0. 前言
用ESP32作了个LVGL界面的项目, 自然少不了中文显示, 要显示中文自然需要中文字库.
这个中文字库一般会有3种存在方式:
- 以 大数组 的形式直接写在代码里. 这种适用于需要的 汉字个数较少 的情况;如果把几千个常用汉字都搞成大数组写在code里的话, 一方面code编译生成的bin会超大, 另一方面 你不觉得这种方式太野蛮太不优雅了吗?(不过这种方式, 程序读取字体数据的速度倒是挺快)
- 直接烧写在flash里 . 也分两种情况, 一种是烧在ESP32模块内部flash里, 一种是在外部flash芯片里. 这种方式, 读取字体数据的速度也很快.
- 以文件的形式 存在文件系统里 . 当然, 这个文件系统也是存在于flash上, 相当于把第2种方式套了一层文件系统的壳. 据官方文档描述, 由于每次读取字体数据时都需要通过文件系统API, 速度较慢, 会引起LVGL界面显示卡顿. 所以此方式, 我们不考虑.
由于我们选用的ESP32模块是16MB版本的, 模块内置flash的存储空间绰绰有余, 所以我们选用将中文字库 烧写在模块内部flash 的方式.
这样, 既保证了读取速度, 成本也增加不了多少(毕竟外置flash芯片也要钱, 还增加板上面积).
1. 字库生成
先来生成字库, 字库生成使用 LvglFontTool 软件, 官方*载下**地址, 绿色版软件, 直接解压即可使用. 感谢作者
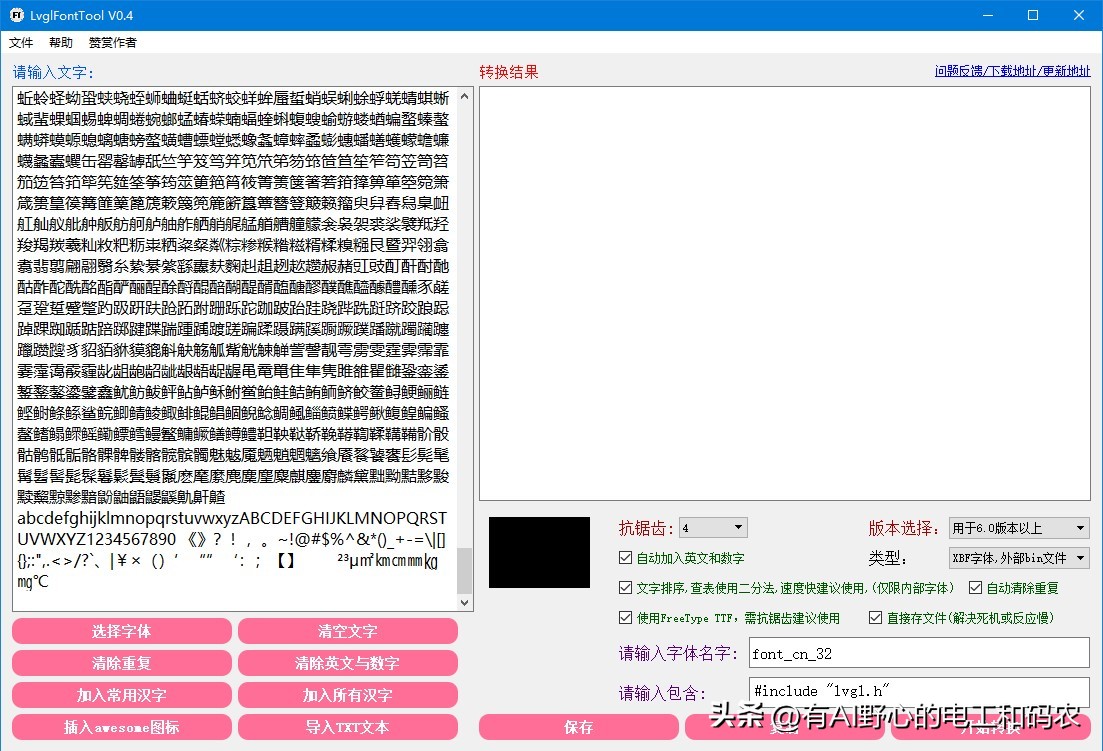
软件运行如上图, 软件的使用方法很简单, 稍稍摸索一下就会了, 软件*载下**地址也有说明, 我这里就不赘述了.
