摘要
“股价预测非常困难,尤其是对未来的预测。”你们中的许多人一定听说过丹麦物理学家尼尔斯 · 玻尔的这句名言。股价预测是这篇博文的主题。在这篇文章中,我们将讨论流行的 ARIMA 预测模型,以预测股票的收益,并展示了一个逐步的过程 ARIMA 建模使用 R 规划。
什么是时间序列预测模型?
预测包括利用一个变量的历史数据点来预测它的值,或者也可以预测一个变量在给定另一个变量值变化的情况下的变化。预测方法主要分为定性预测和定量预测。时间序列预测属于定量预测的范畴,其中统计原理和概念应用于一个变量的给定历史数据,以预测同一变量的未来值。使用的一些时间序列预测技术包括:
- 自回归模型(AR)
- 移动平均线模型
- 季节回归模型
- 分布式滞后模型
- 什么是 ARIMA模型模型?
ARIMa 代表 ARIMA模型。ARIMA 也被称为 Box-Jenkins 方法。博克斯和詹金斯声称,非平稳数据可以通过差分的系列,Yt。Yt 的一般模型是这样写的,
Yt =ϕ1Yt−1 +ϕ2Yt−2…ϕpYt−p +ϵt + θ1ϵt−1+ θ2ϵt−2 +…θqϵt−q
当 Yt 为差分时间序列值时,φ 和 θ 为未知参数,ε 为零均值的独立同分布误差项。在这里,Yt 用它的过去值以及误差项的当前值和过去值来表示。
ARIMA 模型结合了三种基本方法:
- 自回归(AR):在自回归中,给定时间序列数据的值按其自身的滞后值进行回归,ARIMA 模型中的“ p”值表示滞后值。
- 差分(I-为综合):这涉及差分的时间序列数据,以消除趋势和转换一个非平稳的时间序列到一个平稳的。这由ARIMA模型中的“ d”值表示。如果d = 1,它查看两个时间序列条目之间的差异; 如果 d = 2,它查看在 d = 1时得到的差异的差异,等等。
- 移动平均(MA):ARIMA模型的移动平均性质由“ q”值表示,它是误差项的滞后值得个数。
这个模型被称为 Yt 的 ARIMA模型或 ARIMA (p,d,q)。我们将按照下面列举的步骤来构建我们的模型。
步骤1: 测试和确保平稳性
为了用 Box-Jenkins 方法建立一个时间序列模型,这个序列必须是固定的。平稳时间序列是指没有趋势的时间序列,其均值和方差随时间变化不变,这使得预测值变得容易。
平稳性测试:我们使用增强 Dickey-Fuller 单位根测试来测试平稳性。ADF 检验得到的 p 值必须小于0.05或5% ,时间序列才能保持不变。如果 p 值大于0.05或5% ,你得出结论,时间序列有一个单位根,这意味着它是一个非平稳过程。
差分:将非平稳过程转换为平稳过程,我们采用差分法。区分时间序列意味着找出时间序列数据的连续值之间的差异。差异值形成一个新的时间序列数据集,可以测试发现新的相关性或其他有趣的统计特性。
我们可以连续不止一次地应用差分法,产生“一阶差分”、“二阶差分”等。
在进行下一步之前,我们应用适当的差分顺序(d)使一个时间序列静止。
步骤2: 识别p和q
在这一步中,我们利用自相关函数(ACF)和偏自相关函数(PACF)来确定自回归(AR)和移动平均(MA)过程的合适顺序。有关 ACF 和 PACF 功能的解释,请参考我们的博客“从时间序列开始”。
AR模型的p阶辨识
对于 AR 模型,ACF 将呈指数衰减,PACF 将用于识别 AR 模型的阶数(p)。如果我们在 PACF 的滞后1处有一个显著的峰值,那么我们就有一个1阶的 AR 模型,即 AR (1)。如果我们在 PACF 的滞后1,2和3有显著的峰值,那么我们有一个3阶的 AR 模型,即 AR (3)。
MA模型的q阶辨识
对于 MA 模型,PACF 将呈指数衰减,ACF 图将用于识别 MA 过程的顺序。如果我们在 ACF 的滞后1处有一个显著的峰值,那么我们就有一个1级的 MA 模型,即 MA (1)。如果我们在 ACF 的滞后1、2和3有显著的峰值,那么我们有一个3级的 MA 模型,即 MA (3)。
步骤3: 估计和预测
一旦我们确定了参数(p,d,q) ,我们估计 ARIMA 模型在训练数据集上的精度,然后使用拟合模型来预测测试数据集的值使用预测函数。最后,我们交叉检查我们的预测值是否与实际值一致。
利用R规划建立 ARIMA 模型
现在,让我们遵循在 R 中构建 ARIMA 模型的步骤。有许多软件包可用于时间序列分析和预测。我们加载相关的 R 包的时间序列分析和拉股票数据从雅虎财务。
library(quantmod);library(tseries);
library(timeSeries);library(forecast);library(xts);
# Pull data from Yahoo finance
TECHM = getSymbols('TECHM.NS', from='2012-01-01', to='2015-01-01',auto.assign = FALSE)
TECHM = na.omit(TECHM)
# Select the relevant close price series
stock_prices = TECHM[,4]
在下一步,我们计算股票的对数收益,因为我们希望 ARIMA 模型来预测对数收益,而不是股票价格。我们还使用绘图函数绘制了日志返回序列。
# Compute the log returns for the stock
stock = diff(log(stock_prices),lag=1)
stock = stock[!is.na(stock)]
# Plot log returns
plot(stock,type='l', main='log returns plot')

