欢迎回到我们的神经网络系列!在今天的文章中,我们将讨论如何为神经网络预处理股票数据。你可能想知道,为什么我们需要处理数据?我们不能直接把数据扔给神经网络吗?如果你有这些疑问,那么你已经走在了学习的正确道路上。带上你的数据挖掘工具,我们开始吧!

数据处理
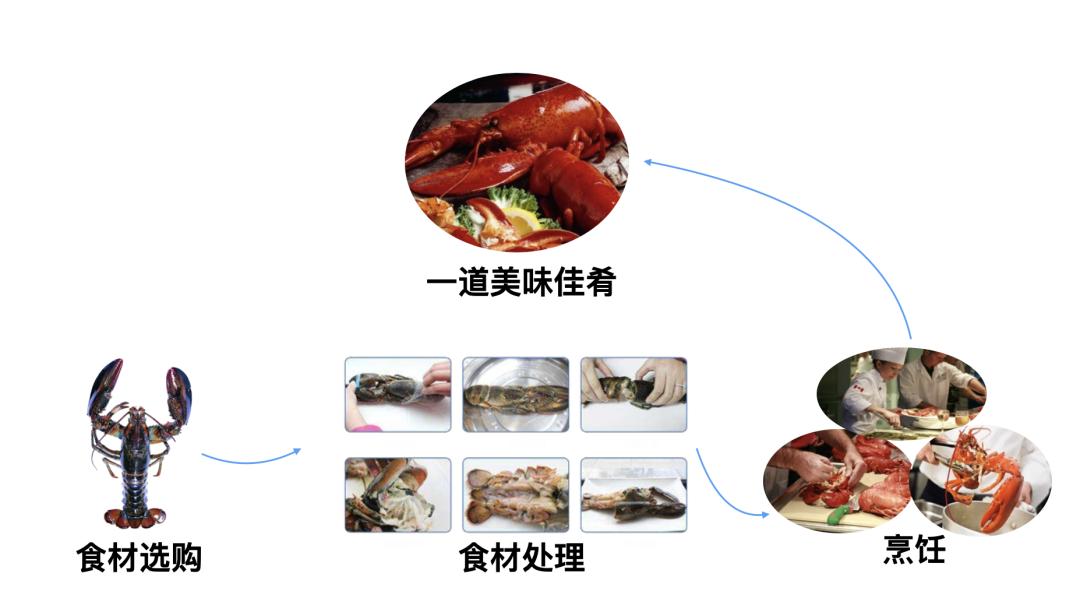
首先,我们需要理解为什么需要数据预处理。你可以把神经网络想象成一个烹饪高手,而数据就是他要烹饪的食材。如果食材是新鲜的、切好的、准备妥当的,那么烹饪的过程就会非常顺利,最终的菜肴也会非常美味。但是,如果食材是生的、未切的、或者是有质量问题的,那么烹饪的过程就会非常困难,最终的菜肴可能也会不尽如人意。同样,如果我们为神经网络准备好正确、清洁、格式一致的数据,那么神经网络的训练过程就会更加顺利,预测结果也会更加准确。
数据处理
股票数据预处理通常包括几个步骤:数据清洗、缺失值处理、数据规范化和数据分割。现在,我们将分别介绍这几个步骤。
数据清洗是数据预处理的第一步。在这一步,我们需要去除无关的数据,比如无关的列或者无关的行。例如,如果我们的任务是预测股票的收盘价,那么我们可能不需要关于股票交易量的数据。此外,我们还需要检查数据中是否存在错误的值,比如非数字的值或者不可能的值,并进行修正。
数据清洗
