如果您准备接受数据工程职位面试,则 必须 了解数据库的所有主要概念。这不是点击诱饵。几个月前,我进行了几次数据工程访谈,所有访谈都涉及我在本文中提到的主题的问题。即使您没有准备面试,您仍然可能想检查一下这些概念并刷新一下。
此外,这将是没有用的升数据工程师Y,而是各种各样的专业工作与数据库中的数据:数据科学家,ML-工程师,软件开发等等。
我的名字叫Oleg,是我在GitHub上发布的开源“数据工程书”的作者。我将尝试尽可能简单地解释数据库的7个主要概念。这些概念是:
- 关系模型
- 数据归一化
- 主键和外键
- 指标
- 交易
- 复制
- 分片
让我们开始吧!
关系模型
关系模型是一种结构化和管理数据的方法。
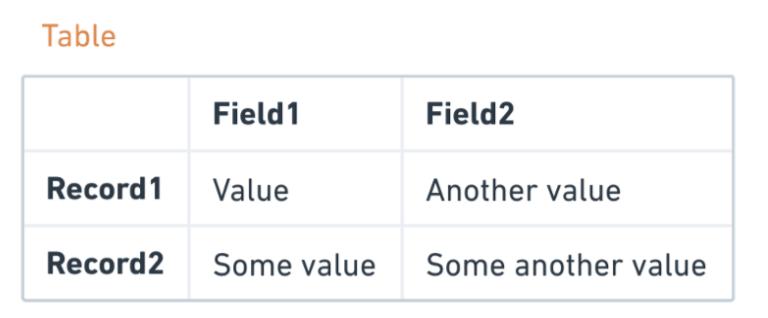
在此模型中,数据被组织到 表中。 每个表都有一个 架构 。这意味着它具有预定义的列表,因此只能将满足模式的数据写入表中。此外,每一列都有一种 数据类型 (数字,字符串,布尔值等)。表的列通常称为字段,行称为记录。
在最初的数据库理论中,表称为“ 关系” ,因此称为模型。不要将此定义与表之间的 关系 混淆,在表之间我们通常使用键来定义这种关系。我们将在本文后面讨论键。
最后,遵循此模型的数据库称为关系数据库。关系数据库使用 SQL (结构化查询语言)访问它们存储的数据。
数据归一化
规范化 是使您的数据适合于关系数据库的过程。
有时,标准化被称为 删除数据冗余 的 过程 。通常,此定义通常易于解释和理解。规范化有助于对抗数据冗余,提高数据完整性,简化数据结构,帮助发现错误。
规范化过程是通过应用两种方法完成的:
- 综合 (例如,创建以前不存在的新项目)或
- 分解 (通过拆分成较小的部分来改善现有数据结构)
考虑下面的例子。想象一下,您经营一家电子商店,并在Excel电子表格中记下了每笔采购。它可能看起来像这样:
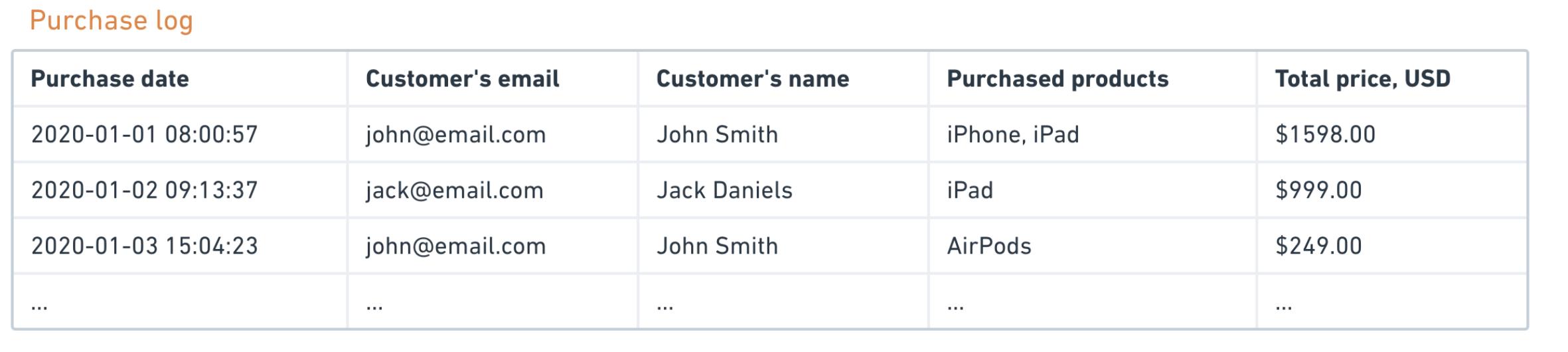
尽管这样的数据结构在Excel中是可以接受的,但是如果您以1对1的方式将其插入数据库中,则可能会导致一些问题:
- 数据是多余的。例如,您是否真的需要在这里输入客户的姓名?也许电子邮件就足够了,名称可以存储在单独的表中。
- 查询此类数据将很困难。例如,您能否说说您买了几部iPhone,以及以什么价格出售?不可以,因为“总价”已经是合计价值,并且您不知道购物车中每件商品的成本。
- 数据更新和删除非常困难。让我们考虑包含两个项目的第一笔订单,并假设客户已决定退回一个项目。在此类表格中反映此更改的最佳方法是什么?
