
量化研究QRI
Zipline是美国Quantopian公司开源的量化交易回测引擎,它使用Python语言开发,部分代码使用Cython融合了部分c语言代码。Quantopian在它的网站上的回测系统就是基于Zipline的,经过生产环境的长期使用,已经比完善,并且在持续的改进中。
不过非常可惜的是,作为Zipline的创始公司Quantopian,在2020年11月14日宣布正式停止服务。 研究和回测功能停止使用 。 Zipline、Alphalens、Pyfolio、Empyrical、Trading calendar以及其他开源项目都将在GitHub上继续运行 。Quantopian将来也会在YouTube上开设一个栏目,其讲座和视频内容可以继续保存。
官方介绍的特征
- Ease of Use:: Zipline尝试摆脱束缚,使您可以专注于算法开发。参见下面的代码示例。
- “Batteries Included”: 可以从用户编写的算法中轻松访问许多常用统计信息,例如移动平均和线性回归。
- PyData Integration: 历史数据的输入和性能统计数据的输出均基于Pandas DataFrames,可以很好地集成到现有的PyData生态系统中。
- Statistics and Machine Learning Libraries: 您可以使用matplotlib,scipy,statsmodels和sklearn之类的库来支持最新交易系统的开发,分析和可视化。
1. 技术解析:
a、运行环境: Windows7以上版本、Ubuntu、Linux
b、开发语言: python3.7
c、系统层次:
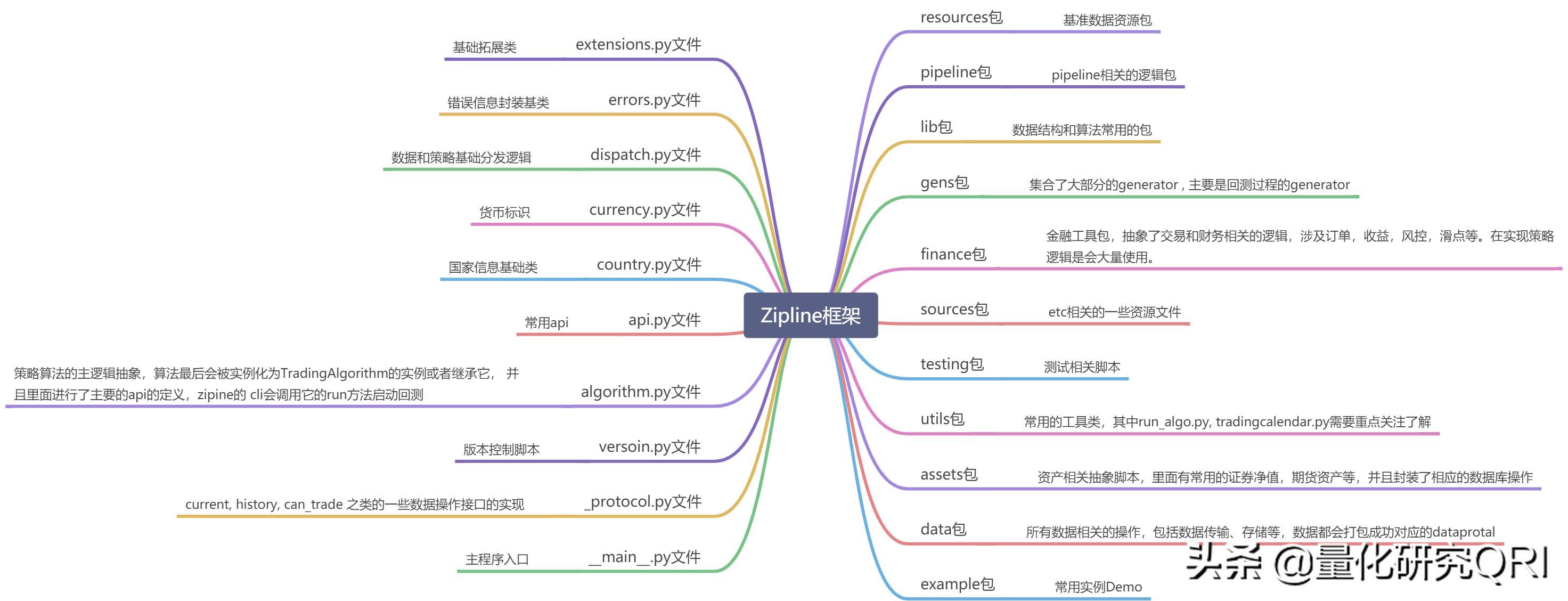
量化研究QRI
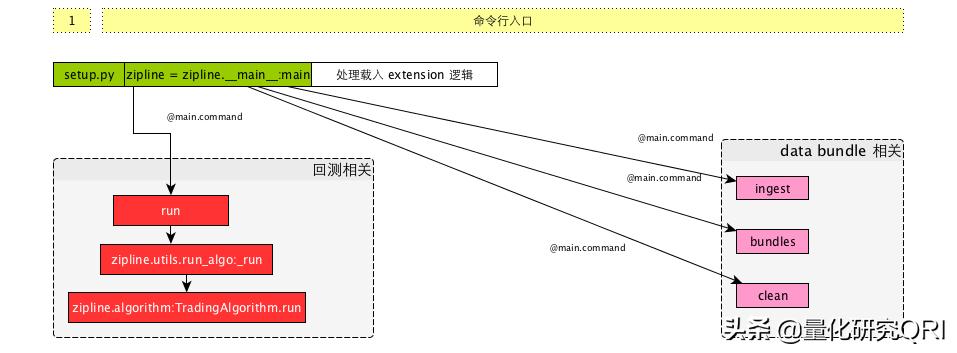
e、程序入口文件__main__.py:
这里我们只需要关注main入口文件里面的几个主要方法:
- run方法:负责策略程序的执行
- ingest方法:负责拉取策略所需要的所有计算数据包
