本文为「大型网红记录片」python 文科数据分析系列。 首发于我的博客 https://willisfusu.github.io/post/jin-ri-tou-tiao-1/
为什么有这篇文章
因为老婆博士专业的原因,她需要获取不少网站的新闻或者帖子的评论,并且对评论进行数据分析或者是自然语义分析(NLP)。因此从来没有接触过 python,只有 VB 二级的我自然就成了她的技术支持,为她提供 python 爬虫和数据分析业务 。
经过一段时间学习之后,我意识到,这些需求可能在文科的数据分析中具有某种程度上的一致性,如果能够记录下每个项目,可以供他人参考,也可以提高自己对于代码的理解。
结合我自己的学习过程,我觉得如果能够在学习一门编程语言的过程中有一个比较明确的目的,并且从一个可以执行的项目开始,可以大幅度地提高自己的学习意愿与动力。所以我觉得如果可以,尽量从一个简单易行的项目入手,而不是拿到一个事无巨细的教程,从基础开始学习。自下而上是可以打下坚实的基础,但是自上而下的学习可以提供更强大的学习动力。
此篇文章产生的需求为:对指定的*今条头日**上的新闻,获取文章下面的评论,并且将评论翻译为英文。
项目过程
目标页面分析
我们先随意选定一条新闻,打开新闻页面。比如这条。打开之后页面如下:
- 然后在页面上右键,选择「检查」

- 之后会打开开发者工具页面,在 Chrome 下,应该是下面这张图这样
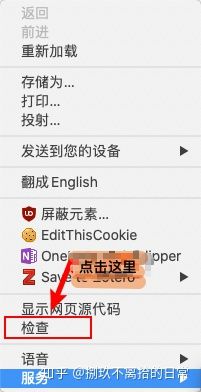
- 选择 Network, 并且刷新页面
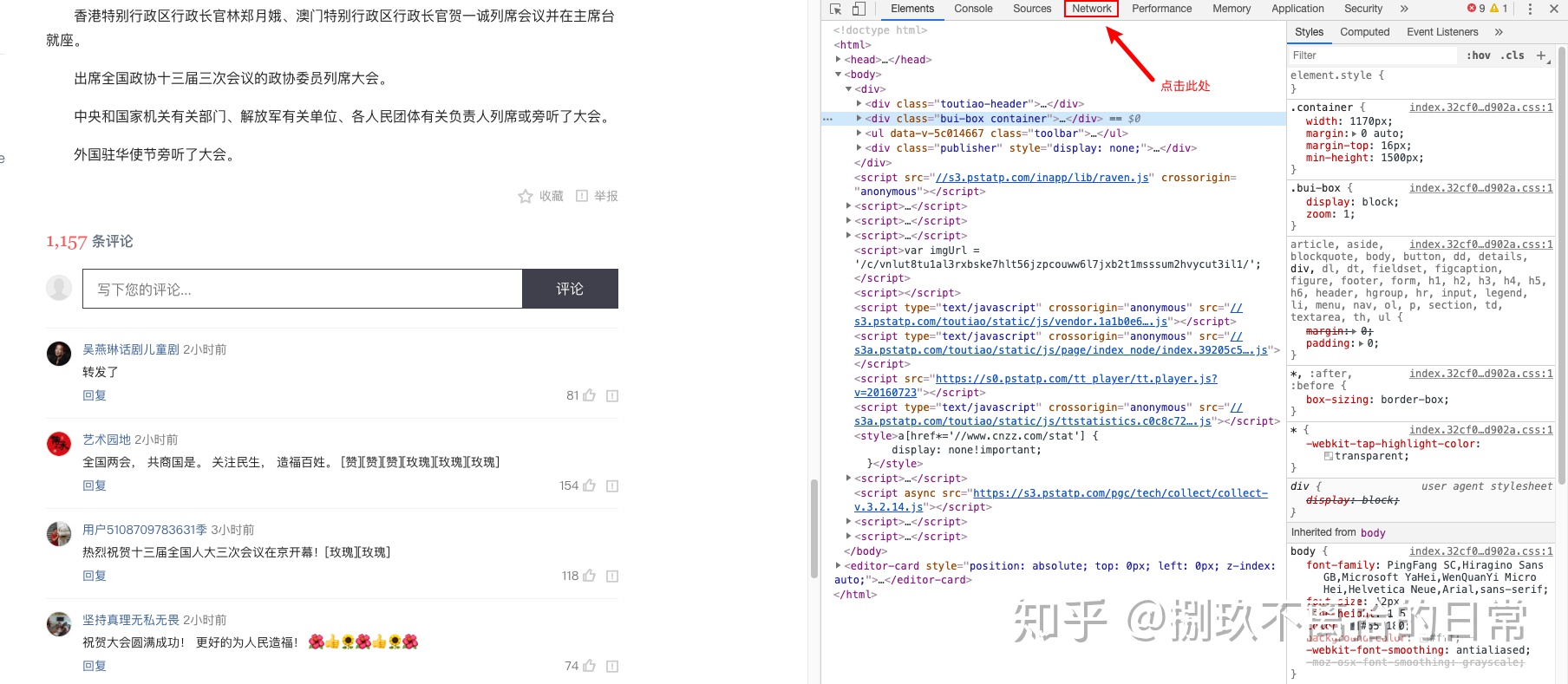
- 这个时候会得到这个页面所有的网络流量内容,我需要的评论内容肯定也在其中。从评论中随便找一句话,或者一个词,在开发者工具中 Control+F,可以打开搜索。搜索刚才随便找的词句。
我就随意选了「转发了」,回车执行搜索后,会发现有结果出现。下一步就是点击搜索结果。点了之后,该搜索结果所在的条目,会变暗(或者变色)。

