作者:Srinivas Gumparthi博士,Venkata Vara Prasad博士
来源:SSRN
发布:2022.08.31
摘要
目的:股票价格预测一直作为一门研究课题,因为它在国家宏观经济中具有重要的作用。很难用一组特定的公式写下股票的未来价值。当我们预测一只股票的未来价格时,许多因素都会出现。其中最重要的是历史价格和成交量数据。
方法:随着机器学习的兴起,人们提出了多种预测股票价格的方法。目前,已开发了RNN、LSTM、CNN滑动窗口等各种模型,但都不够精确。这项工作的兴趣在于预测股票的价格,以及比较使用两种算法,即Kalmam Filters(卡尔曼滤波器)和XGBoost,并获得结果。Kalmam Filters本质上是递归的,并使用反馈机制进行误差校正。这种修正能让他们做出准确的预测,因为它们可以将市场波动考虑在内,而XGBoost对于非线性数据集来说是一种很有前途的技术,可以通过检测数据中的模式和关系来收集知识。此外,XGBoost还能有效地捕获特征的时间依赖性。
新颖性:最后,结合Kalmam Filters和XGBoost开发了一个Hybrid(混合)模型,给出了未来投资和股票预测所需的完美预测。与Kalmam Filters和Hybrid模型相比,XGBoost的平均准确率更高。
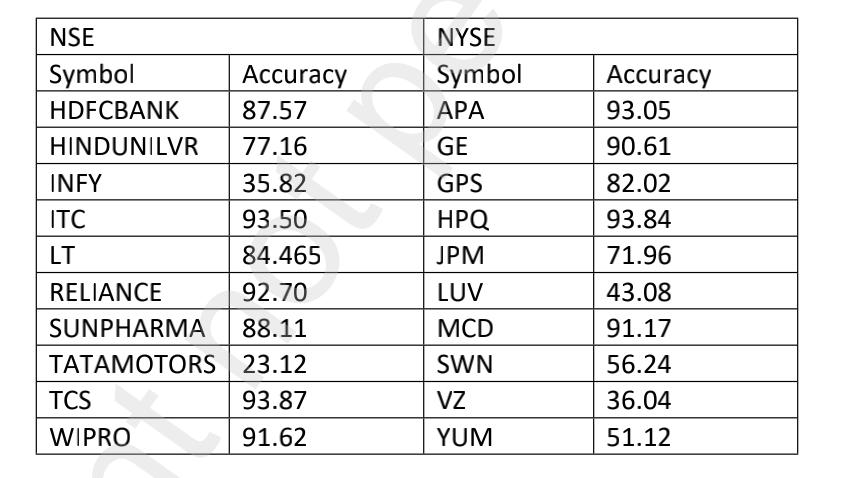
研究结果:混合模型似乎能准确地预测样本的未来趋势,但并不是对所有样本都能做到这一点。XGBoost模型对NSE(国家证券交易所)数据集的平均准确率为88.66%,对NYSE(纽约证券交易所)数据集的平均准确率为90.11%。Kalmam Filter模型对NSE数据集的平均准确率为89.09,对NYSE数据集的平均准确率为64.96。该Hybrid模型对NSE数据集的平均准确率为76.79%,对NYSE数据集的平均准确率为70.91%。然而,对于个股,Hybrid模型表现优于XGBoost和Kalmam Filter。
关键字:XGBoost,Kalman Filter,Hybrid模型,NSE,NYSE,市场情绪
1. 介绍
如今,股票市场已成为大家的一个重要投资领域,很多普通人也对股票投资很感兴趣。受环境、政治和其他社会因素的影响,股票市场价格波动很大。因此,有必要对股票价格预测进行广泛分析。早期的统计模型和机器学习模型用于股票价格的预测。但考虑到历史数据,数据量越来越大,这些模型在股票价格预测方面的准确性逐渐下降。因此,在当前的工作中,作者提出了一种结合统计和机器学习模型的混合模型。利用Kalman filter(统计模型)和XGBoost(机器学习模型)的优点来提高预测准确度。
很多研究人员使用各种统计和机器学习模型来解决这个问题。很少有人研究这些模型的组合,也很少有人给出印度股市带来的显著结果。Chatziset等人[1]的研究旨在利用机器学习技术预测股市危机事件。该方法是基于寻找股票市场崩盘事件在不同时间框架的概率。考察了股票、债券和货币市场之间的交叉传染效应。使用模型预测日收益,利用对数收益的平方计算日波动率。XGBoost在1天和20天内都有最佳的经验表现。