- bundles方法:查看所有数据包
- clearn方法:清除数据包
在mian的入口中,除了这几个子命令,它还是用了load_extensions来载入所有的扩展,extension 可以指定扩展的列表。
run命令在一些初始化和装载过程之后,会调用TradingAlgorithm的run方法。
ingest命令会调用data.bundles.core的ingest函数来进行拉取。
f、整体框架结构:
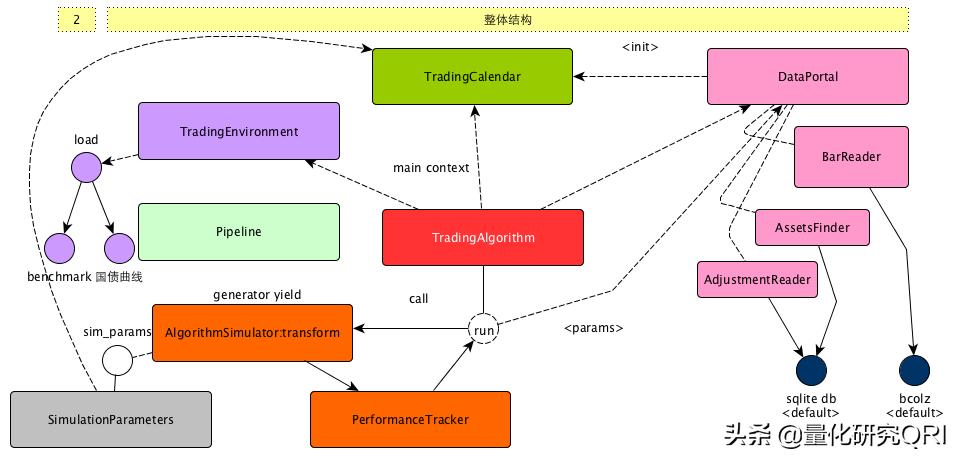
量化研究QRI
这里我们需要注意的几个细节:
TradingAlgorithm: 量化策略的抽象,既可以通过初始化传入构造上参数的方式,也可以通过继承的方式构造,其中zipline命令行主要的运行入口逻辑 run 方法也在这个类中
TradingCalendar: 交易日历的抽象,这个类非常重要,无论是在构建数据的过程还是运行的过程,都可以用到
DataPortal: 数据中心的抽象,可以通过这个入口获取很多不同类型的数据
AlgorithmSimulator: 使用generator的方式,表述了策略运行过程的主循环。如果说TradingAlgorithm更像是代表了策略本身,那么AlgorithmSimulator更像是策略的执行器,尤其要关注的是他的transform方法
TradingEnvirioment: 构造运行环境,主要是benchmark和国债利率曲线等信息,对于美国的市场,这个类基本上不太需要关注,但是对于国内的市场,我么需要构建自己的TradingEnvironment
本身Zipline就是基于事件驱动的回测框架,针对美国市场的适配度很友好,但是针对国内市场的适配度就比较难实现。最好的方法就是实现本地化管理,对接本地数据库来进行策略的回测和编写。在进行策略编写的时候我们的重心往往也就只是在策略本身,如果不是遇到问题我们可能很少关注到框架本身的设计逻辑。
2、使用难度
在讲述Zipline使用难度之前我们需要了解Zipline到底如何使用,怎么实现我们的一个策略,具体实现的整体逻辑又是怎么样的。