我导入了6千多个常用汉字以及一些字母符号, 使用32像素高的字体, 字体名设为 font_cn_32 ,
点击右下的“开始转换”按钮, 软件会生成2个文件:
- font_cn_32.bin : 字库bin文件, 需要烧写入flash中的文件, 大小约为3.45MB
- font_cn_32.c :供LVGL调用的字体接口API函数C文件, 本文后面还会需要对其进行小小的修改
( 注意: 软件中填写的字体名不同, 生成的2个文件名也随之改变 )
2. 字库的烧写
好了, 字库文件已经有了, 终于到了本文的正题—— 字库烧写 了.
先别急, 说到烧写字库, 是不是要想想, 烧写的地址是多少?烧进去的数据又如何读取出来呢?
烧进去读不出来不也没用, 所以说到如何烧写字库, 应该想的是 如何烧写和读取数据?
我们在前言里已经计划好了, 把字库 烧写在ESP32模块内置flash中 , 那么问题就变成了, 如何读取内置flash里的数据, 如何向内置flash里写入数据?
2.1 分区表
了解ESP32开发的朋友可能都知道, ESP32模块的内置flash, 乐鑫官方是以名为 分区表 的形式, 进行组织管理的( 它还真的类似于Windows的硬盘分区 ).
乐鑫官网文档 API指南 >> 分区表 章节中有详细的介绍, 本文截取部分内容介绍一下.
2.1.1 概述
每片 ESP32 的 flash 可以包含多个应用程序, 以及多种不同类型的数据(例如校准数据、文件系统数据、参数存储数据等). 因此, 我们在 flash 的 默认偏移地址 0x8000 处烧写一张分区表( 注意:分区表是最终被烧写入flash里的 ).
分区表的长度为 0xC00 字节, 最多可以保存 95 条分区表条目. MD5 校验和附加在分区表之后, 用于在运行时验证分区表的完整性. 分区表占据了整个 flash 扇区, 大小为 0x1000 (4 KB) . 因此, 它后面的任何分区至少需要位于 (默认偏移地址) + 0x1000 处.
2.1.2 预定义的内置分区表
要了解分区表, 最简单的方法就是打开项目配置菜单( idf.py menuconfig ), 在 CONFIG_PARTITION_TABLE_TYPE 下选择一个预定义的分区表.
有2个预定义的内置分区表:
- “Single factory app, no OTA”
- “Factory app, two OTA definitions”
我们来看看这2个分区表的内容,
先看看 “ Single factory app, no OTA ” 这个分区表的内容, 如下:
# ESP-IDF Partition Table
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x6000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 1M,
一共3个条目.
- 定义了2个数据分区( Type 字段值为 data ), 分别用于存储 NVS 库专用分区 和 PHY 初始化数据, 其具体意义超出本文主题太多, 请查阅官方文档.
- 定义了1个应用程序分区( Type 字段值为 app ), flash 的 0x10000 (64 KB) 偏移地址处存放一个name为 “factory” 的二进制应用程序, 启动加载器将默认加载这个应用程序.
再来看 “ Factory app, two OTA definitions ” 分区表的内容:
# ESP-IDF Partition Table
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x4000,
otadata, data, ota, 0xd000, 0x2000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 1M,
ota_0, app, ota_0, 0x110000, 1M,
ota_1, app, ota_1, 0x210000, 1M,
一共6个条目, 多了3个条目.
- 新增了一个名为 “otadata” 的数据分区, 用于保存 OTA 升级时需要的数据. 启动加载器会查询该分区的数据, 以判断该从哪个 OTA 应用程序分区加载程序. 如果 “otadata” 分区为空, 则会执行出厂程序.
- 分区表中定义了3个应用程序分区, 这3个分区的类型都被设置为 “app”, 但具体 app 类型不同. 其中, 位于 0x10000 偏移地址处的为出厂应用程序 (factory), 其余两个为 OTA 应用程序(ota_0, ota_1).
这里既然提到了 出厂应用程序 和 OTA应用程序 , 就不得不说明一下:
ESP32启动, 会 从 flash 的 0x1000 偏移地址处加载Bootloader, Bootloader会读取分区表, 并根据其中otadata(如果存在)的内容选择需要引导的应用程序 (app) 分区 .