数据规范化将使此类购买日志变成如下所示:

在这种结构中,添加,更新和删除条目将变得更加容易。而且,由于我们将重复的数据替换为标识符并将它们存储在单独的表中,因此它将减少硬盘驱动器上的空间。
这样的标准化不是唯一的。有一些规则描述规范化级别。数据有6种 普通形式 ,每种 形式 都有其自己的一组规则和对数据结构的限制。
主键和外键
主键 是表中记录的唯一标识符。
当我们想与另一个表建立关系时,需要这样的键。当table的列包含对另一个表的引用时,该列将成为 外键 。
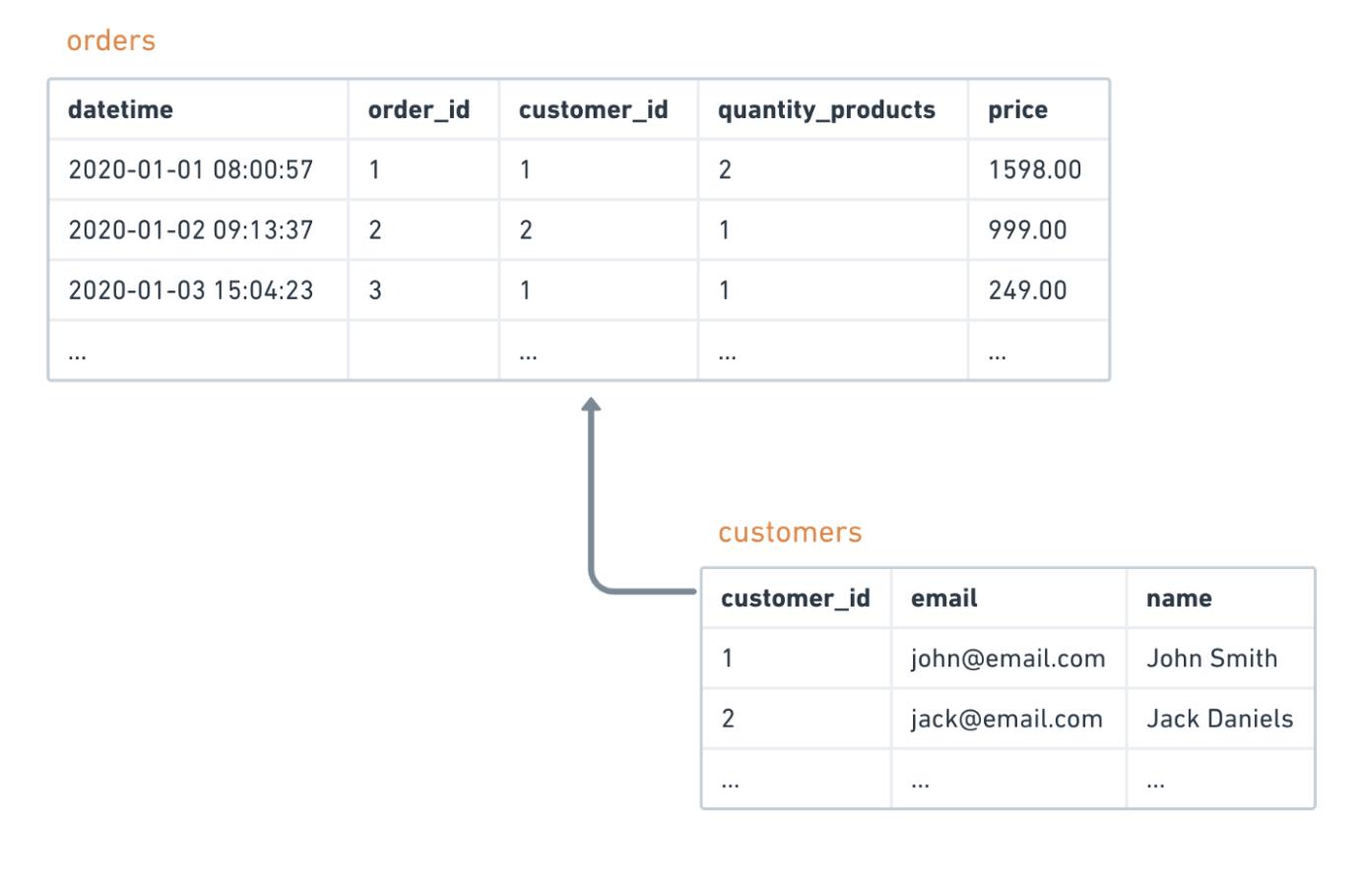
例如,如果我们有一个 customers 表,该表的列名为 customer_id ,则它是该表的 主键 。与此同时,如果表中 orders 有 CUSTOMER_ID 列引用在这一领域的 customers 表,它成为一个 外键 的 orders 表。
索引
索引 是数据库内部的一个特殊对象,有助于在数据内部进行快速搜索。
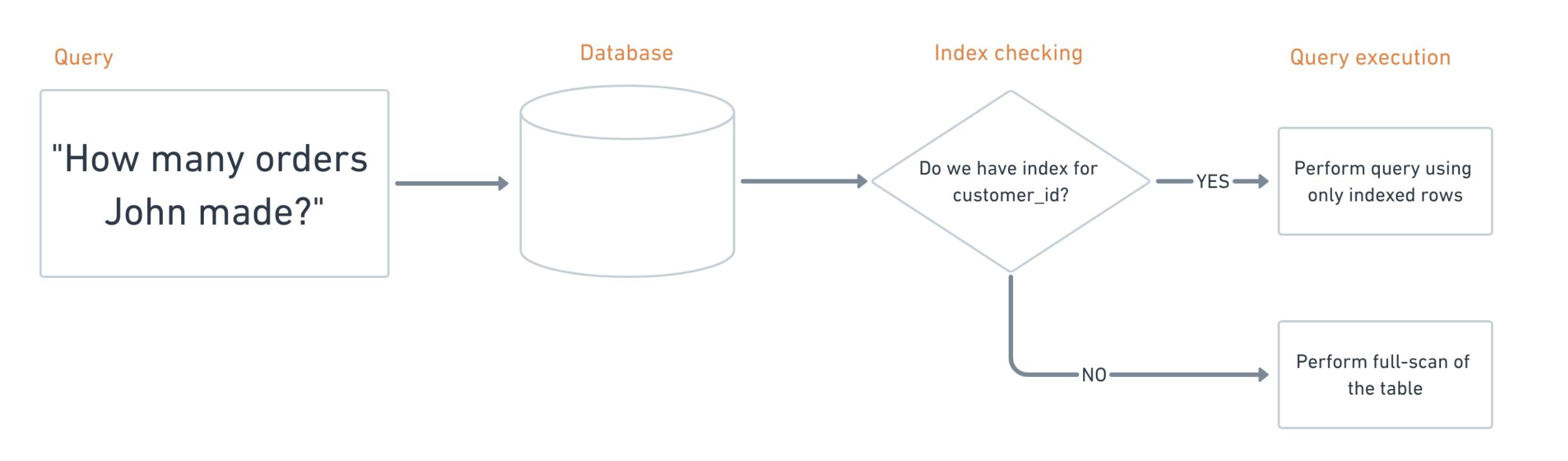
假设您有一个包含 数百万 条记录的大表,并且需要查找该表的满足特定条件的子集,例如,特定客户有多少订单。通常,记录 不带order 插入到表中。因此,要执行搜索,数据库将需要进行 全面扫描 ,这意味着它将从头到尾逐行进行直到找到所需的行。