Sen等人[2]使用具有反向传播算法的ANN(人工神经网络)作为训练阶段,并使用多层前馈网络(multilayer feed-forward network)作为预测股票价格的网络模型。研究了一种基于ANN的股票交易决策支持系统。本文还讨论了基于决策过程的神经网络的研究进展。该模型随输入值和时期的不同组合而变化。它输出性能曲线、误差曲线和输出图形。验证效果良好,回归值为0.996。
Dey等人[3]将各种深度学习算法与XGBoost进行比较,以预测Yahoo数据集的股票市场回报。预测周期分别为28天、60天和90天。已经计算了每一项的准确性、预测性、召回率和特异性。绘制每个模型的假阳性率。
Karyaet等人[4]在论文中,采用集合卡尔曼滤波平方根法(EnKF-SR)和集合卡尔曼滤波法(EnKF)对股票价格进行预测。模拟结果表明,EnKF方法的估计结果比EnKF-SR方法更精确,即EnKF方法的估计误差约为0.2%,而EnKF-SR方法的估计误差为2.6%,。
Mortezaet等人[5]的项目,试图在NSE上使用机器学习技术来预测股票的未来价格,他们使用线性回归和SVM回归。线性回归将使用股票前一天的收盘价来预测股票第二天的开盘价。SVM回归将用于预测第二天股票的收盘价和开盘价之间的差值。外汇汇率、NSE指数、移动平均线、相对强弱指数等外部因素,被用来获得最大的准确性。
Dev Shah等人[6]在论文中,讨论了股票市场分析的技术和基本方法。在技术分析中详细讨论了统计、机器学习、模式识别、情感分析和混合技术,还考虑了算法交易。作者总结说,包含混合和统计的机器学习技术,将产生更好的结果。人工神经网络(ANN)是人工智能(AI)的一部分,是一种识别数据中隐藏的、未知的、适合股票市场预测模式的常用方法。所选股票的历史数据用于建立和训练模型。
Song等人[7]在论文中,将RNN-LSTM模型与SVM和XGBoost进行了比较。数据集是通过应用Python库从Google Finance的API中获得的。选择了20家在NASDAQ(纳斯达克)和 NYSE(纽约证券交易所)交易的公司。考虑了RSI、ADX和抛物线SAR等指标。通过绘制测试集误差图来比较结果。
Wanjawaet等人[8]的研究,提出使用具有多层感知器的前馈人工神经网络,通过反向传播来预测股票价格。该模型分4个阶段进行迭代。数据集来自内罗毕证券交易所(the Nairobi Stock Exchange)和NYSE(纽约证券交易所)。通过改变隐藏层和感知的数量进行调优。每个调优实验都基于前一个实验模型进行的。最终模型的配置比为5:21:21:1,使用80%的可用数据进行训练。采用均方根误差作为参数,将获得的结果与原始结果进行比较。结果表明,该模型对股票价格的预测具有较好的效果。
徐等人[9]进行了比较文献调查,证明ANN比SVM预测更准确。使用反向传播训练若干个前馈ANN。该评估是在NASDAQ证券交易所进行的,采用了6个月的数据集。模型的输入是短期历史股票价格和每周的天数。通过对每个隐藏层中神经元数目和设置不同的值,来优化神经网络的结构。
