本文主要运用了python的requests库爬取QQ音乐全站歌曲(已下架歌曲无法爬取*载下**,其余歌曲均可实现*载下**)。
环境为:python 3.7+pycharm
首先解释下代码中的几个函数,并且分别是什么作用;
- get_all_singer()主要是按字母A-Z以及特殊字符#来爬取全站歌手
- get_genre_singer()主要是遍历当前字母下歌手总页数
- get_singer_songs()主要是获取当前歌手下歌曲总数并获取*载下**歌曲所需的songmid
- download_song()主要是用来*载下**歌曲文件到本地
下面贴上代码:(第一次发代码,不规范处欢迎指正批评,但代码经本人测试ok,贴上即可使用,谢谢)
①、get_all_singer()
def get_all_singer():
# 获取字母A-Z和#的全站歌手
for key in range(1, 28):
# 获取当前字母分类歌手页数并转换为列表结构
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index": ' \
+ str(key)+',"sin":0,"cur_page":1}}}'
r = session.get(url)
total = r.json()['singerList']['data']['total']
page_num = math.ceil(total/80)
page_list = [x for x in range(page_num)]
get_genre_singer(key, page_list)
②、get_genre_singer()
def get_genre_singer(key, page_list):
# 遍历当前字母分类的总页数
for p in page_list:
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index":' \
+ str(key)+',"sin":' + str((p-1)*80)+',"cur_page":' + str(p) + '}}}'
r = session.get(url)
# 遍历每一页的每一个歌手
for k in r.json()['singerList']['data']['singerlist']:
singermid = k['singer_mid']
# 将得到的singer_mid值传入get_singer_songs函数
get_singer_songs(singermid)
③、get_singer_songs()
def get_singer_songs(singermid):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid)+'&order=listen' \
'&begin=0&num=30'
r = session.get(url)
print(url)
# 获取歌手姓名
song_singer = r.json()['data']['singer_name']
print(song_singer)
# 获取歌曲总数
song_count = r.json()['data']['total']
print(song_count)
# 根据歌曲总数计算歌曲页数,每页30首
page_count = math.ceil(int(song_count)/30)
# 循环页数,获取每一页歌曲信息
for p in range(page_count):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid) +\
'&order=listen&begin=' + str(p*30) + '&num=30'
r = session.get(url)
# 得到每一页的歌曲信息
music_data = r.json()['data']['list']
# songname:歌名, ablum:专辑, interval:时长, songmid:歌曲id,用于*载下**音频文件
song_dict = {}
for i in music_data:
song_dict['song_name'] = i['musicData']['songname']
song_dict['song_ablum'] = i['musicData']['albumname']
song_dict['song_interval'] = i['musicData']['interval']
song_dict['song_songmid'] = i['musicData']['songmid']
song_dict['singer_name'] = song_singer
# *载下**歌曲
download_song(song_dict['song_songmid'], song_dict['song_name'])
# 清空处理
song_dict = {}
④、download_song()
def download_song(songmid, songname):
# 获取vkey的purl链接
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":\
{"guid":"0","songmid":["'+songmid + '"],"uin":"0"}}}'
# guid:6946840764
print(url)
r = session.get(url)
song_vkey = r.json()['req_0']['data']['midurlinfo'][0]['purl']
downloadUrl = 'http://183.240.120.15/amobile.music.tc.qq.com/' + song_vkey
resp = session.get(downloadUrl)
print(resp.status_code)
try:
with open('F:\Desktop\python\QQMusic\song\\' + songname + '.m4a', 'wb')as f:
f.write(resp.content)
print('downloadUrl:', downloadUrl)
except Exception:
return 'null'
⑤、主函数,即程序入口
if __name__ == '__main__': get_all_singer()
程序运行结果及编译输出截图如下:
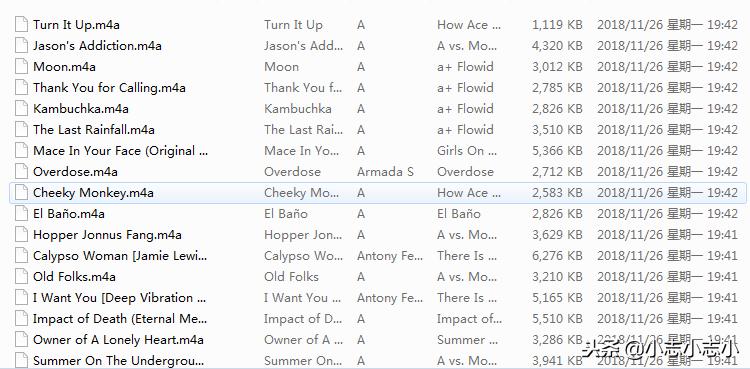
①、本地*载下**歌曲文件

②、pycharm编译输出结果

③、编译输出结果
最后贴上全部代码:
# get_all_singer()主要是按字母A-Z以及特殊字符#来爬取全站歌手
# get_genre_singer()主要是遍历当前字母下歌手总页数
# get_singer_songs()主要是获取当前歌手下歌曲总数并获取*载下**歌曲所需的songmid
# download_song()主要是用来*载下**歌曲文件到本地
# by eric.luo
# 2018/11/26
import requests
import math
session = requests.session()
def get_all_singer():
# 获取字母A-Z和#的全站歌手
for key in range(1, 28):