为了加快该过程,我们可以为搜索到的列 建立索引 。这样的索引将存储表中列的每个值的 位置 。因此,当使用索引列执行搜索时,数据库将首先搜索索引以查找数据的位置,然后才使用这些位置提取所需的行。
交易
术语“ 交易” 通常是指 不可分割的工作单元 。当我们想要在数据库中执行多个操作并且想要确保所有操作一次成功还是失败时,它是必需的。
交易的经典示例是 银行转账 ,当您需要将资金从一个帐户转移到另一个帐户时。基本上,涉及三个步骤:
- 检查帐户1是否存在所请求的金额
- 从帐户#1中减去所需的金额
- 将所需金额添加到帐户2
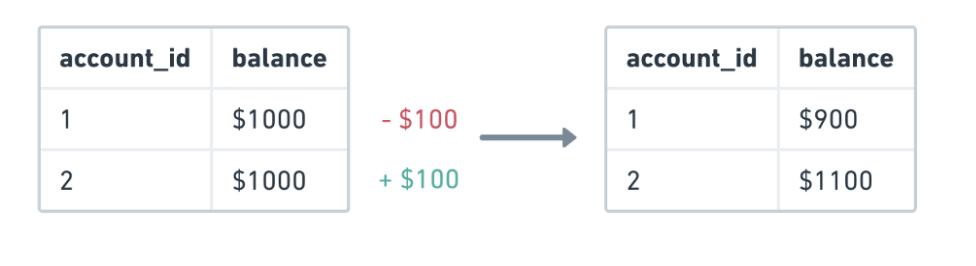
如果银行应用程序开始了转帐过程,则 必须保证 这三个操作 全部成功 或全部 失败 。
为了确保数据库中可以进行事务处理,数据库应满足一组要求,即 ACID 缩写。
ACID 代表原子性,一致性,隔离性,耐久性。
原子性 是保证操作(工作单元)将被完全执行的保证。换句话说,必须成功执行或完全不执行对数据的所有更改。
一致性 是指在事务处理之前和之后,数据应处于一致状态。该规则的执行完全由业务逻辑承担。回想一下银行转帐的示例:如果我们从帐户#1减去$ 100,则无法向帐户#2添加$ 200,因为这会导致不一致。
隔离 意味着并行事务不应影响彼此的结果。对于数据库而言,此要求非常昂贵,因此在某些数据库中存在不同级别的隔离。
