
什么是爬虫?
就是抓取网页数据的程序
爬虫怎么抓取网页数据?
网页三大特征:
- 网页都有自己唯一的URL。
- 网页都是HTML来描述页面信息。
- 网页都使用http/https协议来传输HTML数据。
爬虫的设计思路:
- 获取视频ID
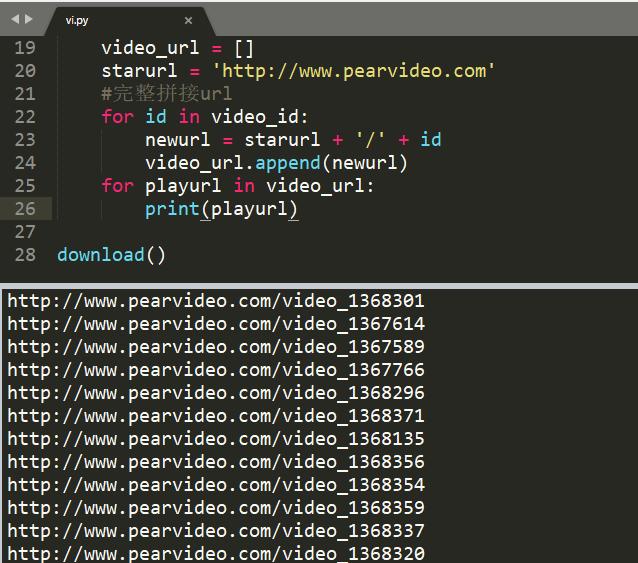
- 拼接完整url
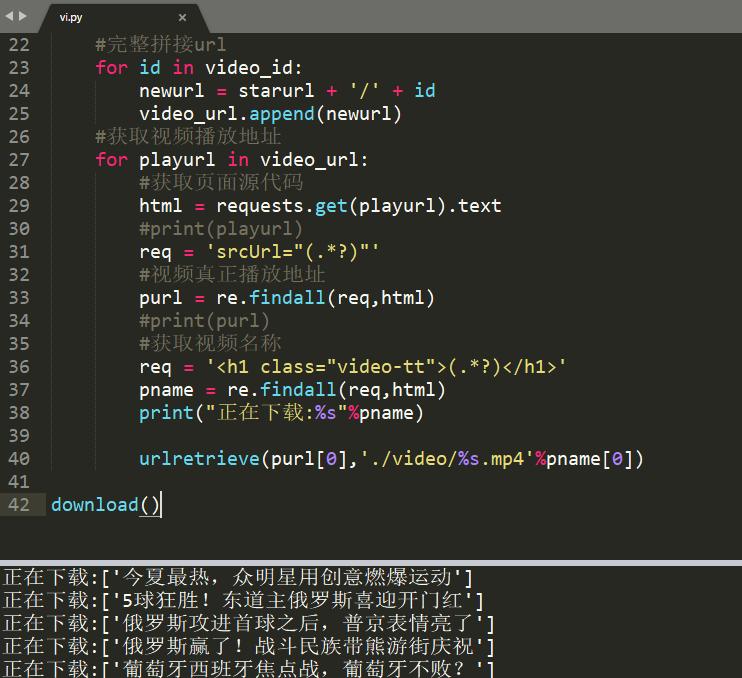
- 获取视频*放播**地址
- *载下**视频
模块使用 requests
安装“pip install requests”
Requests库的七个主要方法

找到单个视频*放播**地址
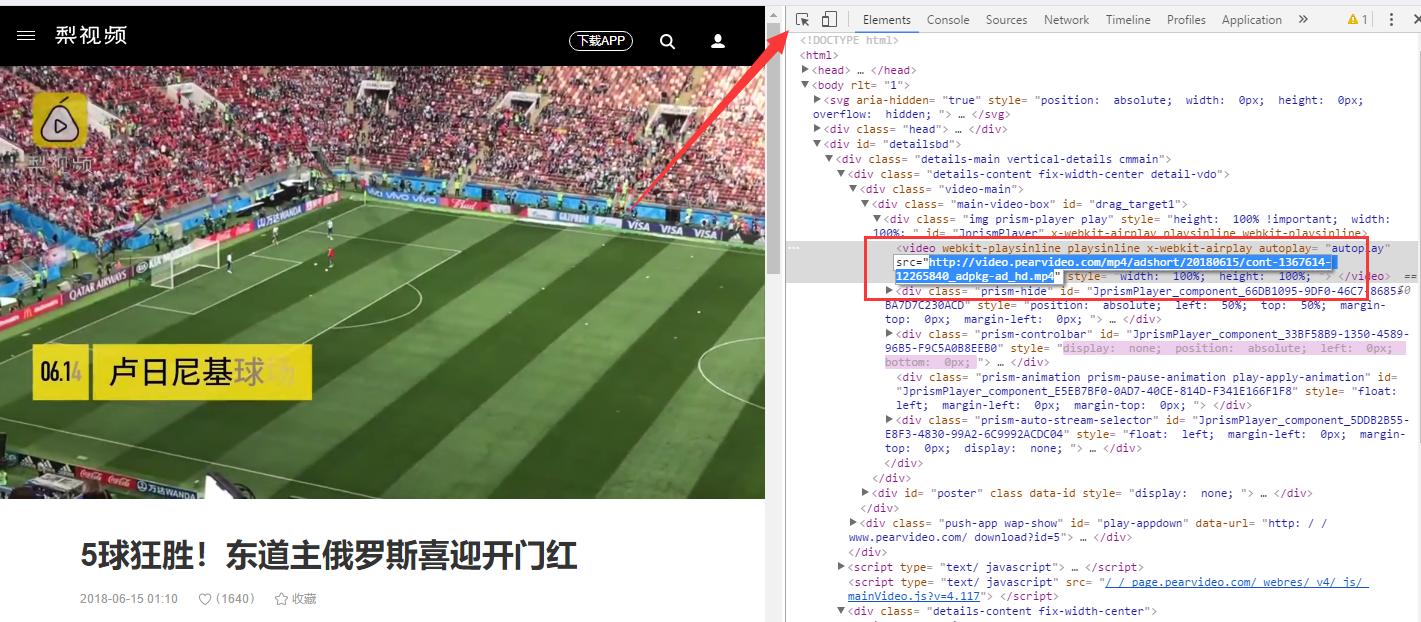
获取网页源代码
获取*放播**地址
*载下**视频
就是抓取网页数据的程序
网页三大特征:
爬虫的设计思路:
模块使用 requests
安装“pip install requests”
Requests库的七个主要方法