接下来,我们对返回的序列数据调用 ADF 测试来检查平稳性。从 ADF 检验得到的0.01的 p 值告诉我们这个级数是平稳的。如果这个序列是非平稳的,我们首先要对返回序列进行差分,使它是平稳的。
# Conduct ADF test on log returns series
print(adf.test(stock))

在接下来的步骤中,我们修复了一个断点,该断点将用于将返回数据集分成两部分。
# Split the dataset in two parts - training and testing
breakpoint = floor(nrow(stock)*(2.9/3))
我们将原始回报系列截断为直到断点,并在此截断的系列中调用ACF和PACF功能。
# Apply the ACF and PACF functions
par(mfrow = c(1,1))
acf.stock = acf(stock[c(1:breakpoint),], main='ACF Plot', lag.max=100)
pacf.stock = pacf(stock[c(1:breakpoint),], main='PACF Plot', lag.max=100)


我们可以观察这些图,并得出自回旋(AR)订单和移动平均(MA)订单。
我们知道,对于AR模型,ACF将呈指数降低,PACF图将用于识别AR模型的顺序(P)。对于MA模型,PACF将呈指数降低,ACF图将用于识别MA模型的顺序(Q)。从这些图中,我们可以选择AR顺序= 2和MA顺序=2。因此,我们的Arima参数将为(2,0,2)。
我们的目标是从断点开始预测整个回报系列。我们将在R中使用for循环语句,在此循环中,我们将预测测试数据集中每个数据点的返回。
在下面给出的代码中,我们首先初始化一个系列,该系列将存储实际的退货和另一个系列以存储预测的返回。在for循环中,我们首先基于动态断点组成训练数据集和测试数据集。
我们在训练数据集上调用ARIMA功能,指定的顺序为(2、0、2)。我们使用此拟合模型通过使用forecast.arima函数来预测下一个数据点。该功能设置为99%的置信度。可以使用置信度级别的参数来增强模型。我们将使用该模型的预测点估计值。预测函数中的“ h”参数指示我们要预测的值数量,在这种情况下,第二天返回。
我们可以使用摘要函数来确认ARIMA模型的结果在可接受的范围内。在最后一部分中,我们分别附加了所有预测的返回和实际返回,分别为预测的返回系列和实际返回系列。
# Initialzing an xts object for Actual log returns
Actual_series = xts(0,as.Date("2014-11-25","%Y-%m-%d"))
# Initialzing a dataframe for the forecasted return series
forecasted_series = data.frame(Forecasted = numeric())
for (b in breakpoint:(nrow(stock)-1)) {
stock_train = stock[1:b, ]
stock_test = stock[(b+1):nrow(stock), ]
# Summary of the ARIMA model using the determined (p,d,q) parameters
fit = arima(stock_train, order = c(2, 0, 2),include.mean=FALSE)
summary(fit)
# plotting a acf plot of the residuals
acf(fit$residuals,main="Residuals plot")
# Forecasting the log returns
arima.forecast = forecast.Arima(fit, h = 1,level=99)
summary(arima.forecast)
# plotting the forecast
par(mfrow=c(1,1))
plot(arima.forecast, main = "ARIMA Forecast")
# Creating a series of forecasted returns for the forecasted period
forecasted_series = rbind(forecasted_series,arima.forecast$mean[1])
colnames(forecasted_series) = c("Forecasted")
# Creating a series of actual returns for the forecasted period
Actual_return = stock[(b+1),]
Actual_series = c(Actual_series,xts(Actual_return))
rm(Actual_return)
print(stock_prices[(b+1),])
print(stock_prices[(b+2),])
}
在我们进入代码的最后一部分之前,让我们检查来自测试数据集的示例数据点的 ARIMA 模型的结果。

