在日益演进的大数据领域,协作已然成为一个至关重要的支柱。随着我们迈入2024年,深入了解数据团队的协作方式和在流程中所使用的工具变得尤为重要。
数据团队本质是协作的
在几乎所有技术角色中,协作都已经成为日常职能的一部分。然而,数据团队面临着独特的需求,使得协作不仅仅是任务之一,而是深深地融入到他们的所有工作流程中。
数据团队的核心目标是追求知识。通过实验运行、原型创建和快速迭代反馈,他们从数据查询中获得洞见,最终转化为对业务利益相关者的可交付成果。这个独特的过程被称为探索性编程,它是将数据专业人员与其他技术从业者区分开的关键因素,而不是软件工程师。
探索性编程意味着许多数据专业人员每天都在不断迭代和探索未知领域,以回答之前并未有答案的问题。这也解释了为什么他们需要在团队内部以及与利益相关者之间进行协作,并且通常在整个过程中保持协同工作。
如何构建协作式数据团队
数据团队中的协作不仅仅是一种便利;还是必需品。现代数据团队如何达到实时协作在日常工作流程中占据主导地位的理想状态呢?
他们从专门为此目的构建的协作数据平台和工具开始。许多公司在建立需要协作的数据科学团队时都转向了一种这样的工具,即在线协作 Jupyter notebook。
协作在行动:协作式 Jupyter notebook
Jupyter notebook已成为协作数据分析和数据科学工作流的主要内容,但要了解为什么它们已成为数据团队内部协作的首选工具,首先必须了解它们在 未来(2024年/...)能够协作的必备功能:
- 一个统一的平台,用于查询、编码、可视化数据集,并为团队成员提供书面上下文
- 共享集成和环境,实现无缝项目协作,无需任何复杂的设置
- 实时和异步协作工具,通过内置的跟踪和版本控制确保项目的连续性,以便于协作编辑、更改跟踪和恢复以前的工作
- 多样化的共享选项,包括基于浏览器的链接、具有特定权限的项目邀请,以及将工作发布为交互式专业输出(如报告、仪表板或应用程序)的能力
- 集中式工作区作为所有数据项目的主要资源,简化了查找、存储、复制和构建团队成员工作的过程
随着团队强调实现协作编辑和在线协作,这表明对数据科学中更具互动性和包容性的工作环境的需求不断增长。这种趋势不会很快消失,基于云的Jupyter notebook越来越能满足这一需求。
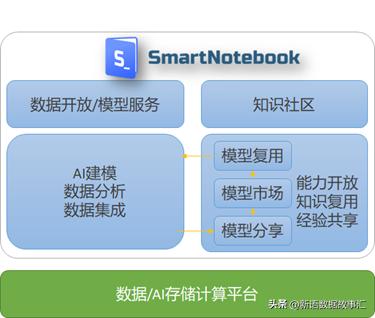
SmartNotebook是协助式、在线的、现代化notebook的数据分析/数据科学平台
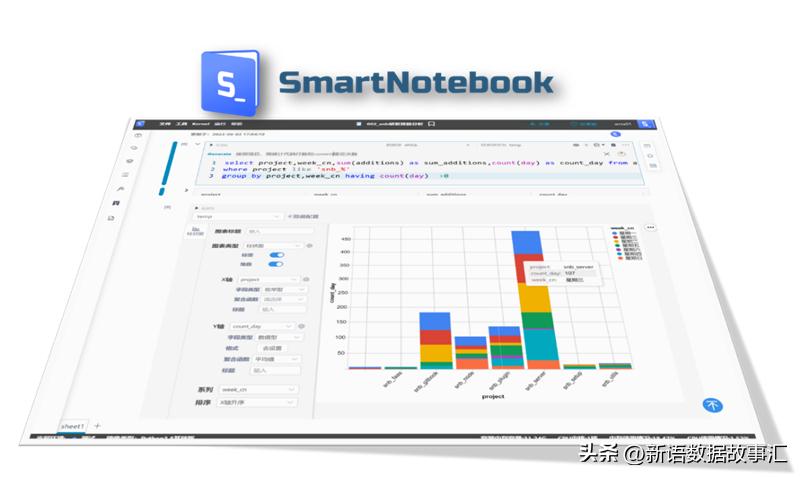
SmartNoteBook(简称:SNB)是一款现代化的Notebook工具,它是一个开箱即用、云原生、协作式的在线数据科学与数据分析、人工智能平台,是大数据和AI应用开发的一站式平台。SNB具有以下特点:
- 数据连接:SNB可以连接到各种数据形式,包括数据文件、数据库/仓库、数据湖、图数据库、数据开放平台API等。您可以轻松地获取所需的数据,无论数据存储在哪里。
- 数据分析与探索:通过SNB可以进行探索性数据分析,内置探索性数据分析的低代码组件、SQL原生支持,支持数据清洗、转换、合并、聚合等操作,深入了解数据的特征和模式。同时也可以使用Python、R等生态体系内各种强大的工具和库。
