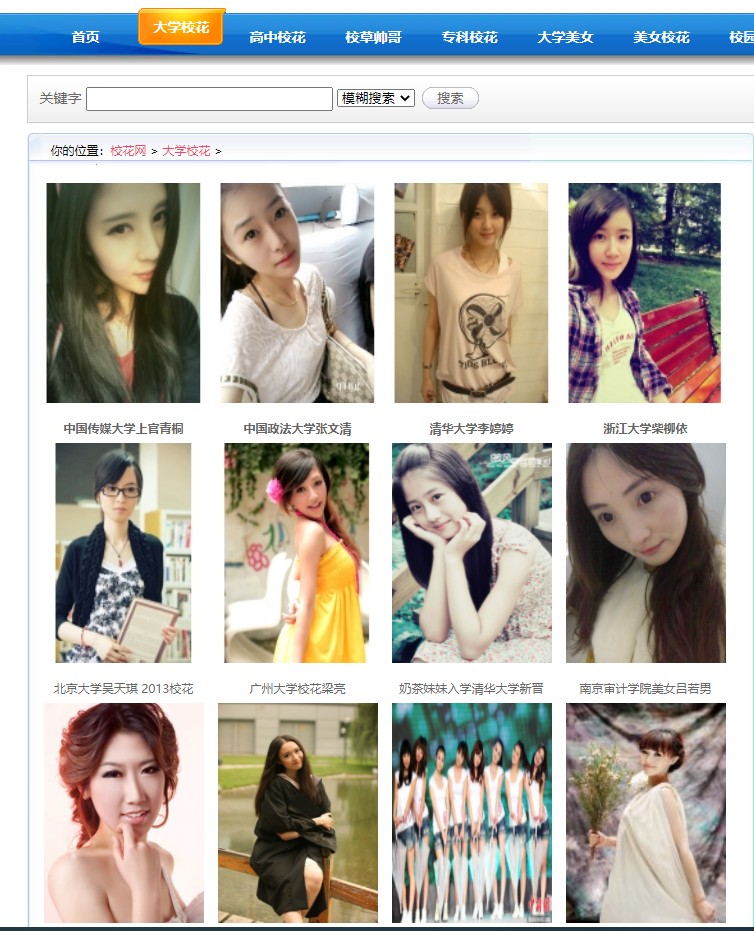
偶然一次,我在深夜难眠时,突然一道靓丽的网站从我眼前滑过,猛然使我惊醒。我发现校花网好多漂亮小姐姐的照片啊!嘿嘿,留下当手机壁纸不错,yyds!
于是,我利用了Python一次性把她们的照片*载下**了出来!
那么,我们该如何一次性爬取*载下**这些令人心动的照片呢?
我们先来看下怎么爬取一张图片的数据:
- 方式1:基于requests
- 方式2:基于urllib
urllib 模块作用和 requests 模块一样,都是基于网络请求的模块
当 requests 问世后就迅速地替代了 urllib 模块
比如,我们现在准备爬取这张可爱的熊熊:
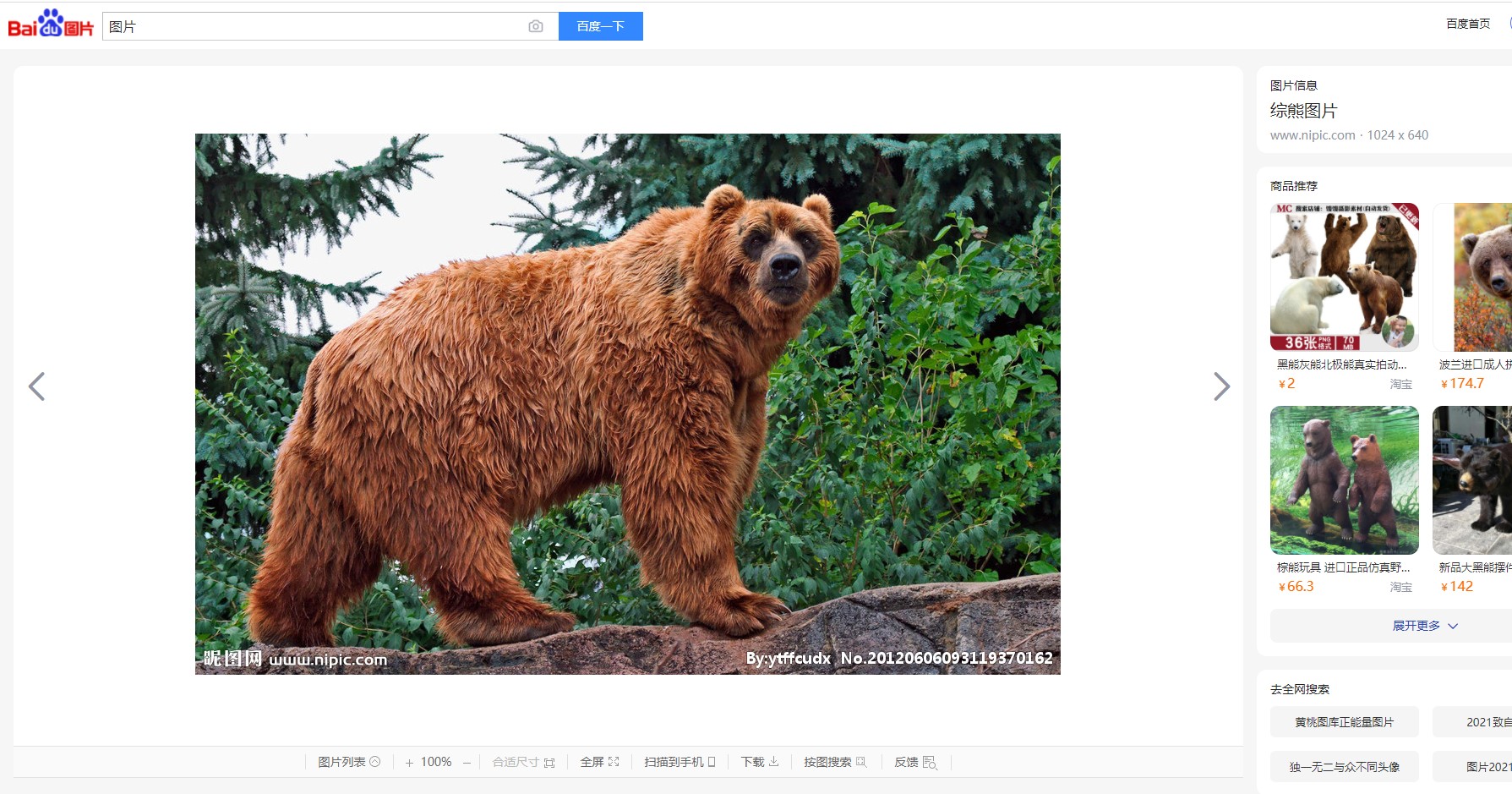
先用右键复制图片地址:
img_url = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fpic21.nipic.com%2F20120606%2F5137861_093119370162_2.jpg&refer=http%3A%2F%2Fpic21.nipic.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1634794705&t=162f415928fef44dc6fb006639dd034d'
requests 方式:
response = requests.get(url=img_url, headers=headers)
img_data = response.content # content返回的是二进制形式的响应数据
with open('1.jpg', 'wb') as f:
f.write(img_data)
# 图片就保存为 '1.jpg'
urllib 方式:
# 可以直接对url发起请求并且进行持久化存储
urllib.request.urlretrieve(img_url, './2.jpg')
上述两种爬起图片的操作不同之处是什么?
使用 urllib 的方式爬取图片无法进行 UA 伪装,而 requests 的方式可以。不需要 UA 伪装的情况下,使用 urllib *载下**图片更方便!
现在,爬取一张图片的方法我们学会了。那怎么才能批量*载下**小姐姐的照片呢?(我的键盘早已饥渴难耐!)
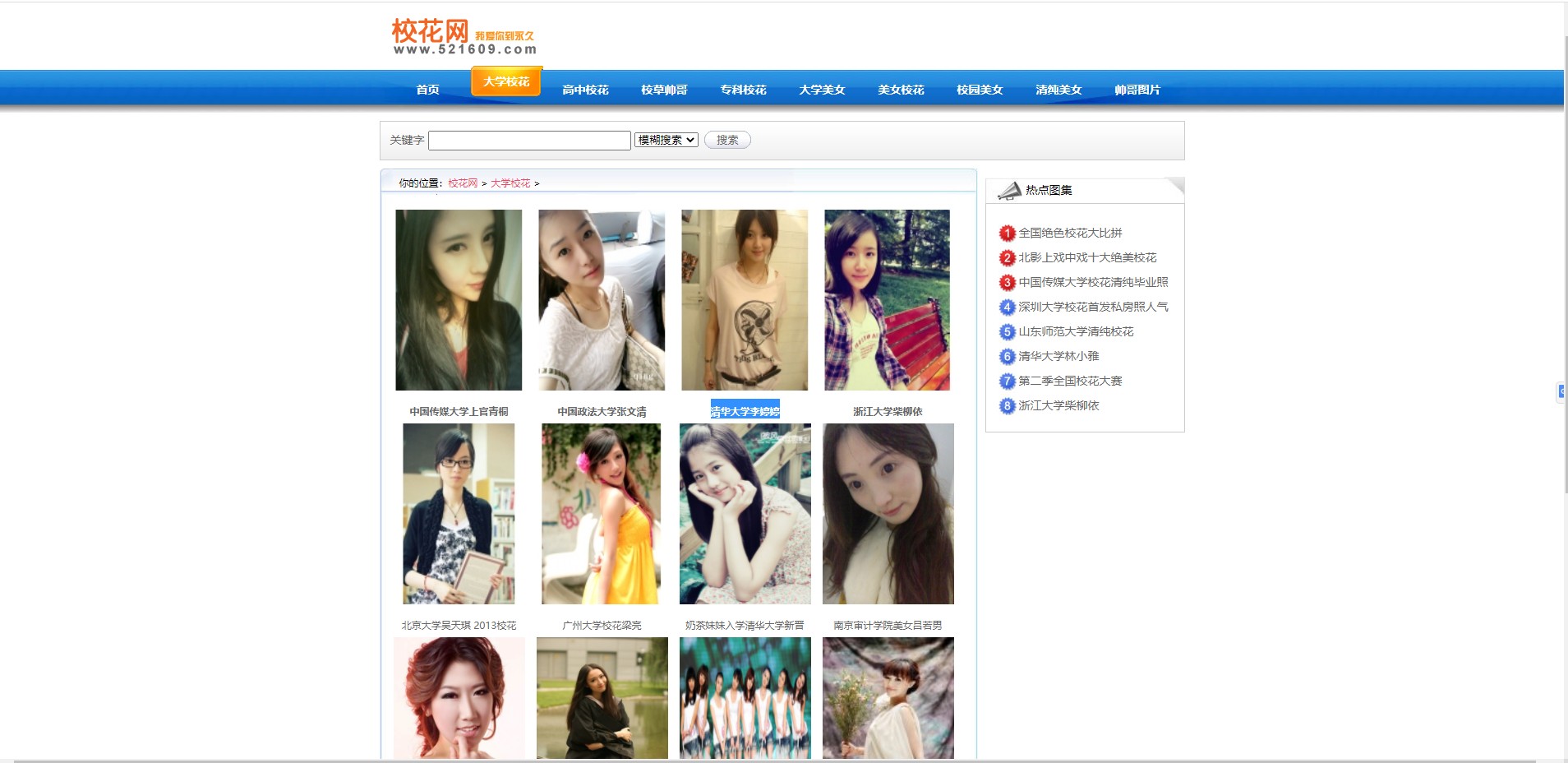
第一步,我们先复制本页面的地址:
url = http://www.521609.com/daxuexiaohua
操作:需要将每一张图片的地址解析出来,然后对图片地址发起请求即可
写代码之前,我们先来了解下 浏览器开发者工具 :
分析浏览器开发者工具中Elements和network这两个选项卡对应的页面源码数据有何不同之处?