详细的请参见官方文档的 API 指南 >> 应用程序的启动流程 和 API 指南 >> 引导加载程序 (Bootloader), 以及API 参考 >> System API >> 空中升级 (OTA) 等章节.
2.1.3 关于分区表需要注意的点
通过前面2个预定义分区表, 我们对分区表有了一个直观粗浅的认识, 详细了解还请参看官方文档.
这里只列出几个需关注的点:
- 内置flash的扇区大小为 0x1000(4KB) , 分区的偏移地址( Offset )必须是 0x1000(4KB) 的倍数, 即必须 4K 对齐
- app分区 的偏移地址(Offset)必须要与 0x10000 (64 K) 对齐
- Name 字段可以是任何有意义的名称, 但不能超过 16 个字节, 其中包括一个空字节(之后的内容将被截断), 该字段对 ESP32 并不是特别重要
- Type 字段可以指定为 app (0x00) 或者 data (0x01) , 也可以直接使用数字 0-254(或者十六进制 0x00-0xFE), 注意: 0x00-0x3F 不得使用(预留给 esp-idf 的核心功能) , 如果应用程序想自定义Type值, 请使用 0x40 ~ 0xFE .
- 启动加载器将忽略 app (0x00) 和 data (0x01) 以外的其他Type分区类型
- 当 Type 定义为 app 时, SubType 字段可以指定为 factory (0x00)、 ota_0 (0x10) … ota_15 (0x1F) 或者 test (0x20)。
- 当 Type 定义为 data 时, SubType 字段可以指定为 ota (0x00)、phy (0x01)、nvs (0x02)、nvs_keys (0x04) 或者其他组件特定的子类型(请参考子类型枚举).
- 当 Type 值是由应用程序定义的任意值 0x40-0xFE 时, subtype 字段可以是由应用程序选择的任何值 0x00-0xFE
- Flags 字段当前仅支持 encrypted 标记. 如果 Flags 字段设置为 encrypted,且已启用 Flash 加密 功能, 则该分区将会被加密.
2.1.4 自定义分区表
好了, 对分区表有一定的认识了. 为了把中文字库写入内置flash的分区内, 我们需要自定义分区表.
先给出我的自定义分区表:
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x4000,
otadata, data, ota, 0xd000, 0x2000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 2M,
ota_0, app, ota_0, 0x210000, 2M,
ota_1, app, ota_1, 0x410000, 2M,
font_cn_32, 0x50, 0x32, 0x610000, 4M,
下面说明一下,
- 基本上就是在 内置分区表“ Factory app, two OTA definitions ”的基础上, 增加了一个字库分区.
- 分区Name直接使用了 字库的字体名
- 由于第1节中我们生成的字库文件有3.45MB, 所以字库分区的 Size 设为了 4M .
- 字库分区的Type值, 使用了自定义的 0x50 (在0x40~FE范围内), SubType值设为了 0x32 , 也是自定义值, 让它表示字体的高度值
- 把3个 app 分区的Size改为了 2M , 目前我的程序bin大小为500K左右, 裕量留的满满的
- 0x100000 对应 1M, 0x200000是2M, 注意后面4个大分区的Offset值
- 这个分区表已使用的空间为 10MB+ , 模块内置flash的size是16MB, 还有剩余, 后面还能增加小size字体的字库分区
2.2 配置menuconfig
自定义的分区表在电脑上是以 .csv 文件的形式, 保存在工程根目录下, 比如我的自定义分区表文件为 partitions.csv .
我们在前面提到过分区表最终是被烧写到flash 的 默认偏移地址 0x8000 处, 因此 csv 文件形式的分区表需要被二进制化, 才能被烧写.
我们在 menuconfig 中选择“Custom partition table CSV”, 然后输入 分区表的csv文件名以及在工程中的路径, 即可.