郑红英等人[11]提出了一种新的深度学习模型-随机长短期记忆(Random Long Short Term Memory,RLSTM),旨在防止过拟合。该模型由Modaugnet-C框架和另一个用于预测的LSTM模块组成,Modaugnet-C框架通过一个LSTM模块和另一个LSTM模块来增强单个LSTM模块的潜力,其中一个LSTM模块可以使用额外的增强数据来降低过拟合的风险,这些数据与用于预测的股票数据有很强的相关性。这在SSEC和S&P500数据集上进行了测试,该模型在准确性上优于其他模型。
Widodo Budiharto[12]提出了一个模型,该模型结合了LSTM和基于R语言的统计计算,用于预测Covid-19大流行期间印度尼西亚交易所的股票。该模型在预测不到一年的短期数据时表现良好,准确率达94.5%,超过了长期数据的预测。
Salvatore M. Cartaet等人[13]使用机器学习方法,借助决策树的二元分类技术来衡量未来股票价格波动的幅度。这些词汇是从全球发表的文章、行业相关新闻等中识别和生成的。这些数据将与提取的特征一起输入到预测模型。这在S&P 500指数公司进行了测试,但准确率只有50-60%。
Milad等人[14]比较了人工神经网络和启发式算法(如蜘蛛优化和蝙蝠算法)与传统的时间序列模型(如ARMA和ARIMA)来预测股票价格。这些模型用于各种国际指数,如Nasdaq指数、S&P500指数和DJI指数。与时间序列模型比较,ANN模型的误差最小,预测效果更好。
Zelingheret等人[15]测试使用各种机器学习模型来预测玉米价格的波动。他们考虑了线性模型,分类和回归树,随机森林(Random Forest),梯度聚类(Gradient Goosting)。这些方法基于均方根误差(Root Mean Square Error,RMSE)、漏一交叉验证(Leave one out Cross Validation,LOOCV)等,证明对玉米价格预测有效。
Chetan等人[16]使用多种机器学习算法(如KNN、逻辑回归、Naïve Bayes、Random Forest、SVM、决策树等)进行了比较研究,并结合情绪分析来预测Covid-19大流行期间的股票价格,因为这个时期社交媒体存在大量情绪。在所考虑的模型中,逻辑回归模型表现最好,而KNN模型的准确性最低。
2. 设计和方法
预测模型的架构图(如图1所示)。首先清理从NSE获得的数据集,以检查空值,并获取从Yahoo Finance收集的市场情绪数据。然后对其进行预处理,以获得各种其他特征,例如调整后的闭合因子、闭合偏移、开启偏移、开启差、闭合差、高差和低差等。输入正在清理的库存数据。然后将该数据发送到三个模型中的每一个。在第一个模型——Kalman Filter,数据在每次迭代时都要经过预测和更新步骤。在预测步骤中,根据在前一时间步骤K-1更新的特征计算下一时间步骤K的收盘价。在更新步骤中,与前一时间步骤的预测相对应的特征被更新。在XGBoost中,数据集经历两个阶段——拟合和预测。在拟合阶段,该模型递归地构建各种决策树,将范围缩小到损失函数值最小的决策树。在预测阶段,使用此决策树进行下一步的预测。对于Hybrid(混合)模型,我们首先运行XGBoost算法来执行特征选择。这些特征输入到Kalman Filter,预测股票的收盘价。然后,我们执行输出分析以比较模型的结果。

