

客户需求:
计算表格中同年度各企业经营范围相似度最高的十个企业(竞争者)
分析使用余弦相似度算法

余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度.

给定两个属性向量,A和B,其余弦相似性由点积和向量长度给出
基于numpy的python代码:
import numpy as np
x_1 = np.array([1,3,6,2,3,6])
x_2 = np.array([3,4,1,5,7,8])
def cos_sim(a, b):
a_norm = np.linalg.norm(a)
b_norm = np.linalg.norm(b)
cos = np.dot(a,b)/(a_norm * b_norm)
return cos
print(cos_sim(x_1,x_2))
基于sklearn的python代码:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
x_1 = np.array([1,3,6,2,3,6]).reshape(1,6)
x_2 = np.array([3,4,1,5,7,8]).reshape(1,6)
con_sim = cosine_similarity(x_1,x_2) #输入必须是一个二维的,如果是一个矩阵的话,输入的是矩阵的每行的
print(con_sim)
实施过程:
1.导入库
import pandas as pd
import re
import jieba
from tqdm import tqdm
from collections import defaultdict
import math
import operator
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
2.清洗数据
#读取EXCEL文件
df=pd.ExcelFile("企业经营范围(分年度).xlsx")
#读取所有sheetname
sheet_names = df.sheet_names
#读取对应sheet
df=pd.read_excel("企业经营范围(分年度).xlsx",sheet_name=sheet_names[0])
#查看空值
df.isna().sum()
#转日期格式
df["统计截止日期"]=pd.to_datetime(df["统计截止日期"])
#删除公司和经营范围重复的
df.drop_duplicates(subset=["股票代码","经营范围"], keep='first', inplace=True, ignore_index=False)
#删除空列
df.dropna(subset=["经营范围"],axis=0,inplace=True)
#重置index
df.reset_index(inplace=True,drop=True)

3.读取停用词文件
#读取停用词文件
f=open("stop_words.txt","r",encoding="utf-8")
stop_lst=f.readlines()
stop_words=[]
for i in stop_lst:
stop_words.append(i.replace("\n","").replace(" ",""))
4.关键词过滤提取函数
#键词过滤提取函数
def create_list(x,stop_word):
#print("删除()及 里内容")
result1 = re.sub(u"\\(.*?\\)|\\【.*?\\】|", "",x)
test_list = jieba.lcut(result1, cut_all=False)
old_list=[]
for i in test_list:
#过滤符合
str1=re.sub(r"[:!?,.、。,!;;:( )()\n “ ”+ ]","",i)
#过滤停用词
if str1!="" and str1 not in stop_word:
old_list.append(str1)
return old_list
5.遍历数据表对经营范围列进行关键字提取并汇总
#遍历数据表对经营范围列进行关键字提取并汇总
all_lst=[]
for i in tqdm(range(len(df))):
#print(i,df.loc[i,"经营范围"])
if pd.isna(df.loc[i,"经营范围"])==False:
all_lst.append(create_list(df.loc[i,"经营范围"],stop_words))
df.loc[i,"经营范围列表"]=",".join(create_list(df.loc[i,"经营范围"],stop_words))
6.关键词频统计,以列表形式返回
# 关键词统计和词频统计,以列表形式返回
def Count(words):
t = {}
i = 0
for word_lst in words:
for word in word_lst:
if word != "" and t.__contains__(word):
num = t[word]
t[word] = num + 1
elif word != "":
t[word] = 1
i = i + 1
# 字典按键值降序
dic = sorted(t.items(), key=lambda t: t[1], reverse=True)
return (dic)
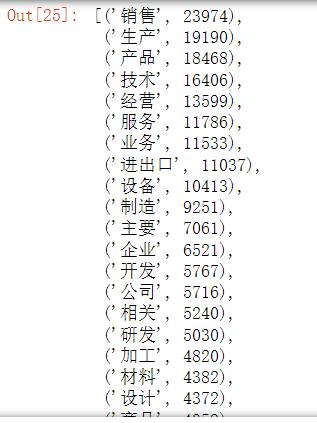
T1=Count(all_lst)
T1
6.合并关键词
def MergeWord(T1):
MergeWord = []
for ch in T1:
MergeWord.append(ch[0])
# print('重复次数 = ' + str(duplicateWord))
# 打印合并关键词
# print(MergeWord)
return MergeWord
mergeword = MergeWord(T1)
mergeword
7.关键字转换向量
# 得出文档向量(TF) T1为子数据,MER为母集数据
def CalVector(T1,MergeWord):
T1=Count1(T1.split(","))
TF1 = [0] * len(MergeWord)
#print(len(T1),len(MergeWord))
for ch in range(len(T1)):
TermFrequence = T1[ch][1]
word = T1[ch][0]
i = 0
while i < len(MergeWord):
if word == MergeWord[i]:
TF1[i] = TermFrequence
break
else:
i = i + 1
# print(TF1)
return TF1
8.制作需求数据模板
#制作需求数据模板
df_year=df[df["统计截止日期"].dt.year==2021]
df_year.drop(["统计截止日期","经营范围"],axis=1,inplace=True)
df_year.reset_index(drop=True,inplace=True)
df_year
9.转换所有公司向量放置集合tmp_xl
#转换所有公司向量放置集合tmp_xl
tmp_xl=[]
for i in tqdm(range(len(df_year))):
tmp_xl.append(CalVector(df_year.loc[i,"经营范围列表"],mergeword))
#使用api计算所有公司余弦相似度
cos_v=cosine_similarity(tmp_xl)
cos_v

10.遍历相似度矩阵匹配对应的代码或简称数据存入字典排序
#对结果进行匹配处理
tmp_cos=[]
for i in tqdm(range(len(df_year))):
dict_xl={}
#遍历相似度矩阵匹配对应的代码或简称数据存入字典
for j in range(len(df_year)):
dict_xl[int(df_year.loc[j,"股票代码"])]=cos_v[i][j]
#print(dict_xl)
#对字典按值进行降序
dict_sort = sorted(dict_xl.items(), key=lambda x: x[1],reverse=True)
a=0
#取字典前十数据写入数据模板
for k,v in dict_sort[1:11]:
df_year.loc[i,a]=int(k)
a+=1
tmp_cos.append (dict_sort)
#tmp_cos[0]
df_year

11.全数据处理
#全数据汇总
all_xl=[]
for i in tqdm(range(len(df))):
all_xl.append(CalVector(df.loc[i,"经营范围列表"],mergeword))
cos1=cosine_similarity(all_xl)
dict1={"name":df["股票简称"]}
for i in range(len(df["股票简称"])):
dict1[i]=cos1[i]
df2=pd.DataFrame(dict1)
col_lst=[]
for i in df["股票简称"]:
col_lst.append(i)
col_lst.insert(0,'name')
# for ii in tqdm(range(len(df))):
# df1.loc[ii,"name"]=df.loc[ii,"股票简称"]
# #df1.iloc[ii,1:]=cos1[ii]
df2.columns=col_lst
#df1.sort_values(by=["cos"],inplace=True)
df2