量化研究QRI
Zipline主要有三种启动的方式:
- 使用Zipline命令行工具
- 使用Jupyter Notebook 的Zipline集成magic
- 直接自己组装和调用TradingAlgorithm
首先,在zipline中,我们需要两个关键函数来完成一个策略。教程中有如下这样段代码。
from zipline.api import order, record, symbol
def initialize(context):
# 策略初始化函数,一般常用的参数设置以及一些需要在策略运行之前初始化的数据都需要在这里提前完成。
pass
def handle_data(context, data):
"""
策略数据绑定函数,大部分策略框架都是事件驱动模型,驱动的前提是有数据交互,绑定数据之后可以实现tick或者是bar类型的数据推送,形成对应的事件行为,针对tick和bar的价格或者订单簿模型做相应的策略处理
"""
order(symbol('AAPL'), 10)
record(AAPL=data.current(symbol('AAPL'), 'price'))
# 构建一个TradingAlgorithm类,然后run这个类
algor_obj = TradingAlgorithm(initialize=initialize, handle_data=handle_data)
perf_manual = algor_obj.run(data_c)
按照上面的步骤,策略的运行逻辑就完成了。
使用难度在了解整体的逻辑和运行思路的前提下还是比较简单的。
因为本文主要测评为主,不会过多涉猎教程,后期会针对相关框架推出更多更加详细的教程供大家学习参考。
3、策略编写难度
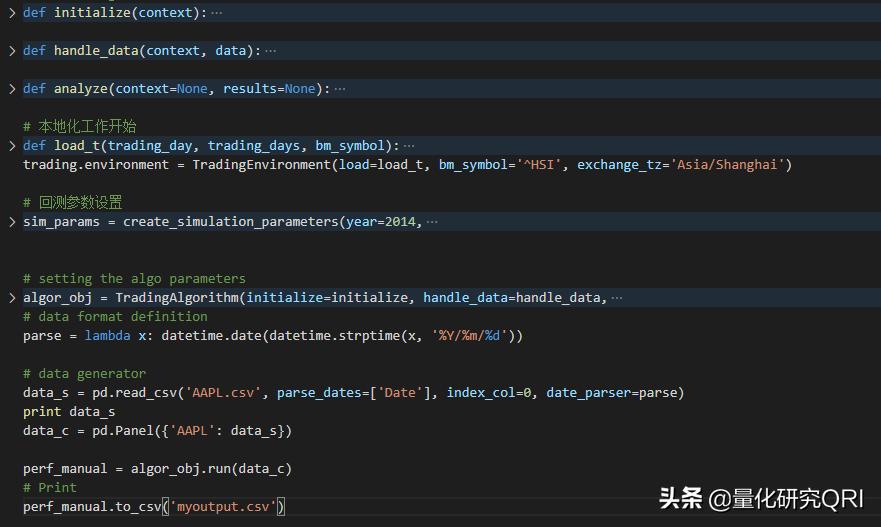
策略方面,我们先看一个简单的策略整体结构。
量化研究QRI
这里不像vnpy一样提供了详细完整的策略模板,完全是需要自己来实现完整的策略模板,对于喜欢动手的同学,可算是一个福音,可能需要踩一点坑。