- 建立预测模型与服务API:SNB提供了机器学习和预测建模的功能。支持Scikit-learn、TensorFlow等库,建立预测模型,并将其敏捷创建为服务API(FaaS:函数即服务),供其他应用程序调用和使用。
- 支持知识图谱挖掘:SNB支持连接图数据库进行关系数据的分析、计算和挖掘,将数据之间的关系和连接进行可视化,有助于发现数据之间的隐藏模式和洞察。
- 数据可视化与报告生成:SNB提供了丰富的数据可视化功能,敏捷可视化分析和输出,用于展示和传达数据的见解和故事。
- 仪表盘与报告共享:通过SNB创建交互式的数据仪表盘和报告。可以将数据的洞察和分析结果以直观和易于理解的方式与团队或其他利益相关者共享。
- 数据智灵(人工智能AI伴侣):用户可以通过自然语言描述数据分析需求生成、编辑、bug修复和文档注释Python或SQL代码,这种方式可以帮助用户更加轻松地处理和分析数据,尤其是对于那些不熟悉编程的人员来说,使用自然语言描述数据分析需求会更加直观和方便。
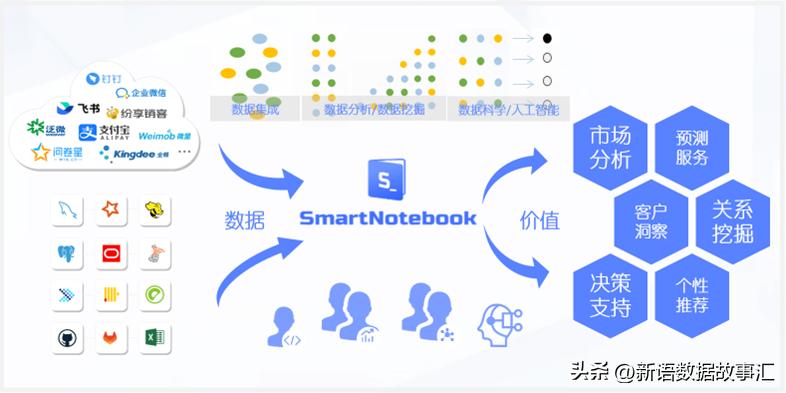
SmartNotebook 的功能列表
1.兼容jupyter notebook:支持互相转换迁移,与kaggle、AWS、Aliyun等notebook兼容。
2.支持的编程语言(kernel)
a)Python(数据科学/人工智能)、R(数据分析)、Julia(数据科学)、SageMath(数学)。
b)SQL(数据处理):Python与SQL融合、链式SQL、动态SQL
c)Cypher(知识图谱分析/挖掘):知识计算语言(Cypher) 与Python无缝融合、动态Cypher。
d)文档语言(Markdown):可视化编辑、标题、列表、图片、代码块、LaTex公式、动态Markdown等。
e)模板语言(Jinja2)(封装SQL、Cypher、MarkDown):变量替换、IF判断、循环等。
3.支持的数据源
a)数据库:MySql、Oracle、SqlServer、PostgresSQL、DuckDB…
b)数据仓库/数据湖:Greenplum、Hive、Spark、Presto、ClickHouse…
c)国产数据库:达梦、金仓、GaussDB、OceanBase…
d)云数仓:Snowflake…
e)图数据库:Neo4j…
f)其他:MindsDB(机器学习和数据联邦)。
g)文件存储:MinIO、S3、NFS…
h)可视化配置、元数据预览。
4.可视化/数据分析/数据探索
a)数据可视化组件:Matplotlib、Plotly、seaborn、pyecharts、ggplot(R语言) …
b)无代码EDA(数据探索):EDA概览、EDA分析。
c)无代码可视化图表:表格(table)(排序、分页、过滤等)、图表(chart)(柱状图、折线图、散点、面积图、饼图等)(支持汇总聚合、分箱)。
d)低代码可视化:河流图、箱线图(盒须图)、雷达图、散点色块图、热力图、桑基图、地图…
e)dfSQL:SQL化操作数据集(过滤筛选、汇总、合并等处理)。
5.仪表盘
a)支持多种布局方式、多种组件方式(富文本、Table、chart、图片、交互组件、背景)、互动的数据大屏。
b)联动、下钻等互动(开发中)。
6.数据转换
a)无代码数据透视表(类似excel 的透视表):支持行汇总、列变换、多种聚合函数(求和、均值、最大值、最小值、中位数、计数、中位数、标准差)。
