
全文刊载于《前瞻科技》2023年第1期"形式化方法与复杂计算系统可信保障专刊”。
文章摘要
近年来,深度神经网络已经发展成为深度学习的重要计算模型,神经网络的鲁棒性对于其在安全攸关领域的部署至关重要。因此,如何训练鲁棒的神经网络是备受学术界和工业界关注的热点问题。文章介绍了目前主流的3类鲁棒神经网络的训练方法,即基于数据增强训练、基于对抗训练和利普希茨鲁棒性训练;并介绍了其各自方法的核心思想、代表性研究工作和适用范围。同时,将近年来的鲁棒神经网络训练方法的优缺点进行比较,对应到神经网络训练的要素上进行深入分析和对照,并对各类训练方法得到的神经网络的鲁棒性的评价指标进行了介绍和比较。最后,分析了目前鲁棒神经网络训练的难点和热点,展望了该领域可能的研究方向,并提出建议。
文章速览
随着人工智能(Artificial Intelligence, AI)和深度学习(Deep Learning, DL)的不断发展,深度神经网络(Deep Neural Network, DNN)成为深度学习的重要计算模型之一,在越来越多的领域取得了突出乃至超过人类专家的表现,如自然语言处理、图像识别与检测和车辆自动驾驶等。
但是因为神经网络的黑盒性质,其行为缺少必要的形式化保证和可解释性,导致其在众多安全攸关领域的应用和部署受到极大限制,如医学图像识别与疾病诊断、国防安全与*器武**制导和无人驾驶等。在神经网络部署到这些重要领域之前,研究者需要对它们的一些关键性质进行形式化验证,以避免发生不可估量的财产或生命损失。常见的神经网络的验证性质包括可达性(Reachability)、安全性(Safety)、公平性(Fairness)和鲁棒性(Robustness)等。目前已有很多方法和工具在不同类型的神经网络上对这些性质进行了验证和评估。
鲁棒性是神经网络的一个重要性质,即网络输入在一定范围扰动时,输出依然可以保持相对稳定。神经网络的鲁棒性验证是具有重要意义的研究问题,与此相对应的,如何在训练过程中增强神经网络的鲁棒性,这也是一个新兴的重要研究领域。本文将这一问题称作“鲁棒神经网络的训练”。基于目前存在的多种主流的神经网络鲁棒性的形式化定义,将分别从数据增强、对抗训练和利普希茨鲁棒性训练3方面对鲁棒神经网络的训练方法进行阐述,比较它们的优势与不足以及相关的网络鲁棒性的评价指标,并对该领域后续的相关研究做出分析和展望。
1 神经网络训练和鲁棒性
1.1 神经网络训练过程
神经网络的训练可以理解为在一个神经网络模型(Model)上训练一个高度复杂的函数来拟合给定的训练集(Training Set),并且在测试集(Testing Set)上也能有较好的泛化能力。一般来说,训练集用于训练神经网络模型的参数,测试集则用来评估最终模型的泛化能力,但不参与参数调整的过程。一些情况下,还会在网络模型训练过程中单独划分验证集(Validation Set)来进一步调整模型的超参数以及对模型能力进行初步评估。神经网络的训练过程涉及网络模型、数据集(Data Sets)和损失函数(Loss Function),将它们称作神经网络的训练要素。
1.1.1 神经网络结构
神经网络通常由1个输入层(Input Layer),1个输出层(Output Layer)和若干隐藏层(Hidden Layer)组成。每个神经网络层都由若干神经元(Neuron)组成。输入层接收神经网络的输入,而后经过隐藏层的传播计算,在输出层输出最终的计算结果。一般地,局部的相邻的2个网络层之间通常可分解为1个仿射变换(Affine Transformation)和1个非线性激活函数(Non-linear Activation Function)。常见激活函数包括Tanh、Sigmoid和ReLU等,激活函数是定义在向量元素上的函数(Element-wise Function)。总而言之,神经网络的训练本质是不断调整网络参数的过程,使得网络模型具有较好的拟合能力和泛化能力。