图1 体系结构图
2.1 Kalman Filter
在统计学中,Kalman Filtering是一种算法,使用一系列测量数据,包含随时间推移观察到的统计噪声和不准确性。该算法对未知变量的估计往往比仅基于单一特征的估计更准确。它估计每个时间段变量的联合概率分布。Kalman Filter是以Rudolf E. Kalman名字命名的,他是该理论的主要开发者之一。
Xk=Fk*Xk+BkUk+Wk
Fk是应用于先前状态Xk-1的状态转换模型,
Bk是应用于控制向量Uk的控制输入模型,
Wk是假定从零均值多元正态分布中提取的过程噪声。
2.2 XGBoost
XGBoost是一种以开源方式实现的高效且流行的梯度增强树算法。梯度提升(boosting)是一种监督学习算法。XGBoost试图通过组合一组更简单、更弱的模型的估计值来准确预测目标变量。
XGBoost是一种集成学习方法。集成学习提供了一种系统的解决方案,结合了多个学习者的预测能力。结果是一个单一的模型,它来自多个模型的聚合输出。形成集成的基本学习者,可以来自相同的学习算法或不同的学习算法。广泛使用的集成学习者是Bagging和Boosting。XGBoost最主要的用途是决策树,其次是统计模型。
当使用梯度提升进行回归时,每个回归树都将一个数据点映射到它的一个连续叶子上,且弱学习者是回归树。XGBoost最小化了一个正则化目标函数,该目标函数结合了凸损失函数和模型复杂性的惩罚项。训练迭代地进行,添加新树来预测先前树的残差,然后将这些树与先前树组合起来,以进行最终的预测。被称之为梯度提升,是因为它使用梯度下降算法来最小化添加新模型时的损失。
3.数据集及其实现
3.1数据集
该数据集包含来自纽约证券交易所(NYSE)和国家证券交易所(NSE)的10个脚本的股票价值。股票的名称及其符号如下表1所示。
表1:显示了所考虑的数据集

