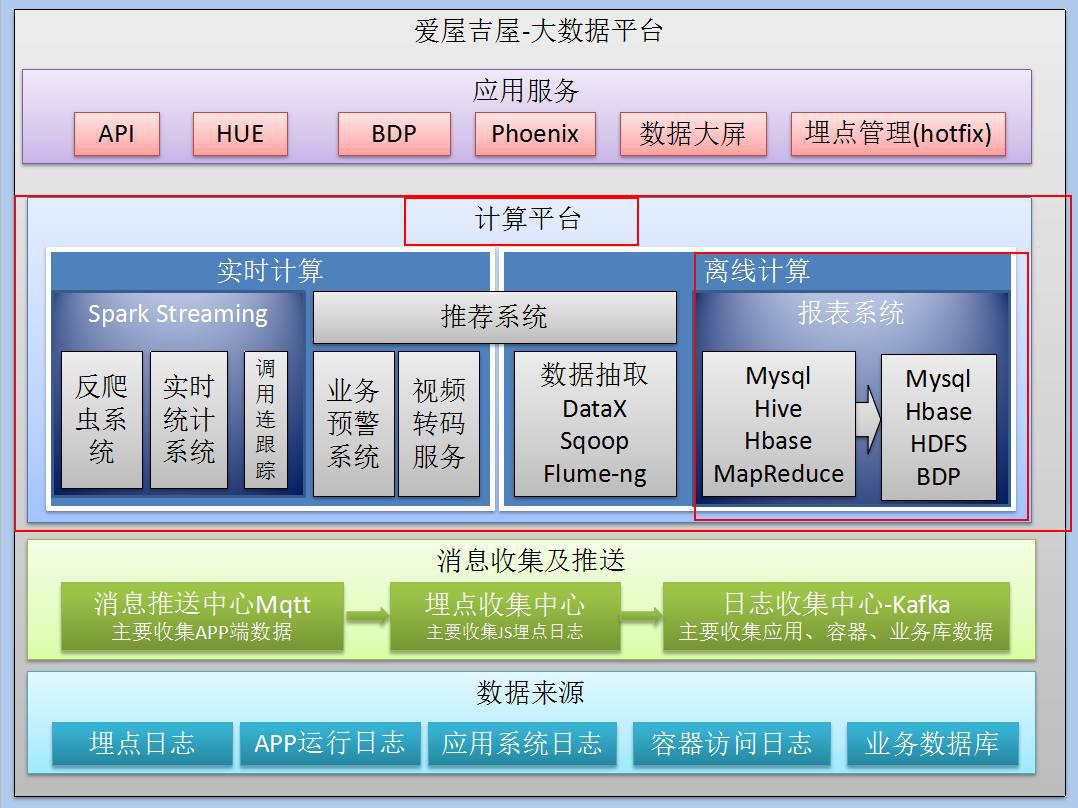
接下来说我们离线计算的报表系统部分:
目前,我们的系统里有很多报表,不需要实现实时计算,所以,这些报表展示的都是前一天的数据,是离线的,需要按天来查询。
我们的大部分报表是用BDP平台生成的,也有一些是我们自己做的。
我们自己做的报表,设计理念参考了DataX,基本上是通过Reader和Writer的方式来实现的。
我们大部分的数据结果是放到BDP里面的,我们现在也在推荐公司的一线产品人员,让他们尽量使用BDP,因为BDP的界面做的比较方便,拖拉拽都可以达到好的处理效果,而我们自己开发呢,成本比较高——数据放到许多平台里,还要通过其他的方式把数据抽取出来,然后才能做出想要的展现形式。
整个大数据平台的最上层,是应用服务层,也是具体展示页面层。这部分出现的统计展示,不仅仅是内部人员看的,用户也会看到。比如用户在APP查看一套房子,想要了解这套房子有多少人租过、多少经纪人线下勘察过。
HUE主要是我们数据挖掘师在使用,本来期望产品经理们能够利用Hadoop生态里可视化分析器HUE,自己写个HQL页面,自己在里面查些简单的数据。后来发现产品经理做不到,所以我们现在主推BDP,就是我们把统计出来的数据放到BDP里面,再让产品报表那一块的人去用BDP来做分析。
使用Phoenix主要是为了降低开发的学习成本。爱屋吉屋之前主要用Mysql,业务发展后记录两增多,Mysql会很重,会影响到其他表的查询功能。哪么这个表格就得放进Hbase,但是Hbase不太支持Mysql语句。本来业务方已经习惯了Mysql,你让他直接改成Hbase去工作太难了。所以Phoenix就是一个包装,量比较大的表迁进Hbase后包一层Phoenix,还可以像Mysql一样用Hbase。
埋点管理系统