# 获取当前字母分类歌手页数并转换为列表结构
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index": ' \
+ str(key)+',"sin":0,"cur_page":1}}}'
r = session.get(url)
total = r.json()['singerList']['data']['total']
page_num = math.ceil(total/80)
page_list = [x for x in range(page_num)]
get_genre_singer(key, page_list)
def get_genre_singer(key, page_list):
# 遍历当前字母分类的总页数
for p in page_list:
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index":' \
+ str(key)+',"sin":' + str((p-1)*80)+',"cur_page":' + str(p) + '}}}'
r = session.get(url)
# 遍历每一页的每一个歌手
for k in r.json()['singerList']['data']['singerlist']:
singermid = k['singer_mid']
# 将得到的singer_mid值传入get_singer_songs函数
get_singer_songs(singermid)
# get_singer_songs(singermid)获取歌手的全部歌曲信息
def get_singer_songs(singermid):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid)+'&order=listen' \
'&begin=0&num=30'
r = session.get(url)
# print(url)
# 获取歌手姓名
song_singer = r.json()['data']['singer_name']
# print(song_singer)
# 获取歌曲总数
song_count = r.json()['data']['total']
# print(song_count)
# 根据歌曲总数计算歌曲页数,每页30首
page_count = math.ceil(int(song_count)/30)
# 循环页数,获取每一页歌曲信息
for p in range(page_count):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid) +\
'&order=listen&begin=' + str(p*30) + '&num=30'
r = session.get(url)
# 得到每一页的歌曲信息
music_data = r.json()['data']['list']
# songname:歌名, ablum:专辑, interval:时长, songmid:歌曲id,用于*载下**音频文件
song_dict = {}
for i in music_data:
song_dict['song_name'] = i['musicData']['songname']
song_dict['song_ablum'] = i['musicData']['albumname']
song_dict['song_interval'] = i['musicData']['interval']
song_dict['song_songmid'] = i['musicData']['songmid']
song_dict['singer_name'] = song_singer
# *载下**歌曲
download_song(song_dict['song_songmid'], song_dict['song_name'])
# 清空处理
song_dict = {}
def download_song(songmid, songname):
# 获取vkey的purl链接
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":\
{"guid":"0","songmid":["'+songmid + '"],"uin":"0"}}}'
# guid:6946840764
# print(url)
r = session.get(url)
song_vkey = r.json()['req_0']['data']['midurlinfo'][0]['purl']
downloadUrl = 'http://183.240.120.15/amobile.music.tc.qq.com/' + song_vkey
resp = session.get(downloadUrl)
# print(resp.status_code)
global num
try:
with open('F:\Desktop\python\QQMusic\song\\' + songname + '.m4a', 'wb')as f:
num = num + 1
print('---------------正在*载下**第' + str(num) + '首歌----------------')
f.write(resp.content)
except Exception as err:
print(err)
if __name__ == '__main__':
num = 0 # 计算*载下**歌曲的数量
get_all_singer()
# myProcess()
时间:2018/11/26 晚,目前测试*载下**将近400首暂未发现问题;如果使用过程中出现问题欢迎联系我讨论;<初学python爬虫>
2018年12月3日:修改为多线程多进程同时*载下**,下面附上源代码,需要自取。
# get_all_singer()主要是按字母A-Z以及特殊字符#来爬取全站歌手
# get_genre_singer()主要是遍历当前字母下歌手总页数
# get_singer_songs()主要是获取当前歌手下歌曲总数并获取*载下**歌曲所需的songmid
# download_song()主要是用来*载下**歌曲文件到本地
# by eric.luo
# 2018/11/26
import requests
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
num = 0 # 计算*载下**歌曲的数量
session = requests.session()
def get_all_singer(): # 单线程单进程
# 获取字母A-Z和#的全站歌手
for key in range(1, 28):
# 获取当前字母分类歌手页数并转换为列表结构
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index": ' \
+ str(key)+',"sin":0,"cur_page":1}}}'
r = session.get(url)
total = r.json()['singerList']['data']['total']
page_num = math.ceil(total/80)
page_list = [x for x in range(page_num)]