HDFCBANK数据的样本如表2所示。它由开盘价、收盘价、最高价、最低价、交易量、调整后收盘价、每股收益、市盈率等列组成。我们既考虑了股票的基本面,也考虑了市场情绪,这有助于我们更好地预测。
表2:来自NSE的HDFC银行数据集

我们使用皮尔逊相关矩阵发现了每一对特征之间的数据相关性。如图2所示。数据关联有助于理解数据集中多个变量和属性之间的关系。使用相关性,我们可以获得一些见解,例如一个或多个属性依赖于另一个属性,或另一个属性的原因,以及一个或多个属性与其他属性相关联。

图2 数据集*特中**征的相关性
对数据集进行预处理以获得其他特征,例如调整因子(Adjusted Factor)、调整闭合位移(Adjusted Close Shift)、开放位移(Open Shift)、高差(High Difference)、低差(Low Difference)、开放差(Open Difference)和关闭差(Close Difference)等特征。预处理后的数据集如表3所示。
表3:预处理的HDFC数据集

调整后的收盘价和开盘价有助于将前一天调整后的收盘价和开盘价与第二天调整后的收盘价和开盘价相关联。开盘价、最高价、最低价和收盘价分别乘以调整因子,使其与调整后的收盘价相对应。
Pankaj Kumar[11]博士的研究结果表明,每股收益是所选公司股票市场价格的可靠预测指标,市盈率对股票市场价格的预测有显著影响。因此,从整体上看,每股收益是A股市场价格表现的主要反映指标。
3.2 Kalman Filter
3.2.1初始化
卡尔曼滤波器(Kalman Filter)类被定义为数据成员F(应用于前一步骤的状态转移)、H(将正确状态映射到观测状态)、Q、R和P(噪声协方差矩阵和后验状态估计)初始化为单位矩阵和X-平均或预测状态估计。
3.2.2预测
该步骤必须预测系统的均值X和协方差P。当给定卡尔曼(Kalman)对象作为输入时,函数predict执行预测。
3.2.3更新
该步骤计算给定待更新的特征Z及其标准偏差R系统的均值X和协方差p。函数更新执行X,y(测量值和实际值的差值)的更新,S,K(卡尔曼增益),P(协方差)。矩阵乘法利用向量的点积。
对于每个时间步长K,执行预测和更新步骤以获得预测值。该预测数组由必须进行预测的日期相对应的收盘价组成。这些值取决于参数,如打开、高、低、调整关闭、调整关闭位移、开放位移、EPS、PE比率等。在这一步之后,我们必须通过对照地面实况来计算预测中的误差。对于此计算,我们使用绝对百分比误差的平均值,其计算公式为:error = [(measured – predicted)/(measured)] * 100(误差=[(测量-预测)/(测量)]*100)。预测图是在考虑的整个时期内绘制的。为此,我们使用Python中可用的matplotlib包。
3.3 XGBoost
下面将详细讨论所涉及的算法和XGBOOST算法的实现细节。该实现是在Anaconda框架下使用Python完成的。
3.3.1 Bagging
尽管决策树是最容易解释的模型之一,但决策树表现出高度可变的行为。考虑将被随机分成两部分的单个训练数据集。每个部分将训练一个决策树以获得两个模型。当这两个模型都符合时,它们将产生不同的结果。由于这种行为,决策树被认为与高方差有关联。Bagging或Boosting聚合有助于减少任何学习者的差异。并行创建的几个决策树构成了Bagging技术的基础学习者。用替换后的样本数据对这些学习者进行训练。最终的预测输出是所有学习者的平均输出。
3.3.2 Boosting
在Boosting中,所有的树都是按顺序构建的,这样每个后续的树都会减少前一棵树的错误。每棵树从它的前项中学习并更新错误。因此,所有后续的树将从错误的更新版本中学习。偏差很高的基础学习者是弱学习者,预测能力只比偶然猜测强一点点。每一个弱学习者都为预测提供了重要信息,从而通过组合这些弱学习者来产生一个强学习者。最后一个和最后的强学习者具有较低的偏差和方差。
与随机森林(Random Forest)等Bagging技术形成鲜明对比的是,XGBoost中的Boosting模型利用了分裂次数较少的树。这样的小树是高度可解释的,因为树的深度非常小。迭代次数或树的数量、梯度提升的学习率和树的深度等参数,可以通过k-fold交叉验证等验证技术进行优化选择。过拟合是由于树太多造成的。因此,有必要谨慎选择助推的停止标准。
3.4 Hybrid Model
Hybrid Model(混合模型)是统计模型,Kalman filter 和机器学习模型XGBoost 的组合。Hybrid模型有助于正确预测股票价值,提高各种数据集的准确性和一致性。当利益变量不能直接测量时,Kalman filters 可以最优地估计感兴趣的变量,间接测量是可用的。对于这种间接测量,可以使用14个参数。通过特征提取,XGBoost算法在14个参数中根据权值取前5个参数。前5个参数因股票而异。将这5个参数输入Kalman filter,对未来股票价值进行预测,并提取输出。
通过在测试集中输入no,对以下每个模型进行测试,测试集包含400天的库存数据,预测必须在几天后进行。所有的模型都用两个不同的数据集进行了测试——一个由价格变动组成,另一个由价格变动和市场情绪组成。价格变动包括开盘价、最高价、最低价、收盘价、成交量、股息率、成交量等数据。市场情绪是指投资者对某一特定证券的整体心理。这是普通大众的感觉,通过证券交易的价格变动表现出来。极高的市盈率(P/E)表示给定股票的价格很高,随时可能下跌。在这种情况下,可以说股票超买了。低市盈率(P/E)表明对公司的业绩和未来缺乏信心。每股收益是指公司持有的每股股票的收益。它是衡量公司盈利能力的指标。通常优选较高的EPS。
3.4.1 Kalman filter
下图描述了该模型在考虑市场情绪前后的HDFC银行数据集预测。我们可以看到,该模型在后一种情况下表现得更好。如图3所示,仅考虑价格变动,我们的准确率仅为88%。但如图4所示,考虑市场情绪后,我们的准确率为91.75%。准确率大大提高。