双击刚刚变色的条目,会打开下面的结果 选择 Preview 可以看到预览,看结构应该是一个 Json 文件。选择 data 打开,发现果然就是需要的评论内容。接下来就是 找到请求的 url 地址以及请求的参数信息。
- 点击 headers,查找请求信息从这张图里,可以知道请求的 url 地址,以及请求方法是 Get 方法。

继续往下拉,可以看到请求的头信息(request headers)
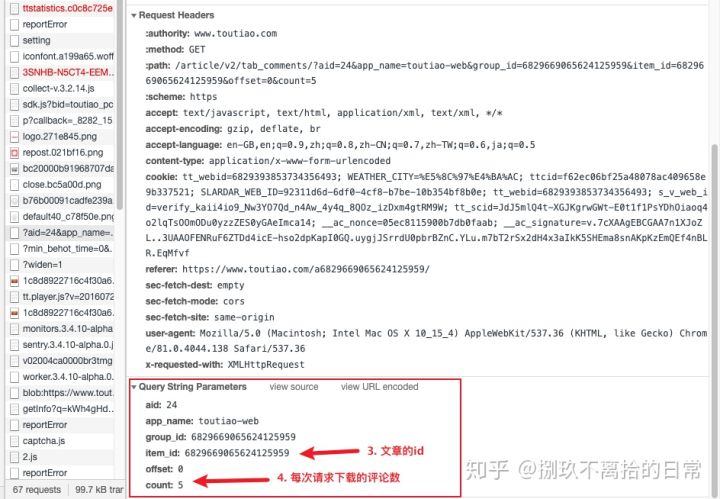
通过上面五步,就完成了对目标页面的分析,那得到了什么结果呢?
请求地址 https://www.toutiao.com/article/v2/tab_comments/?aid=24&app_name=toutiao-web&group_id=6829669065624125959&item_id=6829669065624125959&offset=0&count=5
请求方法 Get
请求参数 Parameters :aid: 24
app_name: toutiao-web
group_id: 6829669065624125959
item_id: 6829669065624125959
/* item_id, group_id 与文章链接中的数字是相同的,应该是文章的id*/
offset: 0
count: 5
/*offset 应该是评论的偏移量,count应该是每次返回的评论数*/
请求地址及请求参数分析
通过对目标页面分析之后,得到了请求的地址及请求参数。在使用爬虫时,我们需要自己构造请求链接,所以首先得搞清楚请求链接是怎么构造的。
观察这个链接:前半部分https://www.toutiao.com/article/v2/tab_comments/? 可以不用管,后半部分则是请求参数组合在一起。
这样看起来,我们只需要在 for 循环中 offset 偏移就可以获取所有的评论。
验证 :
点击下图中标志出来的图标,清空 network 标签,然后点击评论下面的 「加载更多评论」,看看会返回什么结果。