get_genre_singer(key, page_list)
def get_genre_singer(key, page_list):
# 遍历当前字母分类的总页数
for p in page_list:
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index":' \
+ str(key)+',"sin":' + str((p-1)*80)+',"cur_page":' + str(p) + '}}}'
r = session.get(url)
# 遍历每一页的每一个歌手
for k in r.json()['singerList']['data']['singerlist']:
singermid = k['singer_mid']
# 将得到的singer_mid值传入get_singer_songs函数
get_singer_songs(singermid)
# get_singer_songs(singermid)获取歌手的全部歌曲信息
def get_singer_songs(singermid):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid)+'&order=listen' \
'&begin=0&num=30'
r = session.get(url)
# print(url)
# 获取歌手姓名
song_singer = r.json()['data']['singer_name']
# print(song_singer)
# 获取歌曲总数
song_count = r.json()['data']['total']
# print(song_count)
# 根据歌曲总数计算歌曲页数,每页30首
page_count = math.ceil(int(song_count)/30)
# 循环页数,获取每一页歌曲信息
for p in range(page_count):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg?singermid=' + str(singermid) +\
'&order=listen&begin=' + str(p*30) + '&num=30'
r = session.get(url)
# 得到每一页的歌曲信息
music_data = r.json()['data']['list']
# songname:歌名, ablum:专辑, interval:时长, songmid:歌曲id,用于*载下**音频文件
song_dict = {}
for i in music_data:
song_dict['song_name'] = i['musicData']['songname']
song_dict['song_ablum'] = i['musicData']['albumname']
song_dict['song_interval'] = i['musicData']['interval']
song_dict['song_songmid'] = i['musicData']['songmid']
song_dict['singer_name'] = song_singer
# *载下**歌曲
download_song(song_dict['song_songmid'], song_dict['song_name'])
# 清空处理
song_dict = {}
def download_song(songmid, songname):
# 获取vkey的purl链接
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":\
{"guid":"0","songmid":["'+songmid + '"],"uin":"0"}}}'
# guid:6946840764
# print(url)
r = session.get(url)
song_vkey = r.json()['req_0']['data']['midurlinfo'][0]['purl']
downloadUrl = 'http://183.240.120.15/amobile.music.tc.qq.com/' + song_vkey
resp = session.get(downloadUrl)
# print(resp.status_code)
global num
try:
with open('F:\Desktop\python\QQMusic\song\\' + songname + '.m4a', 'wb')as f:
num = num + 1
print('---------------正在*载下**第' + str(num) + '首歌----------------')
f.write(resp.content)
except Exception as err:
print(err)
# 多线程
def myThread(genre):
# 获取当前字母分类歌手页数并转换为列表结构
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"singerList":{"module":"Music.SingerListServer",' \
'"method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index":' + str(genre) + \
',"sin":0,"cur_page":1}}}'
# print(url)
r = session.get(url)
# print(r.status_code)
total = r.json()['singerList']['data']['total']
# print(total)
page_num = math.ceil(total / 80)
page_list = [x for x in range(page_num)]
thread_number = 10
list_interval = math.ceil(len(page_list)/thread_number)
# 设置线程对象
Thread = ThreadPoolExecutor(max_workers=thread_number)
for index in range(thread_number):
# 计算每条线程应执行的页数
start_num = list_interval*index
if list_interval*(index+1) <= len(page_list):
end_num = list_interval*(index+1)
else:
end_num = len(page_list)
# 每个线程各自执行不同歌手列表页数
Thread.submit(get_genre_singer, genre, page_list[start_num:end_num])
# 多进程
def myProcess():
with ProcessPoolExecutor(max_workers=27) as executor:
for i in range(1, 3): # 设置进程数
executor.submit(myThread, i)
if __name__ == '__main__':
# get_all_singer()
# myProcess()
myProcess()