图3 不考虑市场情绪的HDFC预测
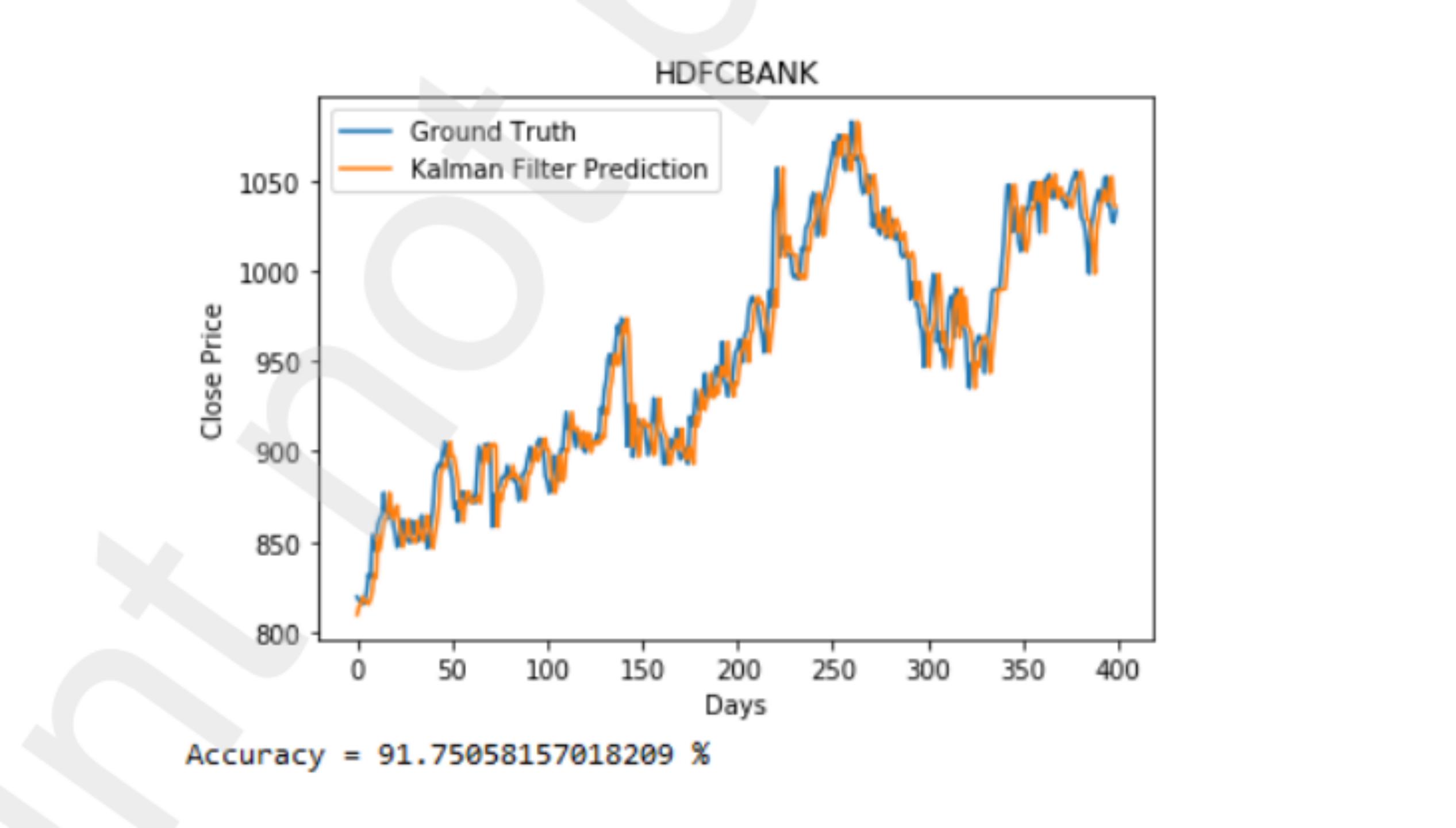
图4 考虑市场情绪的HDFC预测
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表4中。
表4 不同数据集的Kalman filter模型准确性

