写在前面的话:对于初学者对于Linux不熟的童鞋,建议使用root用户操作。另外,本教程为自己试验中的原创。。。
一:前期准备
1.修改hosts文件,增加主机名和端口映射。
终端下输入命令“vi /etc/hosts”,在文件末尾加上主机名与端口的映射关系,如下图所示:

2.关闭防火墙
停止防火墙
[root@master ~]# systemctl stop firewalld [root@master ~]# systemctl disable firewalld
禁用Selinux
[root@master ~]# setenforce 0 [root@master ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
3.配置各节点之间的ssh免密登陆
3.1终端下输入命令“ssh-keygen -t rsa”,生成非对称公钥和私钥,这个在集群中所有节点机器都必须执行,一直回车就行。
3.2通过ssh登录远程机器时,本机会默认将当前用户目录下的.ssh/authorized_keys带到远程机器进行验证,这里是/root/.ssh/authorized_keys中公钥(来自其他机器上的/root/.ssh/ id_rsa.pub.pub), 以下代码只在主节点执行就可以做到主从节点之间SSH免密码登录 cd root/.ssh/
3.3首先将Master节点的公钥添加到authorized_keys
cat id_rsa.pub>>authorized_keys
3.4其次将worker节点的公钥添加到authorized_keys,这里我是在
Master机器上操作的
ssh root@worker01 cat /root/.ssh/id_rsa.pub>> authorized_keys ssh root@worker02 cat /root/.ssh/id_rsa.pub>> authorized_keys
3.5这里将Master节点的authorized_keys分发到其他worker节点
scp -r /root/.ssh/ authorized_keys root@worker01:/root/.ssh/ scp -r /root/.ssh/ authorized_keys root@worker02:/root/.ssh/
二:jdk安装
*载下**Linux版的jdk,可自行百度,此处不再演示。
上传:将*载下**好的jdk上传到Linux服务器(若是在Linux上*载下**的jdk,则此步跳过)。可通过WinScp或者Xftp等工具上传。
解压:tar -zxvf tar -zxvf jdk-8u151-linux-x64.tar.gz

配置环境变量
在终端下输入“vi /etc/profile”,编辑该文件,在文件末尾加上如下内容:
export JAVA_HOME=/bigdata/soft/jdk1.8.0_151/ export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