缺失值处理是数据预处理的第二步。在这一步,我们需要处理数据中的缺失值。缺失值是一个棘手的问题,因为我们不能简单地忽略它们,但是也不能随便填补它们。一种常见的处理方法是通过插值或者预测来填补缺失值。另一种方法是通过删除含有缺失值的行来处理,但是这种方法可能会导致数据量的减少。

缺失值处理
数据规范化是数据预处理的第三步。在这一步,我们需要将数据转换为神经网络可以更好地理解的形式。一种常见的规范化方法是将数据缩放到0到1之间,或者-1到1之间。这样做的好处是可以避免神经网络对某些大值特别敏感,从而导致训练效果不佳。
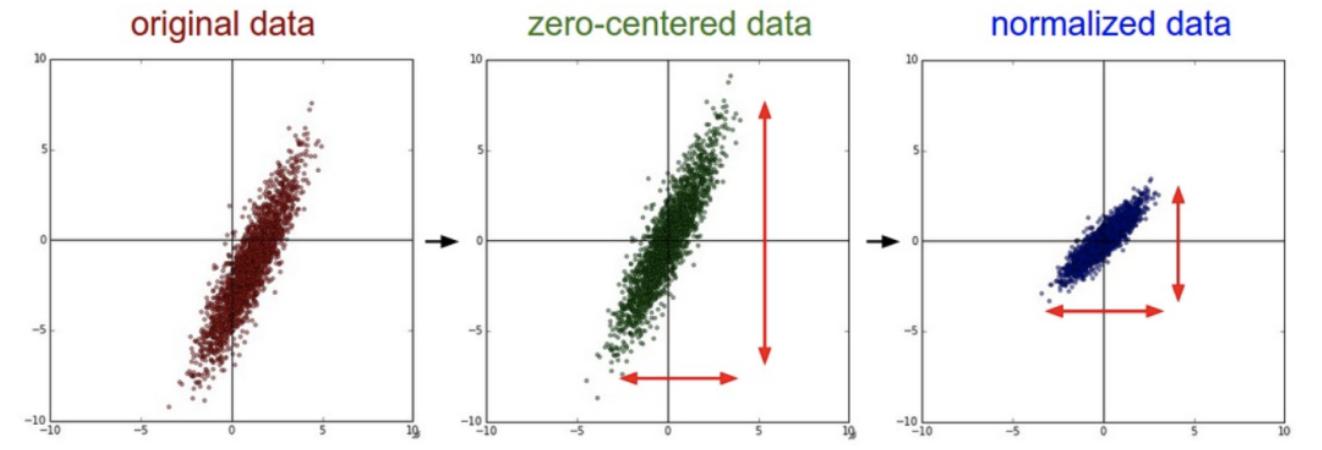
数据规范化
数据分割是数据预处理的最后一步。在这一步,我们需要将数据分割为训练集、验证集和测试集。训练集用于训练神经网络,验证集用于调整神经网络的参数,测试集用于评估神经网络的性能。通常,我们会将大部分数据用于训练,剩余的数据一半用于验证,一半用于测试。
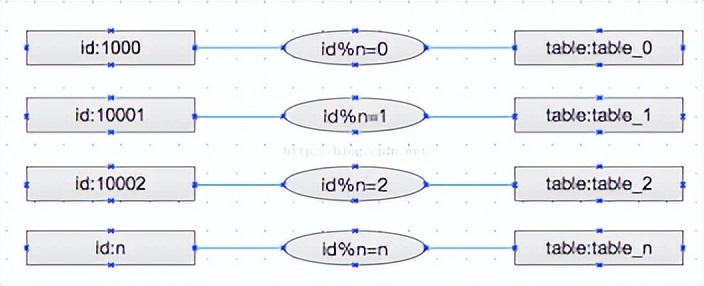
数据分割
至此,我们已经介绍了股票数据预处理的四个步骤:数据清洗、缺失值处理、数据规范化和数据分割。虽然这些步骤可能看起来有些繁琐,但是它们对于神经网络的训练效果至关重要。记住,好的数据预处理就像是烹饪的准备工作,只有准备充分,才能烹饪出美味的菜肴。同样,只有数据预处理做得好,神经网络才能更好地学习和预测。在下一篇文章中,我们将开始构建我们的神经网络。敬请期待!