创业初期阶段,产品经理对于用户行为分析所需要埋点数据需求比较好满足,比如:统计页面点击数。开发人员根据产品经理的需求埋点即可,初创期的埋点数据类型的格式也很简单。
当系统变得复杂时,产品经理要求的埋点功能也越来越复杂,文档也随之复杂化。开发人员一是懒得看文档,二是人员流动时,新的开发人员如果不知道之前有哪些埋点,会出现重复添加埋点的情况,最终导致业务系统到处都散落着埋点。
我们解决这个问题的方式,就是开发埋点管理系统。首先拿一个页面,让产品或者我们这边的人员,一条条分析这个页面里有什么埋点、埋点到底发哪些信息,埋点数据的具体属性总是有方法总结出来的,在管理埋点时,就可以把这个取数据的方法再塞回去,接着根据已定义埋点的格式动态生成JS文件。
之后业务方就不用到处写发布了,只需要引用一个JS文件即可,且这个JS文件还可以随时动态生成。这样做改BUG也很方便。
业务预警系统
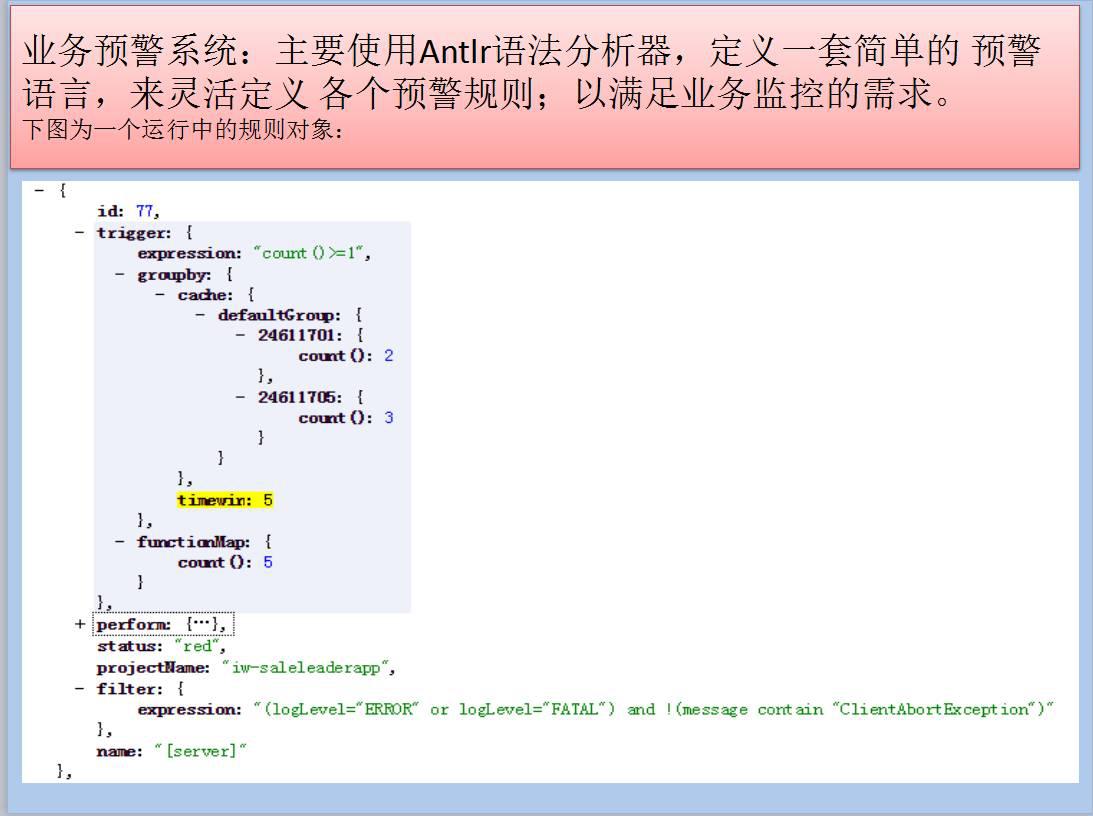
说说业务预警系统:
它的规则比较灵活,实现的核心就是Antlr语法分析器。
我们定义了一个简单的预警语言,然后大家就可以比较灵活的去定义自己的规则。
首先,当一个日志或者是一条消息进来以后,它要先通过我们的Antlr表达式先过滤,如果满足这个表达式,这种信息就通过。后面还有一个触发器,可以对一定时间内过滤后的日志进行聚合操作,例如计数、累加等等,比如说过去5分钟,这种错误出现10次就报警。
Spark Streaming的应用场景

