#寻找真知派# #科学思维看百态# #深度学习 图像识别#
人工智能大常识(2):图像识别(以手写字符识别为例)
近期写一组关于人工智能的科普帖子。第一帖介绍了AI自动诊断的方法,本帖之后准备继续推出《人工智能大常识(3):文本理解(以新闻分类为例)》,基本包括了人工智能几个常见的应用领域:智能数据分析、计算机视觉、自然语言处理。敬请持续"关注"。之所以号称"大"常识,是因虽为常识,但需要用点儿心去读。所以这组帖子主要奉献给爱动脑、勤思考的老铁们,没兴趣的礼节性点个赞可以忙自己的事情。也可以先收藏了,或转发给别的可能感兴趣的朋友。如果不太忙,留言指导一下你爱看的帖子再走。
本帖通过手写字符识别的例子,向大家介绍人工智能在计算机视觉(又称机器视觉)中的应用。我在一个头条帖子中谈到过,智力的5个要素中,第一个就是感知力,也就是通过感觉器官感知现实世界的能力。资料显示,人们从客观现实中收到的信息,约80%来自于视觉。所以,在人工智能中,对于视觉信息的研究具有很重要的意义和广泛的应用价值:人脸识别、医学图像诊断、军事目标识别、异常行为检测、遥感图像处理、自动驾驶、产品品相观检测,等等。
一、特征提取与图像识别
尽管我们对人脑何识别图像的原理并不完全清楚,但并不影响我们探讨AI识别图像的途径,特征提取就是行之有效的方法。注意图1红框区域,动物宝宝们的眼睛、鼻子、嘴巴各有什么特征?

图1 观察动物定定们的各自特征,猜想计算机如何表述这些特征
如果你不知道如何表述动物宝宝们各自的特征就别费心了,因为用自然语言确实不容易准确地讲清楚。计算机当然也"说"不出来,但它有自己的办法,就是计算。"说"不出来的意思可以"算"出来,然后用数字表示图像的特征!
计算的对象是数,幸好,计算机"看"到的和记忆(存储)的图像就是数。
关于把图像划分为像素点,进而编码为数字的原理和方法,请参考其他相关文献。图2每个方格表示图像的一个像素点,每个像素点用一个0~255的整数表示:完全黑的像素值标记为0;完全亮的为255。这样一幅图像就可以用若干行、若干列组成的一组数表示了。图2对图像行列的划分比较粗,实际编码的像素点要小很多,也就是图像划分的行列数更多。