从上面的整体逻辑我们可以看出,核心的模块其实在于入口函数的使用。
设置好回测参数和本地数据之后,就可以把对应的方法直接丢给TraddingAlgorithm方法来执行run方法。
上图的analyze方法主要是调用的画图工具,实现回测结构可视化。这里你可以不知道整体框架具体是怎么实现的,就可以生成一份完美的数据报告。
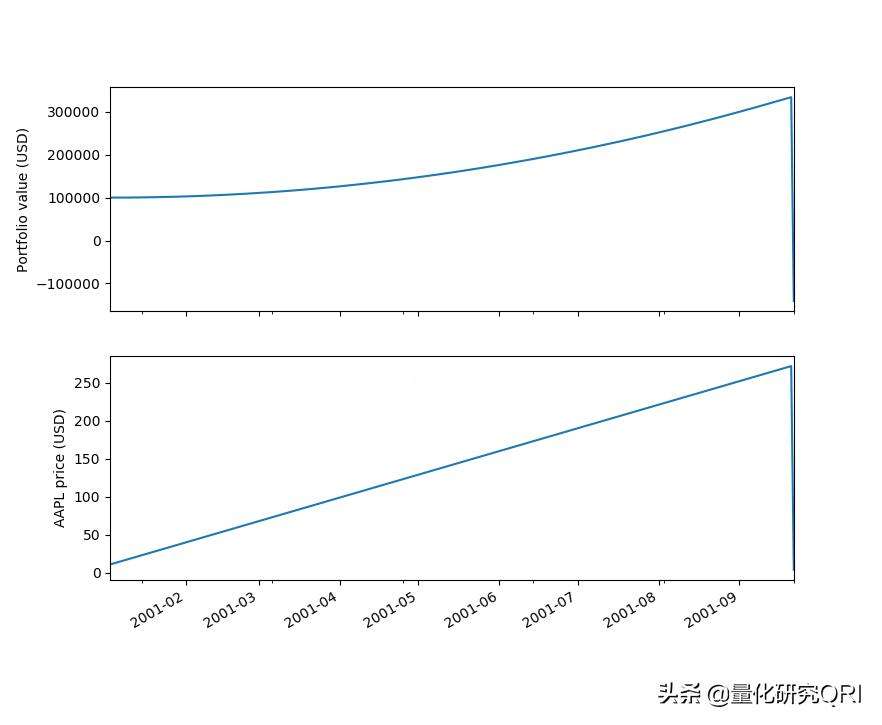
量化研究QRI
在Zipline的回测中,难度比较大的是有关 tradingcalendar的参数设置。交易日历是市场交易日的集合,提供市场交易数据的时间序列,用于交易日的判断、交易数据的时序索引。
zipline提供了NYSE(美国纽交所交易日历)、CME (芝加哥商品交易所交易日历 )、ICE(洲际交易所交易日历)、us_futures (美国期货交易日历)。很多时候,在本地回测和数据展示的时候往往会出现各种模型奇妙的错误,主要原因还是有关交易时序设置的问题,量化研究QRI也针对这种情况做了一些修改,按照国内市场的相关数据封装了适合国内市场的tradingcalendar模板,后期在讲到Zipline的教程是,可以给大家提供以下GitHub地址供大家*载下**使用。
4、风控难度
作为一个回测框架,更多的是用来做量化研究,这里实盘中可能谈不上风控了。
如果要在Zipline里面实现对应的策略风控,我想你需要自己封装一个风控模块来接管整个策略的风控。Zipline官方不提供相关的风控模块。
5、代码完整度
Zipline作为一套完整的策略研究以及回测框架,并没有在Quantopian的下架而变得消沉,依旧有很多的依旧有很多的受众群体在使用。社区依旧很完善,热度也很高。但是对于国内的朋友,可能使用起来并不是那么友好。需要改动的东西比较多,对于喜欢美国市场的朋友来说,可谓是一件辅助利器。在做策略回测的时候可以剩下不少时间。
6、二次开发难易度
对于完全开放源码的系统来说,只要你代码能力过得去,二次开发没什么问题,就算重构都没有任何问题。