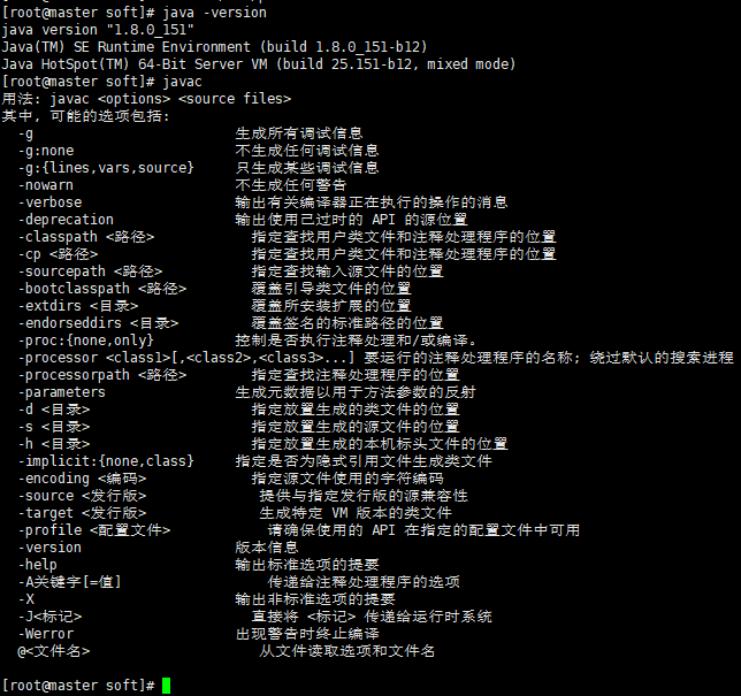
然后保存退出,输入命令“source /etc/profile”,使修改得配置文件生效。在终端下输入“java -version”或者“javac”查看jdk是否安装成功,若成功则如下图所示:然后将配置文件发送到集群中的其他节点。
将jdk分发到集群中的各个worker节点:
scp -r jdk1.8.0_151 root@worker01:/bigdata/soft/jdk1.8.0_151 scp -r jdk1.8.0_151 root@worker02:/bigdata/soft/jdk1.8.0_151
三:Hadoop安装
1.*载下**(本教程以Hadoop3.0稳定版为例)
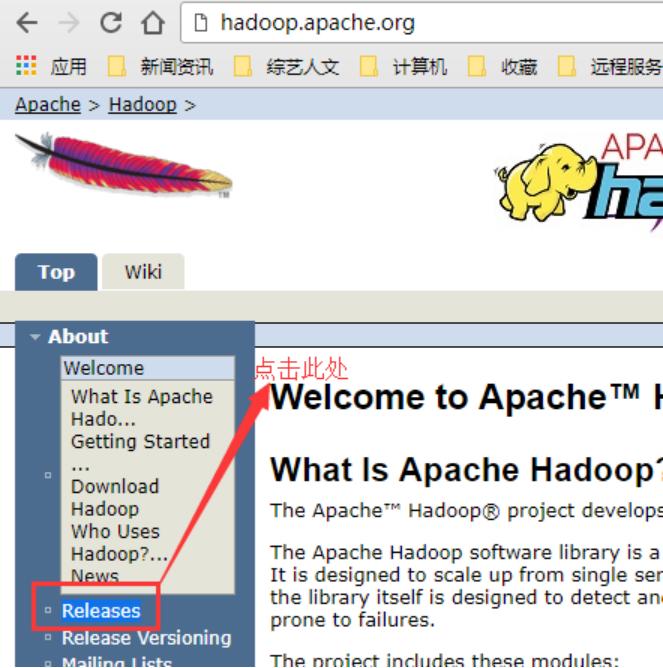
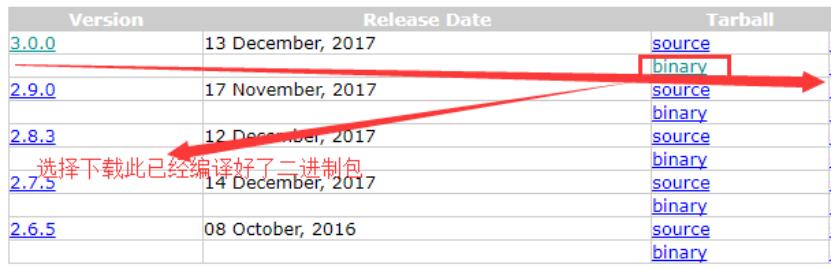
登陆hadoop官网:http://hadoop.apache.org,选择左侧的Releases,选择3.0.0版本,点击binary,此时会看到可供*载下**的镜像源,本例选择清华大学的镜像源,点击之后即可*载下**。整个过程如下图所示:

2.上传(若是在Linux环境下此步骤则不需要,上传方式同jdk,此处不再赘述)
3.解压
在终端输入解压命令 tar -zxvf hadoop-3.0.0
4.配置
4.1系统配置文件修改
修改配置文件“/etc/profile”,终端输入命令“vi /etc/profile”

4.配置
4.1系统配置文件修改
修改配置文件“/etc/profile”,终端输入命令“vi /etc/profile”

在文件末尾新增hadoop的环境变量路径
#set hadoop path export HADOOP_HOME=/bigdata/soft/hadoop-3.0.0 export PATH="$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin"

然后输入命令“source /etc/profile”,使该文件生效,之后将该文件发送到集群中的其他节点,并在其他节点同样source该文件使其生效。
4.2 Hadoop配置文件修改,首先进入$HADOOP_HOME/etc/hadoop目录下,本例为“/bigdata/soft/hadoop-3.0.0/etc/hadoop”,如下图所示:

4.2.1 修改core-site.xml,在终端输入命令“vi core-site.xml”,在文件末增加如下内容:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/bigdata/hdfs/tmp</value> </property> </configuration>
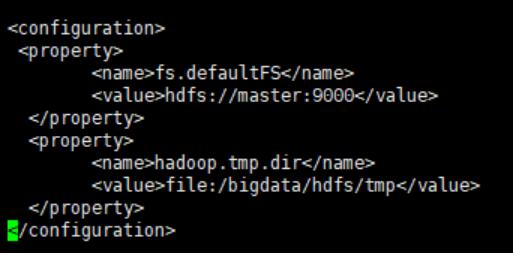
完成之后保存退出。
4.2.2修改“hdfs-site.xml”配置文件,终端输入“vi hdfs-site.xml”,在文件末加上如下内容:
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/bigdata/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/bigdata/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value> worker01:9001</value> </property>
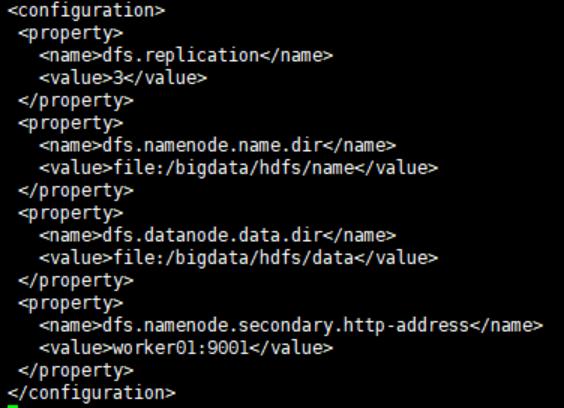
4.3.3修改“mapred-site.xml”配置文件,步骤如上,在文件末新增如下内容:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /bigdata/soft/hadoop-3.0.0/etc/hadoop, /bigdata/soft/hadoop-3.0.0/share/hadoop/common/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/common/lib/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/hdfs/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/hdfs/lib/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/mapreduce/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/mapreduce/lib/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/yarn/*, /bigdata/soft/hadoop-3.0.0/share/hadoop/yarn/lib/* </value> </property> </configuration>
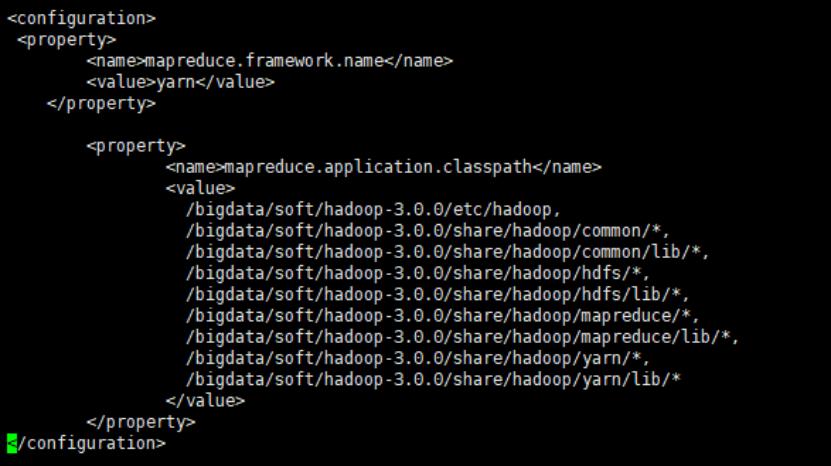
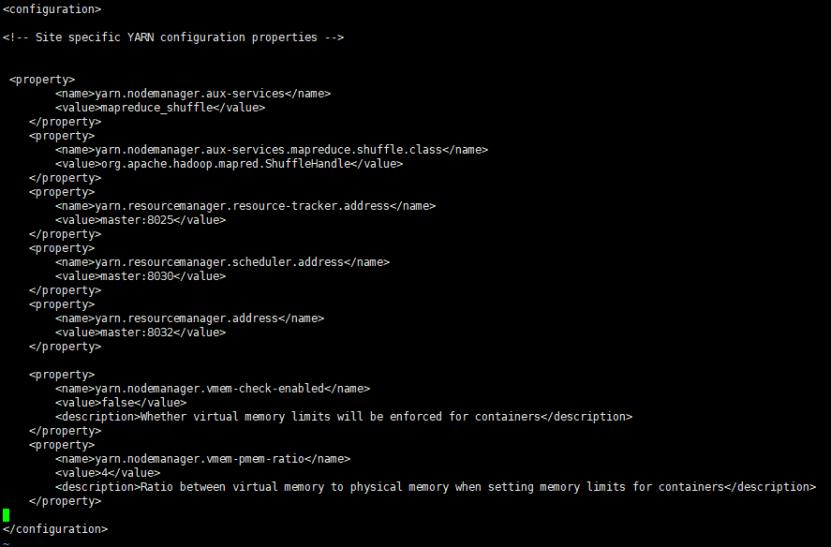
4.3.4修改“yarn-site.xml”配置文件,步骤如上,在文件末新增如下内容:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandle</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /bigdata/soft/bigdata/hadoop-3.0.0/etc/hadoop, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/common/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/common/lib/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/hdfs/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/hdfs/lib/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/lib/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/yarn/*, /bigdata/soft/bigdata/hadoop-3.0.0/share/hadoop/yarn/lib/* </value> </property> <!—下面两个配置是Spark on yarn 需要的,只针对虚拟机搭建的集群,若是物理机则不需要--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> <description>Whether virtual memory limits will be enforced for containers</description> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> <description>Ratio between virtual memory to physical memory when setting memory limits for containers</description> </property> </configuration>
4.3.5修改“hadoop-env.sh”配置文件,用vi打开该文件,然后操作如下图所示:

之后保存退出。
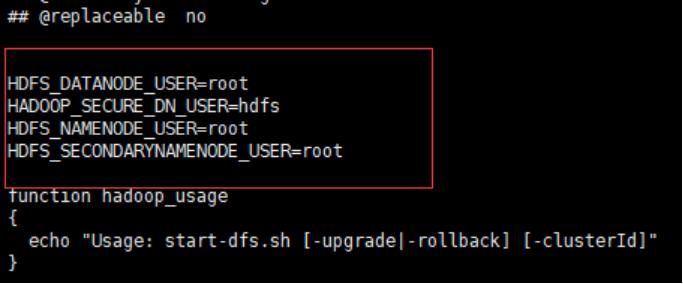
4.3.6修改“start-dfs.sh”和“stop-dfs.sh”(这两个文件位于Hadoop安装目录下的sbin目录下),在文件注释最开始处加上如下:
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
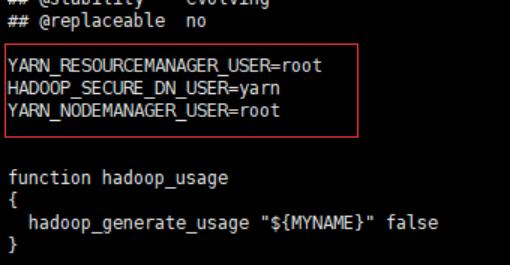
4.3.7同样在该目录下修改“start-yarn.sh”和“stop-yarn.sh” 在文件注释最开始处加上如下:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
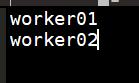
4.3.8 修改worker文件,将worker1,worker2写入到文件中。
5:发送
将解压且配置好的hadoop发送到集群的各个节点:
scp -r hadoop-3.0.0 root@ worker01:/bigdata/soft/hadoop-3.0.0 scp -r hadoop-3.0.0 root@ worker02:/bigdata/soft/hadoop-3.0.0

6.格式化NameNode
hdfs namenode -format
7.启动
启动hdfs:start-dfs.sh 启动yarn:start-yarn.sh
启动成功后输入jps命令,可以看到守护进程如下图所示
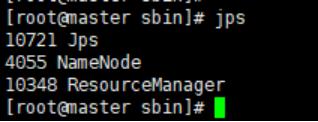
则集群搭建成功。
若要测试该机器是否真正搭建成功,则可以用hadoop自带的WordCount例子测试。具体步骤此处不再演示,可以自行百度。