再说说Spark streaming的应用场景。
它主要是通过Spark streaming记录IP的访问情况,对IP的可疑程度打分。
它打分的时候有很多规则,比如说我们先看它这个访问时间是否均匀,比如说它平时的访问时间白天黑夜基本上是均匀的,这个比例接近1:1,那这个很可能就是爬虫。
还有一个访问频率,一些比较傻的爬虫,短时间内的访问频率非常高,这样也能判断出来是第三方爬虫。
还有一个就是看是不是集中访问列表类页面:爬虫会拉列表页,但是正常用户看的时候,大部分看地图页的比较多,而列表页呢方便抓取数据。
第二块就是实时统计,实时统计这一块比较简单,基本上根据房源ID去做记数就行。
爱屋吉屋现在遇到的问题

我们目前遇到的问题分为四个方面,存储、计算、维护、数据同步。
先从存储这个问题谈起,我们的数据量现在已经到亿级别了,每天大概还有几百万的增量,因为是初创公司,我们的计算集群比较小,都是放在阿里云上面的,我们跑一次计算,时间很长,开发成本也比较高。
特别是后面的维护需求也越来越多,我们整个平台搞起来以后,没有专业的大数据运维,对于我们来说运维的成本比较高。
再有就是数据同步的挑战,比如从我们的Mysql数据库往Hive里面写,也可以实现更改删除,但个速度比较慢,没有Mysql快,所以整个异构数据库里的数据实时同步的话,我们现在还做不到。
所以面对这些问题,最后我们都是把数据放到了BDP里面了,就是把我们需要的这些维度的数据,Mysql的,我们日志的,Hbase的这些所有的数据都最后推到了BDP里面去做,因为BDP里面它可以实现异构数据的实时同步,同步以后我们根据我们的需要拿取报表。
我们制定好我们的中间表,结果表,我们会把结果表实时的放在BDP里面,放完以后我们的成本节约了,因为我们不需要那么多的开发人员了,我们只要一个人负责把这个数据往BDP里面实时导入,就行了。
而在使用方面呢,BDP产品可以通过一些拖拉拽的方式就做出来这种报表,满足产品经理的需求,他们不用再来找我们去帮他们拉取这种数据了。
BDP的可视化功能也特别强大,像同比环比这些东西,最后在BDP上面很容易就实现了。
数据全面性这一块的话,一般我们用友盟,或者是百度等公司的组件,而BDP产品本身的特点是可以集成这些组件,这样的话你就很容易能够接入这个系统。
我们把我们自己的运营塞进来,整个数据在BDP上跑,效率也大幅提高——一般来说,只要你把这个报表格式定义了以后,你在BDP上就能立马操作,而在我们开发的话,是有一定周期的。
爱屋吉屋是如何使用BDP的

爱屋吉屋是怎么使用BDP的呢?首先,我们从整体数据中,处理掉一些敏感数据如用户的门牌号、电话号码,再讲这个脱敏的数据,拆借到BDP里。
其次,我们在BDP里建一些产品或者运营人员需要的表格。接着推动产品人员来使用BDP,他们也挺愿意用的。
最后,使我们和BDP共同维护数据更新,如果我们这边出现了数据漏传、数据中心服务器当机的情况,我们可以借助BDP的力量重新同步数据。
最后呢,我个人想聊聊大数据的未来。个人比较看好大数据这个方向,因为不管是人工智能、机器学习、智能推荐、物联网,都会让基础数据成几何倍数增长。基础数据多了,人们就离不开数据分析平台了。这里借用马云的一句话,现在属于IT时代,未来属于DT时代吧。好吧,最后就这样,谢谢大家。

图为海致BDP上海客户沙龙现场