1.1.2 数据集
数据集是神经网络训练的输入。在有监督学习的学习模式下,数据集的数据通常是一个二元组( x , y ),其中 x 为神经网络的输入, y 为预期得到的输出。训练过程中,算法根据训练集进行参数更新,然后在测试集上对泛化性能进行测试,判断网络的训练结果和泛化能力。测试集不参与训练过程,即测试数据不会被加入训练数据集更新网络参数,以表明网络没有出现过拟合(Overfitting)和欠拟合(Underfitting)现象。
1.1.3 损失函数
损失函数是衡量神经网络的输出与预期输出之间差距的函数,损失函数越小,说明二者之间的差距越小,即神经网络输出结果与预期输出越相近,神经网络的性能越好,反之亦然。因此,神经网络在训练过程中一般采用梯度下降法,即通过更新网络参数来追求更小的损失函数值。常见的损失函数有均方差(Mean Squared Error, MSE)损失函数,交叉熵(Cross Entropy)损失函数,折页(Hinge Loss)损失函数等。损失函数记作 ,其中acc为准确度Accuracy的缩写,因为传统的损失函数是基于网络输出的拟合能力而设计的,衡量了数据拟合的准确性。
1.2 神经网络的鲁棒性
当神经网络完成了训练过程,部署到应用领域之前,需要对网络的行为进行测试和验证,目的在于确保神经网络满足某些特定的性质,尤其是安全攸关领域。神经网络的鲁棒性是这些网络性质中备受关注的一个,其他常见的性质还有可达性、安全性、公平性等。
鲁棒性原指动态系统在一定的参数摄动下,依旧可以表现稳定。神经网络鲁棒性的概念即由此延伸而来,是指将神经网络输入样本在一定范围内扰动而产生的扰动样本作为网络的输入,神经网络依然能够表现稳定,不会因为输入样本的微小扰动而导致网络输出结果急剧变化。相应地,一般把使得神经网络输出结果发生剧烈变化的扰动样本称作对抗样本(Adversarial Sample)。
一般而言,对神经网络输入扰动形成的扰动样本可以通过集合的范数形式进行定义,常见的范数约束包括1-范数,2-范数或者无穷范数等。
根据神经网络不同的具体应用场景,鲁棒性通常有以下3种定义。
1.2.1 分类鲁棒性
分类鲁棒性(Classification Robustness)是指对实现分类任务的神经网络而言,输入样本的微小扰动不会导致神经网络的分类结果发生改变。更具体地,正确分类的样本不会因为扰动而被分到其他类别中。
1.2.2 标准鲁棒性
标准鲁棒性(Standard Robustness)是指输入样本在微小扰动下,神经网络的输出也在一个可容忍的微小范围内变化。这个微小范围一般是用户根据先验经验指定的可容忍的干扰样本输出和真实样本输出之间差距的上界。
1.2.3 利普希茨鲁棒性
利普希茨鲁棒性(Lipschitz Robustness)是基于函数的利普希茨连续性提出的,是标准鲁棒性的一种特殊形式。利普希茨连续性是函数的一种重要性质。如果一个函数是全局利普希茨连续的,那么就存在一个非负常数 L 使得函数值的变化范围在自变量的变化范围的 L 倍之内,其中最小的 L 称为该函数的利普希茨常数。在神经网络上扩展利普希茨连续性的概念,即网络在输入样本的微小扰动下,其输出也在一个微小范围内变化,相较于标准鲁棒性,输出的变化范围与输入的扰动范围之间存在常数约束。同样,满足此性质的最小非负常数 L 称为神经网络的利普希茨常数。