b)过滤筛选组件:开发中。
7.调度
a)内置调度器:配置调度计划(月、周、日、时、分)、调度记录查看、Email通知/告警。
b)第三方调度器AirFlow:开发中
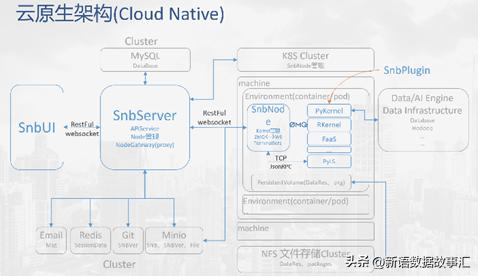
8.弹性扩展
a)容器化的Node运行环境、弹性扩展、定制化镜像。
b)Node运行环境可以对接K8S、Docker容器化服务平台。
9.协同开发/安全/管理:
a)版本管理:内置版本记录、支持提交gitHub、gitLab。
b)支持多人协同开发同一个notebook:实时交互。
c)单元格级别的评论。
d)单元格和notebook及报告在线分享。
e)代码辅助:自动补齐、函数帮助等。
f)模型视图:分析/建模过程可视化(Grap*图h**)。
g)变量配置(密保箱):配置变量、加密。
h)用户角色/权限管理:
i)终端服务:web ssh 终端(term),shell调试、环境管理。
j)辅助管理:包管理器、变量预览、元数据、代码片段库(知识库)…
k)模型市场:一模多用,模型复用、知识共享。
10.服务API
a)FaaS(Function as a Service)的框架:自由灵活的函数开发、调试和注册:单元格内置编写、调试函数、一键注册函数生成API。
b)API帮助:Swagger 化的帮助和调用调试界面。
c)支持外挂API网关,提供鉴权、授权等安全控制。
11.人工智能框架和算法
a)支持Sklearn(scikit-learn)经典机器学习框架:
i.数据预处理:降维、数据归一化、特征提取和特征转换(one-hot)…
ii.回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees…
iii.分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees…
iv.聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN…
v.降维:LinearDiscriminantAnalysis、PCA…
vi.支持PipeLine 管道。
b)支持深度学习框架:Tensorflow、Keras、Pytorch、Paddle Paddle(百度) …
c)AutoML框架支持。
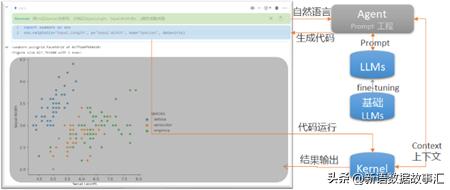
12.数据智灵(AI伴侣):大语言模型的应用辅助数据分析/数据科学
a)支持代码生成、修复bug、代码解释。
b)支持多种大语言模型(LLMs)。
c)支持prompt 模板工程、模型微调(Fine-Tuning)。
d)支持开源大模型再训练。
详细参见《SmartNoteBook产品白皮书v1.5.3.pdf》,请公众号回复“白皮书”进行*载下**。
或者百度网盘*载下**:https://pan.baidu.com/s/1XrO5vwJON9MvVUQCbJ3Xuw
提取码: 32bu
展望未来:协作数据分析/科学的未来
展望未来,轨迹很明确:数据分析/数据科学将越来越依赖协作方法。支持这种合作的平台和工具将变得更加复杂,它们的采用将大大提升数据团队的效率,成为未来的趋势。
随着我们不断突破数据科学的界限,协作的作用只会越来越大,塑造这个动态领域的未来。