根据得到的系数,返回方程可写为:
Yt = 0.6072 Y(t-1) - 0.8818 Y(t-2) - 0.5447ε(t-1) + 0.8972ε(t-2)
该系数给出了标准误差,这需要在可接受的范围内。Akaike信息标准(AIC)得分是Arima模型准确性的良好指标。降低AIC分数更好。我们还可以查看残差的ACF图;良好的Arima模型的自相关将低于阈值限制。预测点返回为-0.001326978,在输出的最后一行中给出。

让我们通过比较预测收益和实际收益来检验 ARIMA 模型的准确性。代码的最后一部分计算出准确的信息。
# Adjust the length of the Actual return series
Actual_series = Actual_series[-1]
# Create a time series object of the forecasted series
forecasted_series = xts(forecasted_series,index(Actual_series))
# Create a plot of the two return series - Actual versus Forecasted
plot(Actual_series,type='l',main='Actual Returns Vs Forecasted Returns')
lines(forecasted_series,lwd=1.5,col='red')
legend('bottomright',c("Actual","Forecasted"),lty=c(1,1),lwd=c(1.5,1.5),col=c('black','red'))
# Create a table for the accuracy of the forecast
comparsion = merge(Actual_series,forecasted_series)
comparsion$Accuracy = sign(comparsion$Actual_series)==sign(comparsion$Forecasted)
print(comparsion)
# Compute the accuracy percentage metric
Accuracy_percentage = sum(comparsion$Accuracy == 1)*100/length(comparsion$Accuracy)
print(Accuracy_percentage)

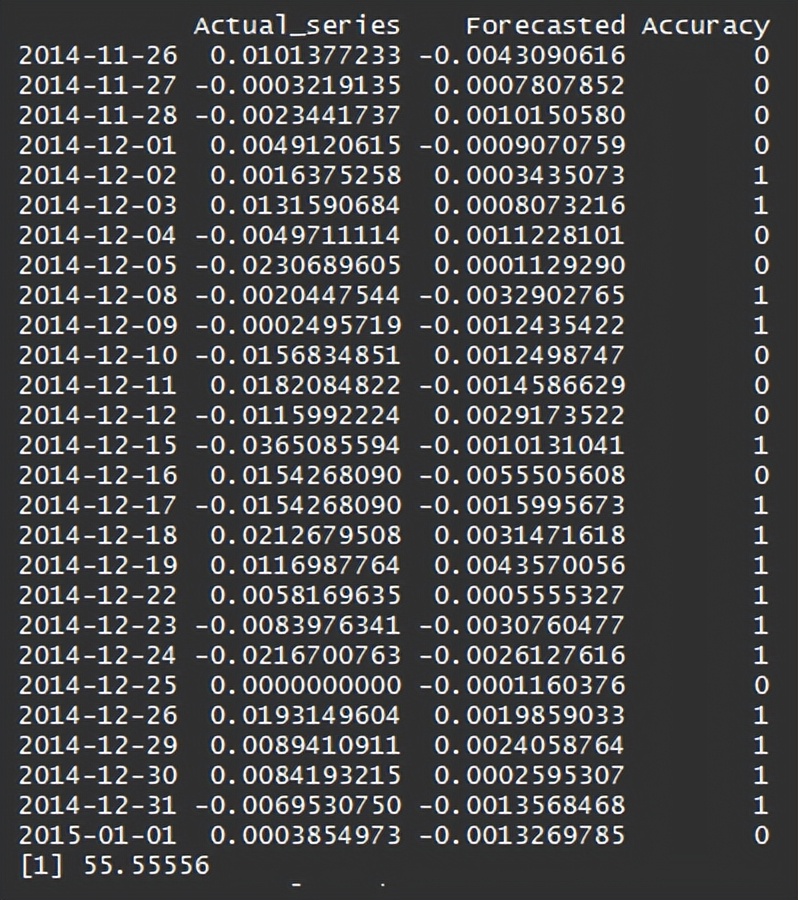
如果预测收益的符号等于实际收益的符号,我们就给它一个正的准确性分数。ARIMA 模型的准确率达到了55% 左右,这看起来是个不错的数字。人们可以尝试运行其他可能的组合(p,d,q)的模型,或者使用 auto.ARIMA 函数来选择最佳参数来运行 ARIMA 模型。
结论
最后,在这篇文章中,我们讨论了 ARIMA 模型,并应用它来预测股票价格收益率使用 R 编程语言。我们还将预测结果与实际回报进行了交叉核对。在我们即将发表的文章中,我们将介绍其他时间序列预测技术,并尝试使用 Python/R 编程语言。