图2 图像数字化
我们看狗狗图像的上面部分,将其分为3个大方块,每一块仍包括许多个像素点,这样还是不利于概括这部分图像的特征。
如果规定一种计算方法(参见后面图5),将一个方块中的"多个"像素值计算成为"一个"。譬如,上面3个方块计算的值分别为:17、196、17,这3个数就是狗的两眼及两眼之间部分图像的特征值;类似地,狗狗其他部分也可以这样用这种方法表示其某一块图像的特征值。
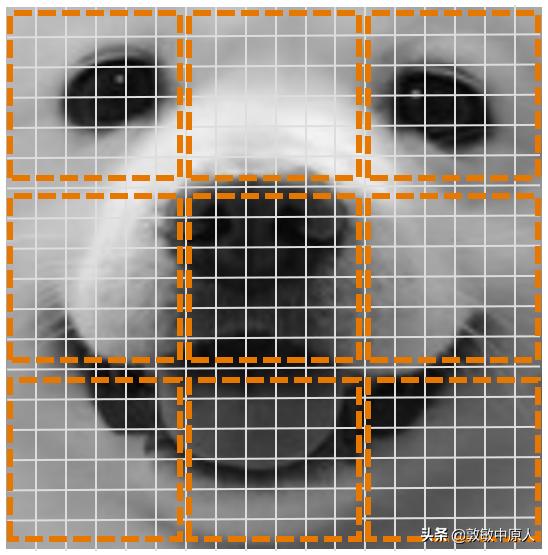
图3 图像特征的提取
实际应用中,由于一幅图像的像素点很多,一次抽取出的特征值可能还比较多,这就需要在此基础上用同样的方法,对已经取得的特征值再进一步抽取特征值,即取得"特征值的特征值"。这样的工作通常需要做5、6层(重),识别复杂图像甚至需要更多层。这就是深度学习之"深度"的含义。
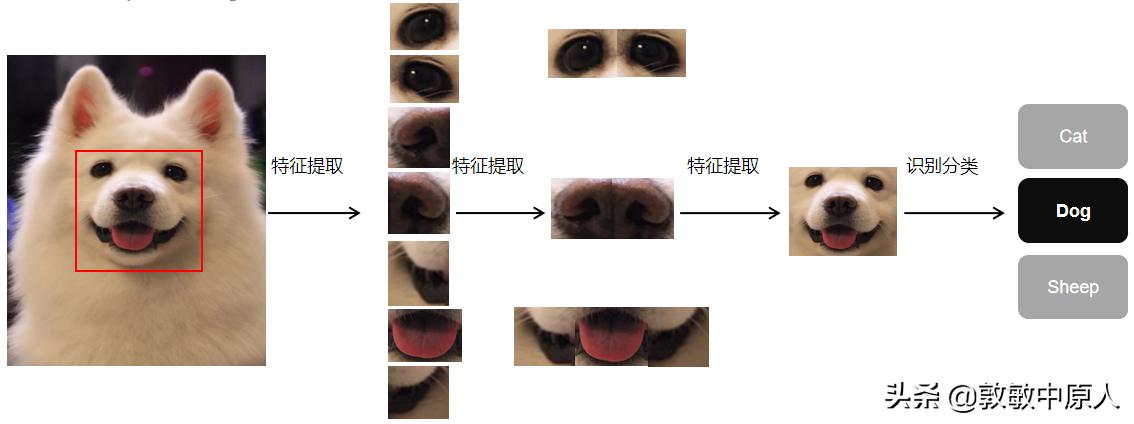
图4 多层(重)特征提取
一般地,第一层(重)特征提取通常是检测特定方向和形状的边缘,以及这些边缘在图像中的位置;第二层(重)特征提取往往是检测多种边缘的特定布局,同时忽略边缘位置的微小变化(池化);第三层(重)则把特定的边缘布局组合成为实际物体的某个部分;后续的层次将会把这些部分组合起来,实现物体的识别。
二、深度学习与卷积神经网络
深度学习是目前机器学习的常用技术,在图像识别中广泛应用。一般通过包含多层的人工神经网络实现,每一层完成一次图像特征的提取,把某些较细微的特征表示成更加抽象的特征,这些特征的提取、抽象过程都不需要人工干预和理解,完全由机器通过数据训练获取和认知这些特征,并在此基础上实现效果更好的识别和分类。卷积神经网络是深度学习用于图像处理的常见模型。