1.2.4 各种鲁棒性的对比与联系
针对以上各种神经网络鲁棒性的定义,表1从定义、应用场景、可解释性和满足难度4方面进行了比较。

表1 各种鲁棒性比较
由表1可以看出,分类鲁棒性在应用场景方面有较强的局限性,只适用于实现分类任务的神经网络,而标准鲁棒性和利普希茨鲁棒性则不受此限制。从可解释性方面看,分类鲁棒性和标准鲁棒性有较强的可解释性,比较符合人们对于神经网络鲁棒性的直观认识和理解,而利普希茨鲁棒性虽然是标准鲁棒性的一种特例,但是将输出的微小扰动和输入的扰动相关联,这使得它的可解释性不如前面两种。从各种鲁棒性的满足难度方面看,一般来说,分类鲁棒性最容易被满足,标准鲁棒性次之,利普希茨鲁棒性最难满足。
从定义看,这3种鲁棒性定义在表达上是相互关联的。标准鲁棒性是对分类鲁棒性一般意义上的推广,利普希茨鲁棒性则是标准鲁棒性的一种特殊形式。因此,神经网络利普希茨鲁棒性的满足在一定程度上会提升网络满足标准鲁棒性的能力,标准鲁棒性的提升也会促进神经网络满足分类鲁棒性。
1.3 神经网络的鲁棒性验证
对于训练好的神经网络,如何验证神经网络是否满足给定的鲁棒性也是极为受关注的研究方向。针对不同类型的神经网络的鲁棒性验证,目前已有众多的工作及研究方法。
基于SMT(Satisfiability Modulo Theories,可满足性模理论)/SAT(Propositional Satisfiability,命题逻辑可满足性)的验证方法是将鲁棒性编码成为逻辑公式,转换为SMT/SAT问题,通过输入已有SMT/SAT求解器得到验证问题的答案,代表性的工作是Reluplex和Planet,但是这类方法的可扩展性较差,计算效率较低,不适用于大规模神经网络的验证。
基于混合整数规划的求解方法最早是由Lomuscio和Maganti提出。通过将神经网络的运算过程编码成混合整数规划问题(Mixed Integer Linear Programming, MILP),然后计算得到网络的输出范围,进而验证其鲁棒性。这类方法使用了凸近似,因此在计算精度上略显不足。此外,混合整数规划问题的求解效率也比较低下。
基于抽象解释(Abstract Interpretation)的方法则是通过选择特定的抽象域(如区间(Interval)、多面体(Polytope)和环形胞带(Zonotope)等),设计专门的转换函数来实现激活函数表达能力的上近似,按照网络层的顺序在网络内部依次传播计算抽象域,得到输出结果的抽象域表示的上近似(Over-approximation)。典型的基于抽象解释的工具有 、DeepZ等。本文后续所述的基于验证的训练方法也是指基于抽象解释的验证方法,主要是借助于它们计算得到输出层神经元的边界估计。
2 鲁棒神经网络的训练方法
2.1 方法概述
基于各种鲁棒性的定义以及已有的网络的鲁棒性验证,产生了如何能够提高神经网络的鲁棒性的研究问题,目前主要有2个问题:①采用何种训练方法,可以使训练得到的神经网络有较强的鲁棒性;②如何通过调整训练好的神经网络的参数来提高已经训练好的神经网络的鲁棒性。本文主要关注问题①,即鲁棒神经网络的训练方法,问题②则更多涉及神经网络修复(Neural Network Repair)的研究范畴。
为了设计一种训练方法,使训练好的神经网络有更好的鲁棒性,通常会对神经网络训练过程的各个要素进行考量和改进,例如对训练过程的数据集和损失函数等进行改造。本文将从数据增强(Data Augmentation)、对抗训练和利普希茨鲁棒性训练这3方面对目前主流的鲁棒神经网络的训练方法进行阐述和总结。