- Elements中包含的显示的页面源码数据为当前页面所有的数据加载完毕后对应的完整页面源码数据(包含了动态加载数据)
- network中显示的页面源码数据仅仅为某一个单独的请求对应的响应数据(不包含动态加载数据)
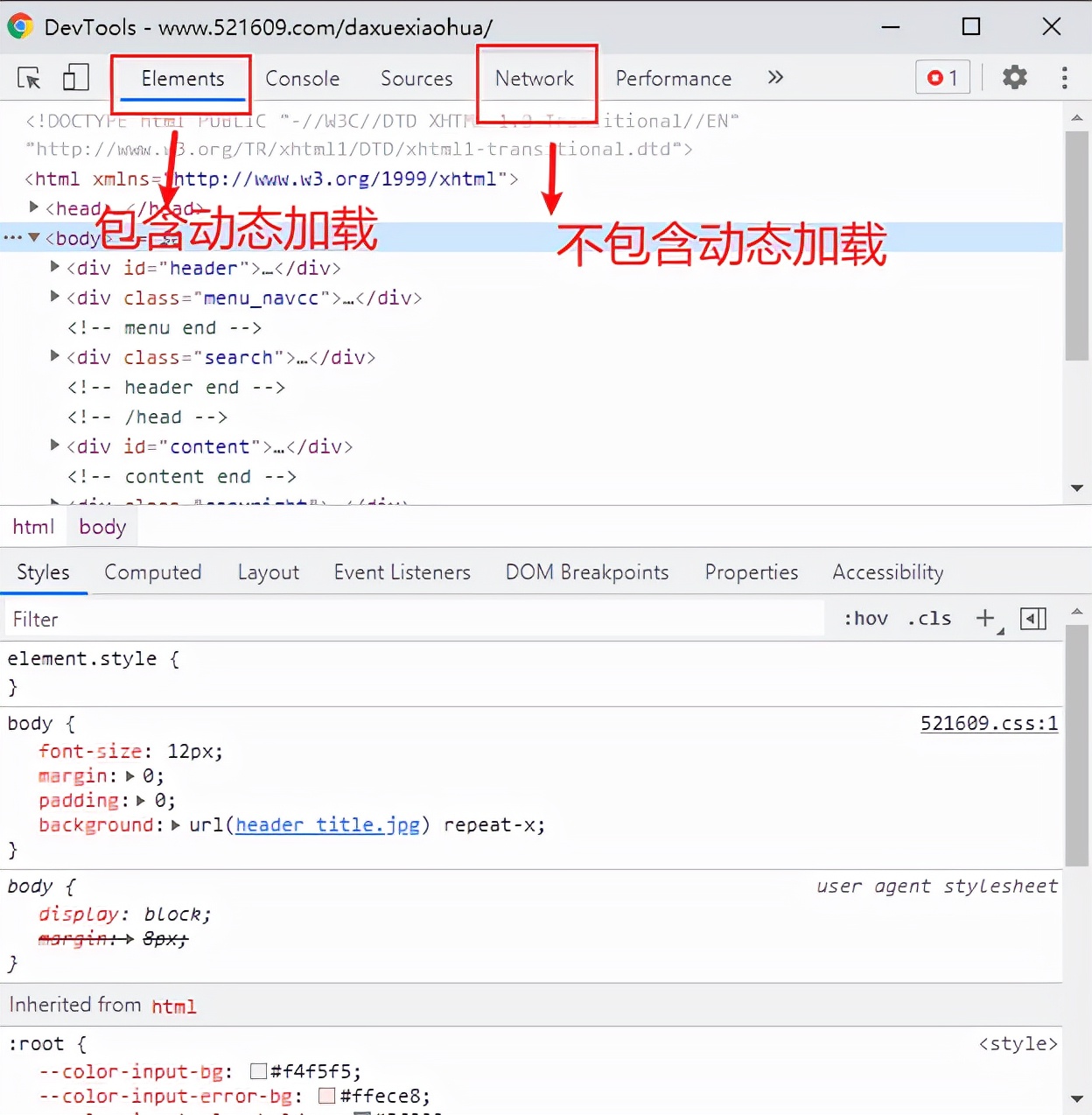
结论:如果在进行数据解析的时候,一定是需要对页面布局进行分析,如果当前网站没有动态加载的数据就可以直接使用Elements对页面布局进行分析。否则只可以使用network对页面数据进行分析。
很显然,当前网站没有动态加载的数据。那么就可以直接使用Elements对页面布局进行分析
爬取前:我们需要使用Elements捕获出图片地址,可以看到图片地址在源码里的 <li> 节点里:
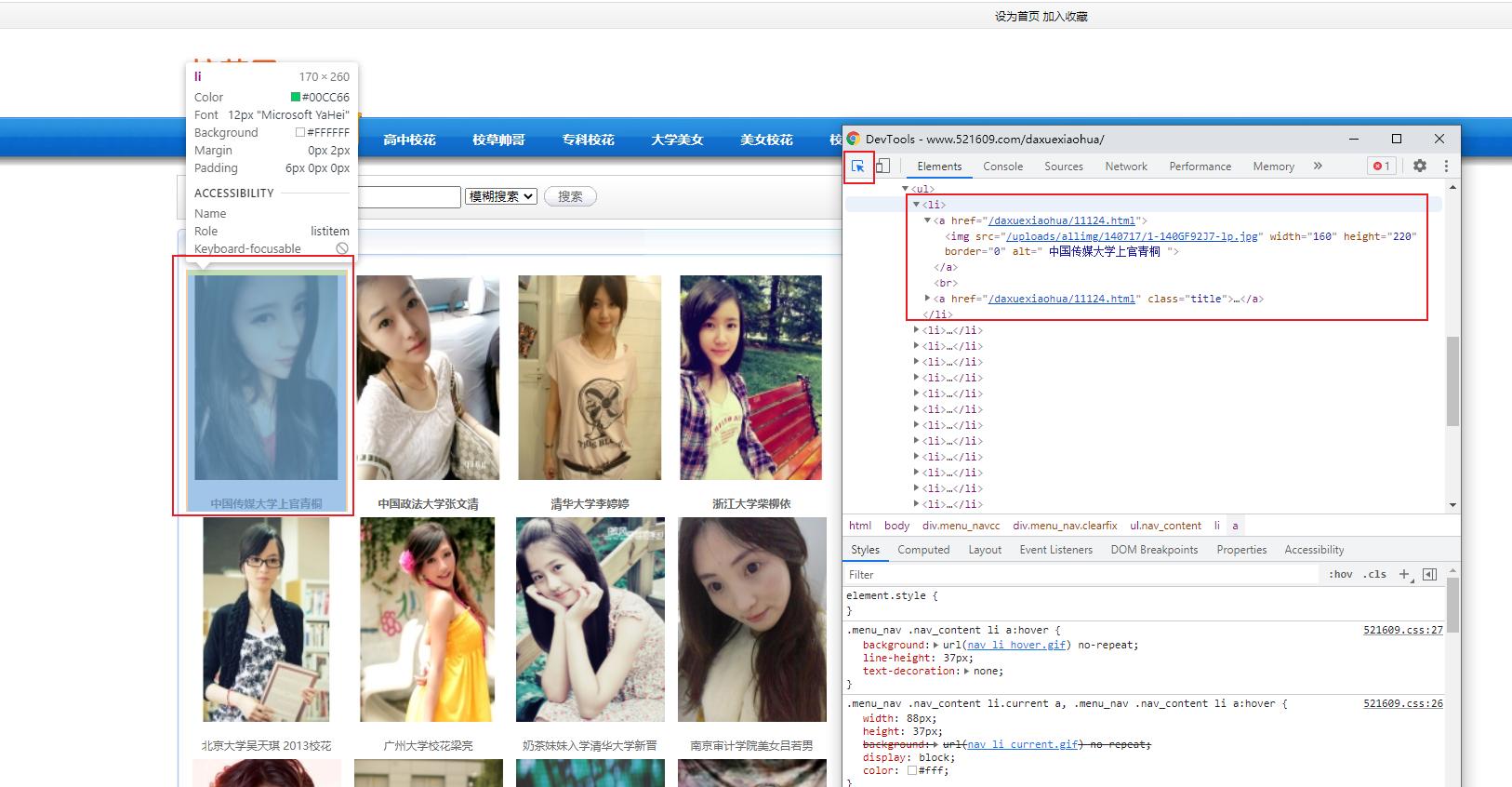
复制 <li> 节点里的源码:
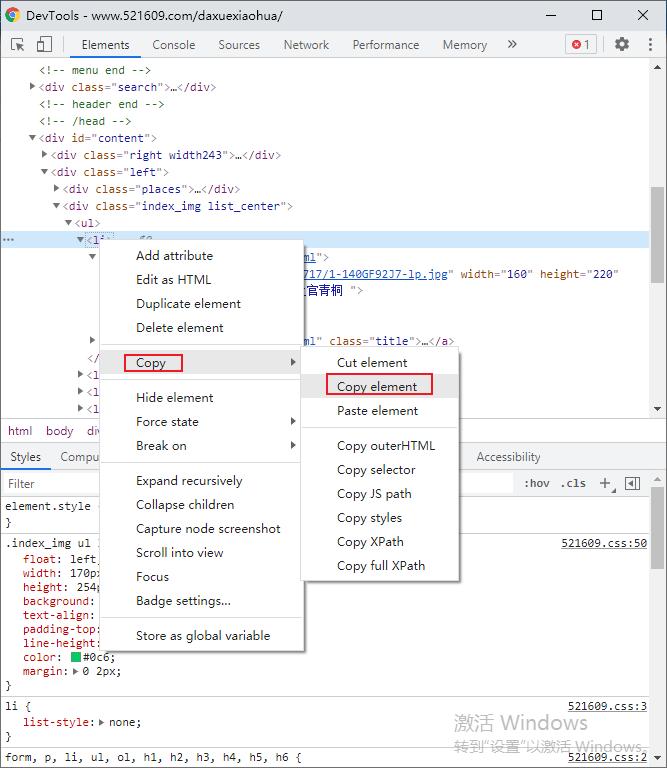
# 此处为复制出的源码:
<li><a href="/daxuexiaohua/11124.html">
<img src="/uploads/allimg/140717/1-140GF92J7-lp.jpg" width="160" height="220" border="0" alt=" 中国传媒大学上官青桐 ">