实操一下, idf环境中, 输入 idf.py menuconfig 命令:
在主界面下选择 Partition Table 分区表,
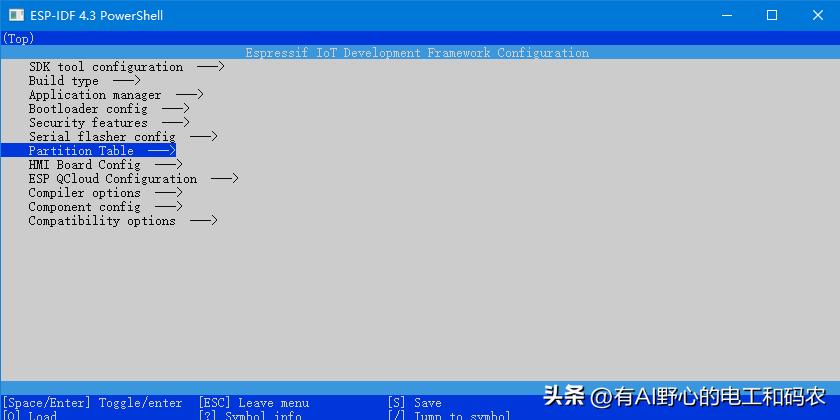
进入
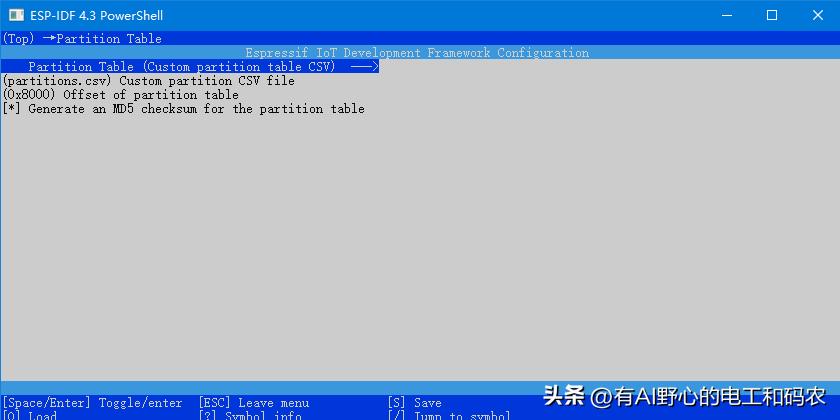
再选择 Partition Table (Custom partition table CSV) , 进入
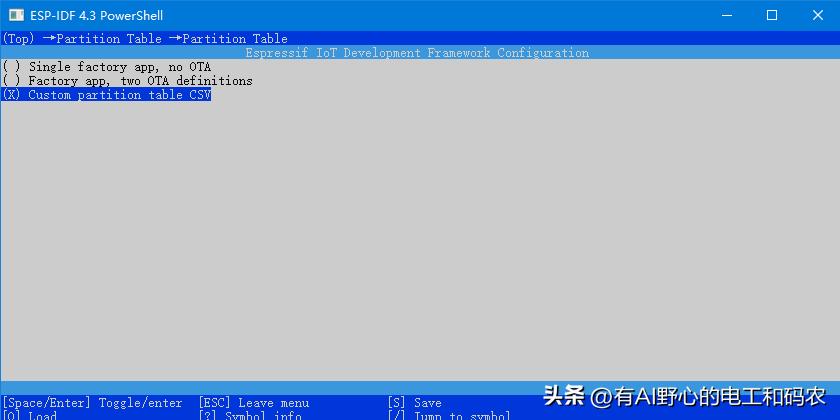
选中 Custom partition table CSV (定制分区表CSV), 再回到上一层
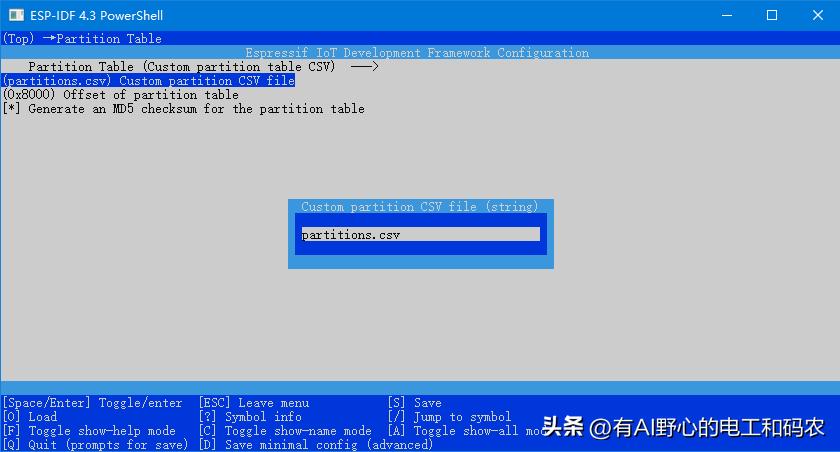
在第二行选中, 可输入 定制分区表的 CSV文件名.
