
一、xdb 结构简述
为了便于了解接下来要介绍的 xdb 的生成过程,我们有必要再了解下 xdb 文件的结构分层,整个文件的数据分为如下四层:
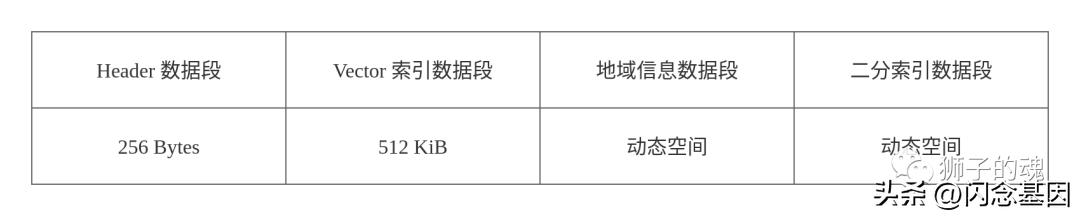
四层结构的作用分别如下:
Header 数据段 :存储例如版本号,索引指针等头信息,固定空间。
Vector 索引数据段 :二级加速索引,固定空间。
地域信息数据段 :IP 归属地地域信息数据,不固定空间。
二分索引数据段 :二分查找依赖的一级索引数据,不固定空间。
二、几个重要约定
描述过程中我会给每个核心过程配上必要的伪代码,为了伪代码的简明我们先统一如下几个约定:
1、 全部的语言层面的 API 调用都忽略错误检测和处理: 伪代码重点用于描述核心过程逻辑,错误处理细节可以阅读相关的 maker 代码。
2、 多字节的编解码全部采用小端字节序 :除非特殊注明的地方。
3、 字面数据类型统一 :uint16,uint32,int64 等等,u表示无符号,后面的数字就表示占据的位数,例如:uint32 表示 32 位的无符号整数。
三、初始化工作
初始化工作主要包括如下三个部分:
1、打开原始的 ip.merge.txt 文件和目标 xdb 二进制文件:
// 以只读模式打开 ip.merge.txt 原始输入文件
srcHandle = fopen("ip.merge.txt file path", "r")
// 以读写模式打开 xdb 二进制文件目的地址,不存在自动创建 xdb 文件
dstHandle = fopen("ip2region.xdb dst path", "rw")
2、分配 header 数据段的空间,并写入已经确定的信息,整个 header 数据段的空间结构如下:

header 数据的初始化逻辑如下:
// 将 dstHandle seek 到文件开头
dstHandle.seek(0, SEEK_SET)
// header 信息 buffer 数组,并且全部初始化为 0
var header[256] = {0}
// 从0索引处写入2个字节的版本号,此处固定为 2
writeShort(header, 0, VersionNo)
// 从2索引处写入2个字节的的缓存策略,此处固定为 1,表示采用 vector 索引
writeShort(header, 2, indexPolicy)
// 从4索引处写入4个字节的生成时间,获取当前系统时间戳
writeInt(header, 4, time.Unix())
// 从8索引处写入4个字节的二分索引开始指针地址,一开始不确定,固定写入 0
writeInt(header, 8, 0)
// 从12索引处写入4个字节的二分索引结束指针地址,一开始不确定,固定写入 0
writeInt(header, 12, 0)
// 写入整个 header 到 dstHandle 文件中
dstHandle.Write(header)
3、加载 ip.merge.txt 中的 IP 数据段并且对数据段进行必要的验证:
// 全部的 ip 数据段对象动态数组
var Segment[] segments
// 上一个 ip 段的引用
var Segment last
// 逐行读取 srcHandle 中的 ip 数据段
for s := srcHandle.lines() {
// 去掉两边可能存在的空白
var l = trim(s)
// 对读取的数据进行拆分
// ps[0] -> 开始 IP
// ps[1] -> 结束 IP
// ps[2] -> 地域信息,不做任何处理
var ps = l.SplitN("|", 3)
// 检查开始和结束 IP,确保都是合法的 IP 地址
var sip = CheckIP(ps[0])
var eip = CheckIP(ps[1])
// 开始 IP 应该 <= 结束 IP
if sip > eip {
return errorf("start ip(%s) should not be greater than end ip(%s)", ps[0], ps[1])
}
// 地域信息应该有点什么,空的算啥?