2.2 基于数据增强训练
数据增强最开始是作为一种技术手段应用于神经网络的训练过程以解决过拟合问题。神经网络的训练严重依赖于大量数据去学习一个具有极为复杂的函数,以便对训练数据进行完美的建模。然而,不是所有的研究领域(如医学图像分析领域)都有如此大量的数据供训练。数据增强正是为了解决这个问题而被提出的,它可以提高训练数据集的规模和质量,从而可以使用它们构建更好的深度学习模型。在图像识别领域,增强算法包括几何变换、核滤波器、随机擦除等。这些算法提高了模型的性能,并扩展了有限的数据集。
数据增强也是一种在神经网络训练过程中提高鲁棒性的直观方法。这种方法可以自然推广应用到对输入样本的各种变换,如施加噪声、平移、旋转和缩放。为了应用这种方法在训练过程中提升网络的鲁棒性,需要在输入样本进行某种变换的区域内采集训练样本扩充训练集进行训练。常见的采样方式主要是随机采样。由此,数据增强本质上是从可能存在对抗样本的区域中采集新的训练样本对神经网络进行训练。通常采样函数随机均匀采样,也可以依据先验知识设计更好的采样函数。
2.3 基于对抗训练
基于对抗训练的鲁棒神经网络的训练方法可以分为基于攻击样本的和基于网络验证的训练方法。前者结合了数据增强和网络攻击方法,后者则主要依赖神经网络的鲁棒性验证实现。
2.3.1 基于攻击样本训练
数据增强是基于采样数据来扩充训练数据集,但是这种采样获得的数据中极少数是真正对于提升网络鲁棒性有用的数据样本,也就是对抗样本,是一种低效的训练方法。此外,通过采样的方式也不可能遍历所有可能的情况。更具体地,因为通常使用的是随机均匀采样,这种“盲目”采集到的样本绝大多数都是神经网络本来就可以正确分类的样本,产生“对抗样本”的概率很低,这对于神经网络鲁棒性的提高贡献有限。
基于此,产生了“有没有高效寻找对抗样本的方法”的问题,基于攻击样本的训练方法应运而生。这类方法的主要思想是基于反例制导(Counterexample Guided)的训练,即通过对神经网络进行某种“攻击”,得到神经网络不能正确分类的样本,也就是对抗样本,加入到训练过程中进行训练,以期在训练过程中提高神经网络的鲁棒性。目前,代表性的基于攻击样本的训练方法主要有FGSM(Fast Gradient Sign Method,快速梯度符号方法)和PGD(Projected Gradient Descent,投影梯度下降)。
FGSM通过计算损失函数 关于样本的梯度,然后沿着梯度符号所在的方向对输入样本进行小范围的扰动,获得扰动样本。将获得的扰动样本记作FGSM( x ),通过向训练集中添加扰动样本获得新的训练集,从而在训练过程中提高神经网络的鲁棒性。
PGD方法是FGSM的一种代表性的变种方法——将FGSM从一步扩展到多步攻击。PGD方法通过多步迭代FGSM获取攻击样本。PGD方法首先在给定的输入样本上添加随机噪声,然后PGD迭代FGSM攻击到达给定次数后使用新的随机噪声重启攻击过程,以提高攻击成功率。将最后一步得到的扰动样本作为攻击样本加入训练集中进行训练。这种多步迭代使得损失函数值在一定范围内变大,也就是网络越难以分辨真实的标签,因此相较于FGSM获得对抗样本的概率更大。其余FGSM方法的变种和进一步的分析可以参考文献[23-25]。
2.3.2 基于网络验证训练
虽然基于攻击样本的训练极大地提高了寻找对抗样本的效率和准确性,但是依然无法遍历所有可能的输入样本。或者说,这些方法只是添加个例样本进行训练,没有从全局考虑输入样本的扰动样本,以改进网络的鲁棒性。