卷积神经网络(CNN = Convolutional Neural Network) 是计算机视觉领域目前应用较多的一种机器学习方法。主要用于图像处理与分析、车牌识别、人脸识别、物体检测与分类、自动驾驶等。
与普通神经网络相比,卷积神经网络中加入一个或多个特殊的隐含层——卷积层。每个卷积层的节点与上层节点并不完全连接,而是只连接其中相邻区域的部分节点,即一个感受野。具体的连接方法是,通过一个被称为卷积核的矩阵,譬如3×3的方阵,与输入层相对应节点值构成的同型方阵(感受野),做"点乘"运算,其结果就是卷积层的一个节点值。
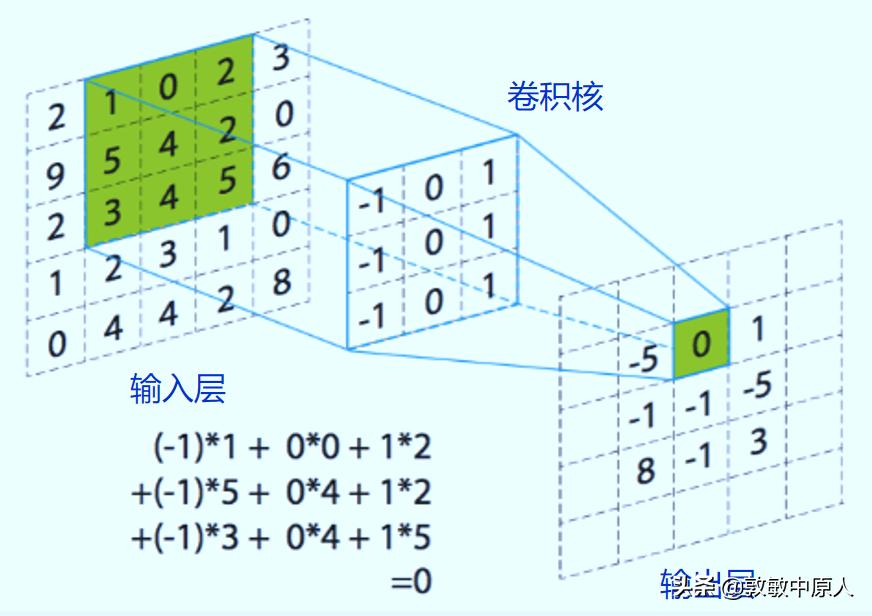
图5 卷积神经网络
也就是说:输入层一个"感受野"区域(3×3的方阵)的节点值,被"感受"(运算)为一个单一值,映射到卷积层的一个节点。这就是卷积神经网络提取图像特征的基本方法,也是提出卷积神经网络的最重要意义所在:网络自动提取和学习图像特征,这个特征被抽象为一个数值来表示。
根据前面介绍的神经网络的结构不难理解,卷积核矩阵中的数相当于前面神经网络中的一组权值。该组权值被确定后在该卷积层不再改变,称为"共享参数"。
节点的部分连接与共享参数是卷积神经网络的两个主要特点。下面我们使用卷积神经网络来识别手写数字字符。
三、手写字符识别
从计算机视觉的角度,一个手写字符被看作一幅图像,把这幅图像识别为一个字符的过程称为手写字符识别。计算机为什么可以把手写符号2和Z分别识别为数字"2"和英文字母"Z"这样两个不同的字符?关键在于对不同字符形状特征的认识。CNN正是通过卷积层不断捕捉和提取手绘图像中的特征。我们以手写数字"2"的识别为例,学习CNN通过卷积计算提取图像特征的工作原理。
简单起见,令表示"2"的数字图像为二值图像,像素数为6×6,即图像的横向、纵向点阵均为6个像素点。并规定有笔画的地方为黑色,用数值1表示;其他位置为白色,用数值0表示。卷积核由3×3 = 9个数值构成,与输入层左上角区域9个节点数值做"点乘"运算,结果"5"保存在卷积层左上角节点位置。