从上述结果中我们可以看出,该模型对NSE的各种数据集的表现是一致的,并且可以依赖该模型做出更好的预测,但对于NYSE,准确率并不一致且不高。
3.4.2 XGBoost
XGBoost模型是为国家证券交易所的HDFC银行数据集和纽约证券交易所的JPMorgan数据集开发的。这些模型是在有市场情绪和没有市场情绪的情况下训练的。不同于Kalman Filters在加入市场情绪后会产生准确率和误差率的显著变化,XGBoost中的准确率和误差率保持不变。因此,在进一步的训练中考虑了市场情绪。在为数据建立模型后,JPMorgan
和HDFC银行的测试数据的准确率分别为91%和88%。

图5 考虑市场情绪的HDFC数据集的准确性

图6 考虑市场情绪的JPM数据集的准确性
图5和图6分别显示了测试HDFC Bank和JPMorgan and Chase数据集时获得的准确性和误差。

图7 训练HDFC数据集时增强回归树的权重

图8 训练JPM数据集时增强回归树的权重
图7和图8显示了在训练模型时获得的增强回归树的权重,然后用于进一步预测训练集。
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表5中。
表5 XGBoost模型在不同数据集上的准确性

3.4.3 Hybrid模型
两个不同公司股票的模型结果,如下所示。
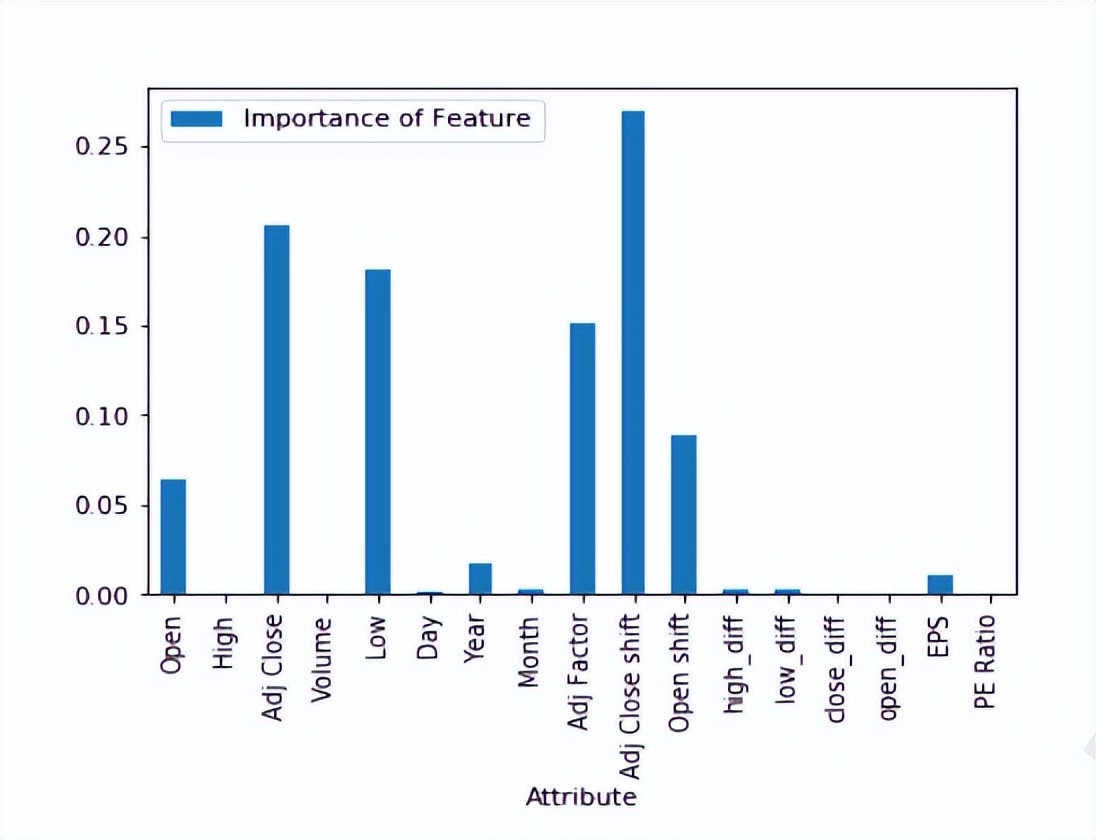
图9 XGBoost为HDFC数据集发现的功能重要性

图10 XGBoost为JPM数据集找到的功能重要性
从上面通过实现XGBoost算法获得的图9和图10中,我们可以找到预测时在增强回归树中起最重要作用的特征。我们只考虑上述步骤中的前5个特征,并将这些特征提供给Kalman Filter模型,以进行最终的股票价值预测。

图11 Hybrid模型对HDFC数据集的预测

图12 Hybrid模型对JPM数据集的预测
该模型在不同的数据集上表现一致。图11和图12显示,对于两个数据集,该模型的准确度优于其他两个单独模型所获得的准确度。
该模型还针对18个可用数据集中的其余数据集进行了测试,这些数据集总结在下表6中。
表6 不同数据集的混合模型准确度
4. 结论
股票市场预测分析是在20个样本上进行的,其中10个属于国家证券交易所(NSE),另外10个属于纽约证券交易所(NYSE)。平均而言,10年期间的股票价值由每个样本2300行组成。所考虑的时间区间为2006年 - 2016年和2010年 - 2020年。XGBoost模型与用于分析的20个样本是一致。XGBoost模型对NSE数据集的平均准确率为88.66,对NYSE数据集的平均准确率为90.11。尽管Kalman Filter统计模型产生了令人印象深刻的结果,但模型的准确性并不一致。Kalman Filter模型对NSE数据集的平均准确率为89.09,对NYSE数据集的平均准确率为64.96。混合模型似乎可以很准确地预测脚本的未来趋势,但它不能对所有样本都这样做。Hybrid模型对NSE数据集的平均准确率为76.79,对NYSE数据集的平均准确率为70.91。将每个季度的市场情绪添加到所有样本中,似乎可以提高三个模型的准确性。当数据集由更高价值的股票数据组成时,混合模型似乎优于其他两个模型。
5. 未来
论文中描述的三个模型都给出了良好的准确度和一致的结果。但Hybrid模型在股票价值的未来预测方面是最好的,它预测了市场的高点和低点,并提高了效率。作为项目的未来工作,我们可以考虑一组样本来进行样本选择。然后,我们可以在这些样本上执行投资组合管理,其中模型返回所需的投资、可接受的风险和手头的投资金额。
6.参考文献:
