这个故事是我的数据科学系列的一部分。
在这个故事中,我想向您展示如何使用 PostgreSQL 快速启动和运行 Rust 进行纯数据分析或机器学习建模。
如果您的系统上安装了 docker,则可以通过运行以下命令快速启动空数据库:
docker run --name ml_db -e POSTGRES_DB=ml_db \
-e POSTGRES_USER=ml_db -e POSTGRES_PASSWORD=ml_db -d -p 5432:5432 postgres
运行之后,接下来我们需要一些数据。 数据科学/分析中的一种常见方法是以 csv 文件的形式移交数据。
作为示例,让我们考虑此处的以下股票数据。
*载下**的存档包含一组名称格式为 YYYY_Global_Markets_Data 的文件。 我们可以使用以下 Rust 代码将所有数据写入一个名为 data.csv 的通用文件中:
use std::{
fs::File,
io::{BufRead, BufReader, BufWriter, Write},
};
fn main() -> std::io::Result<()> {
let mut data_file_writer = BufWriter::new(File::create("data/data.csv")?);
let header = "Ticker,Date,Open,High,Low,Close,Adj Close,Volume";
data_file_writer.write_all(header.as_bytes())?;
data_file_writer.write(b"\n")?;
for year in 2008..2024 {
let file_name = format!("data/{}_Global_Markets_Data.csv", year);
let reader = BufReader::new(File::open(file_name)?);
let mut line_iter = reader.lines().skip(1);
while let Some(Ok(line)) = line_iter.next() {
data_file_writer.write_all(line.as_bytes())?;
data_file_writer.write(b"\n")?;
}
data_file_writer.flush()?;
}
Ok(())
}
接下来我们在 PostgreSQL 上创建一个表来保存数据:
CREATE TABLE stock_prices(
ticker VARCHAR(30),
date DATE,
open REAL,
high REAL,
low REAL,
close REAL,
"Adj Close" REAL,
volume REAL
);
然后我们将data.csv复制到安装docker的位置。 如果您使用的是 Linux,那么您可能已经做好了准备。 如果您使用的是 Windows,则需要将该文件复制到系统上安装的 Linux WSL 中。
此外,我们需要将文件复制到运行数据库的 docker 容器中。 我们上面的容器被命名为 ml_db ,复制可以通过(参见文档)来完成
docker cp ./data.csv ml_db:/data.csv
有了这个,我们就可以运行以下 PostgreSQL 脚本来非常有效地将这些数据加载到表中(请参阅文档):
COPY stock_prices FROM '/data.csv' (FORMAT csv, HEADER true);
这将在文件中插入 44,900 条记录,我们已准备好使用它们。
为了开始在 Rust 的帮助下处理数据,让我们添加 crate sqlx 作为依赖项(在 Cargo.toml 中):
dotenv = "0.15.0"
futures = "0.3.28"
sqlx = { version = "0.6.3", features = [ "runtime-tokio-rustls", "postgres", "macros", "migrate" ] }
tokio = { version = "1", features = ["full"] }
sqlx 是一个非常高性能的数据库查询框架。 它默认使用异步功能,这就是为什么我还添加了 tokio 和 futures 作为依赖项。
处理数据库意味着必须设置一些描述连接和凭据的全局变量。 为了在生产中部署时保持足够的灵活性,一个不错的选择是使用 dotenv。 因此,我们将这些详细信息添加到文件 .env 中,如下所示:
DB_NAME=ml_db
DB_USER=ml_db
DB_PWD=ml_db
DB_HOST=localhost
DB_PORT=5432
DB_CONNECTIONS=5
DB_URL=postgres://${DB_USER}:${DB_PWD}@${DB_HOST}:${DB_PORT}/${DB_NAME}
现在我们可以使用以下代码从数据库中获取所有可用的股票代码名称:
use dotenv::dotenv;
use futures::stream::TryStreamExt;
use sqlx::{postgres::PgPoolOptions, Result, Row};
use std::env;
mod data_utils;
const DB_CONNECTIONS: &str = "DB_CONNECTIONS";
const DB_URL: &str = "DB_URL";
#[tokio::main]
async fn main() -> Result<()> {
dotenv().ok(); // setting up the env variables
// creating a connection pool
let db_connections = env::var(DB_CONNECTIONS).unwrap();
let pool = PgPoolOptions::new()
.max_connections(db_connections.parse().unwrap())
.connect(&env::var(DB_URL).unwrap())
.await?;
// running a query and obtaining a Stream to the result set
let mut rows =
sqlx::query(
"SELECT sp.ticker FROM stock_prices sp GROUP BY sp.ticker")
.fetch(&pool);
// consuming the Stream
while let Some(ticker) = rows.try_next().await? {
println!("{:?}", ticker.try_get::<String, usize>(0)?);
}
Ok(())
}
这打印出:
"^NSEI"
"000001.SS"
"^N225"
"^NYA"
"GC=F"
"^GSPC"
"^FTSE"
"^IXIC"
"CL=F"
"^DJI"
"^BSESN"
"^N100"
在机器学习中,通常需要对数据进行标准化,即缩小到区间 [-1, 1]。
为此,让我们添加一个新列:
ALTER TABLE stock_prices ADD COLUMN "close_normalized" REAL;
但是,我们不直接在数据库上运行它,而是考虑 sqlx 的另一个非常有用的功能,即迁移。 为此,我们将以下文件夹结构添加到项目的根目录中:db/migrations
在此文件夹中,我们放置一个名为 1_some_name.sql 的文件,其中包含以下内容:
ALTER TABLE stock_prices ADD COLUMN IF NOT EXISTS "close_normalized" REAL;
ALTER TABLE stock_prices ADD COLUMN IF NOT EXISTS "open_normalized" REAL;
ALTER TABLE stock_prices ADD COLUMN IF NOT EXISTS "high_normalized" REAL;
ALTER TABLE stock_prices ADD COLUMN IF NOT EXISTS "low_normalized" REAL;
然后我们将以下代码片段添加到 main 函数中,使其变为:
async fn main() -> Result<()> {
dotenv().ok();
let pool = create_db_pool().await?;
sqlx::migrate!("db/migrations").run(&pool).await?;
...
}
如果我们下次启动应用程序,sqlx 将获取上述迁移文件并针对数据库运行它。 同时,它将创建一个新表 _sqlx_migrations 来跟踪已应用的迁移。
在当今的数据库框架中,像这样的东西,尤其是这种模式已经成为标准。 另外值得一提的是,sqlx 提供了一个 CLI,允许“手动”运行迁移。
最后,让我们针对执行规范化的数据库运行更新脚本:
let mut rows =
sqlx::query(
"SELECT sp.ticker FROM stock_prices sp GROUP BY sp.ticker"
).fetch(&pool);
while let Some(ticker) = rows.try_next().await? {
let ticker_name = ticker.try_get::<String, usize>(0)?;
let mut txn = pool.begin().await?; // open a transaction
sqlx::query(r#"
with "ranges" as (
select max(sp."close") - min(sp."close") as "range",
min(sp."close") as min_close
from stock_prices sp
where sp.ticker = $1
)
update stock_prices as sp set ("close_normalized") =
(select (sp."close" - r.min_close) / r."range" from ranges r)
where sp.ticker = $1"#)
.bind(ticker_name)
*ex.e**cute(&mut txn).await?; // execute on the transaction
txn.commit().await?; // commit the transaction
}
正如您所看到的,sqlx 完全支持事务管理。
顺便说一句,在非教育环境下,您最好也将类似上面的查询放入迁移文件中。 这可能是 2_normalize_data.sql,其内容为:
create index
if not exists stock_prices_ticker_idx on stock_prices (ticker);
with value_ranges as (
select
max(sp."close") - min(sp."close") as close_range,
min(sp."close") as min_close,
max(sp."open") - min(sp."open") as open_range,
min(sp."open") as min_open,
max(sp."high") - min(sp."high") as high_range,
min(sp."high") as min_high,
max(sp."low") - min(sp."low") as low_range,
min(sp."low") as min_low,
sp.ticker as ticker
from stock_prices sp
group by sp.ticker
)
update stock_prices as sp
set
close_normalized = (sp."close" - vr.min_close) / vr.close_range,
open_normalized = (sp."open" - vr.min_open) / vr.open_range,
low_normalized = (sp."low" - vr.min_low) / vr.low_range,
high_normalized = (sp."high" - vr.min_high) / vr.high_range
from value_ranges vr
where sp.ticker = vr.ticker;
drop index stock_prices_ticker_idx;
这个查询的解释计划实际上告诉我们索引不是必需的:
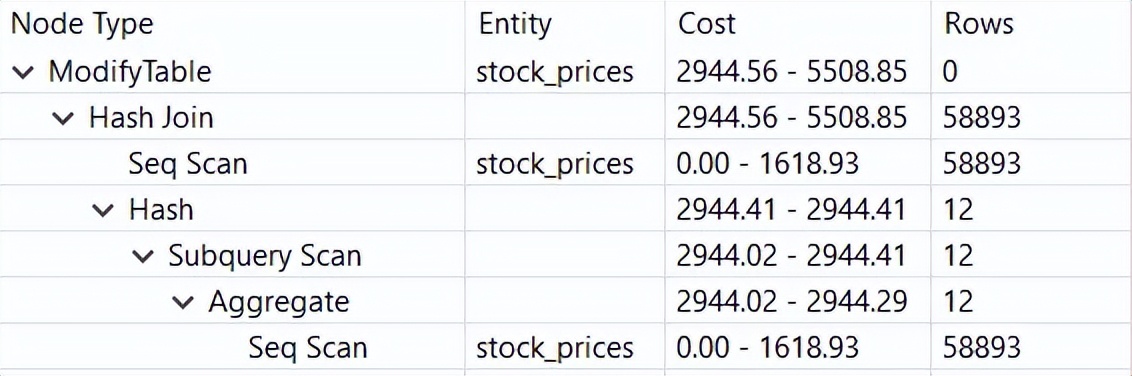
最后,让我们考虑一种创建数据图的方法。 尽管有可能,Rust 并不是一种针对此类前端任务的语言。 在这里,我建议走最小摩擦的道路,只使用这个方向上最先进的工具,即Python:
我们将以下依赖项添加到我们的项目中,并添加一个库(Cargo.toml):
...
[lib]
name = "information_theory"
crate-type = ["cdylib"]
[dependencies]
...
pyo3 = { version = "0.19", features = ["extension-module"] }
pyo3-asyncio = { version = "0.19", features = ["attributes", "tokio-runtime"] }
pyo3、pyo3-asyncio 是 Python 的 Rust 绑定,可以创建包含可调用 Rust 函数的 Python 模块。
此外,我们通过命令在本地设置一个虚拟环境
python -m venv .venv
并通过 pip 安装 maturin:
pip install maturin
maturin 是一个 Python 包,它将 pyo3 生成的 Rust 二进制文件实际*绑捆**到 Python 包中。
我们的目标是公开 Rust 函数并使其可以从 Python 中调用。 这是通过 lib.rs 中的以下代码完成的:
use data_utils::fetch_ticker_data;
use db_connections::create_db_connection;
use dotenv::dotenv;
use pyo3::prelude::*;
mod constants;
mod data_utils;
mod db_connections;
// This makes a Rust function eligable for being part of a Python module:
#[pyfunction]
fn get_ticker_data(py: Python, ticker1: String, ticker2: String)
-> PyResult<&PyAny> {
pyo3_asyncio::tokio::future_into_py(py, async move {
dotenv().ok();
let mut connection = create_db_connection().await.unwrap();
let data = fetch_ticker_data(&mut connection, &ticker1, &ticker2)
.await
.unwrap();
Ok(data)
})
}
// This registers the function within the python module to be generated:
#[pymodule]
fn information_theory(_py: Python<'_>, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(get_ticker_data, m)?)?;
Ok(())
}
然后可以通过调用创建 Python 包并将其注册到 venv
maturin develop
要运行此程序,请确保本地 venv 已激活! 这将编译 Rust 代码,将二进制文件*绑捆**到 Python 包中,最后将其注册到 venv 中。
在展示如何从 Python 中调用此函数之前,让我们快速看一下 fetch_ticker_data 的实现,它检索两个股票代码的数据:
pub async fn fetch_ticker_data(
executer: impl PgExecutor<'_>,
ticker1: &str,
ticker2: &str,
) -> sqlx::Result<(Vec<f32>, Vec<f32>)> {
let rows = sqlx::query(
r#"
select
sp1.close_normalized,
sp2.close_normalized
from stock_prices sp1, stock_prices sp2
where sp1."date" = sp2."date"
and sp1.ticker = $1
and sp2.ticker = $2
order by sp1."date" asc
"#,
)
.bind(ticker1)
.bind(ticker2)
.fetch_all(executer)
.await?;
let (mut ticker_vec_1, mut ticker_vec_2) = (vec![], vec![]);
rows.iter().for_each(|row| {
ticker_vec_1.push(row.get::<f32, usize>(0));
ticker_vec_2.push(row.get::<f32, usize>(1));
});
Ok((ticker_vec_1, ticker_vec_2))
}
将以下索引添加到迁移脚本中
CREATE INDEX stock_prices_ticker_idx ON stock_prices (ticker);
使这个查询执行如下:
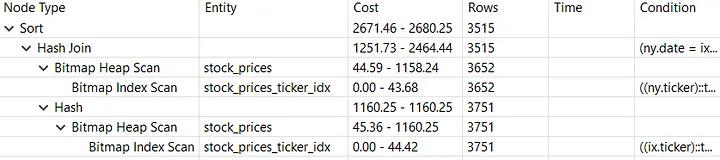
以下 Python 脚本导入我们的库并执行公开的 Rust 函数。 请注意,所有这些都需要是异步的,因为 Rust 端也是异步的,也就是说,两个事件循环需要在同一线程中同步。
import asyncio;
import information_theory as it;
import matplotlib.pyplot as plt
import numpy as np
async def main():
(ticker_1, ticker_2) = await it.get_ticker_data("^NSEI", "000001.SS")
time = np.arange(0, len(ticker_1)) * 100/len(ticker_1)
plt.scatter(ticker_1, ticker_2, c=time)
plt.show()
asyncio.run(main())
输出

请注意,所介绍的 pyo3 用法适用于纯粹的数据分析任务。 在生产系统中,从 Python 代码调用 Rust 函数并连接到数据库,在大多数情况下可能不是一个好主意。
结论:
我们在本文中介绍了很多内容,但这是有意为之。 我的目的是展示 Rust 基础设施与其他技术的匹配程度,并为数据科学提供有用的工具。
感谢您的阅读!