基于验证的鲁棒神经网络训练方法则考虑了所有扰动样本的可能情况。基于验证训练的核心思想是构造一个新的损失函数,在最小化原有损失函数 的同时(保证性能),也考虑最小化扰动范围内的最差违背鲁棒性的可能情况 Loss robust (保证鲁棒性)。此时,损失函数通常是二者的线性组合,其中 用来刻画训练过程中神经网络的性能得到保证, Loss robust 则在训练过程中对神经网络的鲁棒性进行约束。最终的损失函数是通过系数折中考虑性能损失和鲁棒性损失。
基于边界的验证是一种典型的网络鲁棒性验证方法,会从神经网络的输入层开始传播一个输入区域到输出层,然后获得输出层各个神经元的过近似的上下界。这个上下界是对于整个输入区域的最差情况的一种保守估计。因此,在训练过程中使用这个上下界,改进最差鲁棒性违背情况,从而提高网络的鲁棒性。
DiffAI基于神经网络鲁棒性验证的思路,采用Hybrid Zonotope作为抽象域,通过设计转换函数实现对激活函数隐藏状态或输出层的上近似,进而估计所有可能的扰动样本中的最差违背鲁棒性的情况。通过这种方法可以训练得到较为鲁棒的神经网络,但是因为Hybrid Zonotope集合表示方式在实际计算中效率比较低,所以训练耗时,对于大规模的神经网络受到限制。此外,DiffAI因为网络传播计算Hybrid Zonotope抽象域的精度原因,只考虑了激活函数为ReLU的神经网络,这也使其在实际网络类型中比较受限。
为了缓解DiffAI存在的不足和限制,可以采用较为松弛的验证抽象域,也就是牺牲一部分的计算精度用以换取网络训练效率的提升,而区间就是满足此性质的较好的抽象域候选。
IBP(Interval Bound Propagation,区间边界传播)方法的核心思想是从输入边界,通过区间传播算法得到输出层神经元的输出范围,从而构建训练过程的损失函数。IBP方法首先通过扰动范围约束,确定每一个输入维度的上下界。然后根据前一层的神经元的边界,通过区间算法计算得到后一层的神经元的边界。IBP方法分别为仿射变换和激活函数设计了边界估计函数。获得输出层的边界后,分别从非真实标签神经元的上界中减去真实标签类别所对应的神经元的下界,得到最差情况的验证边界。基于此可以构造鲁棒性损失函数 Loss robust ,与准确度损失函数 的区别在于此时使用的不是网络对单个样本的输出,而是通过区间传播估计到的边界误差,然后通过构造损失函数在训练过程中更新神经网络参数。这种方法虽然在实际的神经网络鲁棒性验证中没有足够的准确度,主要是因为区间传播的计算边界比较粗糙,从而降低了精度。但是在训练神经网络时,能够快速计算出输出神经元的边界,其计算效率高,因而能够应用到大规模神经网络的鲁棒性训练。
CROWN-IBP方法是IBP算法的一种扩展,目的在于弥补IBP计算边界的粗糙,以期取得更好的训练效果。但是与IBP前向传播计算边界不同,CROWN-IBP采用了一种线性凸近似来描述神经网络的行为,借助后向边界传播方法来计算给定输入范围下输出层神经元的边界。采用前向IBP估计边界和CROWN后向估计边界的加权组合作为最终的边界估计,然后构造新的鲁棒性损失函数。因为得到了更为精确的边界估计,所以CROWN-IBP的鲁棒性损失函数也能够更准确地反映鲁棒性。实验结果也表明,CROWN-IBP在训练神经网络鲁棒性方面取得了比IBP更好的结果。
2.4 利普希茨鲁棒性训练
利普希茨鲁棒性训练方法是为了让神经网络满足利普希茨鲁棒性的训练方法。与上面两类训练方法不同,这类鲁棒性训练方法通常是对神经网络参数进行直接约束,即直接添加关于网络参数的正则化项(Regularization Term)进行训练。
LipSDP方法提出了一种对神经网络利普希茨常数进行高效估计的算法。该算法借助于非线性激活函数满足的斜率受限性质,这种性质对于多种激活函数都成立。这种斜率受限性质可以扩展为向量形式,并且改写成增量二次约束问题,文献[29]给出了网络利普希茨连续的充分条件,命名为LipSDP。基于LipSDP,Pauli等进一步完善了LipSDP问题的定义,并且设计了新的损失函数以提升神经网络的利普希茨连续性。
Gouk等利用函数的利普希茨特性提出,如果两个函数都是利普希茨连续的,那么它们的合成函数也是利普希茨连续的,且其利普希茨常数是原来两个函数的利普希茨常数的乘积。基于这个特性,文章提出对每一层在训练过程中设置阈值作为该层理想的利普希茨常数,神经网络的层数固定之后,则最终整个神经网络理想的利普希茨常数也确定了。通过在训练过程中根据原有损失函数对网络参数进行更新之后,增加投影梯度法(Projected Gradient Method, PGM)对参数进一步更新,以更好满足利普希茨鲁棒性。
3 评价指标
前文介绍了目前主流的鲁棒神经网络的训练方法,对于一个训练好的神经网络,通常借助以下指标来衡量其鲁棒性,也反映了各种鲁棒性训练方法的性能。
3.1 用户-对抗样本存在性
用户-对抗样本存在性(User-Adversarial Existence, UAE)是指用户在实际使用神经网络时遇到对抗样本的可能性。对一个神经网络而言,如果用户-对抗样本存在性指标数值越高,那么它的鲁棒性越差。
3.2 攻击样本存在性
攻击样本存在性(Attack Sample Existence, ASE)指标是指对于训练好的神经网络,攻击算法成功找到一个对抗样本的概率。对一个神经网络而言,攻击样本存在性指标越高,它的鲁棒性越差。
3.3 可验证性
与前两个指标相比,可验证性(Verifiable Proportion, VP)指标没有那么直接。可验证性是指对于已训练好的网络,对于训练集中的样本,已有的验证方法能够验证鲁棒性成立的样本的比例(通常会给定验证时间)。对一个神经网络而言,可验证性指标越高,很大程度上其鲁棒性也越高,可验证性指标提供了一个网络鲁棒性的评估下界。
4 各种训练方法比较
基于各种鲁棒神经网络的训练方法和评价指标,以下对各种训练方法的优缺点以及它们之间的区别和联系进行介绍。
4.1 区别
表2从核心思想、训练要素、适用性和实际效果4方面比较了各种鲁棒神经网络训练方法之间的区别,简要给出了各种方法的评价。
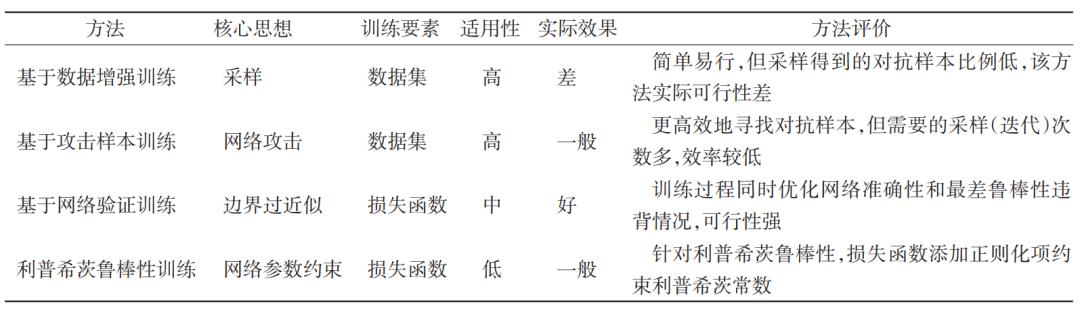
表2 各种鲁棒神经网络训练方法比较
基于数据增强训练的核心思想是通过采样来扩充训练数据集,可以适用于各种神经网络鲁棒性定义,但是扩充的数据集中真正是对抗样本的比例很小,因此算法效率不能得到保证,在实际训练网络过程中不具备太大的可行性和实用性。
基于攻击样本训练是从攻击神经网络的角度出发来提高采样中对抗样本的比例,适用于各种鲁棒性定义。因为从攻击角度出发,所以数据集扩充采样的目标更为明确,找到对抗样本的可能性也更高,效率得到保证,应用到训练过程中也更容易改进神经网络的鲁棒性。
基于网络验证训练的核心思想在于验证过程(算法)中提供的输入范围的最差违反鲁棒性情况,然后在训练过程中同时优化鲁棒性损失函数。此类算法避免了采样的低效率和随机性,但是因为训练过程要求损失函数的可微性,所以其适用性一般。目前看来,应用基于网络验证的训练方法,对鲁棒性的提升效果最好。
利普希茨鲁棒性训练方法则主要是针对提升利普希茨鲁棒性而设计的,因此其适用范围最小。并且,由于神经网络的利普希茨属性本身在保证网络性能的前提下不容易满足,因此采用这种方法对利普希茨鲁棒性的提升效果不明显。
4.2 联系
从各种方法考虑的网络训练要素看,基于数据增强的训练方法和基于攻击样本的训练方法都是扩充训练数据集。因此,基于攻击样本的训练方法也可以被看作数据增强的一种特例——它采用了更有效的采样方式的数据增强。而基于网络验证的训练方法和利普希茨鲁棒性训练方法都是针对损失函数进行修改,但前者是增加神经网络鲁棒性损失项来优化网络参数更新过程,后者则一般是直接增加约束参数的正则化项。
从鲁棒性之间的联系看,因为利普希茨连续性是一种特殊的标准鲁棒性,因此利普希茨训练方法理论上也一定程度改进了神经网络的标准鲁棒性,但实际训练效果一般。同样,标准鲁棒性是相较于分类鲁棒性更为普遍的定义。因此,改进标准鲁棒性的训练方法也同时提高了网络模型的分类鲁棒性。
另外,目前各种鲁棒神经网络训练方法的分类也不唯一。例如,基于攻击样本的训练方法既可以认为是一种特殊的数据增强方法,也可以认为是基于对抗训练的方法,本文采用的是后者。
5 研究难点及建议
经过最近几年在鲁棒神经网络训练方面的研究工作,在训练过程中提高神经网络的鲁棒性已经取得了显著的进展。但该领域的相关工作主要是国外的研究成果,国内相关研究比较缺乏,根据目前该领域的研究进展,仍然存在以下主要难点和研究前景。
5.1 一个统一的鲁棒性框架
目前存在多种鲁棒性的定义,包括但不限于文中列举的几种,这导致已有的训练方法的适用范围存在局限。此外,Leino等也形式化了一个全局鲁棒性(Global Robustness)的概念,它捕获了在线的局部鲁棒性的操作属性,同时为鲁棒网络训练提供了一个自然的训练目标。他们通过将有效的全局利普希茨边界纳入网络,构造产生可靠的鲁棒模型。Singh等针对图像数据集提出了几何鲁棒性的定义(图像的旋转、缩放等)并给出了神经网络中此类鲁棒性的验证思路,但几何鲁棒的神经网络的训练方法依然是缺少的。
对于各种形式的神经网络鲁棒性定义,如何基于已有鲁棒性的定义,在构建一个统一的鲁棒性定义框架的基础上,进一步研究发展通用的鲁棒神经网络训练方法是未来值得研究的一个关键问题。这种统一的鲁棒性可以是某种形式上的统一定义,具体鲁棒性是统一定义的特殊形式,在这种统一的鲁棒性框架指导下,鲁棒神经网络训练方法的普适性将更强,也更有助于从理论上指导鲁棒神经网络的训练。
5.2 鲁棒的神经网络结构
目前已有的鲁棒神经网络的训练方法或关注训练样本(数据集),或关注损失函数的构造(或在损失函数中添加正则项)。结合本文提及的网络训练要素,能否设计某种神经网络结构,使得该种网络结构相较于已有的神经网络结构,能够在训练过程中更容易满足鲁棒性,是一个值得讨论的问题。
之前的一些研究工作涉及了鲁棒的神经网络结构,更系统的工作是香港中文大学多媒体实验室尝试从神经网络结构的角度全面分析、理解神经网络的鲁棒性。该实验室基于One-shot NAS方法搜索并设计了一系列鲁棒的神经网络结构,命名为RobNets。在CIFAR、SVHN、Tiny-ImageNet和Image等数据集上的实验表明了RobNets相比于其他广泛使用的网络结构,在对抗攻击下具有更好的鲁棒性。文献[37]也揭示了一些有价值的观察结果。例如,密集连接的神经网络模型鲁棒性更高,在存储受限的情况下,卷积运算添加到直连边对于提高鲁棒性更有效。
总体来看,鲁棒的神经网络结构是较少研究的领域,目前已有的工作更多的还是基于神经网络结构搜索开展的,虽然提供了一些有意义的观测现象,但是对神经网络结构和网络鲁棒性的理论分析和理解的研究是缺乏的,这也是目前亟待研究的问题。
5.3 训练与验证的相互促进
