1、背景:
通过python实现爬取罪全书(十宗罪前传) 的所有章节的内容,并按照章节.txt的格式保存到本地文件夹里。https://www.kanunu8.com/book/4609/
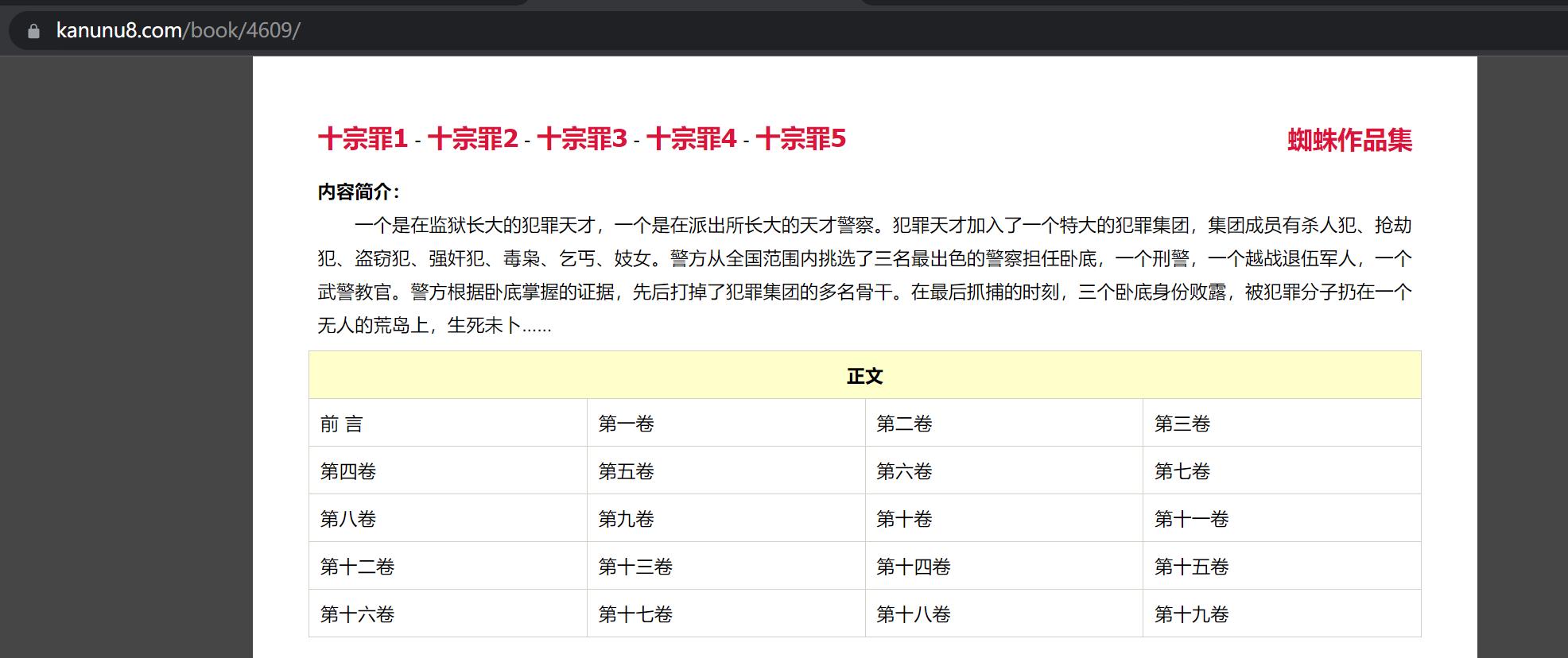
2、实现步骤:
(1)先抓取十宗罪前传中各个章节的URL地址;
(2)根据URL地址再去抓取每个URL地址下的章节内容;
(3)将章节内容保存到本地txt文件里;
3、关键技术:
python、requests、正则表达式、文件读取
4、代码实现:
############## 3、爬取 罪全书(十宗罪前传) 的所有章节的内容,并按照章节保存到本地文件夹里
import requests
import re
urlbase = "https://www.kanunu8.com/book/4609/"
filepath = "C:\\Users\\fangel\\Desktop\\2022年代码\\十宗罪前传\\"
############ 步骤1:先要抓取各个章节的URL地址,加上urlbase拼成完整的URL地址
html = requests.get(url=urlbase)
#先抓取各个链接所在的大的片段
firstRE = re.findall(r'正文(.*?)</tbody>', str(html.content.decode("GBK")), re.S)
#再从结果中抓取每个章节的链接,并保存到列表里
#charterURL是抓取章节的URL,charterName是抓取章节的编号:第一卷,第二卷
charterList = []
charterNameList = []
charterURL = re.findall('<a href="(.*?)">', str(firstRE), re.S)
charterName = re.findall('.html">(.*?)</a></td>', str(firstRE), re.S)
#最后加上url基线地址拼成完成的URL链接
#i的作用是抓取章节的标题是第几章节,后续按照这个来保存文件
i = 0
for url in charterURL:
charterList.append(urlbase + url)
charterNameList.append(charterName[i])
i = i + 1
############ 步骤2:访问各个章节的内容,并保存到文件里
i = 0
for url in charterList:
html = requests.get(url=url)
firstContent = re.findall(r'<td width="820"(.*?)</td>', str(html.content.decode("GBK")), re.S)
secondContent = re.findall(r'<p>(.*?)</p>', str(firstContent), re.S)[0]
# 为了消除掉:<br />\r\n<br />\r\n\u3000\u3000。但是发现只消除了<br />
secondContent = secondContent.strip("").strip('\r\n').replace(u'\u3000', '').replace("<br />", "")
fileName = filepath+str(charterNameList[i])+".txt"
with open(file=fileName, mode="w", encoding="gbk") as f:
f.write(secondContent)
i = i + 1
5、运行结果:
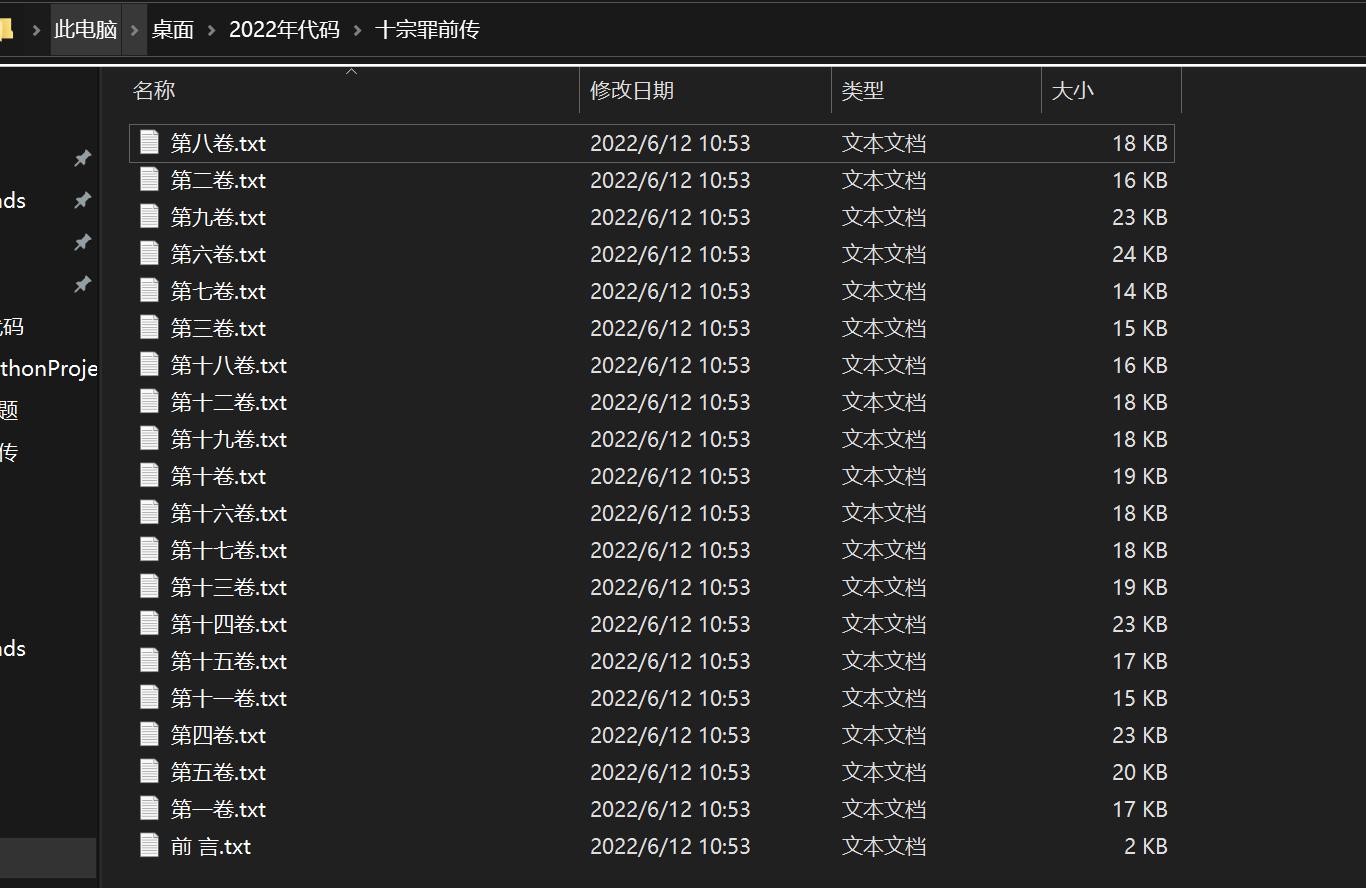
但是发现虽然代码里处理了\r\n\u3000\u3000的标记,但是如下实际的爬取结果里仍然有这些标记,待继续研究消除方法。
# 为了消除掉:<br />\r\n<br />\r\n\u3000\u3000。但是发现只消除了<br />
secondContent = secondContent.strip("").strip('\r\n').replace(u'\u3000', '').replace("<br />", "")

补:
晚上继续研究了一番,发现如下的代码改成下面的形式就可以了
secondContent = str(secondContent).replace('\\r','').replace('\\n','\n').replace(u'\\u3000', u'').replace("<br />", "")
需要用到\\来进行转义,对于回车\\n不能repalce成'',否则整篇小说就没有回车换行了,运行后爬取到的页面如下所示:
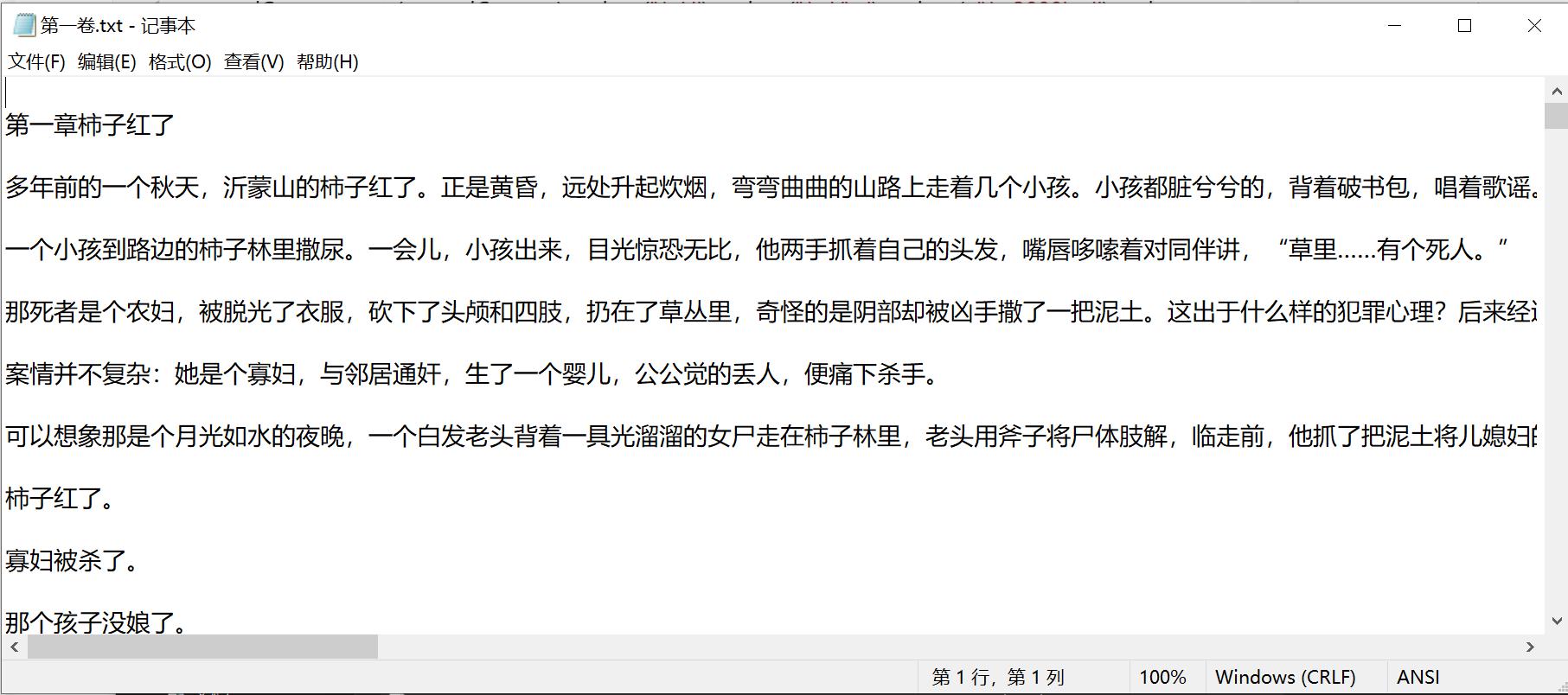
搞定!!!Nice!!!