if len(ps[2]) < 1 {
return errorf("empty region info in segment line `%s`", l)
}
// 创建一个 Segment 结构体或者对象
// 这里 seg 为指针或者引用
var seg = &Segment{
StartIP: sip,
EndIP: eip,
Region: ps[2],
}
// 检查 IP 数据段的连续性
// 也就是上一行的结束 IP + 1 需要等于这行的开始 IP
if last != nil {
if last.EndIP+1 != seg.StartIP {
return errorf("discontinuous data segment: last.eip+1(%d) != seg.sip(%d, %s)", sip, eip, ps[0])
}
}
// 将得到的 IP 段对象加入到全局的 segments 动态数组中
segments.add(seg)
// 重置上一个 IP 段 last 为当前这个 Segment对象
last = seg
}
四、写入地域数据信息
完成了上面的初始化就可以开始写入地域数据了,为什么地域数据的写入是在这一步呢?vector 索引在第二层,但是他需要等到二分索引写入完成后才能确定,因为 vector 索引本身就是二分索引的索引,而二分索引在第四层,但是二分索引的结构本身需要对应 IP 段的地域信息的指针,所以我们需要先写入地域信息数据并且得到每个地域信息的指针,才能比较自然的完成不同层段的数据依赖映射。
地域信息的去重和写入逻辑如下:
// 地域信息指针 map,同时用来去重
var regionPool[string]int64
// 将 dstHandle seek 到数据段的开始位置
// HeaderInfoLength 就是 header 段的长度 - 固定 256
// VectorIndexLength 就是 vector 索引段的长度 - 固定 512KiB
dstHandle.seek(HeaderInfoLength+VectorIndexLength, SEEK_SET)
// 逐条写入初始化过程中加载的 segments 集合
for _, seg := range segments {
// 先检测下对应的地域信息是否已经写入
// 同时可以过滤已经写入了的重复地域信息
ptr, has := regionPool[seg.Region]
if has {
// 地域信息已经写入了
continue
}
// 使用 utf-8 编码地域信息字符串
var region = getUtf8Bytes(seg.Region)
// 确保 region 字节数的整个长度不超过 65535
// 也就是可以用两个字节存储其长度
if len(region) > 0xFFFF {
return errorf("too long region info `%s`: should be less than %d bytes", seg.Region, 0xFFFF)
}
// 获取当前 dstHandle 的当前的文件指针
pos = dstHandle.ftell()
// 写入 region 到 dstHandle
dstHandle.write(region)
// 记下当前地域信息写入时候的文件指针
// 这里使用 uint32 转换文件指针,也就是之保留 32 位
// 文件最大可以 4G,对于 ipv4 完全足够了
regionPool[seg.Region] = uint32(pos)
}
五、构建二分索引
上一步我们写入了地域数据并且存储对应的文件指针信息 - regionPool,有了这个数据我们就可以构建第四层的二分索引了,这一步是整个生成过程最复杂的一个过程,这个过程还需要同步构建 vector 二级索引信息,需要对本身的 IP 数据段进行二次拆分, 目的是为了使用一次固定的 IO 操作大幅度的减少二分索引的扫描范围,加速查询 ,详细的解释请阅读上一篇的 ”xdb 的查询过程“。
在生成二分索引的时候我们将利用 IP 的第一个和第二个字节来生成 vector 索引,所以要确保每个 IP 段的开始和结束 IP 的第一个和第二个字节一样,如果不一样就需要拆分成多个 IP 段,例如如下的一个 IP 数据段:
1.1.0.0|1.3.3.24|中国|广东|深圳|电信
第一个字节相同都是 1,但是第二个字节就不同了,所以这里需要拆分成如下三个 IP 段:
1.1.0.0|1.1.255.255|中国|广东|深圳|电信
1.2.0.0|1.2.255.255|中国|广东|深圳|电信
1.3.0.0|1.3.3.24|中国|广东|深圳|电信
经过拆分后的三个 IP 段的开始和结束 IP 的第一个和第二个字节都相等了,这样我们在构建二分索引的时候可以非常方便的构建 vector 二级索引。IP 数据段的二次拆分代码就不在此描述了,你可以用你自己的逻辑来实现,也可以参考默认的 maker 的实现。
二分索引项的空间结构如下:
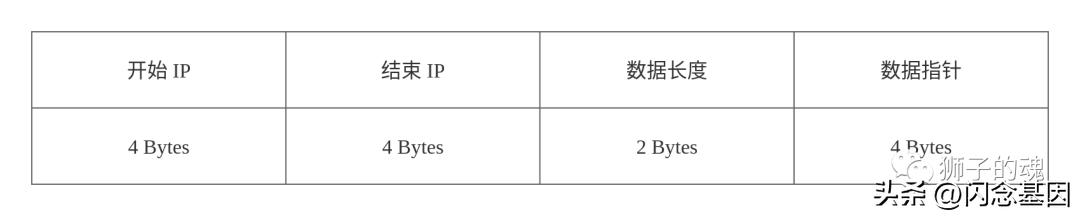
二分索引整个写入逻辑如下:
// 二分索引数据段的开始和结束文件指针值
var startIndexPtr, endIndexPtr = int64(-1), int64(-1)
// 二分索引缓冲 buffer,并且初始化为 0
var indexBuff[SegmentIndexSize] = {0}
// 遍历每一个 segment 开始生成二分索引
for _, seg := range segments {
// 获取当前地域信息的位置指针