最后, 持久性 保证了操作结果可以持久保存在数据库中,并且不会丢失。例如,如果用户收到事务已完成的响应,则可以确保不会因为系统故障或其他中断而放弃所做的更改。
副本
复制 是将数据库同步到其他节点或服务器。换句话说,复制是 将 我们的数据从一个来源 复制 到另一个来源的 过程 。
如果我们的数据主副本会发生问题,那么复制可以使我们免受 数据丢失的 困扰。例如,如果我们的数据库正在停机(例如,缺少网络或中断),则我们的应用程序将无法运行,因为它没有任何数据可显示给用户。
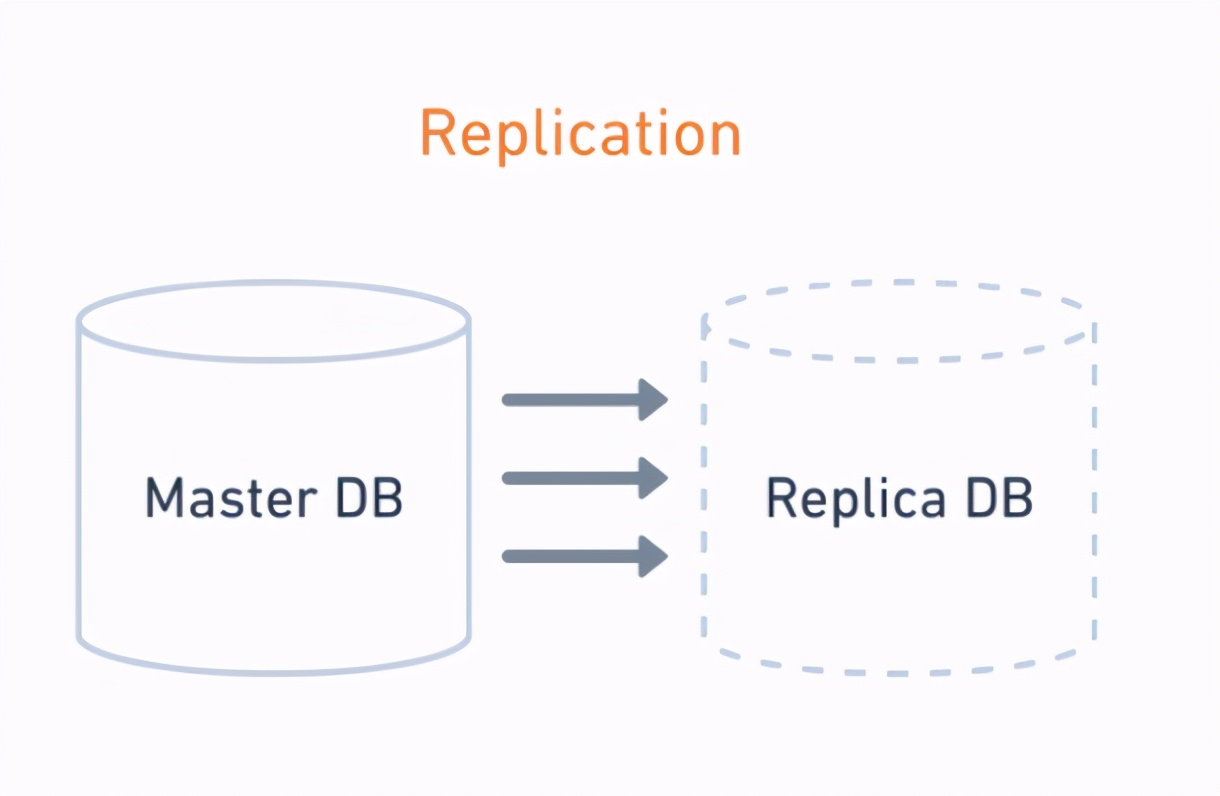
复制给我们带来了什么:
- 副本是我们数据库的 完整副本
- 主副本中的更改 立即应用于 副本
- 如果主数据库关闭,则所有传入请求都可以 重定向 到副本
- 所有添加/更新/删除请求都路由到主数据库,但所有读取都复制到副本数据库的常见情况,为这种体系结构提供了很好的 负载平衡
副本可以在两种模式下工作: 同步 和 异步 。
顾名思义, 同步模式 是指副本应用与主实例相同的更改,并且仅在该用户从数据库获得响应之后。同步模式具有 一致的数据 ,但响应时间通常 较慢 。
在 异步模式下 ,主服务器不等待副本的响应,而是立即将操作结果发送回用户。异步模式可能会有一些数据延迟( 不一致 ),但是响应 速度 非常 快 。
分片
分片 是一种通过某些键拆分表中数据并将不同部分发送到不同节点的方法。