</a><br>
<a href="/daxuexiaohua/11124.html" class="title"><b>中国传媒大学上官青桐</b>
</a>
</li>
具体代码实现*载下**步骤: (咱们课程主要讲解爬虫的抓包方式和解析方法,具体正则写法等基础教程,可以关注我的Python基础教程)
import re
import os
# 1.捕获到当前首页的页面源码数据
url1 = 'http://www.521609.com/daxuexiaohua'
page_text = requests.get(url=url1, headers=headers).text
# 2.从当前获取的页面源码数据中解析出图片地址,并用正则写出:
ex = '<li>.*?<img src="(.*?)" width=.*?</li>'
# 正则写好后我们现在开始获取
img_src_list = re.findall(ex, page_text)
print(img_src_list)
# 我们发现打印的是[]。这是因为源码里有空格和换行
# 代码应该是:
img_src_list = re.findall(ex, page_text, re.S)
print(img_src_list)
# 现在我们看出获取的地址只是部分,例:'/uploads/allimg/140717/1-140GF92J7-lp.jpg'
# 我们可以直接在网页上复制图片地址'http://www.521609.com/uploads/allimg/140717/1-140GF92J7-lp.jpg'
# 加上前缀,遍历列表,获取完整地址.进行请求
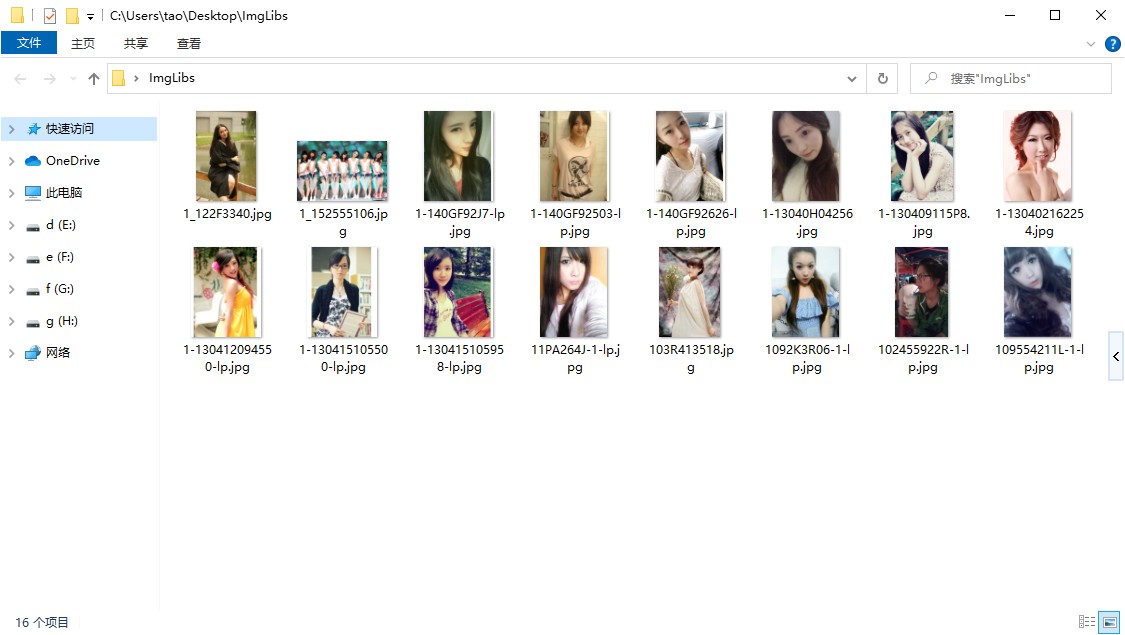
# 新建个文件夹存储图片
dirName = 'ImgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
for src in img_src_list:
src = 'http://www.521609.com' + src
imgPath = dirName + '/' + src.split('/')[-1] # 图片名称
urllib.request.urlretrieve(src, imgPath)
print(imgPath, '*载下**成功!!!')
结果我们就一次性*载下**完小姐姐的照片了!
关注 Python*哥涛** ,学习更多Python知识!