// 这个数据是在第四步的 “写入地域信息” 记录的
ptr, has := regionPool[seg.Region]
if !has {
return errorf("missing ptr cache for region `%s`", seg.Region)
}
// 获取地域信息 utf-8 编码后的字节数
var rLen = utf8Bytes(seg.Region)
// 检测并且拆分当前数据段
var segList = seg.Split()
// 遍历拆分后的数据段进行处理
for _, s := range segList {
// 记录当前 dstHandle 文件指针位置
pos = dstHandle.ftell()
// 编码二分索引信息到 indexBuff
// 从0索引处写入4字节的开始 IP
writeInt(indexBuff, 0, s.StartIP)
// 从4索引处写入4字节的结束 IP
writeInt(indexBuff, 4, s.EndIP)
// 从8索引处写入2字节的地域信息长度
writeInt(indexBuff, 8, uint16(rLen))
// 从10索引处写入4字节的地域信息位置指针
writeInt(indexBuff[10:], ptr)
// 写入编码后的 indexBuff 到 dstHandle 文件
dstHandle.write(indexBuff)
// 更新当前 IP 段的 vector 索引信息
// @Note: 查看下面的详细介绍
setVectorIndex(s.StartIP, uint32(pos))
// 检测并且更新二分索引的开始和结束指针
endIndexPtr = pos
if startIndexPtr == -1 {
startIndexPtr = pos
}
}
}
六、写入 vector 索引信息
二分索引写入完成后,我们就可以紧接着处理 vector 二级索引了,上面的二分索引构建过程中有个 setVectorIndex 就是更新内存中的 vector 索引的位置,vectorIndex 的空间结构如下,等同于一个 256 x 256 的二位数组:
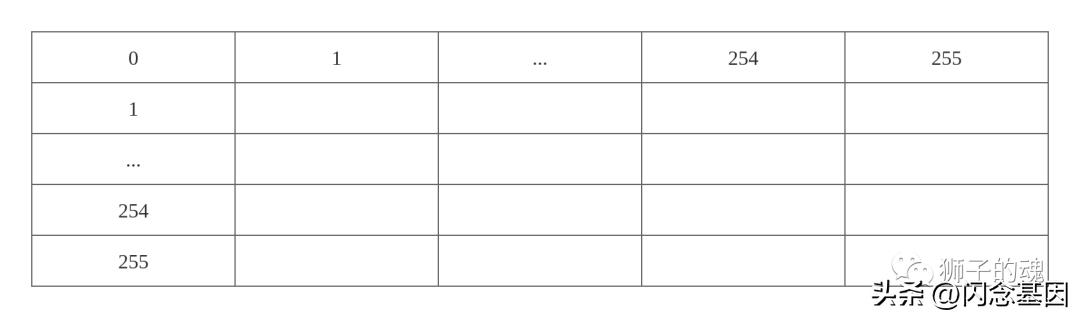
vector 索引更新函数的实现如下:
func setVectorIndex(ip uint32, ptr uint32) {
// 获取 ip 的第一个字节
var il0 = (ip >> 24) & 0xFF
// 获取 ip 的第二个字节
var il1 = (ip >> 16) & 0xFF
// 计算当前 ip 的 vector 索引的偏移量
// 等同于二位数组的 vectorIndex[il0][il1]
var idx = il0*VectorIndexCols*VectorIndexSize + il1*VectorIndexSize
// 从 idx 解码4个字节得到当前 ip 的 vector 索引信息
var sPtr = getInt(vectorIndex, idx)
if sPtr == 0 {
// 索引信息尚不存在 - 第一次更新
// 从 idx 处写入4字节的ptr信息
writeInt(vectorIndex, idx, ptr)
// 从 idx+4 处写入4字节的ptr信息
writeInt(vectorIndex, idx + 4, ptr+SegmentIndexSize)
} else {
// vector 索引信息已经存在 - 更新
// 从 idx+4 处写入4字节的ptr信息
writeInt(vectorIndex, idx+4, ptr+SegmentIndexSize)
}
}
二分索引写入完成后,就可以直接写入 vector 索引到 dstHandle 文件中,具体逻辑如下:
// 将 dstHandle seek 到 vector 索引段开始位置
dstHandle.seek(int64(HeaderInfoLength), SEEK_SET)
// 写入 vectorIndex 缓冲到 dstHandle
dstHandle.write(vectorIndex)
七、记录二分索引位置信息
最后再把二分索引写入过程中记载的二分索引段的开始和结束的指针信息写入头信息中即可,具体实现如下:
// dstHandle seek 到 8 位置 - header 信息中存储索引首地址的位置
dstHandle.seek(8, SEEK_SET)
// 编码二分索引开始和结束地址到 indexBuff
var indexBuff[8]
// 从 0 处写入4个字节的 startIndexPtr
writeInt(indexBuff, 0, uint32(startIndexPtr))
// 从 4 处写入4个字节的 endIndexPtr
writeInt(indexBuff, 4, uint32(endIndexPtr))
// 最后将 indexBuff 写入到 dstHandle
dstHandle.write(indexBuff[:8])
利用这里写入的二分索引的开始和结束位置信息也可以做完全的二分查找,也就是不基于 vector 索引的查找,查找过程自然会慢很多。
到此整个 xdb 二进制文件的生成过程就介绍完成了,详细的实现代码可以参考你熟悉的语言的 maker 实现,有问题欢迎到 ip2region 技术交流群讨论。
作者:狮子的魂
来源:微信公众号: 狮子的魂
出处:https://mp.weixin.qq.com/s/HEAc7WKzAjH5oTwgxojPUg