虽然鲁棒神经网络的训练和验证看上去是矛盾的,但是事实上二者却是相互促进的。更精确的验证技巧可能催生更有效的训练方法,更有效的训练方法也极有可能提升验证的精度和效率。因此,后续的研究中,从相互促进的角度改进鲁棒神经网络的训练方法也是一个值得深入探索的问题。
在目前已有的研究工作中,研究者更多关注的是如何训练易于验证(即验证友好)的鲁棒神经网络。美国麻省理工大学团队基于网络验证探索了协同设计的概念,具体目标是训练的神经网络不仅对对抗性扰动具有鲁棒性,而且其鲁棒性可以更容易验证。为此,该团队确定了网络模型的两个关键属性——权值稀疏性和ReLU稳定性。文献[40]证明了仅改善权值稀疏性就已经使计算上难以解决的验证问题变成可处理的问题,而提高ReLU稳定性可以使验证速度得到极大提升。此外,这种方法可以对众多验证方法都是兼容的。类似的概念也应用在文献[41]中,以训练可验证的神经网络满足某些期望的输入-输出属性(如鲁棒性)。核心思想是同时训练两个网络:一个是执行目前任务的预测器网络;另一个是验证器网络,用于计算预测器网络满足被验证属性的程度。这两个网络可以同时训练,以优化数据拟合损失和限制最大违反属性的项的加权组合。
在神经网络训练和验证相互促进的研究中,目前研究者更多关注的是设计新的训练方法以提升网络验证的效率,而验证方法对于训练的指导作用的相关研究相比显得不足。前文介绍的IBP和CROWN-IBP就是网络验证方法应用于网络训练过程的代表性工作,如何将众多的更加复杂精确的网络验证方法高效地应用于网络鲁棒性训练过程,是下一步研究的重要挑战。
5.4 实验效果到实际应用的跨越
目前,鲁棒神经网络的训练方法主要以学术性实验研究为主,因此实验采用的数据集比较简单(如MNIST手写数字数据集、CIFAR-10彩*图色**像数据集等),训练的神经网络与实际工程中应用的神经网络在规模上仍有差距。鲁棒性训练方法在实际工程所使用的神经网络中依然是缺位的。因此,下一步的研究也应当更加关注如何将实验的显著效果复现到实际应用中。毕竟,提升实际使用网络的鲁棒性是该领域学术研究的终极目标。
为了尽快将学术成果应用到实际的神经网络中,可以首先将目前成熟的鲁棒性神经网络训练方法应用到一般的实际网络中(网络应用场景安全性要求不高),技术成熟之后,逐渐应用到安全性要求较高的领域中,进一步完善训练方法。
6 结束语
神经网络日益成为深度学习中的主要计算模型,在越来越多的领域中取得了卓越表现。神经网络因其固有的黑盒特性,即在网络行为上缺乏必要的可解释性和安全保证,阻碍了它们在安全攸关领域的应用。鲁棒性则是衡量神经网络行为可靠的重要指标之一,描述了当神经网络的输入在一定范围内扰动时,神经网络的输出不会发生急剧变化,其行为依旧可信。
一方面,研究者提出了大量的关于神经网络的鲁棒性验证的方法和工具,取得了不错的验证精度;另一方面,如何训练鲁棒的神经网络也是重要的研究方向。本文对已有的鲁棒神经网络的验证方法进行了阐述,主要包括基于数据增强训练、基于对抗训练和利普希茨鲁棒性训练,列出了主要的神经网络鲁棒性评价指标,并且对已有方法的优缺点进行了比较。最后,给出了目前该研究领域的研究热点与难点。
END
关于本刊
《前瞻科技》是由中国科学技术协会主管,科技导报社主办、出版的科技智库型自然科学综合类学术期刊,于2022年创刊。
办刊宗旨:围绕国家重大战略任务、科技前沿重要领域和关键核心技术,刊载相关研究成果的综述和述评,促进学术交流,推动科技进步,服务我国经济社会高质量发展。
常设栏目有“前瞻”“综述与述评”“聚焦”“论坛”“文化”“书评”等,其中“前瞻”“综述与述评”为固定栏目,其他为非固定栏目。
期刊官网:www.qianzhankeji.cn