爬取豆瓣电影的信息。
关注后私信小编 PDF领取十套电子文档书籍
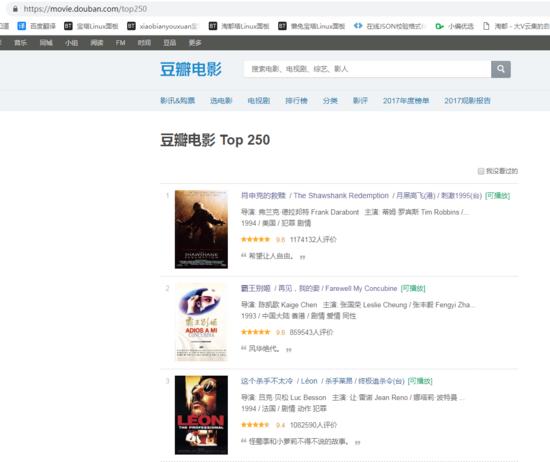
1,首先找一些代理用户代理(user_agent)
self.user_agent = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", ] 复制代码
2.找了一个获取代理ip的网址
www.kuaidaili.com/ops/proxyli…
3.测试代理ip是否有效的网址
'http://icanhazip.com'
4.下面代码是爬取信息所用的时间。
# 计算运行所需的时间
def run_time(func):
def wrapper(*args, **kw):
start = time.time()
func(*args, **kw)
end = time.time()
print('running', end-start, 's')
return wrapper
复制代码
5.定义一些常量
def __init__(self):
# 豆瓣链接
self.start_url = 'https://movie.douban.com/top250'
# 获取代理IP链接,不能确保代理ip真实可用
self.getProxy = 'http://www.xicidaili.com/nn/1/'
# 测试代理IP是否代理成功
self.testIP = 'http://icanhazip.com'
# 爬取豆瓣信息的队列
self.qurl = Queue()
# 爬取代理ip信息的队列
self.IPQurl = Queue()
self.data = list()
self.item_num = 5 # 限制每页提取个数(也决定了二级页面数量)防止对网页请求过多
self.thread_num = 10 # 抓取二级页面线程数量
self.first_running = True
# 设置代理ip
self.proxy = {}
# 设置获取代理ip的代理ip
self.proxy1 = {}
# 不设置代理ip
self.notproxy = {}
self.user_agent = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
复制代码
6.爬取代理ip的信息放入队列里,方便爬取豆瓣信息时获取。
def get_proxy(self):
url = self.getProxy
try:
# random.choice(self.user_agent)是随机获取一个用户代理。
# 因为免费的代理ip不稳定所以这里设置self.notproxy,如果稳定的话就换成self.proxy1
r = requests.get(url, headers={'User-Agent': random.choice(self.user_agent)}, proxies=self.notproxy,verify=False,timeout=1)
r.encoding = 'utf-8'
if (r.status_code == 200):
soup = BeautifulSoup(r.content, 'html.parser')
ip_list = soup.find_all('table', id='ip_list')
if(len(ip_list)):
tr_list = ip_list[0].find_all('tr')[1:10]
for i in tr_list:
td_list = i.find_all('td')
temp = td_list[5].text + ',' + td_list[1].text + ':' +td_list[2].text
self.IPQurl.put(temp)
return True
else:
print('页面查询不到该id')
return False
else:
print('无法获取代理ip')
return False
except Exception as e:
print('获取代理ip出错--',str(e))
return False
7.设置代理ip的值
def set_proxy(self):
if self.IPQurl.empty():
if self.get_proxy():
arr = self.IPQurl.get().split(',')
arr1 = self.IPQurl.get().split(',')
if arr[0].find('HTTPS') == -1:
self.proxy = {arr[0].lower(): 'http://'+arr[1]}
else:
self.proxy = {arr[0].lower(): 'https://'+arr[1]}
if arr1[0].find('HTTPS') == -1:
self.proxy1 = {arr1[0].lower(): 'http://'+arr1[1]}
else:
self.proxy1 = {arr1[0].lower(): 'https://'+arr1[1]}
else:
self.proxy = {}
self.proxy1 = {}
else:
arr = self.IPQurl.get().split(',')
if arr[0].find('HTTPS') == -1:
self.proxy = {arr[0].lower(): 'http://' + arr[1]}
else:
self.proxy = {arr[0].lower(): 'http://' + arr[1]}
8.开始爬取豆瓣top250数据的链接。
def parse_first(self, url):
print('crawling,parse_first', url)
self.set_proxy()
try:
# 因为免费的代理ip不稳定所以这里设置self.notproxy,如果稳定的话就换成self.proxy
r = requests.get(url, headers={'User-Agent': random.choice(self.user_agent)},proxies=self.notproxy,verify=False,timeout=5)
r.encoding = 'utf-8'
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
# 每一页爬数据条数
movies = soup.find_all('div', class_='info')[:self.item_num]
for movie in movies:
url = movie.find('div', class_='hd').a['href']
self.qurl.put(url)
nextpage = soup.find('span', class_='next').a
if nextpage:
nexturl = self.start_url + nextpage['href']
self.parse_first(nexturl)
else:
self.first_running = False
else:
print('ip被屏蔽')
self.proxy = {}
self.proxy1 = {}
self.first_running = False
except Exception as e:
self.proxy = {}
self.proxy1 = {}
self.first_running = False
print('代理ip代理失败--',str(e))
9.是时候爬取真正的信息了,爬取的信息写入数组里面。
def parse_second(self):
# 停止触发的条件是self.first_running = False和self.qurl为空。
while self.first_running or not self.qurl.empty():