7、系统性能测评
对于性能这块,我在使用的时候测了两个模式,一个是多线程,一个是多进程的模式,两种模式在整体测下来并没有太大的差别。
唯一要说的是,数据加载的时候,如果你的数据量很大,那么可能需要花费的时间就很多,再加上python本身处理能力的问题,你可能需要结合更高效的第三方库来使用。
这里推荐大量使用numpy、pandas、numba等第三方库来帮助你实现更高效的使用率。
系统资源消耗率测评
性能这块我们使用了一台Windows10系统。

量化研究QRI
系统参数如上,开了一整天跑的模拟交易,目前看来系统使用
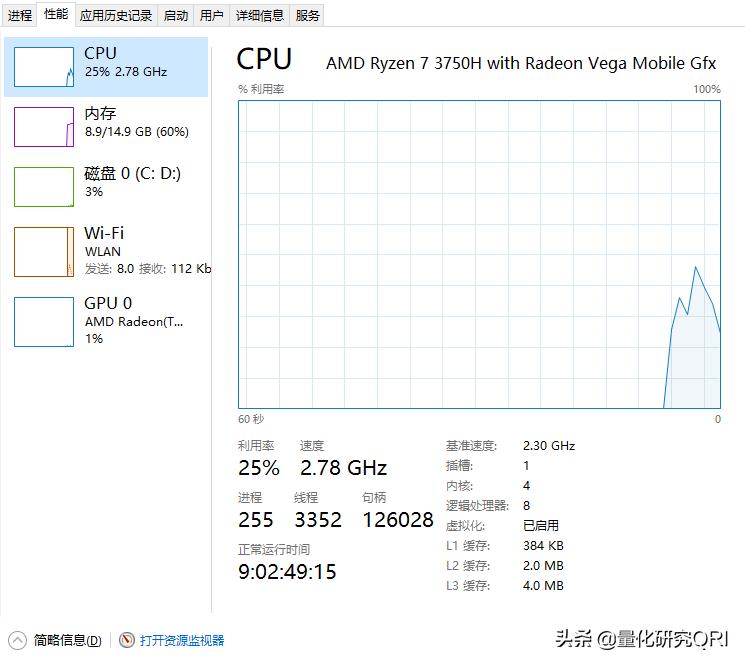
量化研究QRI
应该不算是很占用系统资源的。
最后总结:
- 针对这套回测框架,可以很方便也很容易的实现一些CTA策略,如果是高频一点的策略,这个框架可能回测的精准度有待考量。
- 针对Zipline来说,如果你有很好的代码基础,我想这可能为你剩下不少时间来帮助你搭建属于自己的策略研究平台,我其实有一天回测平台用的就是Zipline来实现的,但是我做了很多的改动,如果后期感兴趣的人比较多我考虑把这套系统开源出来。我当时结合的思路很简单,不需要很精准的回测,只针对CTA策略来说,使用一套Mongodb数据库来做底层BD存储,中间使用Spark来实现高效的数据传输,上层自己封装了Zipline来进行项目回测,其实也就是继承了Zipline重写了里面的一些方法,就很容易实现自己的回测平台。本地化之后做了JupyterLab环境隔离,这样每一个人都可以有自己独立的研究环境,互不干扰 。
- 新思路:还有一套整体使用的新思路,我目前还没有弄出来,还在研究中,就是使用Zipline去研究多因子策略,这里需要处理的是,研究平台和数据平台都是独立的微服务系统,剩下的就是如何实现多因子结果的自动化部署问题,实现自动化回测部署,直接检索提交因子,审核入库,这些步骤结合起来就是一整套完整的研究、发布、策略管理的整体逻辑。后面成功了之后可以把新思路开放出来供大家学习研究。