到此定制分区表的配置完毕.
另外提一下, 我们可在menuconfig中, 设置一下flash的size大小, 一定要和自己使用的模块一致, 如下图操作:
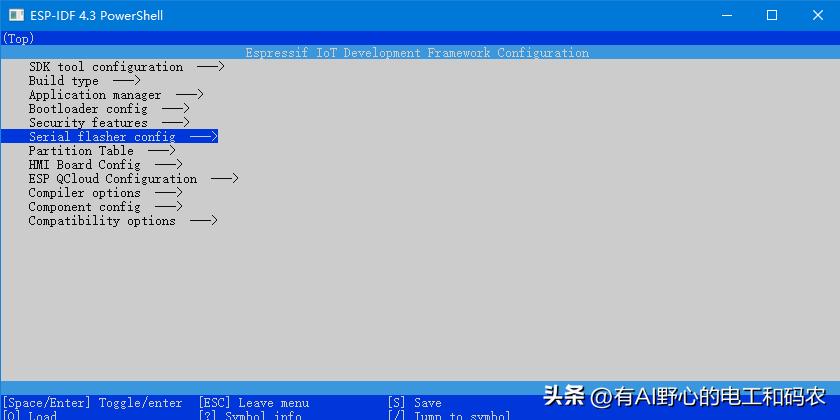
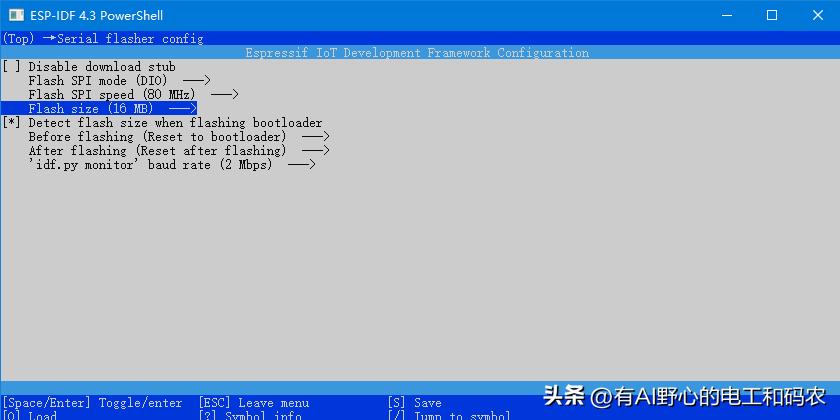
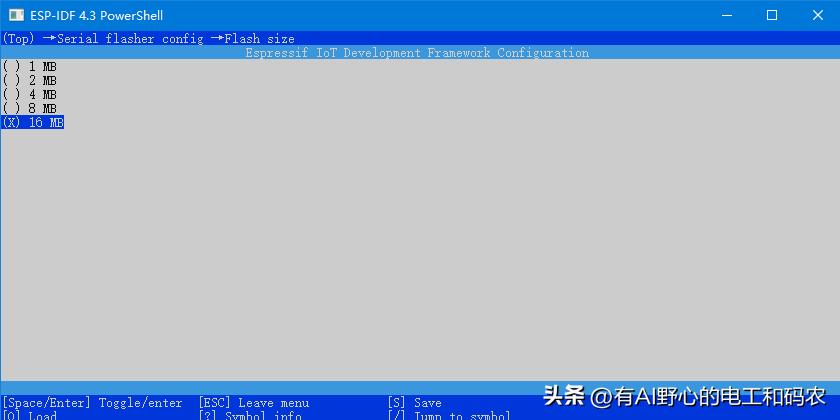
自定义分区表在menuconfig中配置好后, 后面编译工程执行 idf.py build 时, 会自动将将csv分区表生成二进制bin文件.
2.3 修改C文件
字库数据写在flash什么地方已经安排好了, 现在要考虑怎么把flash里的字库数据读出来了.