if not self.qurl.empty():
url = self.qurl.get()
print('crawling,parse_second', url)
self.set_proxy()
try:
r = requests.get(url,headers={'User-Agent': random.choice(self.user_agent)},proxies=self.notproxy,verify=False,timeout=5)
r.encoding = 'utf-8'
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
mydict = {}
mydict['url'] = url
title = soup.find('span', property = 'v:itemreviewed')
mydict['title'] = title.text if title else None
duration = soup.find('span', property = 'v:runtime')
mydict['duration'] = duration.text if duration else None
addtime = soup.find('span', property = 'v:initialReleaseDate')
mydict['addtime'] = addtime.text if addtime else None
average = soup.find('strong', property = 'v:average')
mydict['average'] = average.text if average else None
imgSrc = soup.find_all('div', id='mainpic')[0].img['src']
mydict['imgSrc'] = imgSrc if imgSrc else None
mydict['play'] = []
ul = soup.find_all('ul', class_='bs')
if len(ul):
li = ul[0].find_all('li')
for i in li:
obj = {
'url':urllib.parse.unquote(i.a['href'].replace('https://www.douban.com/link2/?url=','')),
'text':i.a.text.replace(' ', '').replace('\n','')
}
mydict['play'].append(obj)
self.data.append(mydict)
# 线程随机休眠
time.sleep(random.random() * 5)
else:
print('ip被屏蔽')
except Exception as e:
self.proxy = {}
self.proxy1 = {}
print('代理ip代理失败2--',str(e))
10.真正要运行的函数是这里。
#这个是函数运行完所需要的时间
@run_time
def run(self):
ths = []
th1 = Thread(target=self.parse_first, args=(self.start_url, ))
th1.start()
ths.append(th1)
for _ in range(self.thread_num):
th = Thread(target=self.parse_second,)
th.setDaemon(True)
th.start()
ths.append(th)
for th in ths:
# 等待线程终止
th.join()
s = json.dumps(self.data, ensure_ascii=False, indent=4)
with open('top250.json', 'w', encoding='utf-8') as f:
f.write(s)
print('Data crawling is finished.')
11.开始运行啦。
if __name__ == '__main__': Spider().run()
12.最后运行完啦。这里只爬取了50条数据,用了20秒。
爬取出来的数据格式是这样子的。

13.最后附上所有代码,希望能帮到你。
import time
import json
import random
import logging
import requests
import urllib.parse
from queue import Queue
from threading import Thread
from bs4 import BeautifulSoup
logging.captureWarnings(True)
# 爬豆瓣电影 Top 250
# 计算运行所需的时间
def run_time(func):
def wrapper(*args, **kw):
start = time.time()
func(*args, **kw)
end = time.time()
print('running', end-start, 's')
return wrapper
class Spider():
def __init__(self):
self.start_url = 'https://movie.douban.com/top250'
# 获取代理IP链接,不能确保代理ip真实可用
self.getProxy = 'http://www.xicidaili.com/nn/1/'
# 测试代理IP是否代理成功
self.testIP = 'http://icanhazip.com'
self.qurl = Queue()
self.IPQurl = Queue()
self.data = list()
self.item_num = 5 # 限制每页提取个数(也决定了二级页面数量)防止对网页请求过多
self.thread_num = 10 # 抓取二级页面线程数量
self.first_running = True
# 设置代理ip
self.proxy = {}
# 设置获取代理ip的代理ip
self.proxy1 = {}
# 不设置代理ip
self.notproxy = {}
self.user_agent = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
def get_proxy(self):
url = self.getProxy
try:
r = requests.get(url, headers={'User-Agent': random.choice(self.user_agent)}, proxies=self.notproxy,verify=False,timeout=1)
r.encoding = 'utf-8'
if (r.status_code == 200):
soup = BeautifulSoup(r.content, 'html.parser')
ip_list = soup.find_all('table', id='ip_list')
if(len(ip_list)):
tr_list = ip_list[0].find_all('tr')[1:10]
for i in tr_list:
td_list = i.find_all('td')
temp = td_list[5].text + ',' + td_list[1].text + ':' +td_list[2].text
self.IPQurl.put(temp)
return True
else:
print('页面查询不到该id')
