最近做的一个项目,是使用Python来编写的,其中有一个需求是客户输入的金钱,是数值类型的,经过处理变成中文形式的,也就是输入123元,要变成一百二十三元,这样经过我们的智能语音机器人的读取,才是人类可读并接受的形式。
首先要知道人类读取金额的习惯:
1、1-9,就直接返回中文的一到九了,或者是繁体的
2、10-19,读成十几返回,不要读成一十几
3、20-99,要读成几十几返回
4、个位数什么都不加,十位数要加十,百位数要加百,千位数要加千
5、四位一组,超过四位要后加‘万’,超过八位后加‘亿’,由于项目中业务原因,只需支持到千亿就行,也就是12位数的金额(怕是没有这么高位的)
6、金额数值中有0或者多个0的,要根据情况来读取,0后面还有大于0的数,就在转换成中文时加‘零’,否则什么都不加,如101读成一百零一,100读成一百
好了,上代码吧:
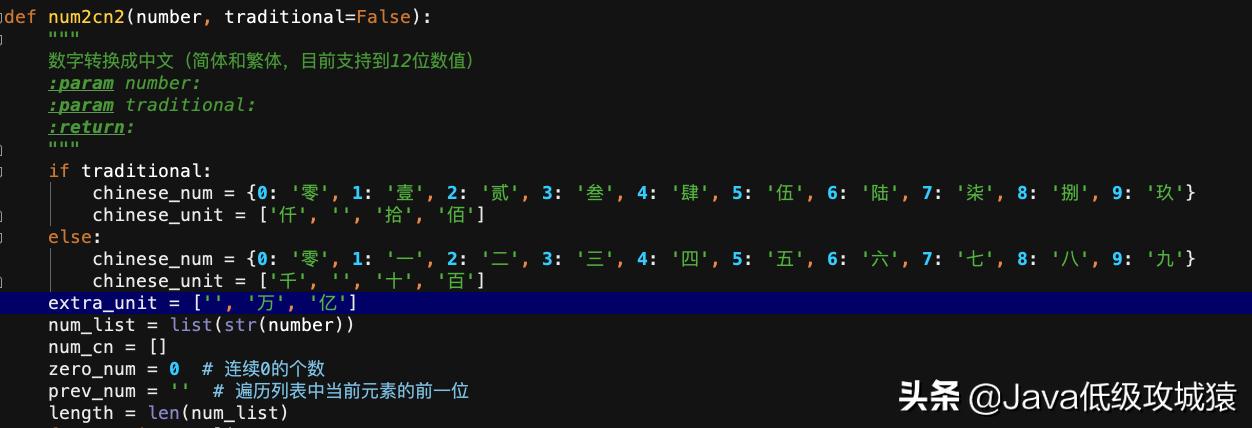
def num2cn2(number, traditional=False):
"""
数字转换成中文(简体和繁体,目前支持到12位数值)
:param number:
:param traditional:
:return:
"""
if traditional:
chinese_num = {0: '零', 1: '壹', 2: '贰', 3: '叁', 4: '肆', 5: '伍', 6: '陆', 7: '柒', 8: '捌', 9: '玖'}
chinese_unit = ['仟', '', '拾', '佰']
else:
chinese_num = {0: '零', 1: '一', 2: '二', 3: '三', 4: '四', 5: '五', 6: '六', 7: '七', 8: '八', 9: '九'}
chinese_unit = ['千', '', '十', '百']
extra_unit = ['', '万', '亿']
num_list = list(str(number))
num_cn = []
zero_num = 0 # 连续0的个数
prev_num = '' # 遍历列表中当前元素的前一位
length = len(num_list)
for num in num_list:
tmp = num
if num == '0': # 如果num为0,记录连续0的数量
zero_num += 1
num = ''
else:
zero = ''
if zero_num > 0:
zero = '零'
zero_num = 0
# 处理前一位数字为0,后一位为1,并且在十位数上的数值读法
if prev_num in ('0', '') and num == '1' and chinese_unit[length % 4] in ('十', '拾'):
num = zero + chinese_unit[length % 4]
else:
num = zero + chinese_num.get(int(num)) + chinese_unit[length % 4]
if length % 4 == 1: # 每隔4位加'万'、'亿'拼接
if num == '零':
num = extra_unit[length // 4]
else:
num += extra_unit[length // 4]
length -= 1
num_cn.append(num)
prev_num = tmp
num_cn = ''.join(num_cn)
return num_cn
代码中的逻辑,就是按照人类可读的形式来编写的,由于python中的代码编写风格是按照四个空格为一位的缩进,下面的截图可以看的更清楚一些:

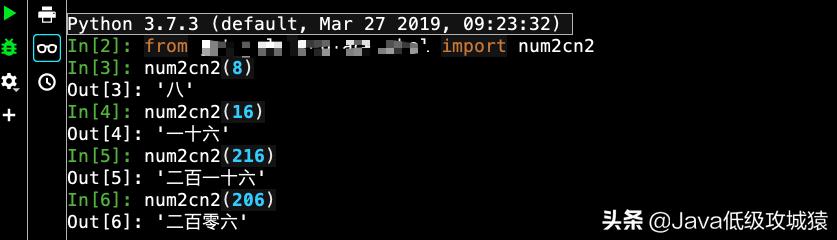
在Python Console中来测试一下:

你觉得生活中我们正常读取金钱的读法是什么样呢?