分片是 水平缩放 。我们将一个表分成几个 逻辑分区 。每个分区的架构都是相同的(因为我们按行而不是按列划分数据)。每个分区代表表的 逻辑 分片。
在不同节点之间分布后,它们成为 物理碎片 。数据库的一个节点可以容纳多个逻辑分片。
如何实现分片?共有三种常见方法:
- 在 应用程序级别上 。基本上,知道所需数据的存储位置是您应用程序的工作。
- 在 数据库级别上 。数据库本身决定将数据放置在哪个节点上。当然,它不是自动完成的,因为数据库需要预先提供正确的配置。
- 使用 外部协调服务 。在这里,您将分片外包给第三方服务,该服务决定数据的存储位置。您的应用程序使用此服务而不是数据库。
有很多方法可以实现分片,但是在所有情况下,您都需要提供 分发密钥 。该键决定您的数据如何在整个群集中分布。而且,没有关于 如何选择正确的分发密钥的 灵丹妙药。分发密钥的两个最常见的选择是 基于哈希的 密钥或 基于值的 密钥。
概括
希望您喜欢这篇文章,并在此过程中学到一些新东西。
面试中祝你好运!
(本文由闻数起舞翻译自文章《7 concepts of databases every data engineer should know》,转载请注明出处,原文链接:https://oleg-agapov.medium.com/7-concepts-of-databases-every-data-engineer-should-know-5ea4a357c149)