return False
else:
print('无法获取代理ip')
return False
except Exception as e:
print('获取代理ip出错--',str(e))
return False
def set_proxy(self):
if self.IPQurl.empty():
if self.get_proxy():
arr = self.IPQurl.get().split(',')
arr1 = self.IPQurl.get().split(',')
if arr[0].find('HTTPS') == -1:
self.proxy = {arr[0].lower(): 'http://'+arr[1]}
else:
self.proxy = {arr[0].lower(): 'https://'+arr[1]}
if arr1[0].find('HTTPS') == -1:
self.proxy1 = {arr1[0].lower(): 'http://'+arr1[1]}
else:
self.proxy1 = {arr1[0].lower(): 'https://'+arr1[1]}
else:
self.proxy = {}
self.proxy1 = {}
else:
arr = self.IPQurl.get().split(',')
if arr[0].find('HTTPS') == -1:
self.proxy = {arr[0].lower(): 'http://' + arr[1]}
else:
self.proxy = {arr[0].lower(): 'http://' + arr[1]}
def parse_first(self, url):
print('crawling,parse_first', url)
self.set_proxy()
try:
r = requests.get(url, headers={'User-Agent': random.choice(self.user_agent)},proxies=self.notproxy,verify=False,timeout=5)
r.encoding = 'utf-8'
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
# 每一页爬数据条数
movies = soup.find_all('div', class_='info')[:self.item_num]
for movie in movies:
url = movie.find('div', class_='hd').a['href']
self.qurl.put(url)
nextpage = soup.find('span', class_='next').a
if nextpage:
nexturl = self.start_url + nextpage['href']
self.parse_first(nexturl)
else:
self.first_running = False
else:
print('ip被屏蔽')
self.proxy = {}
self.proxy1 = {}
self.first_running = False
except Exception as e:
self.proxy = {}
self.proxy1 = {}
self.first_running = False
print('代理ip代理失败--',str(e))
def parse_second(self):
while self.first_running or not self.qurl.empty():
if not self.qurl.empty():
url = self.qurl.get()
print('crawling,parse_second', url)
self.set_proxy()
try:
r = requests.get(url,headers={'User-Agent': random.choice(self.user_agent)},proxies=self.notproxy,verify=False,timeout=5)
r.encoding = 'utf-8'
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
mydict = {}
mydict['url'] = url
title = soup.find('span', property = 'v:itemreviewed')
mydict['title'] = title.text if title else None
duration = soup.find('span', property = 'v:runtime')
mydict['duration'] = duration.text if duration else None
addtime = soup.find('span', property = 'v:initialReleaseDate')
mydict['addtime'] = addtime.text if addtime else None
average = soup.find('strong', property = 'v:average')
mydict['average'] = average.text if average else None
imgSrc = soup.find_all('div', id='mainpic')[0].img['src']
mydict['imgSrc'] = imgSrc if imgSrc else None
mydict['play'] = []
ul = soup.find_all('ul', class_='bs')
if len(ul):
li = ul[0].find_all('li')
for i in li:
obj = {
'url':urllib.parse.unquote(i.a['href'].replace('https://www.douban.com/link2/?url=','')),
'text':i.a.text.replace(' ', '').replace('\n','')
}
mydict['play'].append(obj)
self.data.append(mydict)
# 线程随机休眠
time.sleep(random.random() * 5)
else:
print('ip被屏蔽')
except Exception as e:
self.proxy = {}
self.proxy1 = {}
print('代理ip代理失败2--',str(e))
@run_time
def run(self):
ths = []
th1 = Thread(target=self.parse_first, args=(self.start_url, ))
th1.start()
ths.append(th1)
for _ in range(self.thread_num):
th = Thread(target=self.parse_second,)
th.setDaemon(True)
th.start()
ths.append(th)
for th in ths:
# 等待线程终止
th.join()
s = json.dumps(self.data, ensure_ascii=False, indent=4)
with open('top250.json', 'w', encoding='utf-8') as f:
f.write(s)
print('Data crawling is finished.')
if __name__ == '__main__':
Spider().run()