回忆第1节中, 我们用字库生成软件 生成了 font_cn_32.c 文件, 其中有这么一段代码:
//static uint8_t __g_font_buf[714];//如bin文件存在SPI FLASH可使用此buff
static uint8_t *__user_font_getdata(int offset, int size){
//如字模保存在SPI FLASH, SPIFLASH_Read(__g_font_buf,offset,size);
//如字模已加载到SDRAM,直接返回偏移地址即可如:return (uint8_t*)(sdram_fontddr+offset);
return __g_font_buf;
}
需要在 __user_font_getdata 函数体内, 写入实际的flash读数据的代码, 读出的数据放到buffer __g_font_buf 中(buffer数组的size是字库生成软件自动设定的, 和字体大小有关, 我们32的字体算较大的了, 所以buffer也不小.).
既然我们用了分区表, 乐鑫官方也提供了分区内数据读写的API函数, 参见官方文档API参考>>存储API>>分区API, 截取官方文档中的一段内容如下:
该组件在 esp_partition.h 中声明了一些 API 函数,用以枚举在分区表中找到的分区,并对这些分区执行操作:
esp_partition_find():在分区表中查找特定类型的条目,返回一个不透明迭代器;
esp_partition_get():返回一个结构体,描述给定迭代器的分区;
esp_partition_next():将迭代器移至下一个找到的分区;
esp_partition_iterator_release():释放 esp_partition_find() 中返回的迭代器;
esp_partition_find_first():返回描述 esp_partition_find() 中找到的第一个分区的结构;
esp_partition_read()、esp_partition_write() 和 esp_partition_erase_range() 等同于 esp_flash_read()、esp_flash_write() 和 esp_flash_erase_region(),但在分区边界内执行。
我们从flash分区中读数据, 最终只需要用到2个函数即可, esp_partition_find_first() (用来找到我们的 字库 分区) 和 esp_partition_read() (读出数据).
这两个函数的详细声明如下:
const esp_partition_t * esp_partition_find_first (esp_partition_type_t type, esp_partition_subtype_t subtype, const char *label)
Find first partition based on one or more parameters.
参数:
- type – Partition type, one of esp_partition_type_t values or an 8-bit unsigned integer. To find all partitions, no matter the type, use ESP_PARTITION_TYPE_ANY, and set subtype argument to ESP_PARTITION_SUBTYPE_ANY.
- subtype – Partition subtype, one of esp_partition_subtype_t values or an 8-bit unsigned integer To find all partitions of given type, use ESP_PARTITION_SUBTYPE_ANY.
- label – (optional) Partition label. Set this value if looking for partition with a specific name. Pass NULL otherwise.
返回 : pointer to esp_partition_t structure, or NULL if no partition is found. This pointer is valid for the lifetime of the application.
esp_err_t esp_partition_read (const esp_partition_t *partition, size_t src_offset, void *dst, size_t size)
Read data from the partition.
Partitions marked with an encryption flag will automatically be be read and decrypted via a cache mapping.
参数:
- partition – Pointer to partition structure obtained using esp_partition_find_first or esp_partition_get. Must be non-NULL.
- dst – Pointer to the buffer where data should be stored. Pointer must be non-NULL and buffer must be at least ‘size’ bytes long.
- src_offset – Address of the data to be read, relative to the beginning of the partition.
- size – Size of data to be read, in bytes.
返回: ESP_OK, if data was read successfully; ESP_ERR_INVALID_ARG, if src_offset exceeds partition size; ESP_ERR_INVALID_SIZE, if read would go out of bounds of the partition; or one of error codes from lower-level flash driver.
最终, 我们对 font_cn_32.c 文件的修改如下:
#include "esp_partition.h"
...
...
...
static uint8_t __g_font_buf[714];//如bin文件存在SPI FLASH可使用此buff
static esp_partition_t* partition_font = NULL;
static uint8_t *__user_font_getdata(int offset, int size){
//如字模保存在SPI FLASH, SPIFLASH_Read(__g_font_buf,offset,size);
//如字模已加载到SDRAM,直接返回偏移地址即可如:return (uint8_t*)(sdram_fontddr+offset);
if( partition_font == NULL ) {
partition_font = esp_partition_find_first(0x50, 0x32, "font_cn_32");
assert(partition_font != NULL);
}
esp_err_t err = esp_partition_read(partition_font, offset, __g_font_buf, size);//读取数据
if(err != ESP_OK) {
printf("Failed to reading cn font date\n");
}
return __g_font_buf;
}
我们加了 #include "esp_partition.h" , 以便调用2个API函数.