跟上面一样,找到返回的评论,点击 headers,观察请求地址

将两次请求的地址放到一起对比,更容易找到变化:
https://www.toutiao.com/article/v2/tab_comments/?aid=24&app_name=toutiao-web&group_id=6829669065624125959&item_id=6829669065624125959&offset=0&count=5
https://www.toutiao.com/article/v2/tab_comments/?aid=24&app_name=toutiao-web&group_id=6829669065624125959&item_id=6829669065624125959&offset=5&count=10
Python 程序编写
由于此次返回的结果直接就是 Json 格式,对于结果处理是相当友好。 代码中用到的库如下:
- requests http 请求库,用于向服务器发送请求,获得请求结果。
- pymongo 数据库,用于数据持久化 (用其它文件存储方式也可以,我这里使用 pymongo 主要是因为自己想要熟练一下这个库的使用。完全也可以用 pandas 或者 Excel 相关的库替代)
- json json 处理 因为返回的结果是 json 格式。
请求链接构造首先我们要做的是构造请求的 url 链接,根据我们上面的分析,只要在 for 循环中更新 offset 就可以了。代码示例如下:
def handle_comment_url(id):
for a in range(0, 80, 20):
# 此处使用 range 函数,产生 offset 的数值(0, 20, 40, 60……)这里的80是因为老婆只需要前50条热评。如果想得到所有的评论,可以将80换成一个很大的数值即可,例如80000。
param_data = {
"group_id": id,
"item_id": id,
"offset": a,
"count": 20
}
# param_data 就是上面分析得到的请求参数
url = "https://www.toutiao.com/article/v2/tab_comments/?aid=24&app_name=toutiao-web&" + urlencode(param_data)
# 构造 url,使用 urlencode 将参数组合到一起,省得自己写产生错误。
result = handle_response(url)
if result:
break
# 将构造的 url给到另一个函数,处理。这里 if 条件语句的作用是在上面想要获得所有评论时,可以及时退出循环。
然后我们再构造结果请求函数def handle_url(url):
header = {
"accept": "text/javascript, text/html, application/xml, text/xml, */*",
"accept - encoding": "gzip, deflate, br",
"accept-language": "en-GB,en;q=0.9,zh;q=0.8,zh-CN;q=0.7,zh-TW;q=0.6,ja;q=0.5",
"user-agent": "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
# 增加 headers 参数可以一定程度上防止被「反爬虫」,只能说是一定程度上。「反爬虫」与「反反爬虫」之间的斗争是另一个很长的故事。
response = requests.get(url, headers=header)
return (response)
处理返回结果的函数我们现在构造一个处理返回结果的函数,并且在这个函数里,调用上面的 请求函数。另外,这一步里需要我们对请求返回的 json 数据的结构进行分析,以便我们可以找到对应的键值对。分析 json 很简单,找一个 json 解析的网页,比如。 然后将我们 复制进这个网页中,就可以在右边得到结构比较清晰的结果。
def handle_response(url):
response = handle_url(url)
# 此处调用请求函数
response_json = json.loads(response.text)
# 使用 json 的 loads 方法,将 json 格式的数据,转换为 dict 格式的数据,方便 python 处理。
break_for = True
if (len(response_json["data"]) == 0):
print("评论已经获取完毕!!")
return break_for
# 这里这个 if 语句用于判断评论是否请求完,如果已经请求完,那返回 True,方便上面步骤1中及时中断循环。
else:
for item in response_json["data"]:
comment = {}
comment['id'] = item["comment"]["id"]
comment['username']=item["comment"]["user_name"]
comment["comment_text"] = item["comment"]["text"]
comment["reply_count"] = item["comment"]["reply_count"]
comment["digg_count"] = item["comment"]["digg_count"]
comment["creat_time"] = item["comment"]['create_time']
mycol.insert_one(comment)
print("已经完成20次数据库写入")
# 写入数据。
说明
多线程、协程的使用
这个例子中,我其实尝试使用过多线程,毕竟可以大幅度缩减时间。但是*今条头日**对于爬虫限制的挺厉害,我有一天晚上就被限制了 ip,导致几个小时没法访问*今条头日**。所以后来就干脆不使用多线程了,能稳定的运行实在是优先于时间少。 也有可能是我使用方法不对,想尝试的朋友可以尝试。
pymongo 的使用
在这个例子中使用 pymongo 仅仅是因为我想要练习使用这个工具,数据的持久化有太多方法,使用任何一种即可。其实使用 pymongo 后面还给我带来了不少不便利。
获取所有评论的方法
在这个例子中,获取所有评论的方法显得有些「*力暴**」直接是使用一个很大的数值来代替真实的评论总数。其实这也是无奈,因为头条将对已有评论的回复也计算在评论数中,所以就算是使用真实的评论数,也得对返回的 json→ data 长度进行判断。既然是这样,直接使用一个大数值代替也是一样的。
总结
技术总结
头条新闻评论的获取就到这里了。其实大部分的爬虫都是这样的思路,最重要的就是获得请求地址,以及能构造出正确的请求 url。
我的代码文件可以在这里找到:https://github.com/willisfusu/python_projects_wife/tree/master/jin_ri_tou_tiao
部分库及方法详解
其实我自己在写的过程中,也是不断去确认一些函数、库、方法的使用详解。比如 json 的 load 与 loads 区别。所以我在这里把一些我查过的列出来,这样也方便我自己回来复习。