卷积层这个节点值5代表了数字图像"2"左上角部分向右上的一段弧,这就是对"2"这个字符一部分特征的提取或抽象。当然数字"3"、"8"等的图像相应的左上角部位可能也具有这样的特征,但随着卷积运算的进行,其他部位的特征将会把它们区别开来。见图6。
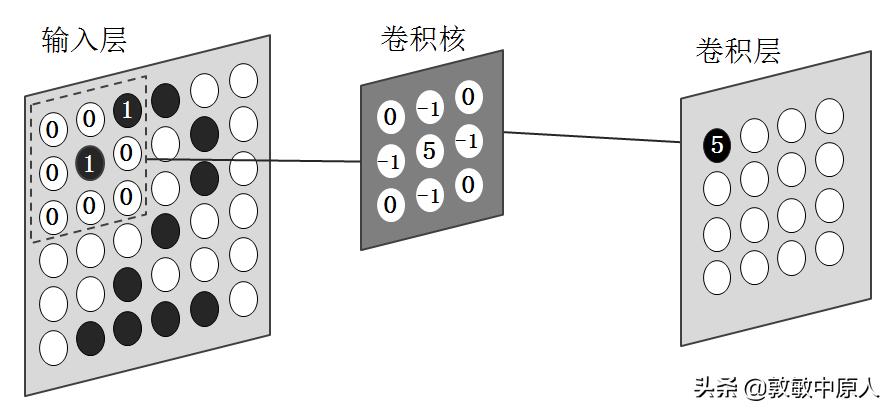
图6 "2"的左上角部分图像的特征提取
卷积运算第二步,将输入层中的虚线框右移一位,所对应的输入值矩阵继续与卷积核矩阵作同样的点乘运算,结果为-2。……
该卷积层4×4=16个节点的值,就代表了对字符"2"不同部分形状特征的抽象,抽象的结果用数值标识。这是对字符图像较小局部特征的提取或抽象。
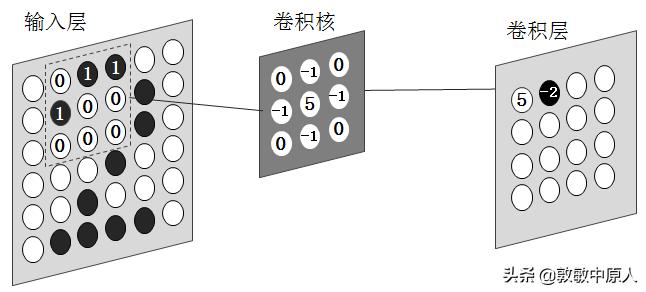
图7 卷积运算第二步,特征值"-2"的提取
将上述4×4=16个节点的卷积层作为下一级卷积运算的输入层,并对该输入层再次做相同的卷积运算,卷积核仍保持3×3=9个元素组成(具体元素值可能有所不同),相对应的下一级卷积层则由2×2=4个节点构成。这一层卷积运算是对上一层卷积运算所得图像局部特征的再次抽象,所得的4个结节值可以理解为数字图像"2"的左上、右上、左下、右下等4个部位形状的特征值。最后还要加一个全连接层,构成一个完整的图像识别网络,其输出值就是一个手写字符识别的结果。
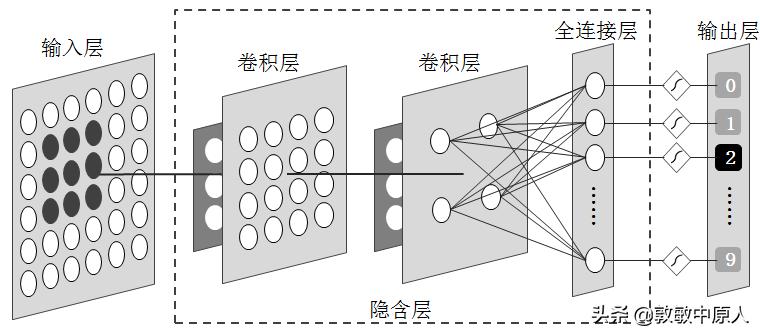
图8 完整的图像识别网络
小结:本帖介绍了人工智能进行图像特征提取和识别的基本原理,介绍了一种非常常用的深度学习方法:卷积神经网络,并通过该网络识别了手写数字2。举一反三:其他数字、字符、图像等都可以通过这种方法识别。
向耐心读完的老铁致敬!请点关注,静候《人工智能大常识(3):文本理解(以新闻分类为例)》的出笼。如有错讹之处,请各位高人批评拍砖,不吝赐教。
#寻找真知派# #科学思维看百态# #深度学习 图像识别#