通过分区的 Type值0x50, SunType值0x32 和 Name值"font_cn_32" 来找到我们的 字库分区,
代码很简单, 其他就没什么好说明的了.
记得把这个c文件加入到工程里, 至于如何添加, 就不是本文的范畴了.
2.4 烧写字库
2.4.1 工程编译
现在, 我们分区表设定好了, 代码也改好了, 可以编译了.
idf环境里工程目录下, 执行 idf.py build
编译成功, 最后会输出如下:
Project build complete. To flash, run this command:
C:\Users\admin\.espressif\python_env\idf4.3_py3.8_env\Scripts\python*ex.e**
..\..\..\Users\admin\Desktop\esp-idf\components\esptool_py\esptool\esptool.py -p (PORT)
-b 460800 --before default_reset --after hard_reset --chip esp32s2
write_flash --flash_mode dio --flash_size detect --flash_freq 80m
0x1000 build\bootloader\bootloader.bin
0x8000 build\partition_table\partition-table.bin
0xd000 build\ota_data_initial.bin
0x10000 build\myapp.bin
or run 'idf.py -p (PORT) flash'
2.4.2 烧写
终于到了心心念念的烧写字库这个步骤了.
前面我们编译成功后, 最后的输出中, 可以看到:
要么用 idf.py -p (PORT) flash 这个命令来烧写, 要么用那个"一长串的命令".
就是说这两者是等效的.
那个一长串的命令里, 不仅列出来很多烧写时的参数, 还列出了要烧写的各个bin文件及其开始地址, 如下:
0x1000 build\bootloader\bootloader.bin
0x8000 build\partition_table\partition-table.bin
0xd000 build\ota_data_initial.bin
0x10000 build\myapp.bin
看, 有bootloader, 分区表, ota_data初始值 (我打开看了全是0xFF) 和 我们的app 共4个bin文件,
它们前面的烧写地址也和本文前面所描述的预期地址一致.
但, 有个问题, 没有我们的字库bin文件.
没有我们就自己加上呗, 在最后加上 0x610000 main\font_cn_32.bin 即可!
这样相当于修改了烧写命令, 就不能用 idf.py -p (PORT) flash 这个命令来烧写了, 下面是我修改的烧写命令, 精简掉了python前的一大串路径(可惜esptool.py前的路径不能精简)
python ..\..\..\Users\admin\Desktop\esp-idf\components\esptool_py\esptool\esptool.py
-p COM3 -b 460800 --before default_reset --after hard_reset --chip esp32s2
write_flash --flash_mode dio --flash_size detect --flash_freq 80m
0x1000 build\bootloader\bootloader.bin
0x8000 build\partition_table\partition-table.bin
0xd000 build\ota_data_initial.bin
0x10000 build\myapp.bin
0x610000 main\font_cn_32.bin
注意几点:
- 我用COM3带入了(PORT)
- 上面命令行, 我为了看起来清晰, 加入了回车. 使用时, 请一定要去掉回车让其成为一行, 或 使用命令行的换行符来替代, 不然肯定无法执行
用这个命令, 就可以在烧写程序的同时, 顺便把字库烧写进去了.
而且经过测试, 后续再用 idf.py -p (PORT) flash 命令烧写更新程序, 也不会覆盖掉后面的字库分区, app烧写更新, 字库不受影响, 烧写一次会一直妥妥的在那里, nice.
如果仅烧写字库, 也可以使用下面的精简命令:
python ..\..\..\Users\admin\Desktop\esp-idf\components\esptool_py\esptool\esptool.py
-p COM3 write_flash 0x610000 main\font_cn_32.bin
3. 字库的使用
至于如何在LVGL中显示汉字, 代码编写和显示英文差不多, 只是多个字体声明语句.
代码如下:
...
LV_FONT_DECLARE( font_cn_32 ); // 声明我们的中文字体, 如果代码里已声明过, 就不用再声明
...
lv_label_set_text(btnInfoLab, (LV_SYMBOL_HOME "你好 世界"));
lv_obj_set_style_local_text_font(btnInfoLab, LV_LABEL_PART_MAIN, LV_STATE_DEFAULT, &font_cn_32);
...
OK, 这样就可以了.